PET/CT图像的纹理特征提取
目的
检验纹理特征对3d-PET/CT图像分类的效果。
简介
在使用传统分类器的时候,和深度学习不一样,我们需要人为地定义图像特征,其实CNN的卷积过程就是一个个的滤波器的作用,目的也是为了提取特征,而这种特征可视化之后往往就是纹理、边缘特征了。因此,在人为定义特征的时候,我们也会去定义一些纹理特征。在这次实验中,我们用数学的方法定义图像的纹理特征,分别计算出来后就可以放入四个经典的传统分类器(随机森林,支持向量机,AdaBoost,BP-人工神经网络)中分类啦。
工具
我使用的工具是MATLAB 2014b,建议版本高一点好,因为里面会更新很多的函数库。实验过程尽量简化,本实验的重点是检验纹理特征对PET/CT图像分类的效果,因此,有些常规的代码我们就用标准的函数库足够啦。
参考文档
PORTS 3D Image Texture Metric Calculation Package
1. 直方图-histogram
直方图描述的是一幅图像中各个像素的分布情况,也就是一个对像素做的统计图。
对于一幅灰度图像 I,它每个像素值的范围是0-255,我们对这些像素点做一个统计,遍历整幅图像,统计像素值0,1,2,3,…,255分别出现的次数。统计完以后相当于我们有了256个频数(次数),再把它们转化成频率,也就是每个频数除以总频数:
p(i) = P(i) / ∑P
以像素值作为横坐标,对应的频率作为纵坐标,就可以得到这个灰度图像 I 的直方图啦。
1.1 举栗子:CT图像的直方图
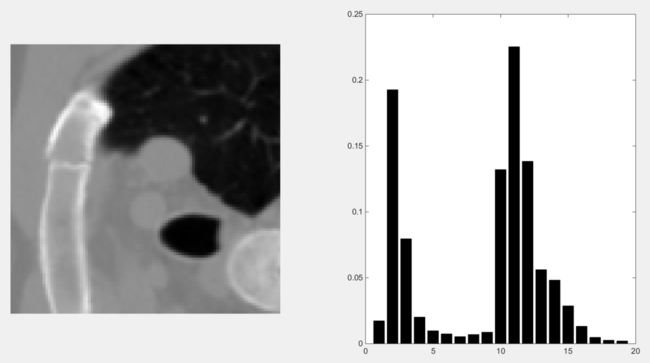
1. CT图像的像素值范围是-1000~1000。相当于我们需要统计2000个像素值的频数,这样划分的粒度有点太细了,因此
2. 将这-1000~1000的区间20等分,每个像素值投射到20个值。直接导致的结果是图像看上去不那么丰富了,但是这样有利于计算。
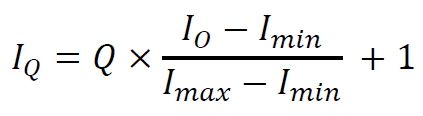
3. 分别统计这20个像素值出现的频数,除以总频数转化成频率。这样频率介于[0,1],并且加和为1.
4. 以20个像素值为横坐标,对应的频率为纵坐标,即可画出这个CT图像的直方图。
The end of this 栗子.
1.2 直方图的代码实现
%%%%%
%%%%% Histogram-based computations:
%%%%%
% Compute the histogram of the ROI and probability of each voxel value:
vox_val_hist = zeros(num_img_values,1);
for this_vox_value = 1:num_img_values
vox_val_hist(this_vox_value) = length(find((img_vol_subvol == this_vox_value) & (mask_vol_subvol == 1) ));
end
% Compute the relative probabilities from the histogram:
vox_val_probs = vox_val_hist / num_ROI_voxels;
% Compute the histogram_based metrics:
texture_metrics(1:6) = compute_histogram_metrics(vox_val_probs,num_img_values);1.3 基于直方图的PET/CT纹理特征
包括六个值,分别是:
(1) Mean
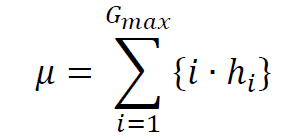
(2) Variance
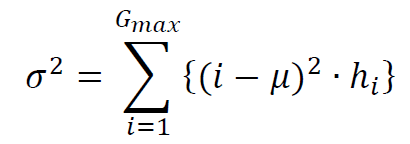
(3) Skewness – set to 0 when σ=0
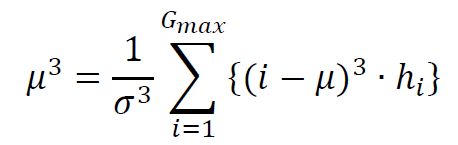
(4) Kurtosis – set to 0 when σ=0 (NOTE: “Kurtosis” and “Excess Kurtosis” differ in that Excess Kurtosis = Kurtosis – 3).
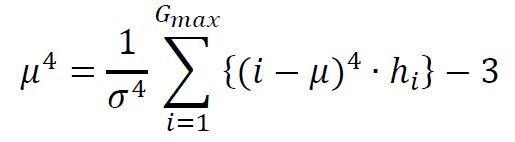
(5) Energy
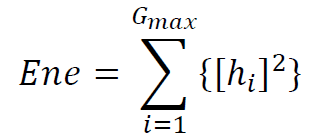
(6) Entropy (NOTE: We will differentiate between the various entropy calculations in this document, specifying the distribution from which the entropy is computed)
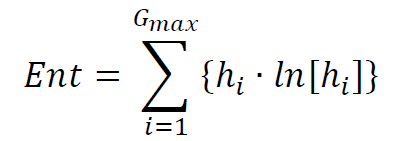
1.4 纹理特征计算实现
%%% Overhead:
% The numerical values of each histogram bin:
vox_val_indices = (1:num_img_values)';
% The indices of non-empty histogram bins:
hist_nz_bin_indices = find(vox_val_probs);
%%% (1) Mean
metrics_vect(1) = sum(vox_val_indices .* vox_val_probs);
%%% (2) Variance
metrics_vect(2) = sum( ((vox_val_indices - metrics_vect(1)).^2) .* vox_val_probs );
%%%%% IF standard variance is zero, so are skewness and kurtosis:
if metrics_vect(2) > 0
%%% (3) Skewness
metrics_vect(3) = sum( ((vox_val_indices - metrics_vect(1)).^3) .* vox_val_probs ) / (metrics_vect(2)^(3/2));
%%% (4) Kurtosis
metrics_vect(4) = sum( ((vox_val_indices - metrics_vect(1)).^4) .* vox_val_probs ) / (metrics_vect(2)^2);
metrics_vect(4) = metrics_vect(4) - 3;
else
%%% (3) Skewness
metrics_vect(3) = 0;
%%% (4) Kurtosis
metrics_vect(4) = 0;
end
%%% (5) Energy
metrics_vect(5) = sum( vox_val_probs .^2 );
%%% (6) Entropy (NOTE: 0*log(0) = 0 for entropy calculations)
metrics_vect(6) = -sum( vox_val_probs(hist_nz_bin_indices) .* log(vox_val_probs(hist_nz_bin_indices)) );注:vox_val_probs表示直方图中的概率值向量,num_img_values表示像素值划分了几等分,相当于上面的栗子中的20.
2. 灰度共生矩阵-GLCM/GTSDM
了解了直方图,我们接下来看看灰度共生矩阵Grey-level co-occurrence matrix GLCM (also called grey tone spatial dependence matrix GTSDM)是个啥。说白了如果直方图是简单的像素概率统计,得到的统计结果是个一维的向量;GLCM就是两个像素之间的共现(共同出现)概率统计,得到的统计结果是个二维的向量。
闹,没看懂。
比如,一幅图中,A处出现了像素值为x的值,如果在距离A处一个特定的地方出现了像素值为y的值,那么得到的GLCM中,坐标(x,y)处的计数加一。假设我们是一个灰度图,x和y的范围都是固定的(0-255),那么也就是说这个统计矩阵也是固定的,是256×256的大小,矩阵中的数值就是频数统计结果,最后转换成频率就是GLCM啦。
也就是说GLCM刻画的是一组像素对儿在图像中的分布情况。
2.1 不知道有没有讲清楚,举个栗子。
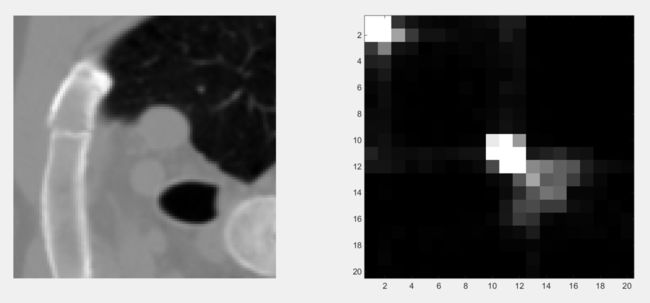
1. CT图像的像素值范围是-1000~1000。相当于我们需要统计2000个像素值的频数,这样划分的粒度有点太细了,因此
2. 将这-1000~1000的区间20等分,每个像素值投射到20个值。直接导致的结果是图像看上去不那么丰富了,但是这样有利于计算。
以上两步和直方图一样。
**3. 锁定CT图中一个点A,坐标(i,j)。**A点的像素值是x,在CT图中,距离A点向右del_i个像素,向下del_j个像素的位置B点,坐标(i+del_i, j+del_j),B点的像素值是y,那么,GLCM矩阵中的位置(x,y)计数加一。注意哦,这里的x,y是原来的CT图像的像素值大小,i,j,del_i,del_j,x,y的意义可不要搞混喽!
4. 遍历CT图中所有的点,方法就是按照第三步这么统计。注意:del_i和del_j这两个偏移量是预先设定好的,也就是说可以认为是常量。
5. 分别将统计完的矩阵中的频数,除以总频数转化成频率。这样频率介于[0,1],并且加和为1.
6. 以20个像素值为横坐标,20个像素值为纵坐标,中间的值表示对应的频率,就得到了这个CT图像的GLCM可视化图。
如此这般,得到的GLCM矩阵描述的就是一组像素对儿在原始CT图像中,在固定偏移(del_x,del_y)中的共现概率分布。
The end of this 栗子.
2.2 简易的2D-image-GLCM代码实现
GLCM2 = graycomatrix(CTimage, 'Offset',[4,4], 'NumLevels',20,'GrayLimits',[]);
2.3 2D-image向3D-image拓展
对于一幅3D的图像,它的GLCM矩阵计算方法与2D图像类似,得到的GLCM矩阵依旧是一个二维的哦,因为GLCM的横纵坐标是像素值,和原始图像的维度无关,即使是个4D图像,它的GLCM矩阵也同样是二维的。
与二维图像相比,三维图像在计算GLCM的步骤类似,只有栗子2的第三步需要做一个改动:
**3. 锁定3D-CT图中一个点A,坐标(i,j,k)。**A点的像素值是x,在CT图中,距离A点向右del_i个像素,向下del_j个像素,向外del_k个像素的位置B点,坐标(i+del_i, j+del_j, k+del_k),B点的像素值是y,那么,GLCM矩阵中的位置(x,y)计数加一。注意哦,这里的x,y是原来的CT图像的像素值大小,i,j,k,del_i,del_j,del_k,x,y的意义可不要搞混喽!
厉害的你可能已经发现,对于一个固定的偏移量del,可以取0或者±del,一共是三个取值,那么对于2D图像,就有3×3-1种情况,如下图所示:
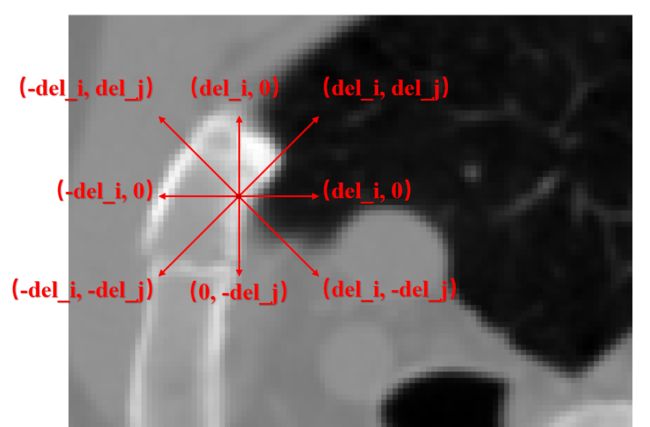
对于3D图像,就有3×3×3-1种情况。
2.4 基于GLCM的PET/CT纹理特征
一共有19个,分别是:
% The first 14 entries in the output are from [Haralick, 1973]:
(1) Angular second moment (called “Energy” in Soh 1999)
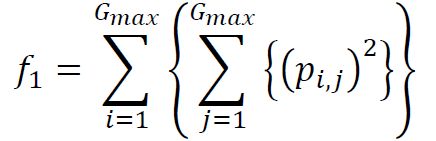
(2) Contrast
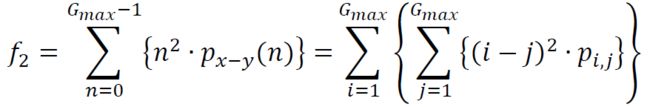
(3) Correlation
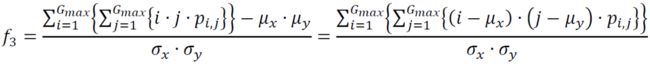
(4) Sum of squares variance
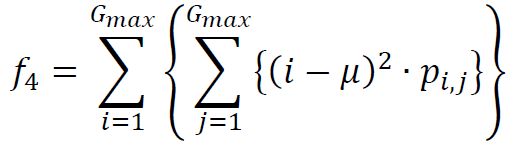
(5) Inverse Difference moment (called “Homogeneity” in [Soh, 1999])
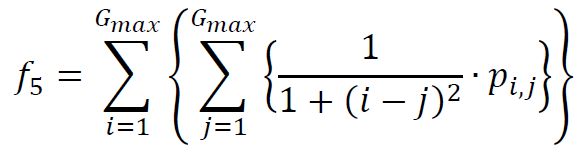
(6) Sum average
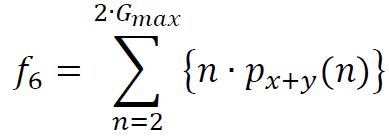
(7) Sum variance
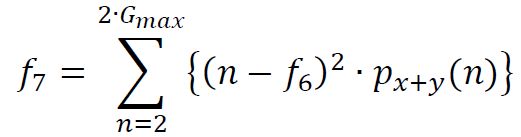
(8) Sum Entropy
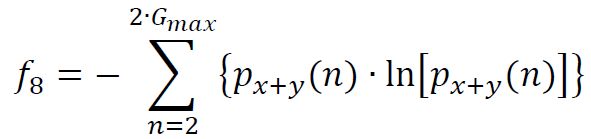
(9) Entropy

(10) Difference Variance
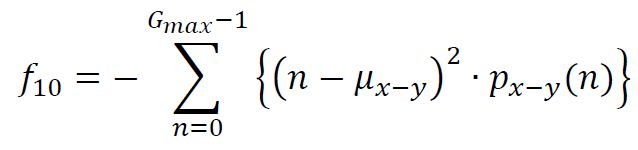
(11) Difference Entropy
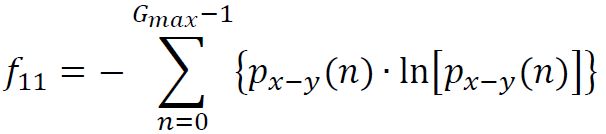
(12) Information Correlation 1
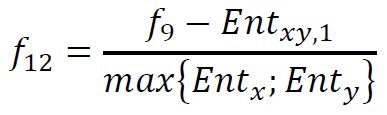
(13) Information Correlation 2
(14) Maximal Correlation Coefficient (不做计算,永远是0)
% The next five entries in the output are from [Soh, 1999]:
(15) Autocorrelation
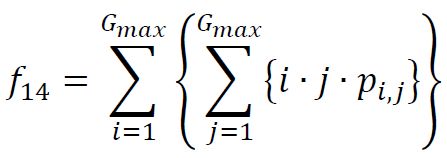
(16) Dissimilarity
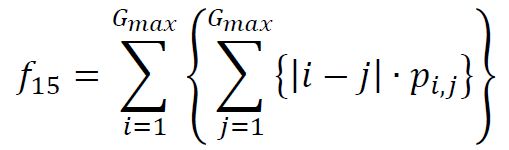
(17) Cluster Shade

(18) Cluster Prominence
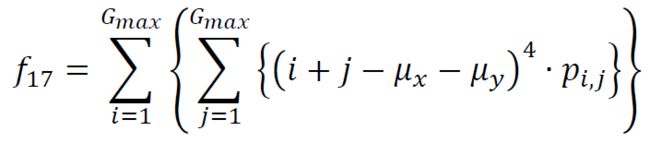
(19) Maximum Probability
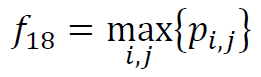
% The next entries are from [Clausi, 2002]:
(20) Inverse Difference
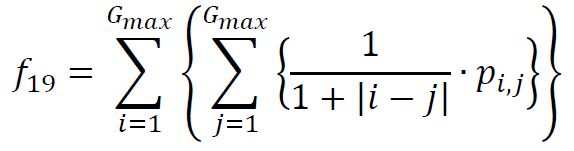
中间量的计算
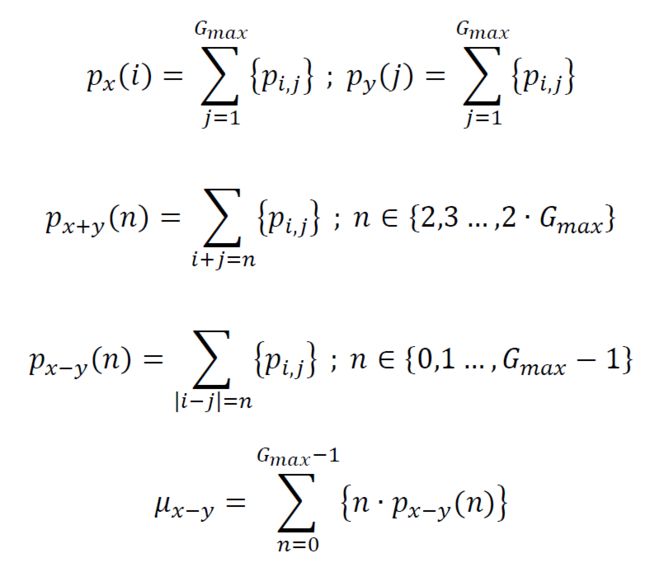
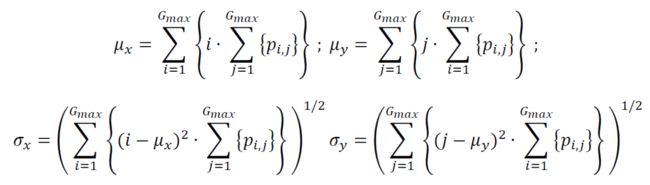

2.5 纹理特征计算实现
% (1) Angular second moment
metrics_vect(1) = sum( p(:).^2 );
% (2) Contrast (for some reason, the paper does not explicitly state p_xmy
% here):
metrics_vect(2) = sum( ((0:(N_g-1))' .^2) .* p_xmy );
% (3) Correlation (there is mathematical ambiguity in the nature of the sum as
% stated in the paper ; this version has the means subtracted after the sum is
% taken, which is the proper method for computation):
mu_x = sum( (1:N_g)' .* p_x );
mu_y = sum( (1:N_g)' .* p_y );
sg_x = sqrt( sum( ( ((1:N_g)' - mu_x).^2 ) .* p_x ) );
sg_y = sqrt( sum( ( ((1:N_g)' - mu_y).^2 ) .* p_y ) );
if (sg_x*sg_y) == 0
metrics_vect(3) = Inf;
else
metrics_vect(3) = ( sum(ndr(:) .* ndc(:) .* p(:) ) - (mu_x*mu_y) ) ./ (sg_x*sg_y);
end
% (4) Sum of squares variance (NOTE: \mu is not defined in the paper, we will
% take it to describe the mean of the normalized GTSDM):
metrics_vect(4) = sum( (( ndr(:) - mean(p(:)) ) .^2) .* p(:) );
% (5) Inverse Difference moment
metrics_vect(5) = sum( ( 1 ./ (1 + ((ndr(:)-ndc(:)).^2) ) ) .* p(:) );
% (6) Sum average
metrics_vect(6) = sum( (1:(2*N_g))' .* p_xpy(:) ); % NOTE: p_xpy(1) = 0 , so adds nothing.
% (7) Sum variance
metrics_vect(7) = sum( (((1:(2*N_g))' - metrics_vect(6)) .^2) .* p_xpy(:));
% (8) Sum Entropy (computed above)
metrics_vect(8) = SE;
% (9) Entropy (computed above)
metrics_vect(9) = HXY;
% (10) Difference Variance
mu_xmy = sum( (0:(N_g-1))' .* p_xmy );
metrics_vect(10) = sum( (((0:(N_g-1))' - mu_xmy) .^2) .* p_xmy );
% (11) Difference Entropy
metrics_vect(11) = -sum( p_xmy(p_xmy>0) .* log(p_xmy(p_xmy>0)) );
% (12) and (13) Information Correlations
if (max(HX,HY)== 0)
metrics_vect(12) = Inf;
else
metrics_vect(12) = (HXY - HXY1) / max(HX,HY);
end
metrics_vect(13) = sqrt(1-exp(-2*(HXY2-HXY)) );
% (14) Maximal Correlation Coefficient
%%% I don't think we use it, so I'll only code it up if needed.
%%%%%
%%%%% The following are from Soh (1999)
%%%%%
% (15) Autocorrelation
metrics_vect(15) = sum( (ndr(:) .* ndc(:)) .* p(:) );
% (16) Dissimilarity
metrics_vect(16) = sum( abs(ndr(:) - ndc(:)) .* p(:) );
% (17) Cluster Shade
metrics_vect(17) = sum( (ndr(:) + ndc(:) - mu_x - mu_y) .^3 .* p(:) );
% (18) Cluster Prominence
metrics_vect(18) = sum( (ndr(:) + ndc(:) - mu_x - mu_y) .^4 .* p(:) );
% (19) Maximum Probability
metrics_vect(19) = max( p(:) );
%%%%%
%%%%% The following are from Clausi (2002)
%%%%%
% (20) Inverse Difference:
metrics_vect(20) = sum( ( 1 ./ (1 + abs( ndr(:)-ndc(:) ) ) ) .* p(:) );3. Neighborhood grey tone difference matrix (NGTDM)
NGTDM刻画的是一个像素与其周围像素值的关系。
3.1 举个2D图像的栗子
1. CT图像的像素值范围是-1000~1000。相当于我们需要统计2000个像素值的频数,这样划分的粒度有点太细了,因此
2. 将这-1000~1000的区间20等分,每个像素值投射到20个值。直接导致的结果是图像看上去不那么丰富了,但是这样有利于计算。
以上两步和前面栗子的一样。
3. 锁定CT图中一个点A,坐标(i,j)。对于一个二维图像来说,A点周围应该有8个点,左边分别是(i±1,j±1),(i,j±1),(i±1,j),这8个点的像素范围是1~20(因为步骤2)。求这8个点的像素值的平均值,为A’。那么,设A点的像素值为p_A
NGTDM(p_A) = NGTDM(p_A) + abs(p_A-A’);
occur(p_A) = occur(p_A) + 1;
4. 遍历CT图中所有的点,方法就是按照第三步这么统计。我们可以得到两个矩阵NGTDM和occur,它们都是20×1的矩阵,NGTDM记录每个像素值周围的情况,occur记录的是每个像素值在整个CT图像中出现的频数。
5. 分别将统计完的occur中的频数,除以总频数转化成频率。这样频率介于[0,1],并且加和为1。
6. 以20个像素值为横坐标,以它们所对应的NGTDM和occur值为纵坐标,做一个柱状图,就可以得到NGTDM和occur的可视化图。
3.2 3D-NGTDM代码实现
function [NGTDM,vox_occurances_NGD26] = compute_3D_NGTDM(ROI_vol,img_vol,binary_dir_connectivity,num_img_values)
% Placeholder for the NGTDM and number of occurances with full NGDs:
NGTDM = zeros(num_img_values,1);
vox_occurances_NGD26 = zeros(num_img_values,1);
% Record the indices of the voxels used in the ROI:
ROI_voxel_indices = find(ROI_vol);
% Loop over each voxel in the ROI sub-volume:
for this_ROI_voxel = 1:length(ROI_voxel_indices)
% The index of this voxel in the sub-volume:
this_voxel_index = ROI_voxel_indices(this_ROI_voxel);
% This voxel must have 26 neighbors (plus itself) to be considered:
if sum(binary_dir_connectivity{this_ROI_voxel}(:)) == 27
% Determine the [r,c,s] of this voxel:
[r,c,s] = ind2sub(size(ROI_vol),this_voxel_index);
% Compute the mean value around this voxel:
this_vox_val = img_vol(this_voxel_index);
vox_ngd = img_vol((r-1):(r+1) , (c-1):(c+1) , (s-1):(s+1));
vox_ngd_sum = sum(vox_ngd(:)) - this_vox_val;
vox_ngd_mean = vox_ngd_sum / 26;
% Add this value to the matrix:
NGTDM(this_vox_val) = NGTDM(this_vox_val) + abs(this_vox_val-vox_ngd_mean);
% Increment the number of occurances of this voxel:
vox_occurances_NGD26(this_vox_val) = vox_occurances_NGD26(this_vox_val) + 1;
end % Test for full neighborhood
end % Loop over ROI voxels3.3 基于NGTDM的PET/CT纹理特征
(1) Coarseness
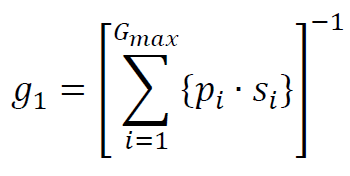
(2) Contrast
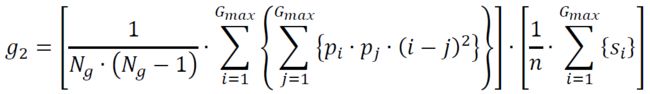
(3) Busyness
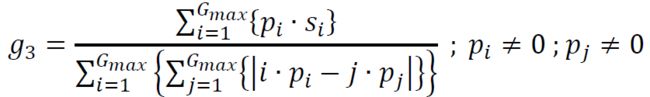
(4) Complexity
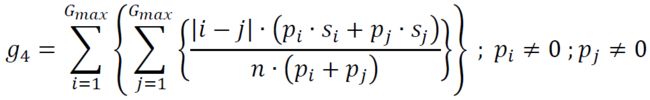
(5) Texture Strength
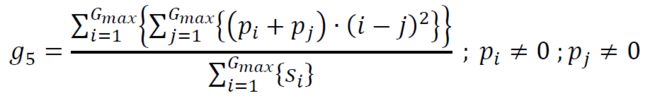
3.4 纹理特征计算实现
%%% (1) Coarseness
metrics_vect(1) = sum( vox_val_probs .* NGTDM );
% It's the reciprocal, so test for zero denominator:
if metrics_vect(1) == 0
metrics_vect(1) = Inf;
else
metrics_vect(1) = 1/metrics_vect(1);
end
%%% (2) Contrast
if N_g > 1 % There is some voxel color differences, so perform calculations as normal:
% The first term in equation (4):
first_term_mat = (vox_val_probs * vox_val_probs') .* ( (nd_r-nd_c).^2 );
first_term_val = sum(first_term_mat(:)) / (N_g * (N_g-1) );
% The second term in equation (4). Note that the 3D computation
% necessitates normalization by the number of voxels instead of the n^2 that appears in
% equation (4).
second_term_val = sum(NGTDM) / sum(vox_occurances_NGD26);
% Record the value:
metrics_vect(2) = first_term_val * second_term_val;
else % There is only a single color, so no contrast to compute, so set to negative:
metrics_vect(2) = -1;
end
%%% (3) Busyness
% NOTE: The denominator equals zero in the paperAmadasun 1989. Absolute value inside the
% double-sum is given here, in accordance with
%
% Texture Analysis Methods ? A Review
% Andrzej Materka and Michal Strzelecki (1998)
%
first_term = sum(vox_val_probs .* NGTDM);
second_term_mat = (nd_nz_r .* nd_nz_p_r) - (nd_nz_c .* nd_nz_p_c);
second_term = sum(abs(second_term_mat(:)));
if second_term == 0
metrics_vect(3) = Inf;
else
metrics_vect(3) = first_term / second_term;
end
%%% (4) Complexity
first_term_num = abs(nd_nz_r - nd_nz_c);
first_term_den = nd_nz_p_r + nd_nz_p_c;
second_term = (nd_nz_p_r .* nd_nz_NGTDMop_r) + (nd_nz_p_c .* nd_nz_NGTDMop_c);
if second_term == 0
metrics_vect(4) = Inf;
else
tmp = first_term_num(:) .* second_term(:) ;
tmp = sum(tmp ./ first_term_den(:)) ;
metrics_vect(4) = tmp / sum(vox_occurances_NGD26) ;
end
%%% (5) Texture Strength
first_term_mat = (nd_nz_p_r+nd_nz_p_c) .* ( (nd_nz_r - nd_nz_c) .^2 );
first_term = sum(first_term_mat(:));
second_term = sum(NGTDM);
if second_term == 0
metrics_vect(5) = Inf;
else
metrics_vect(5) = first_term / second_term ;
end4. Grey Level Zone Size Matrix (GLZSM)
4.1 基于GLZSM的PET/CT纹理特征
(1) Small Zone Size Emphasis
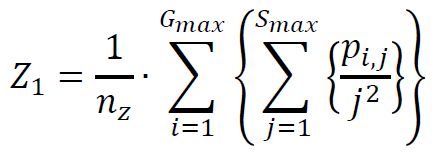
(2) Large Zone Size Emphasis

(3) Low Gray-Level Zone Emphasis
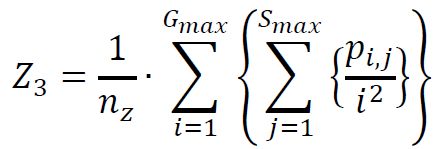
(4) High Gray-Level Zone Emphasis
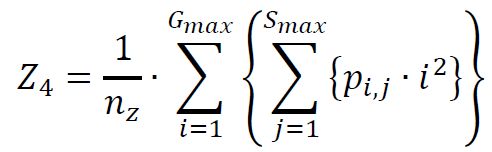
(5) Small Zone / Low Gray Emphasis
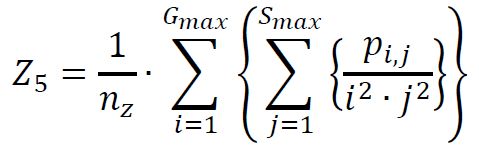
(6) Small Zone / High Gray Emphasis
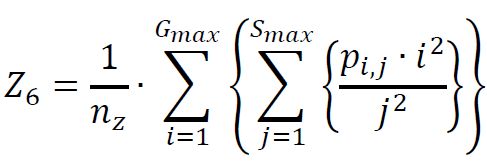
(7) Large Zone / Low Gray Emphasis
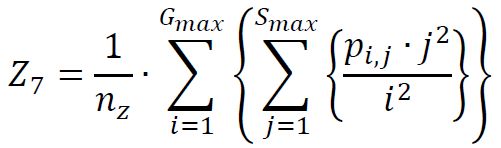
(8) Large Zone / High Gray Emphasis
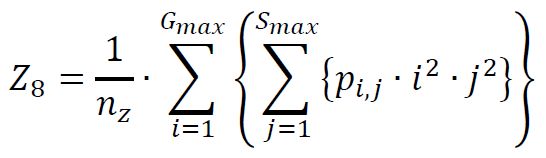
(9) Gray-Level Non-Uniformity
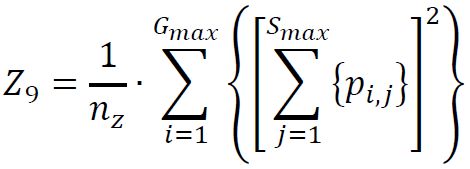
(10) Zone Size Non-Uniformity
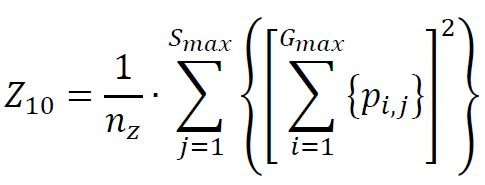
(11) Zone Size Percentage
