如何将数据从Hadoop导出到关系型和NoSQL数据库?
数据库通常是Hadoop数据输出的目标之一,企业通常将数据移回生产数据库以供生产系统使用,或者将数据移动到OLAP数据库以执行商业智能和分析功能。
(注:本文为《Hadoop从入门到精通》大型专题的第五章内容,本专题的其他文章见文末链接,专题的上半部也将于不久之后与大家见面,请持续关注本专题!)
5.3.3 数据库
本节,我们将使用Apache Sqoop将数据从Hadoop导出到MySQL数据库。Sqoop是一种简单的数据库导入和导出工具。我们会介绍将数据从HDFS导出到Sqoop的过程。我们还将介绍使用常规连接器的方法,以及如何使用快速连接器执行批量导入。
实践:使用Sqoop将数据导出到MySQL
Hadoop擅长与大多数关系型数据库打交道,因此将OLTP数据提取到HDFS,执行一些分析,然后将其导出回数据库是很常见的。
问题
希望将数据写入关系数据库,同时确保写入是幂等的。
解决方案
此技术介绍了如何使用Sqoop将文本文件导出到关系数据库,还介绍了如何配置Sqoop以使用具有自定义字段和记录分隔符的文件。我们还将介绍幂等导出,以确保失败的导出不会使数据库处于不一致状态。
讨论
这种技术假设已经安装MySQL并创建模式。
Sqoop导出要求导出数据库表已存在,Sqoop可以支持表中行的插入和更新。
将数据导出到数据库共享
我们在导入部分检查的许多参数,不同之处在于export需要使用--export-dir参数来确定要导出的HDFS目录,还将为导出创建另一个选项文件,以防止在命令行上不安全地提供密码:

第一步是将数据从MySQL导出到HDFS,以确保有一个良好的起点,如以下命令所示:

Sqoop导入的结果是HDFS中有许多CSV文件,可以在以下代码中看到:

对于从HDFS到MySQL的Sqoop导出,将指定目标表应该是stocks_export并且应该从HDFS库目录导出数据:

默认情况下,Sqoop导出将对目标数据库表执行INSERT,可以使用--update-mode参数支持更新。值updateonly意味着如果没有匹配的密钥,更新将失败。如果匹配的键不存在,则allowInsert的值将直接插入。用于执行更新的表列名称在--update-key参数中提供。
以下示例表明只应使用主键尝试更新:

输入数据格式
可以使用多个选项覆盖用于解析输入数据的默认Sqoop设置,表5.7列出了这些选项。

表5.7 输入数据的格式选项
幂等输出
执行输出的Sqoop map任务使用多个事务进行数据库写入。如果Sqoop导出MapReduce作业失败,则表可能包含部分写入。对于幂等数据库写入,可以指示Sqoop执行MapReduce写入临时表。成功完成作业后,临时表将在单个事务中移动到目标表,该事务是幂等的,可以在图5.19中看到事件顺序。
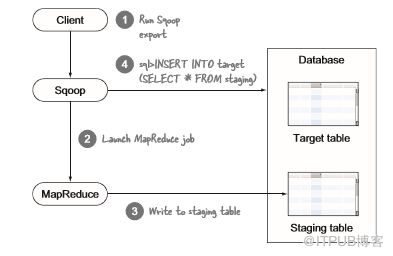
图5.19 Sqoop分段事件序列,有助于确保幂等输出
在下面的示例中,临时表是stocks_staging,还告诉Sqoop在MapReduce作业以--clear-staging-table参数启动之前清除它:

直接输出
在导入技术中使用快速连接器,这是使用mysqldump实用程序的优化。Sqoop导出也支持使用mysqlimport工具的快速连接器。与mysqldump一样,集群中的所有节点都需要安装mysqlimport,并且在用于运行MapReduce任务的用户路径中可用。与导入一样, - diand参数可以使用快速连接器:

使用mysqlimport进行幂等输出
Sqoop不支持将快速连接器与临时表结合使用,这就是使用常规连接器实现幂等输入的方法。但是仍然可以通过快速连接器实现幂等输入,并在最后进行一些额外的工作。需要使用快速连接器写入临时表,然后触发INSERT语句,该语句将数据原子复制到目标表中,步骤如下所示:
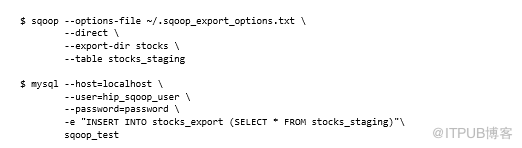
这打破了关于在命令行上公开凭证的早期规则,但是编写可以从配置文件中读取这些设置的脚本很容易。
总结
与使用MapReduce中提供的DBInputFormat格式类相比,Sqoop提供了简化的使用模型。但是,使用DBInputFormat类将为在执行数据库导出的同一MapReduce作业中转换或预处理数据提供额外的灵活性。Sqoop的优点是不需要编写任何代码,并且有一些有用的概念,比如分段,以帮助实现幂等。
5.3.4 NoSQL
MapReduce是一种将数据批量加载到外部系统的强大而有效的方法。到目前为止,我们已经介绍了如何使用Sqoop加载关系数据,现在我们将看看NoSQL系统,特别是HBase。
Apache HBase是一个分布式key/value,面向列的数据存储。在本章的前半部分,我们研究了如何将HBase中的数据导入HDFS,以及如何将HBase用作MapReduce作业的数据源。将数据加载到HBase的最有效方法是通过其内置的批量加载机制,但是这种方法绕过了预写日志(WAL),这意味着正在加载的数据不会复制到从属HBase节点。
HBase还附带了一个org.apache.hadoop.hbase.mapreduce.Export类,它将从HDFS加载HBase表,类似于本章前面的幂等输出工作方式。但是,我们必须以SequenceFile形式提供数据,这种方式有缺点,包括不支持版本控制,可以在自己的MapReduce作业中使用TableOutputFormat类将数据导出到HBase,但这种方法比批量加载工具慢。
我们现在已经完成了对Hadoop输出工具的检查。我们介绍了如何使用HDFS File Slurper将数据移出到文件系统以及如何使用Sqoop对关系数据库进行幂等输入,我们总结了将Hadoop数据输入HBase的方法。
5.4 本章总结
将数据移入和移出是Hadoop架构的关键部分。本章,我们介绍了可用于执行数据输入和输出以及与各种数据源一起使用的各种技术。值得注意的是,我们介绍了Flume,一种数据收集和分发解决方案,Sqoop,一种用于将关系数据移入和移出Hadoop的工具,以及Camus,一种用于将Kafka数据导入HDFS的工具。现在,是时候查看一些可应用于数据的有趣处理模式。
相关文章:
1、《第一章:Hadoop生态系统及运行MapReduce任务介绍!》链接: http://blog.itpub.net/31077337/viewspace-2213549/
2、《学习Hadoop生态第一步:Yarn基本原理和资源调度解析!》链接: http://blog.itpub.net/31077337/viewspace-2213602/
3、《MapReduce如何作为Yarn应用程序运行?》链接: http://blog.itpub.net/31077337/viewspace-2213676/
4、《Hadoop生态系统各组件与Yarn的兼容性如何?》链接: http://blog.itpub.net/31077337/viewspace-2213960/
5、《MapReduce数据序列化读写概念浅析!》链接: http://blog.itpub.net/31077337/viewspace-2214151/
6、《MapReuce中对大数据处理最合适的数据格式是什么?》链接: http://blog.itpub.net/31077337/viewspace-2214325/
7、《如何在MapReduce中使用SequenceFile数据格式?》链接: http://blog.itpub.net/31077337/viewspace-2214505/
8、《如何在MapReduce中使用Avro数据格式?》链接: http://blog.itpub.net/31077337/viewspace-2214709/
9、《企业自有数据格式杂乱,MapReduce如何搞定?》链接: http://blog.itpub.net/31077337/viewspace-2214826/
10、《企业使用Hadoop的重大挑战:如何在HDFS中组织和使用数据?》链接: http://blog.itpub.net/31545816/viewspace-2215158/ 》
11、《如何在HDFS中进行数据压缩以实现高效存储?》链接: http://blog.itpub.net/31545816/viewspace-2215281/
12、《Hadoop数据传输:如何将数据移入和移出Hadoop?》链接: http://blog.itpub.net/31545816/viewspace-2215580/
13、《如何将日志和二进制文件连续移入HDFS?》链接: http://blog.itpub.net/31545816/viewspace-2215948/
14、《如何将传统关系数据库的数据导入Hadoop?》链接: http://blog.itpub.net/31545816/viewspace-2216000/
来自 “ ITPUB博客 ” ,链接:http://blog.itpub.net/31545816/viewspace-2216458/,如需转载,请注明出处,否则将追究法律责任。
转载于:http://blog.itpub.net/31545816/viewspace-2216458/