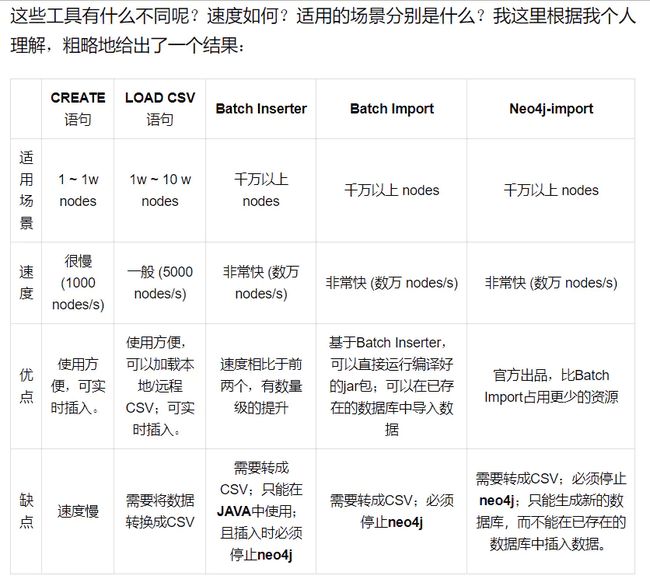
- 应收账款管理的要点问题
DebtCollection
目前,许多企业在应收账款的管理上存在以下现状:(1)在赊销货物前对客户的信用状况调查不够,导致应收账款不断增加;(2)对应收账款的账龄没有及时分析,导致企业风险增大;(3)催收应收账款的方法和程序不当,导致应收账款的催收费用大量增加。应收账款管理作为企业管理中的一项重要工作,需要每个部门相互配合,把企业应收账款的风险降到最低。应收账款管理不善会存在诸多弊端1.影响企业资金周转,掩盖企业真实经营状况
- 目标检测-YOLOv5
wydxry
深度学习目标检测YOLO人工智能深度学习
YOLOv5介绍YOLOv5是YOLO系列的第五个版本,由Ultralytics团队发布。虽然YOLOv5并非JosephRedmon原团队发布,但它在YOLOv4的基础上进行了重要的优化和改进,成为了深度学习目标检测领域中的热门模型之一。YOLOv5的优势不仅体现在其性能上,还包括其简洁易用、部署便捷的特点。相较于YOLOv4,YOLOv5对于代码框架的重构、推理速度的提升,以及模型的轻量化等方
- 困境是磨难也是礼物
静默小太阳
艰难的2020年刚刚过去,疫情的反弹让2021年的开年也变得不那么顺利。但这也不全是坏事,很多事情,是磨难也是馈赠。《总有一天你会变成自己喜欢的样子》这本书中观点:困难就是礼物。不要觉得这句话老套,其实很少有人能记住它,并把它贯彻在生活中。人类学家做过这样的设想:如果人类在诞生之初便衣食无忧,不必为生存而奋斗,不经历磨难和挫折,那么直到今天,人类文明可能还处于原始的蒙昧年代。世界的大局就是这样,对
- 让员工成为“野鸭”,才是对员工真正的爱
9019429cf8b5
据说,IBM的宗旨之一是“珍视员工”。事实也的确如此,IBM拥有大量高工龄员工,这在日本或许较为常见,但美国的职场潜规则是“跳槽越多,身价越高”,所以说,IBM员工的平均工龄算是相当长的了。在阐述IBM公司宗旨的文件中,有这样一个寓言故事。在某个北国湖畔,住着一位心地善良的老人。每年冬天,一群野鸭都会飞来过冬。不知从何时起,那位善良的老人养成了给聚集在湖面的野鸭喂食的习惯。野鸭们也渐渐变得亲近老人
- 如何倾听
华青娱
几乎所有男人都认为女人的话太多,意思是指女人抢走了他们说话的机会。许多女人错误地认为,听男人说话就是默不作声地坐在那里,耐心地听男人说个没完。其实,听人说话也要表现出积极的态度,如果你是一个善于倾听的人,就会在适当的时刻加入到谈话当中去。倾听别人谈话,首先要集中精力。眼睛不能飘移不定,或神色紧张、坐立不安。如果你真的能集中思想,或许还能学到许多东西。倾听别人谈话的时候,表情要尽量放松,而且要随着对
- 常见商业问题及其金刚解药
琪言瑾语
周二(11月9日)早5:00,第26期能断金刚读书会,我们开始共读《能断金刚》第13期:第七章《因果关联》——常见“商业问题”及其“金刚解药”。(第6-9问题:书100-102页)。本次共读的核心内容如下:1.商业问题6:公司的员工和管理阶层人员似乎总是在闹意见。商业问题7:你老是对你的生意伙伴心生不满;不论你如何改变他们,你们之间总是一再地发生争执。金刚解药6/7:你必须小心谨慎,绝对不要发表任
- 光缆弹性模量计算_光纤光缆布线基础知识及系统设计
weixin_39542111
光缆弹性模量计算
光纤作为高带宽、高安全的数据传输介质被广泛应用于各种大中型网络之中。由于线缆和设备造价昂贵,光纤大多只被用于网络主干,即应用于垂直主干子系统和建筑群子系统的系统布线,实现楼宇之间以及楼层之间的连接,目前也应用于对传输速率和安全性有较高要求的水平布线子系统。一、光纤1、光及其特性:1)光是一种电磁波可见光部分波长范围是:390~760nm(毫微米)。大于760nm部分是红外光,小于390nm部分是紫
- Matlab实现的二维框架非线性动力学求解器:几何非线性应用
悦闻闻
本文还有配套的精品资源,点击获取简介:二维框架非线性动力学求解器Matlab工具用于分析复杂结构在动态载荷作用下的行为,特别是在几何非线性效应显著的情况下。求解器采用Newmark方法进行数值积分,并通过多个Matlab脚本文件,如Newmark_Nonlinear.m和Analysis.m等,实现从加载条件到结果可视化的一系列计算流程。用户可以通过各种分析功能和示例深入了解结构在动态载荷下的响应
- 读名老中医之路笔记(一)岳美中:无恒难以做医生
weixin_33937499
岳美中:无恒难以做医生岳美中先生虽然处于流离颠沛的年代中,通过不断的刻苦学习,终成一代名医。岳老从《衷中参西录》、《歌头汤诀》、《药性赋》一路走到《伤寒论》《金匮要略》,后又学习唐代祛疾利器《千金》、《外台》等书,他的读书经验:一、对中华古典文化的学习,培养读书的能力和习惯二、读书宁涩勿滑,对经典著作每个字句要读懂掌握,强调对经典著作熟读甚至必须背诵三、自学必当知道自己的短处,每个人都有他的优点,
- 从零开始:Android自定义相机应用开发全解析
悦闻闻
本文还有配套的精品资源,点击获取简介:本文深入探讨了在Android平台上开发自定义相机应用的核心技术要点,包括权限申请、创建预览界面、掌握CameraAPI、初始化相机、设置预览回调、拍照和视频录制、处理相机事件、界面交互设计、兼容性测试及性能优化。通过逐步实践这些知识点,开发者可以定制出符合特定需求的相机应用,并确保其在多种Android设备上的表现。1.Android自定义照相机权限与界面创
- 人脸数目统计系统实现:基于OpenCV和C++的人脸识别
本文还有配套的精品资源,点击获取简介:本项目介绍如何利用OpenCV库和C++语言开发一个人脸识别系统,用于统计图像中的人脸数量。内容涵盖人脸识别的基本原理、关键步骤及技术细节,包括使用Haar级联分类器进行人脸检测,并通过C++编程实现从图像处理到人脸统计的全过程。1.人脸识别基本原理与步骤人脸识别技术已经在安全验证、智能家居、社交媒体等多个领域得到了广泛应用。其基本原理是通过分析人脸图像中的特
- Java Swing组件鼠标拖拽功能实现
悦闻闻
本文还有配套的精品资源,点击获取简介:本文详细介绍了如何在JavaSwing中实现鼠标拖拽功能,这是一个构建桌面应用程序的常见需求。文章深入探讨了涉及的事件处理、组件交互和GUI设计方面,包括MouseListener和MouseMotionListener接口的具体应用。实现拖拽功能的关键步骤和方法被详尽地讲解,包括鼠标事件的记录、拖拽距离的计算和组件状态的更新。同时,还涉及了数据传输、事件传播
- Docker-Compose配置文件docker-compose.yml详解
高压锅_1220
dockerdockerdocker-compose容器配置文件容器
一份标准的docker-compose.yml文件应该包含version、services、networks三大部分,其中最关键的就是services和networks两个部分。Compose和Docker兼容性:Compose文件格式有3个版本,分别为1,2.x和3.x目前主流的为3.x其支持docker1.13.0及其以上的版本#目前主流的为3.x其支持docker1.13.0及其以上的版本,
- Github库镜像到本地私有Gitlab服务器
Thinbug
版本控制githubgitlab
上一节我们看了如何架设自己的Gitlab服务器,今天我们看怎么把Github库转移到自己的Gitlab上。首先登录github,进入自己的库复制地址。克隆镜像库在本地新建一个文件夹在文件夹执行CMD指令
[email protected]:thinbug/A.git–mirror参数就是拉取镜像库。拉取结束,进入目录:cdA.git我们可以看到这个库是这样的。添加远程库通过
- 中韩医美市场观察及政策法律分析(下)
This_is_刘小白
通过本文您将了解以下内容~一、什么是医美二、全球医美发展现状及发展格局三、为什么选择韩国作为研究对比的国家四、中韩医美市场观察五、中韩医美政策立法对比分析以下是正文~上篇已经跟大家介绍了什么是医美,全球医美发展现状及发展格局是什么样的状况以及对于中韩医美市场的观察。下篇将跟大家介绍韩国医美产业快速发展、成熟的动因,中韩两国在医美立法监管层面的异同以及两国在医美广告法律制度上的差异。一、韩国医美产业
- Realsense D435i 使用说明
D435i驱动安装及ROS使用Ubuntu16.04适配https://blog.csdn.net/lemonxiaoxiao/article/details/107834936过程中遇到fatalerror;需要添加标签。使用下面网址的博客解决了。https://blog.csdn.net/xuzhengzhe/article/details/135407342最终如下:target_compi
- 半夜姐姐屋进小偷,男子抓捕时捅死小偷,是正当防卫吗?如何处罚
一丝不苟的法律人
“半夜姐姐屋里进了小偷,姐姐妹妹都在家,我抓小偷,是正当防卫?抓的过程中虽然小偷死了,但是也不能判我11年?”凌晨4时小偷蒙面进入男子姐姐房中,被发现后,小偷躲到床底,男子找到小偷后,欲抓住小偷,遭到反抗,男子持刀捅了小偷腹部致死。这天凌晨4时许,被害人李涛蒙面潜入王强家中盗窃财物。王强和父亲、姐姐、妹妹正在家中睡觉。李涛进入住在二楼的姐姐王红的房间翻找东西时惊醒了姐姐王红,被王红喝问后跑出去,王
- 基于MATLAB的空时编码技术(源码+万字报告+部署讲解等)
炳烛之明科技
matlab人工智能网络通信仿真
目录基于MATLAB的空时编码技术论文IIAbstractIII第1章绪论11.1选题的背景与选题意义11.1.1选题的背景11.1.2选题的意义21.2论文现状21.3主要内容5第2章空时编码技术72.1空时分组码72.2空时网格码102.3分层空时码112.4三种码及空时分组码优点12第三章STBC空时分组码123.1基本原理123.2编码方法153.2.1两发多收天线系统的空时分组编码方法1
- Django母婴商城项目实践(一) - 母婴商城项目介绍
ITB业生
Djangodjango数据库python
1、母婴商城项目介绍1、项目需求分析需求归纳网站提供的搜索功能搜索结果展示:根据销量、价格、上架时间和收藏数量进行排序商品详情展示:商品尺寸、原价、活动价、图片展示、收藏功能与购买功能购买后的订单信息:包含支付金额、购买时间、订单状态等商品购买的在线支付方式:支付宝、微信、银行卡等功能商品库存管理:SKU(StockKeepingUnit,库存量单位)与SPU(StandardProductUni
- Docker应用推荐个人服务器实用有趣的项目推荐
牧子与羊
docker服务器容器
Wallabag:是一个开源的、自托管的文章阅读和保存工具。它允许你保存网页文章并进行离线阅读,去除广告和不必要的内容,以提供更好的阅读体验。Wallabag支持多种导入和导出格式,并提供了一些实用的功能,如标签、阅读列表和文本高亮。phpMyAdmin:是一个基于Web的MySQL数据库管理工具。它提供了一个易于使用的界面,用于管理数据库、执行SQL查询、导入导出数据、创建表格、用户管理等各种数
- 贫瘠而丰富的一天(2022.9.22)
琳言自语
星期四,天气阴雨健康为首:8小时睡眠,饮食有度。每月休养期。有闲有趣:小打卡。好的天气,坏的天气,如果能够有人陪伴,一同分享,每一天,都适合去爱或相爱。阅读。看了一些关于极简,降级消费的文集。清理物欲,整理人生,让物来服务我们的生活,而不是被其束缚。一直以来,从购物到择偶,都是偏向经济适用型,现在越发不在意别人的眼光,舒适过好自己就好了。亲子。下周小宝将进行国旗下讲话,今天和他一起拟好了稿子。身边
- 心灵寄语16篇
串珠小哒人
2019.1.5《心灵寄语》第16篇。大家好,我是张冰泽,今天我来说一下,我对丧三年,常悲咽,居处变,酒肉绝,丧尽礼,祭尽诚,事死者,如事生的理解,首先,丧三年,常悲咽就是,在父母去世的时候,在古代呢,有守孝三年的礼仪,我们要常常追思,感怀父母教养的恩德,自己的生活要简朴,你不要吃喝玩乐,不要饮酒作乐,丧尽礼,祭尽诚就是办理父母的丧事,要合乎礼法,不可以草率,不可以马虎。也不能为了面子铺张浪费。祭
- Git 核心操作全解析:从忽略规则到分支实战
越来越无动于衷
elasticsearch大数据搜索引擎
本文结合真实命令行操作记录,深度拆解Git核心功能:忽略文件配置、变更暂存与对比、分支管理、冲突解决及Stash临时工作流,帮你建立从“会用命令”到“理解原理”的完整认知。一、忽略文件:.gitignore配置1.1为什么需要.gitignore?排除日志文件、编译产物、临时文件、编辑器配置等无需版本控制的内容;避免这些文件出现在gitstatus的“未跟踪文件”列表,保持仓库整洁。1.2语法规则
- django母婴商城实训报告
傲娇御小剑
djangopython后端
实训内容:完成django项目:母婴商城一:对这个项目进行了可行性分析一、项目建议书通过批复后或者项目建议与项目可行性阶段进行合并后,项目建设单位应该开展项目可行性研究方面的工作。二、项目可行性研究内容一般应包括如下内容:投资必要性技术可行性财务可行性组织可行性经济可行性社会可行性风险因素及对策三、项目可行性研究阶段,包括:机会可行性研究:主要任务是对投资项目或投资方向提出建议,并对各种设想的项目
- 小思(一)
珠夏
小时候写作文,总是喜欢命题作文,不喜欢自由作文,原因很简单,命题作文我起码知道我写什么,而自由作文就像是什么都可以却又什么都没得写我们习惯了带着镣铐在一定范围内跳舞,而不是随心所欲,因为我们有太多顾忌,而不能够充分表达自己。久而久之我们都快丧失了这种能力。但我们对现状不满,想要改变它,于是,我们大声疾呼,我们大声呼喊着自由,可是真的当自由给你的时候,你手足无措,根本没有你想象中的那种快乐和解脱,就
- 做一个有温度的幼儿教师
读读看看写写
——读《做有温度的教育》有感梅子青转紫时间匆匆,在这个因疫情延长的假期里,白天的时间给了工作和孩子,晚上更多的时间留给自己。随着夜幕的来临,静下心的时间也多了些许。细细品读着叙事者团队推荐的本月书目——方华局长的《做有温度的教育》。让我看到了一位教育者前辈的坚守,那份对自己永恒使命的坚守,对教育信仰的坚守。众览全书,他以人性为出发点的教育价值观——做温暖人心的教育,无不让人打心底敬仰。何为“有温度
- 如何做让90后跟随你
孙万笑SWX
1.管理者首先要一碗水端平,让员工觉得你没有偏心,才是真正做到一碗水端平,同一件事多问问不同人的意见看法,从不同的角度看待问题,然后总结做决定。2.多往自己的情感账户存钱,少取钱,这样可以提升号召力,凝聚团队的执行力。3.凡事以身作则,以自身出发去影响其他人,来确保团队的执行力。
- Python-Zstandard 使用教程
Python-Zstandard使用教程项目介绍Python-Zstandard是一个为Zstandard(zstd)压缩库提供Python绑定的开源项目。Zstandard是一种由Facebook开发的高性能数据压缩算法,旨在提供高压缩比和快速压缩解压速度。Python-Zstandard项目的目标是通过一个Pythonic的接口,提供对底层CAPI的丰富访问,同时不牺牲性能。项目地址:GitH
- 京东优惠劵,你真的会用吗?揭秘获得京东优惠劵的全攻略
优惠券高省
如果你已经加入了十几个京东优惠群,那么你可能已经意识到,找到真正有用的优惠券并不容易。那么,如何才能有效地领取京东优惠券呢?【高省】APP(高佣金领导者)是一个自用省钱佣金高,分享推广赚钱多的平台,2000万用户信赖的四年老平台,稳定可靠。高省APP佣金更高,模式更好,终端用户不流失。高省是公认的返利最高的软件。古楼导师高省邀请码555888,注册送2皇冠会员,送万元推广大礼包,教你如何1年做到百
- SFT:大型语言模型专业化定制的核心技术体系——原理、创新与应用全景
大千AI助手
人工智能Python#OTHER语言模型人工智能自然语言处理深度学习机器学习微调SFT
本文由「大千AI助手」原创发布,专注用真话讲AI,回归技术本质。拒绝神话或妖魔化。搜索「大千AI助手」关注我,一起撕掉过度包装,学习真实的AI技术!以下基于权威期刊、会议论文及技术报告,对监督微调(SupervisedFine-Tuning,SFT)的技术框架、创新方法与实际应用进行系统梳理:一、核心定义与技术原理基本概念SFT是在预训练语言模型(如GPT、BERT)基础上,利用标注数据集对模型进
- 枚举的构造函数中抛出异常会怎样
bylijinnan
javaenum单例
首先从使用enum实现单例说起。
为什么要用enum来实现单例?
这篇文章(
http://javarevisited.blogspot.sg/2012/07/why-enum-singleton-are-better-in-java.html)阐述了三个理由:
1.enum单例简单、容易,只需几行代码:
public enum Singleton {
INSTANCE;
- CMake 教程
aigo
C++
转自:http://xiang.lf.blog.163.com/blog/static/127733322201481114456136/
CMake是一个跨平台的程序构建工具,比如起自己编写Makefile方便很多。
介绍:http://baike.baidu.com/view/1126160.htm
本文件不介绍CMake的基本语法,下面是篇不错的入门教程:
http:
- cvc-complex-type.2.3: Element 'beans' cannot have character
Cb123456
springWebgis
cvc-complex-type.2.3: Element 'beans' cannot have character
Line 33 in XML document from ServletContext resource [/WEB-INF/backend-servlet.xml] is i
- jquery实例:随页面滚动条滚动而自动加载内容
120153216
jquery
<script language="javascript">
$(function (){
var i = 4;$(window).bind("scroll", function (event){
//滚动条到网页头部的 高度,兼容ie,ff,chrome
var top = document.documentElement.s
- 将数据库中的数据转换成dbs文件
何必如此
sqldbs
旗正规则引擎通过数据库配置器(DataBuilder)来管理数据库,无论是Oracle,还是其他主流的数据都支持,操作方式是一样的。旗正规则引擎的数据库配置器是用于编辑数据库结构信息以及管理数据库表数据,并且可以执行SQL 语句,主要功能如下。
1)数据库生成表结构信息:
主要生成数据库配置文件(.conf文
- 在IBATIS中配置SQL语句的IN方式
357029540
ibatis
在使用IBATIS进行SQL语句配置查询时,我们一定会遇到通过IN查询的地方,在使用IN查询时我们可以有两种方式进行配置参数:String和List。具体使用方式如下:
1.String:定义一个String的参数userIds,把这个参数传入IBATIS的sql配置文件,sql语句就可以这样写:
<select id="getForms" param
- Spring3 MVC 笔记(一)
7454103
springmvcbeanRESTJSF
自从 MVC 这个概念提出来之后 struts1.X struts2.X jsf 。。。。。
这个view 层的技术一个接一个! 都用过!不敢说哪个绝对的强悍!
要看业务,和整体的设计!
最近公司要求开发个新系统!
- Timer与Spring Quartz 定时执行程序
darkranger
springbean工作quartz
有时候需要定时触发某一项任务。其实在jdk1.3,java sdk就通过java.util.Timer提供相应的功能。一个简单的例子说明如何使用,很简单: 1、第一步,我们需要建立一项任务,我们的任务需要继承java.util.TimerTask package com.test; import java.text.SimpleDateFormat; import java.util.Date;
- 大端小端转换,le32_to_cpu 和cpu_to_le32
aijuans
C语言相关
大端小端转换,le32_to_cpu 和cpu_to_le32 字节序
http://oss.org.cn/kernel-book/ldd3/ch11s04.html
小心不要假设字节序. PC 存储多字节值是低字节为先(小端为先, 因此是小端), 一些高级的平台以另一种方式(大端)
- Nginx负载均衡配置实例详解
avords
[导读] 负载均衡是我们大流量网站要做的一个东西,下面我来给大家介绍在Nginx服务器上进行负载均衡配置方法,希望对有需要的同学有所帮助哦。负载均衡先来简单了解一下什么是负载均衡,单从字面上的意思来理解就可以解 负载均衡是我们大流量网站要做的一个东西,下面我来给大家介绍在Nginx服务器上进行负载均衡配置方法,希望对有需要的同学有所帮助哦。
负载均衡
先来简单了解一下什么是负载均衡
- 乱说的
houxinyou
框架敏捷开发软件测试
从很久以前,大家就研究框架,开发方法,软件工程,好多!反正我是搞不明白!
这两天看好多人研究敏捷模型,瀑布模型!也没太搞明白.
不过感觉和程序开发语言差不多,
瀑布就是顺序,敏捷就是循环.
瀑布就是需求、分析、设计、编码、测试一步一步走下来。而敏捷就是按摸块或者说迭代做个循环,第个循环中也一样是需求、分析、设计、编码、测试一步一步走下来。
也可以把软件开发理
- 欣赏的价值——一个小故事
bijian1013
有效辅导欣赏欣赏的价值
第一次参加家长会,幼儿园的老师说:"您的儿子有多动症,在板凳上连三分钟都坐不了,你最好带他去医院看一看。" 回家的路上,儿子问她老师都说了些什么,她鼻子一酸,差点流下泪来。因为全班30位小朋友,惟有他表现最差;惟有对他,老师表现出不屑,然而她还在告诉她的儿子:"老师表扬你了,说宝宝原来在板凳上坐不了一分钟,现在能坐三分钟。其他妈妈都非常羡慕妈妈,因为全班只有宝宝
- 包冲突问题的解决方法
bingyingao
eclipsemavenexclusions包冲突
包冲突是开发过程中很常见的问题:
其表现有:
1.明明在eclipse中能够索引到某个类,运行时却报出找不到类。
2.明明在eclipse中能够索引到某个类的方法,运行时却报出找不到方法。
3.类及方法都有,以正确编译成了.class文件,在本机跑的好好的,发到测试或者正式环境就
抛如下异常:
java.lang.NoClassDefFoundError: Could not in
- 【Spark七十五】Spark Streaming整合Flume-NG三之接入log4j
bit1129
Stream
先来一段废话:
实际工作中,业务系统的日志基本上是使用Log4j写入到日志文件中的,问题的关键之处在于业务日志的格式混乱,这给对日志文件中的日志进行统计分析带来了极大的困难,或者说,基本上无法进行分析,每个人写日志的习惯不同,导致日志行的格式五花八门,最后只能通过grep来查找特定的关键词缩小范围,但是在集群环境下,每个机器去grep一遍,分析一遍,这个效率如何可想之二,大好光阴都浪费在这上面了
- sudoku solver in Haskell
bookjovi
sudokuhaskell
这几天没太多的事做,想着用函数式语言来写点实用的程序,像fib和prime之类的就不想提了(就一行代码的事),写什么程序呢?在网上闲逛时发现sudoku游戏,sudoku十几年前就知道了,学生生涯时也想过用C/Java来实现个智能求解,但到最后往往没写成,主要是用C/Java写的话会很麻烦。
现在写程序,本人总是有一种思维惯性,总是想把程序写的更紧凑,更精致,代码行数最少,所以现
- java apache ftpClient
bro_feng
java
最近使用apache的ftpclient插件实现ftp下载,遇见几个问题,做如下总结。
1. 上传阻塞,一连串的上传,其中一个就阻塞了,或是用storeFile上传时返回false。查了点资料,说是FTP有主动模式和被动模式。将传出模式修改为被动模式ftp.enterLocalPassiveMode();然后就好了。
看了网上相关介绍,对主动模式和被动模式区别还是比较的模糊,不太了解被动模
- 读《研磨设计模式》-代码笔记-工厂方法模式
bylijinnan
java设计模式
声明: 本文只为方便我个人查阅和理解,详细的分析以及源代码请移步 原作者的博客http://chjavach.iteye.com/
package design.pattern;
/*
* 工厂方法模式:使一个类的实例化延迟到子类
* 某次,我在工作不知不觉中就用到了工厂方法模式(称为模板方法模式更恰当。2012-10-29):
* 有很多不同的产品,它
- 面试记录语
chenyu19891124
招聘
或许真的在一个平台上成长成什么样,都必须靠自己去努力。有了好的平台让自己展示,就该好好努力。今天是自己单独一次去面试别人,感觉有点小紧张,说话有点打结。在面试完后写面试情况表,下笔真的好难,尤其是要对面试人的情况说明真的好难。
今天面试的是自己同事的同事,现在的这个同事要离职了,介绍了我现在这位同事以前的同事来面试。今天这位求职者面试的是配置管理,期初看了简历觉得应该很适合做配置管理,但是今天面
- Fire Workflow 1.0正式版终于发布了
comsci
工作workflowGoogle
Fire Workflow 是国内另外一款开源工作流,作者是著名的非也同志,哈哈....
官方网站是 http://www.fireflow.org
经过大家努力,Fire Workflow 1.0正式版终于发布了
正式版主要变化:
1、增加IWorkItem.jumpToEx(...)方法,取消了当前环节和目标环节必须在同一条执行线的限制,使得自由流更加自由
2、增加IT
- Python向脚本传参
daizj
python脚本传参
如果想对python脚本传参数,python中对应的argc, argv(c语言的命令行参数)是什么呢?
需要模块:sys
参数个数:len(sys.argv)
脚本名: sys.argv[0]
参数1: sys.argv[1]
参数2: sys.argv[
- 管理用户分组的命令gpasswd
dongwei_6688
passwd
NAME: gpasswd - administer the /etc/group file
SYNOPSIS:
gpasswd group
gpasswd -a user group
gpasswd -d user group
gpasswd -R group
gpasswd -r group
gpasswd [-A user,...] [-M user,...] g
- 郝斌老师数据结构课程笔记
dcj3sjt126com
数据结构与算法
<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<
- yii2 cgridview加上选择框进行操作
dcj3sjt126com
GridView
页面代码
<?=Html::beginForm(['controller/bulk'],'post');?>
<?=Html::dropDownList('action','',[''=>'Mark selected as: ','c'=>'Confirmed','nc'=>'No Confirmed'],['class'=>'dropdown',])
- linux mysql
fypop
linux
enquiry mysql version in centos linux
yum list installed | grep mysql
yum -y remove mysql-libs.x86_64
enquiry mysql version in yum repositoryyum list | grep mysql oryum -y list mysql*
install mysq
- Scramble String
hcx2013
String
Given a string s1, we may represent it as a binary tree by partitioning it to two non-empty substrings recursively.
Below is one possible representation of s1 = "great":
- 跟我学Shiro目录贴
jinnianshilongnian
跟我学shiro
历经三个月左右时间,《跟我学Shiro》系列教程已经完结,暂时没有需要补充的内容,因此生成PDF版供大家下载。最近项目比较紧,没有时间解答一些疑问,暂时无法回复一些问题,很抱歉,不过可以加群(334194438/348194195)一起讨论问题。
----广告-----------------------------------------------------
- nginx日志切割并使用flume-ng收集日志
liyonghui160com
nginx的日志文件没有rotate功能。如果你不处理,日志文件将变得越来越大,还好我们可以写一个nginx日志切割脚本来自动切割日志文件。第一步就是重命名日志文件,不用担心重命名后nginx找不到日志文件而丢失日志。在你未重新打开原名字的日志文件前,nginx还是会向你重命名的文件写日志,linux是靠文件描述符而不是文件名定位文件。第二步向nginx主
- Oracle死锁解决方法
pda158
oracle
select p.spid,c.object_name,b.session_id,b.oracle_username,b.os_user_name from v$process p,v$session a, v$locked_object b,all_objects c where p.addr=a.paddr and a.process=b.process and c.object_id=b.
- java之List排序
shiguanghui
list排序
在Java Collection Framework中定义的List实现有Vector,ArrayList和LinkedList。这些集合提供了对对象组的索引访问。他们提供了元素的添加与删除支持。然而,它们并没有内置的元素排序支持。 你能够使用java.util.Collections类中的sort()方法对List元素进行排序。你既可以给方法传递
- servlet单例多线程
utopialxw
单例多线程servlet
转自http://www.cnblogs.com/yjhrem/articles/3160864.html
和 http://blog.chinaunix.net/uid-7374279-id-3687149.html
Servlet 单例多线程
Servlet如何处理多个请求访问?Servlet容器默认是采用单实例多线程的方式处理多个请求的:1.当web服务器启动的