python3 利用requests爬取拉勾网数据
学习python,了解了一点爬虫的知识,成功的对拉勾网的招聘信息进行了爬取,将爬取心得记录下来,和大家一起学习进步。
准备工作:
python3
requests
pandas
谷歌浏览器(或者火狐浏览器、qq浏览器)
爬取步骤:
首先打开拉勾网的网址对网站进行分析,打开拉勾网首页(https://www.lagou.com/),通过常用的get方式请求,返回的网页信息不完整,考虑网站是用了ajax异步刷新,所以需要用开发者工具,截取数据包,找到post请求的页面,进行分析。
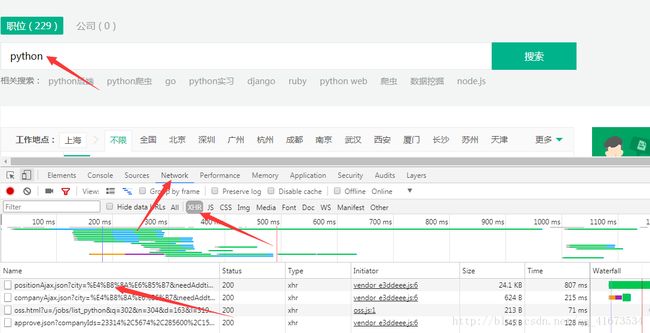
按照图片中的箭头所示,先打开f12调试工具,点击Network,然后输入你想搜索的职位名称,在这以python为例,搜索,会看见下面加载出很多的文件,在这里选择XHR格式,第一个就是post请求的文件,这是我们开始分析这个post请求,看看是不是我们所需要的页面


发现里面存储的是我们需要的数据,随意需要使用post请求,获取动态加载的数据
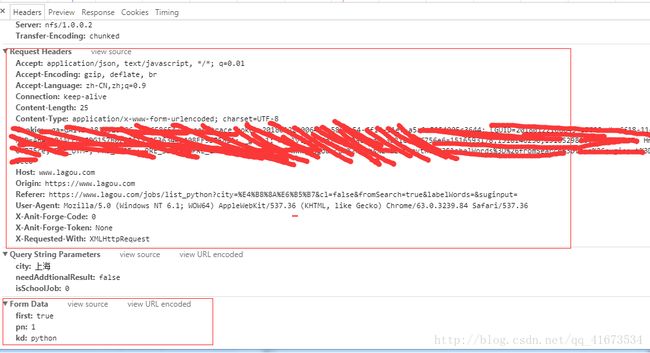
上面的是我们需要的模仿浏览器访问添加的请求头,下面的是我们通过post提交的数据
首先我们需要安装requests和pandas模块,
可以使用
pip install requests
pip install pandas
安装模块
然后开始代码实现:
import requests
from time import sleep
import random
import pandas
#职位所属地
city='北京'
#职位关键字
job='python'
url='https://www.lagou.com/jobs/positionAjax.json?city='+city+'&needAddtionalResult=false&isSchoolJob=0'
header = {
'Host': 'www.lagou.com',
'User-Agent':'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/63.0.3239.84 Safari/537.36',
'Accept': 'application/json, text/javascript, */*; q=0.01',
'Accept-Language': 'zh-CN,en-US;q=0.7,en;q=0.3',
'Accept-Encoding': 'gzip, deflate, br',
'Referer': 'https://www.lagou.com/jobs/list_Python?labelWords=&fromSearch=true&suginput=',
'Content-Type': 'application/x-www-form-urlencoded; charset=UTF-8',
'X-Requested-With': 'XMLHttpRequest',
'X-Anit-Forge-Token': 'None',
'X-Anit-Forge-Code': '0',
'Content-Length': '26',
'Connection': 'keep-alive',
'Pragma': 'no-cache',
'Cache-Control': 'no-cache'
}
for num in range(1,16):
#取随机延迟
ran=random.randint(1,3)
sleep(ran)
#
flag='true'
if num!=1:
flag='false'
form = {'first':flag,
'kd':job,
'pn':str(num)}
html=requests.post(url=url,data=form,headers=header)
result=html.json()
print('--------------------'+str(num)+'-----------------------')
data=result['content']['positionResult']['result']
print(data)
table = pandas.DataFrame(data)
table.to_csv(r'C:\Users\Administrator\Desktop\LaGouPython.csv',header = False, index = False,mode='a+')经过一段时间的等待,可以在桌面看到我们爬取的全部拉勾网的信息

以上简单的爬虫就已经实现了,欢迎大家一起学习交流。