Redis开发与运维读书笔记-第二章-字符串数据类型介绍(二)
下面从redis几种数据结构的角度来进行理解:
一.字符串
字符串是redis数据类型的基础,首先键都是字符串类型.字符串类型的值实际可以是字符串(简单的字符串、复杂的字符串(例如JSON、XML))、数字(整数、浮点数),甚至是二进制(图片、音频、视频),但是值最大不能超过512MB。
(一) 相关命令
常用命令:
(1)设置值(set key value [ex seconds] [px milliseconds] [nx|xx])
set key value [ex seconds] [px milliseconds] [nx|xx]下面操作设置键为hello,值为world的键值对,返回结果为OK代表设置成功:
127.0.0.1:6379> set hello world
OKset命令有几个选项:
·ex seconds:为键设置秒级过期时间。
·px milliseconds:为键设置毫秒级过期时间。
·nx:键必须不存在,才可以设置成功,用于添加。
·xx:与nx相反,键必须存在,才可以设置成功,用于更新。
除了set选项,Redis还提供了setex和setnx两个命令:它们的作用和ex和nx选项是一样的。下面的例子说明了set、setnx、set xx的区别。

setnx和setxx在实际使用中有什么应用场景吗?以setnx命令为例子,由于 Redis的单线程命令处理机制,如果有多个客户端同时执行setnx key value, 根据setnx的特性只有一个客户端能设置成功,setnx可以作为分布式锁的一种 实现方案,Redis官方给出了使用setnx实现分布式锁的方法:http://redis.io/topics/distlock
(2)获取值(get key)

(3)批量设置值(mset key value [key value ...])
下面操作通过mset命令一次性设置4个键值对:
127.0.0.1:6379> mset a 1 b 2 c 3 d 4
OK(4)批量获取值(mget key [key ...])
下面操作批量获取了键a、b、c、d的值:
127.0.0.1:6379> mget a b c d
1) "1"
2) "2"
3) "3"
4) "4"如果有些键不存在,那么它的值为nil(空),结果是按照传入键的顺序返回
127.0.0.1:6379> mget a b c f
1) "1"
2) "2"
3) "3"
4) (nil)要注意的是每次批 量操作所发送的命令数不是无节制的,如果数量过多可能造成Redis阻塞或者网络拥塞。
(5)计数(incr key)
incr命令用于对值做自增操作,返回结果分为三种情况:
·值不是整数,返回错误。
·值是整数,返回自增后的结果。
·键不存在,按照值为0自增,返回结果为1,继续对该键进行自增,返回2。
除了incr命令,Redis提供了decr(自减)、incrby(自增指定数字)、 decrby(自减指定数字)、incrbyfloat(自增浮点数)
不常用命令:
(1)追加值(append key value)
append可以向字符串尾部追加值,例如:
127.0.0.1:6379> get key "redis"
127.0.0.1:6379> append key world (integer) 10
127.0.0.1:6379> get key "redisworld"
(2)字符串长度(strlen key)
例如,当前值为redisworld,所以返回值为10:
127.0.0.1:6379> get key
"redisworld"
127.0.0.1:6379> strlen key
(integer) 10下面操作返回结果为6,因为每个中文占用3个字节
127.0.0.1:6379> set hello "世界"
OK
127.0.0.1:6379> strlen hello
(integer) 6(3)设置并返回原值(getset key value)
getset和set一样会设置值,但是不同的是,它同时会返回键原来的值,例如:
127.0.0.1:6379> getset hello world
(nil)
127.0.0.1:6379> getset hello redis
"world"
(4)设置指定位置的字符(setrange key offeset value)
下面操作将值由pest变为了best:
127.0.0.1:6379> set redis pest
OK
127.0.0.1:6379> setrange redis 0 b
(integer) 4
127.0.0.1:6379> get redis
"best"(5)获取部分字符串(getrange key start end)
start和end分别是开始和结束的偏移量,偏移量从0开始计算,例如下面操作获取了值best的前两个字符。
127.0.0.1:6379> getrange redis 0 1
"be小结:
设值:set name zhangsan (说明:多次设置name会覆盖)
命令:
setnx name lx: (not exist) 如果name不存在,则设值。如果name存在,则不设值并返回0;
setex name 10 lx :(expired) 设置name的值为lx,过期时间为10秒,10秒后name清除(key也清除)
setrange string range value 替换字符串
取值: get name
删值:del name
批量写:mset k1 v1 k2 v2 ...
批量读:mget k1 k2 k3
一次性设值和读取(返回旧值,写上新值):getset name lx
数值类型自增减:incr,decr,incrby,decrby
字符串拼接:append key value
字符串长度:strlen key(二)内部编码
字符串类型的内部编码有3种:
·int:8个字节的长整型。
·embstr:小于等于39个字节的字符串。
·raw:大于39个字节的字符串。
Redis会根据当前值的类型和长度决定使用哪种内部编码实现。
整数类型示例如下:
127.0.0.1:6379> set key 8653
OK
127.0.0.1:6379> object encoding key
"int"短字符串示例如下:
#小于等于39个字节的字符串:embstr
127.0.0.1:6379> set key "hello,world"
OK
127.0.0.1:6379> object encoding key
"embstr"长字符串示例如下:
#大于39个字节的字符串:raw
127.0.0.1:6379> set key "one string greater than 39 byte........."
OK
127.0.0.1:6379> object encoding key "raw"
127.0.0.1:6379> strlen key
(integer) 40(三)典型使用场景
1.缓存功能
下图是比较典型的缓存使用场景,其中Redis作为缓存层,MySQL作 为存储层,绝大部分请求的数据都是从Redis中获取。由于Redis具有支撑高并发的特性,所以缓存通常能起到加速读写和降低后端压力的作用.
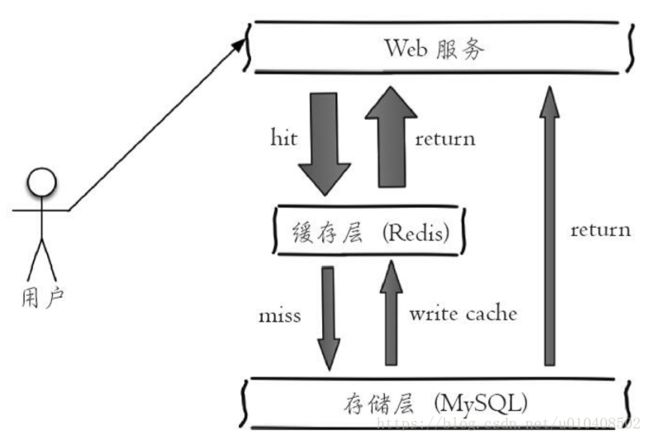
下面伪代码模拟上图的访问过程:
1)该函数用于获取用户的基础信息:
UserInfo getUserInfo(long id){ ... }2)首先从Redis获取用户信息
// 定义键
userRedisKey = "user:info:" + id;
// 从Redis获取值
value = redis.get(userRedisKey);
if (value != null) {
// 将值进行反序列化为UserInfo并返回结果
userInfo = deserialize(value);
return userInfo;
}
3)如果没有从Redis获取到用户信息,需要从MySQL中进行获取,并将 结果回写到Redis,添加1小时(3600秒)过期时间:
// 从MySQL获取用户信息
userInfo = mysql.get(id);
// 将userInfo序列化,并存入Redis
redis.setex(userRedisKey, 3600, serialize(userInfo));
// 返回结果
return userInfo
整个功能的伪代码如下:
UserInfo getUserInfo(long id){
userRedisKey = "user:info:" + id ;
value = redis.get(userRedisKey);
UserInfo userInfo;
if (value != null) {
userInfo = deserialize(value);
} else {
userInfo = mysql.get(id);
if (userInfo != null)
redis.setex(userRedisKey, 3600, serialize(userInfo));
}
return userInfo;
}2.计数
许多应用都会使用Redis作为计数的基础工具,它可以实现快速计数、查询缓存的功能,同时数据可以异步落地到其他数据源。例如有的视频播放数系统就是使用Redis作为视频播放数计数的基础组件,用户每 播放一次视频,相应的视频播放数就会自增1:
long incrVideoCounter(long id) {
key = "video:playCount:" + id;
return redis.incr(key);
}
3.共享Session
如下图所示,一个分布式Web服务将用户的Session信息(例如用户登录信息)保存在各自服务器中,这样会造成一个问题,出于负载均衡的考虑,分布式服务会将用户的访问均衡到不同服务器上,用户刷新一次访问可能会发现需要重新登录,这个问题是用户无法容忍的
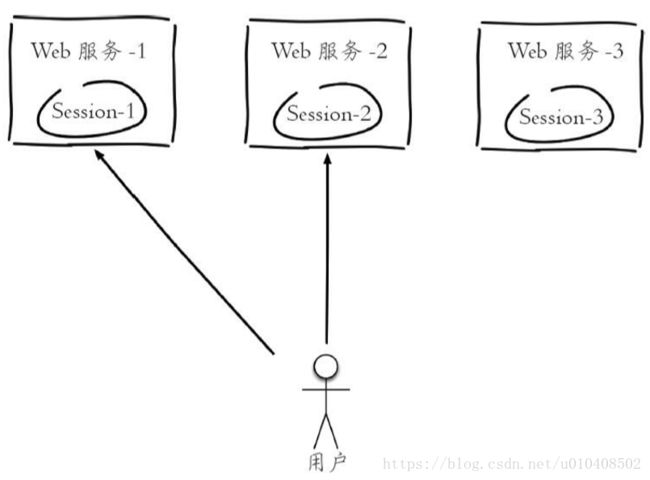
为了解决这个问题,可以使用Redis将用户的Session进行集中管理,如下图所示,在这种模式下只要保证Redis是高可用和扩展性的,每次用户 更新或者查询登录信息都直接从Redis中集中获取。
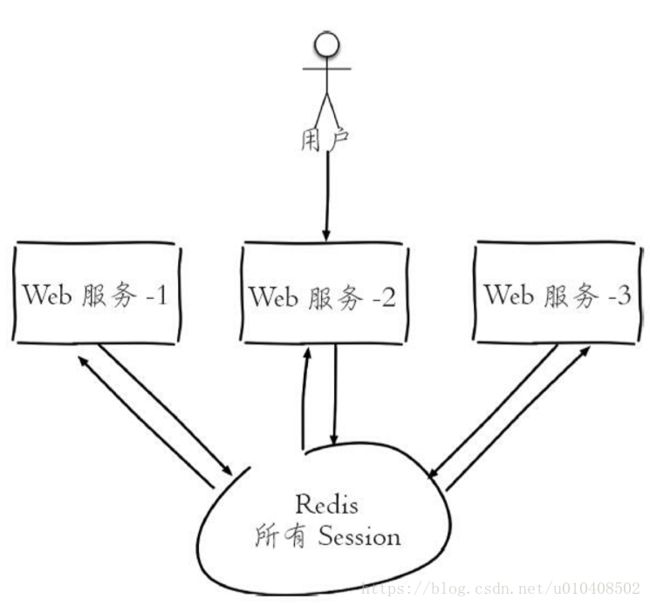
4.限速
很多应用出于安全的考虑,会在每次进行登录时,让用户输入手机验证码,从而确定是否是用户本人。但是为了短信接口不被频繁访问,会限制用 户每分钟获取验证码的频率,例如一分钟不能超过5次,此功能可以使用Redis来实现,下面的伪代码给出了基本实现思路:
phoneNum = "138xxxxxxxx";
key = "shortMsg:limit:" + phoneNum;
// SET key value EX 60 NX
isExists = redis.set(key,1,"EX 60","NX");
if(isExists != null || redis.incr(key) <=5){
// 通过
}else{
// 限速
}上述就是利用Redis实现了限速功能,例如一些网站限制一个IP地址不 能在一秒钟之内访问超过n次也可以采用类似的思路