- Java安全:SpringBoot项目中Fastjson组件的使用与安全实践
rockmelodies
java安全java安全springboot
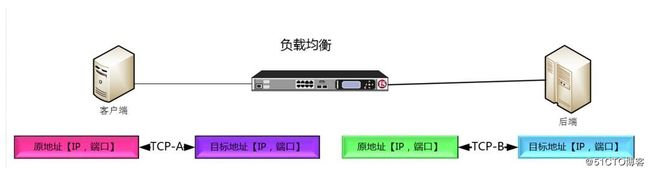
前言Fastjson是阿里巴巴开源的一个高性能JavaJSON库,广泛用于Java对象的序列化和反序列化操作。在SpringBoot项目中,Fastjson常被用作JSON处理工具。然而,Fastjson因其高性能而广受欢迎的同时,也因多次爆出的安全漏洞而备受关注。本文将介绍如何在SpringBoot项目中正确使用Fastjson,并讨论相关的安全实践。一、SpringBoot项目中集成Fastj
- 100天挑战训练营day63/100
美妆博主樱子
每日三问三答问题一:今天有什么突破?(最有感觉的事)今天在拍视频的技巧上和路线上有一些心得,视频中的表现力是非常重要的,一定要抓住黄金前三秒,破了前三秒,后面的内容才可能曝光,而点赞和评论加转发量达到一定程度才能获得热门。我今天发现要想获得大热门,要么就是自己很可爱美丽,稍加表演就可能热门;但是如果颜值不是特别好,就必须培养成一个有趣的灵魂,灵动的表情和高超的化妆技术,这样才能获得大热门。直播带货
- 2012-6-3 金学伟:在混沌中寻找有序
Jasmine_yao
5月26日我在公司给客户讲课并给不能前来现场的客户录制视频。讲课中我演示了一组数据——(1429-386)÷1429=0.7299(1558-325)÷1558=0.7914(1052-512)÷1052=0.5133(2245-998)÷2245=0.5554(6124-1664)÷6124=0.7283(3478-2132)÷3478=0.387这是1992年以来6次重大调整(幅度超过50%或
- 基于K8s ingress灰度发布配置
这里只对基于ingress和configmap两种方式进行了演示,一种是流量控制,一种是configmap配置控制。ingress:适用于整体版本更新迭代或者是某个页面的局部更新。configmap:可以结合代码对指定地理区域或者指定机型(ios、安卓、pc)进行推送新版本。一、安装ingress-nginx#安装教程可以看另一篇文章安装的是2025年7月份最新的ingress版本https://
- 2022-12-26
胡诌文学
今天看到一个人发了文章说不再买书了,这是时代的悲哀,也是时代的幸运,以前,知识就像是一个象牙塔,虽说事事洞明皆学问,但躲不过黄金屋的书籍,但是现在,知识扩散越来越明显,我们只要有心,就可学习,不必纠结于书
- 2019-02-10
轻尘_b215
R:[阅读社会]真正会休息的人,是如何度过假期的?I:假期本来是用来休息的,让们恢复疲劳,放松神经。但是长假后多数人的体验就是一个字一一累。为什么会是这样,皆因不懂得休息所致。体验心流是最好的休息方法,心流是人陶醉于所专注的事物,内心纯净安宁,超越现实,物我两忘,获得极大的放松和满足。减少刷手机,看电视等被动式休闲投入,主动式休闲,从事个人爱好、运动、阅读等容易产生心流。A1:春节长假期间读到这篇
- 76年前的今天,永远铭记!
苜蓿_49ff
在今天这样的日子,我的语言显得太过匮乏,只能粘贴如下:这是值得每个中国人永远铭记的一天76年前的今天1945年8月15日日本天皇裕仁广播《停战诏书》宣布日本无条件投降这是每个中国人都不能忘却的历史从1931年到1945年中国一半国土被日本侵略者践踏3500多万同胞伤亡4200多万难民无家可归烽火岁月山河飘摇苍生蒙难家国难安这是14年挥洒血泪永不屈服的抗争面对异常残暴的敌人不甘屈辱的中华儿女共赴国难
- 男宝
郭婵飞
男宝应该挺受欢迎吧!前两周家婆和奶奶通视频,又聊到这个话题。奶奶说:“朱*现在可以再生一个了,现在都开放三胎了,再生一个男宝。”家婆也在一边附和着说,可以生一个男宝了。小叔也在一边说,让我老公再生一个男宝。我在旁边听了就很生气。为什么我还要再生一个?难道生两个女儿不可以吗?难道口口声声说不管生男生女都可以,生了两个就行了是假话吗?你一个连二胎都不愿生的人凭什么唆使我老公让我生三胎?当时我就很生气地
- Kubernetes学习笔记(四)--Pod 状态与生命周期管理
Mr小三
Kubernetes云原生kubernetes
文章目录四、Pod状态与生命周期管理1.Pod概念网络存储用法pod的终止2.Init容器init模板用途3.Pause容器4.Pod的生命周期Podphase(阶段)Pod状态5.Pod健康-容器探针(Probe)概念EXEC探针HTTP探针TCPSocket探针四、Pod状态与生命周期管理Pod是kubernetes中最重要的基本概念,在kubernetes中最小的管理元素不是一个个独立的容器
- HTML+CSS+JS
binzhenliziyuan
javascripthtmlcss
HTML+CSS+JSHTML基础1.HTML文件中的DOCTYPE是什么作用?2.HTML、XML、XHTML之间有什么区别?3.前缀为data-开头的元素属性是什么?4.谈谈你对HTML语义化的理解?5.HTML5对比HTML4有哪些不同之处?6.meta标签有哪些常用用法?7.img标签的srcset的作用是什么?8.响应式图片处理优化:Picture标签9.在script标签上使用defe
- Windows 安装 nvm-windows(Node.js 版本管理器)
听听你说的--
nuxtwindowsnode.js
Windows安装nvm-windows(Node.js版本管理器)教程✅第一步:卸载旧版Node.js(如已安装)打开「控制面板」→「程序和功能」找到Node.js,点击卸载确保命令行输入node-v显示不是命令,表示已卸载干净✅第二步:下载安装nvm-windows下载地址:nvm-windowsGitHubReleases下载方式:找到最新版本(如1.1.12)点击下载nvm-setup.e
- 跑步大神 2017/12/13
Surprise旅程
图片发自App本不想跑,同学过来拿东西,冯丽萍过来吃完饭,回去,有点晚,本不想跑,但还是想自己的计划不要被打乱,还是去跑了,而且跑的比以往都快了些。给自己一个大大的赞
- 5.k8s:helm包管理器,prometheus监控,elk,k8s可视化
鹏哥哥啊Aaaa
运维kubernetes容器云原生
目录一、Helm包管理器1.什么是Helm2.安装Helm(3)Helm常用命令(4)目录结构(5)使用Helm完成redis主从搭建二、Prometheus集群监控1.监控方案2.Prometheus监控k8s三、ELK日志搜集1.elk流程2.配置elk(1)配置es(2)配置logstash(3)配置filebeat,kibana3.kibana使用和日志检索四、k8s可视化管理1.Dash
- 跃迁
韩涵数
每次买完付费课程,我就问自己,你想从这里学到什么,是那一句文案吸引了你,他宣传的那些吸引人的模式又能做到多少呢?反正也买了,就来验证一下他们的用心程度。但核聚老师的课我真心不后悔,反而捡到了宝,比如今天学到的第8课,如何快速掌握一门知识,图片发自App图片发自App给出4个方法,3个结论1.比如数学,你选一章节,是你花一些力气就能见效果的。把他分成5组,每组6道题,就是30道题,如果6道题有3道是
- Spring AI 函数调用(Function Call)系统设计方案
大树~~
AI应用开发spring人工智能数据库SpringAIFunctionCall
一、系统概述与设计目标1.1核心目标从零构建一个灵活、安全、高效的函数调用系统,使大语言模型能够在对话中调用应用程序中的方法,同时保持良好的开发体验和企业级特性。1.2主要功能需求支持通过注解将普通Java方法标记为可被AI调用的函数自动生成符合LLM要求的函数描述和参数定义安全地解析和执行模型的函数调用请求处理并返回执行结果给模型提供扩展点以支持不同LLM提供商的特定实现1.3设计原则开发便捷性
- 2021-10-22
和力
车祸今天中午,回来的路上,拐进市里的最后一个红绿灯,南边路口横竖的停着两辆车。黑色车的后备箱敞开着,灰色轿车插进了便道,车身上的零固件,散落在了整个路口。两个司机在路边,交谈商量着什么。我不算老司机,只开了三四年的车,车技也不算好。不过事故,除了刚开车时候的两起,到现在再也没有过。讲老实话,我有时候也挺猛的。我出的两起事故,一起是我撞别人,另一起是别人撞我。快速路上,洒水车刚刚走过,湿润的路面更加
- spring的AnnotatedBeanDefinitionReader类
https://docs.spring.io/spring-framework/docs/6.1.3/javadoc-api/org/springframework/context/annotation/AnnotatedBeanDefinitionReader.htmlorg.springframework.context.annotation.AnnotatedBeanDefinitionRe
- bug:定时任务因数据库时间滞后导致数据清理失效问题
刘火锅
javaspringcloudspring后端mybatis
问题背景:在数据清理定时任务中,发现理应被删除的数据未被正确清理。经排查发现:定时任务配置在每日00:00:00执行删除数据SQL语句逻辑正常应用服务器时间准确数据库服务器时间比应用服务器慢15秒数据清理SQL使用CURDATE()获取当前日期问题原因分析:当应用服务器在00:00:00触发任务时:应用服务器时间:2025-07-1800:00:00数据库服务器时间:2025-07-1723:59
- 暑假第八周
09小溪流家臣
第八周就是因为这么就开学了,顿时我就感觉非常非常兴奋,终于可以开学了,在家都憋闷了,我觉得这一种很快乐^ω^,因为作业都差不多都完了,这一周我和一个朋,玩了两天,这两天我们一直在玩,当然也不能忘了读书(´-ωก`),第一天我先去他家玩,我们先玩了会儿电脑,什么什么的,然后我们又读书了,要干很多很多的事,然后终于到了第二天,他是来我家玩的,我们先是看了会儿书,在玩了会,我们晚上还看了一部电影巨齿鲨。
- 读《致教师》轻松做教师
菩提xqsx
8月,是个很惬意的时间,作为教师正值暑假过半,心无杂念、游走之余捧一本书静静地阅读,这真是难得的幸福!这次我读的是朱永新教授的《致教师》。用本书中的一句话形容本书在一个教师成长过程的重要性就是:在大师的肩膀上攀升!本书以书信的形式共有四辑,由教师提出教育教学中出现的各种困惑、问题、现象,朱教授用书信的形式给予回答。第一辑是:给我一个做教师的理由,一共15个问题,告诉我们为什么要做教师,如何做老师?
- Kubernetes 集群简介 部署搭建 及常用命令
GHY@CloudGuardian
Kuberneteskubernetes容器云原生运维linux
Kubernetes集群简介Kubernetes(简称K8s)是一个开源的容器编排平台,用于自动化容器化应用的部署、扩展和管理。它为容器提供了一个完整的管理框架,帮助开发者和运维团队在大规模环境中高效地部署和管理应用。Kubernetes集群是由多个组件组成的,主要包括控制平面和工作节点。集群的核心目的是确保容器化应用的高可用性、可扩展性、负载均衡、自动化部署等功能。Kubernetes集群的基本
- 《独孤残缺》第一百一十六章:传国玉玺
卧龙镇吟
韩萧萧只是从直觉上认为寂无名有问题,但是还说不出到底有什么问题,而最有话语权和可信度的人就是柳云烟,但是李默天暂时还不准备见她,他还没准备好要以什么样的心去接受她。如今寂无名又跟陵南王扯上了关系,不管慕容汐所言真假,就算真的是在借刀杀人,李默天都不能再对这个人置之不理。“背叛你!”李默天又问道:“你的意思是说寂无名只是你的人?”慕容汐也感觉自己表达有误,急忙改口,说道:“背叛我就是背叛组织。”李默
- 工作 随感,收获
宁静致远05
1.维护好自己的声誉和品质,一起配合,提供合理的建议,帮助,做好自己份内事。2.接受比对,真诚对待,态度不卑不亢。
- 超详细 Conda 指令详解---附有相应的示例
以下是所有conda指令的详细列表,并附有相应的示例超详细Conda指令详解环境管理命令condacreate:创建新环境condacreate--name[package_spec1package_spec2...]示例:condacreate--namemyenvnumpypandascondainstall:安装包到当前环境condainstall[--name][--file][--cha
- 仓库货物检测:基于YOLOv5的深度学习应用与UI界面开发
YOLO实战营
YOLO深度学习ui目标跟踪目标检测人工智能
一、引言随着电商和物流行业的快速发展,仓库货物管理已经成为企业运营中至关重要的环节。为了提高仓库管理的效率和准确性,越来越多的企业开始应用自动化技术来完成货物的盘点、分类、分拣等任务。传统的货物管理方式通常依赖人工检查,不仅效率低下,而且容易出现误差。为了克服这些问题,利用计算机视觉和深度学习技术来实现仓库货物的自动化检测成为了一种有效的解决方案。本博客将介绍如何使用YOLOv5进行仓库货物检测,
- 2021-5-11晨间日记
飞翔_8019
今天是什么日子起床:7:05就寝:23:32天气:晴天心情:好纪念日:昨天跟闺蜜聊天一个多小时叫我起床的不是闹钟是梦想年度目标及关键点:财富自由本月重要成果:理财投资学习今日三只青蛙/番茄钟1.读书2.日更文章成功日志-记录三五件有收获的事务1.不能自己欺骗自己,要实事求是能做多少,不能做多少,为什么做不了,要分析原因。不能太迁就自己。2.自己最近做事效率不高。要想办法提高效率。3.规定自己什么时
- 【云原生】Helm来管理Kubernetes集群的详细使用方法与综合应用实战
景天科技苑
云原生K8S零基础到进阶实战云原生kubernetes容器Helmk8sk8s集群
✨✨欢迎大家来到景天科技苑✨✨养成好习惯,先赞后看哦~作者简介:景天科技苑《头衔》:大厂架构师,华为云开发者社区专家博主,阿里云开发者社区专家博主,CSDN全栈领域优质创作者,掘金优秀博主,51CTO博客专家等。《博客》:Python全栈,前后端开发,小程序开发,人工智能,js逆向,App逆向,网络系统安全,数据分析,Django,fastapi,flask等框架,云原生k8s,linux,she
- 什么才是成功?
岳雪莲
今天想到这个问题,是因为前段时间孩子的比赛状态不好,他比较喜欢乒乓球,最近有很大进步,但是一到比赛就紧张的打不好球,往往以失败告终。那在我的思想里他这样的状态就是不成功的,有球却输了。孩子从小喜欢圆的东西,玩具也都是大大小小的球,四岁时就在篮球场把篮球能托到球筐里(我们那叫端马桶),到五岁时我们去社区玩,他看到乒乓球台,突然说我也要玩,于是第二天我们就带上球拍和球过去打了(我和他爸都会打打,但打的
- 以自我革命精神推进全面从严治党向纵深发展
uosuor
勇于自我革命是中国共产党最鲜明的政治品格,也是我们党最大的优势,党的二十大报告指出,全面从严治党永远在路上,党的自我革命永远在路上,决不能有松劲歇脚、疲劳厌战的情绪,必须持之以恒推进全面从严治党,深入推进新时代党的建设新的伟大工程,以党的自我革命引领社会革命。高度重视自身建设,不断进行自我革命。历史和实践表明,中国共产党之所以能够带领中国人民克服一个又一个艰难险阻,在战胜困难中不断成熟,不断从胜利
- 【泽宇读书会18】突发事件打乱所有计划,四大法则傍身,谁来也不怕!
暴富的小青
阅读《高效能人士的时间管理课:不可不知的8项黄金法则》P46-61第四天,进度只有20页。我们经常经常会碰到这样一种情况:花了很长时间制定好自己的一份完美的计划清单。当准备重新开始美好的一天时,却发现自己办公桌堆满新的任务,工作如大海波浪,一波未平一波又起,而且每一波都会被注明是“紧急任务”,看看计划清单,再看看堆积如山的新任务,瞬间更加焦虑了。元亨利在《高效能人士的时间管理课:不可不知的8项黄金
- java的(PO,VO,TO,BO,DAO,POJO)
Cb123456
VOTOBOPOJODAO
转:
http://www.cnblogs.com/yxnchinahlj/archive/2012/02/24/2366110.html
-------------------------------------------------------------------
O/R Mapping 是 Object Relational Mapping(对象关系映
- spring ioc原理(看完后大家可以自己写一个spring)
aijuans
spring
最近,买了本Spring入门书:spring In Action 。大致浏览了下感觉还不错。就是入门了点。Manning的书还是不错的,我虽然不像哪些只看Manning书的人那样专注于Manning,但怀着崇敬 的心情和激情通览了一遍。又一次接受了IOC 、DI、AOP等Spring核心概念。 先就IOC和DI谈一点我的看法。IO
- MyEclipse 2014中Customize Persperctive设置无效的解决方法
Kai_Ge
MyEclipse2014
高高兴兴下载个MyEclipse2014,发现工具条上多了个手机开发的按钮,心生不爽就想弄掉他!
结果发现Customize Persperctive失效!!
有说更新下就好了,可是国内Myeclipse访问不了,何谈更新...
so~这里提供了更新后的一下jar包,给大家使用!
1、将9个jar复制到myeclipse安装目录\plugins中
2、删除和这9个jar同包名但是版本号较
- SpringMvc上传
120153216
springMVC
@RequestMapping(value = WebUrlConstant.UPLOADFILE)
@ResponseBody
public Map<String, Object> uploadFile(HttpServletRequest request,HttpServletResponse httpresponse) {
try {
//
- Javascript----HTML DOM 事件
何必如此
JavaScripthtmlWeb
HTML DOM 事件允许Javascript在HTML文档元素中注册不同事件处理程序。
事件通常与函数结合使用,函数不会在事件发生前被执行!
注:DOM: 指明使用的 DOM 属性级别。
1.鼠标事件
属性
- 动态绑定和删除onclick事件
357029540
JavaScriptjquery
因为对JQUERY和JS的动态绑定事件的不熟悉,今天花了好久的时间才把动态绑定和删除onclick事件搞定!现在分享下我的过程。
在我的查询页面,我将我的onclick事件绑定到了tr标签上同时传入当前行(this值)参数,这样可以在点击行上的任意地方时可以选中checkbox,但是在我的某一列上也有一个onclick事件是用于下载附件的,当
- HttpClient|HttpClient请求详解
7454103
apache应用服务器网络协议网络应用Security
HttpClient 是 Apache Jakarta Common 下的子项目,可以用来提供高效的、最新的、功能丰富的支持 HTTP 协议的客户端编程工具包,并且它支持 HTTP 协议最新的版本和建议。本文首先介绍 HTTPClient,然后根据作者实际工作经验给出了一些常见问题的解决方法。HTTP 协议可能是现在 Internet 上使用得最多、最重要的协议了,越来越多的 Java 应用程序需
- 递归 逐层统计树形结构数据
darkranger
数据结构
将集合递归获取树形结构:
/**
*
* 递归获取数据
* @param alist:所有分类
* @param subjname:对应统计的项目名称
* @param pk:对应项目主键
* @param reportList: 最后统计的结果集
* @param count:项目级别
*/
public void getReportVO(Arr
- 访问WEB-INF下使用frameset标签页面出错的原因
aijuans
struts2
<frameset rows="61,*,24" cols="*" framespacing="0" frameborder="no" border="0">
- MAVEN常用命令
avords
Maven库:
http://repo2.maven.org/maven2/
Maven依赖查询:
http://mvnrepository.com/
Maven常用命令: 1. 创建Maven的普通java项目: mvn archetype:create -DgroupId=packageName
- PHP如果自带一个小型的web服务器就好了
houxinyou
apache应用服务器WebPHP脚本
最近单位用PHP做网站,感觉PHP挺好的,不过有一些地方不太习惯,比如,环境搭建。PHP本身就是一个网站后台脚本,但用PHP做程序时还要下载apache,配置起来也不太很方便,虽然有好多配置好的apache+php+mysq的环境,但用起来总是心里不太舒服,因为我要的只是一个开发环境,如果是真实的运行环境,下个apahe也无所谓,但只是一个开发环境,总有一种杀鸡用牛刀的感觉。如果php自己的程序中
- NoSQL数据库之Redis数据库管理(list类型)
bijian1013
redis数据库NoSQL
3.list类型及操作
List是一个链表结构,主要功能是push、pop、获取一个范围的所有值等等,操作key理解为链表的名字。Redis的list类型其实就是一个每个子元素都是string类型的双向链表。我们可以通过push、pop操作从链表的头部或者尾部添加删除元素,这样list既可以作为栈,又可以作为队列。
&nbs
- 谁在用Hadoop?
bingyingao
hadoop数据挖掘公司应用场景
Hadoop技术的应用已经十分广泛了,而我是最近才开始对它有所了解,它在大数据领域的出色表现也让我产生了兴趣。浏览了他的官网,其中有一个页面专门介绍目前世界上有哪些公司在用Hadoop,这些公司涵盖各行各业,不乏一些大公司如alibaba,ebay,amazon,google,facebook,adobe等,主要用于日志分析、数据挖掘、机器学习、构建索引、业务报表等场景,这更加激发了学习它的热情。
- 【Spark七十六】Spark计算结果存到MySQL
bit1129
mysql
package spark.examples.db
import java.sql.{PreparedStatement, Connection, DriverManager}
import com.mysql.jdbc.Driver
import org.apache.spark.{SparkContext, SparkConf}
object SparkMySQLInteg
- Scala: JVM上的函数编程
bookjovi
scalaerlanghaskell
说Scala是JVM上的函数编程一点也不为过,Scala把面向对象和函数型编程这两种主流编程范式结合了起来,对于熟悉各种编程范式的人而言Scala并没有带来太多革新的编程思想,scala主要的有点在于Java庞大的package优势,这样也就弥补了JVM平台上函数型编程的缺失,MS家.net上已经有了F#,JVM怎么能不跟上呢?
对本人而言
- jar打成exe
bro_feng
java jar exe
今天要把jar包打成exe,jsmooth和exe4j都用了。
遇见几个问题。记录一下。
两个软件都很好使,网上都有图片教程,都挺不错。
首先肯定是要用自己的jre的,不然不能通用,其次别忘了把需要的lib放到classPath中。
困扰我很久的一个问题是,我自己打包成功后,在一个同事的没有装jdk的电脑上运行,就是不行,报错jvm.dll为无效的windows映像,如截图
最后发现
- 读《研磨设计模式》-代码笔记-策略模式-Strategy
bylijinnan
java设计模式
声明: 本文只为方便我个人查阅和理解,详细的分析以及源代码请移步 原作者的博客http://chjavach.iteye.com/
/*
策略模式定义了一系列的算法,并将每一个算法封装起来,而且使它们还可以相互替换。策略模式让算法独立于使用它的客户而独立变化
简单理解:
1、将不同的策略提炼出一个共同接口。这是容易的,因为不同的策略,只是算法不同,需要传递的参数
- cmd命令值cvfM命令
chenyu19891124
cmd
cmd命令还真是强大啊。今天发现jar -cvfM aa.rar @aaalist 就这行命令可以根据aaalist取出相应的文件
例如:
在d:\workspace\prpall\test.java 有这样一个文件,现在想要将这个文件打成一个包。运行如下命令即可比如在d:\wor
- OpenJWeb(1.8) Java Web应用快速开发平台
comsci
java框架Web项目管理企业应用
OpenJWeb(1.8) Java Web应用快速开发平台的作者是我们技术联盟的成员,他最近推出了新版本的快速应用开发平台 OpenJWeb(1.8),我帮他做做宣传
OpenJWeb快速开发平台以快速开发为核心,整合先进的java 开源框架,本着自主开发+应用集成相结合的原则,旨在为政府、企事业单位、软件公司等平台用户提供一个架构透
- Python 报错:IndentationError: unexpected indent
daizj
pythontab空格缩进
IndentationError: unexpected indent 是缩进的问题,也有可能是tab和空格混用啦
Python开发者有意让违反了缩进规则的程序不能通过编译,以此来强制程序员养成良好的编程习惯。并且在Python语言里,缩进而非花括号或者某种关键字,被用于表示语句块的开始和退出。增加缩进表示语句块的开
- HttpClient 超时设置
dongwei_6688
httpclient
HttpClient中的超时设置包含两个部分:
1. 建立连接超时,是指在httpclient客户端和服务器端建立连接过程中允许的最大等待时间
2. 读取数据超时,是指在建立连接后,等待读取服务器端的响应数据时允许的最大等待时间
在HttpClient 4.x中如下设置:
HttpClient httpclient = new DefaultHttpC
- 小鱼与波浪
dcj3sjt126com
一条小鱼游出水面看蓝天,偶然间遇到了波浪。 小鱼便与波浪在海面上游戏,随着波浪上下起伏、汹涌前进。 小鱼在波浪里兴奋得大叫:“你每天都过着这么刺激的生活吗?简直太棒了。” 波浪说:“岂只每天过这样的生活,几乎每一刻都这么刺激!还有更刺激的,要有潮汐变化,或者狂风暴雨,那才是兴奋得心脏都会跳出来。” 小鱼说:“真希望我也能变成一个波浪,每天随着风雨、潮汐流动,不知道有多么好!” 很快,小鱼
- Error Code: 1175 You are using safe update mode and you tried to update a table
dcj3sjt126com
mysql
快速高效用:SET SQL_SAFE_UPDATES = 0;下面的就不要看了!
今日用MySQL Workbench进行数据库的管理更新时,执行一个更新的语句碰到以下错误提示:
Error Code: 1175
You are using safe update mode and you tried to update a table without a WHERE that
- 枚举类型详细介绍及方法定义
gaomysion
enumjavaee
转发
http://developer.51cto.com/art/201107/275031.htm
枚举其实就是一种类型,跟int, char 这种差不多,就是定义变量时限制输入的,你只能够赋enum里面规定的值。建议大家可以看看,这两篇文章,《java枚举类型入门》和《C++的中的结构体和枚举》,供大家参考。
枚举类型是JDK5.0的新特征。Sun引进了一个全新的关键字enum
- Merge Sorted Array
hcx2013
array
Given two sorted integer arrays nums1 and nums2, merge nums2 into nums1 as one sorted array.
Note:You may assume that nums1 has enough space (size that is
- Expression Language 3.0新特性
jinnianshilongnian
el 3.0
Expression Language 3.0表达式语言规范最终版从2013-4-29发布到现在已经非常久的时间了;目前如Tomcat 8、Jetty 9、GlasshFish 4已经支持EL 3.0。新特性包括:如字符串拼接操作符、赋值、分号操作符、对象方法调用、Lambda表达式、静态字段/方法调用、构造器调用、Java8集合操作。目前Glassfish 4/Jetty实现最好,对大多数新特性
- 超越算法来看待个性化推荐
liyonghui160com
超越算法来看待个性化推荐
一提到个性化推荐,大家一般会想到协同过滤、文本相似等推荐算法,或是更高阶的模型推荐算法,百度的张栋说过,推荐40%取决于UI、30%取决于数据、20%取决于背景知识,虽然本人不是很认同这种比例,但推荐系统中,推荐算法起的作用起的作用是非常有限的。
就像任何
- 写给Javascript初学者的小小建议
pda158
JavaScript
一般初学JavaScript的时候最头痛的就是浏览器兼容问题。在Firefox下面好好的代码放到IE就不能显示了,又或者是在IE能正常显示的代码在firefox又报错了。 如果你正初学JavaScript并有着一样的处境的话建议你:初学JavaScript的时候无视DOM和BOM的兼容性,将更多的时间花在 了解语言本身(ECMAScript)。只在特定浏览器编写代码(Chrome/Fi
- Java 枚举
ShihLei
javaenum枚举
注:文章内容大量借鉴使用网上的资料,可惜没有记录参考地址,只能再传对作者说声抱歉并表示感谢!
一 基础 1)语法
枚举类型只能有私有构造器(这样做可以保证客户代码没有办法新建一个enum的实例)
枚举实例必须最先定义
2)特性
&nb
- Java SE 6 HotSpot虚拟机的垃圾回收机制
uuhorse
javaHotSpotGC垃圾回收VM
官方资料,关于Java SE 6 HotSpot虚拟机的garbage Collection,非常全,英文。
http://www.oracle.com/technetwork/java/javase/gc-tuning-6-140523.html
Java SE 6 HotSpot[tm] Virtual Machine Garbage Collection Tuning
&