CS231n 图像分类
图像分类
- 目标:
- 例子
- 困难和挑战
- 图像分类流程
- Nearest Neighbor分类器
- k-Nearest Neighbor分类器
- 用于超参数调优的验证集
- Nearest Neighbor分类器的优劣
- 小结
目标:
就是在已有固定的分类标签集合,然后对于输入的图像,从分类标签集合中找出一个分类标签,最后把分类标签分配给该输入图像
例子
以下图为例,图像分类模型读取该图片,并生成该图片属于集合{dog,cat,hat,mug}中各个标签的概率。对于计算机来说,图像是一个由数字组成的巨大的三维数组,图像大小分别有自己对应的像素,并且有三个颜色通道,分别是红、绿和蓝(RGB)。每个数字是8bit,即2^8=256个数,每个数字范围是0-255,其中0是全黑,255表示全白。我们的任务就是把这些上百万的数字变成一个简单的标签,比如猫。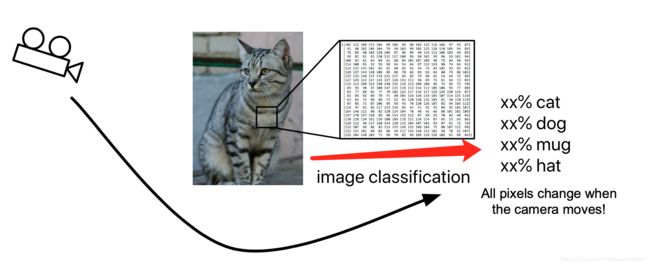
困难和挑战
1、大小变化(Scale variation):物体可视的大小通常会变化
2、视角变化(Viewpoint variation):摄像机可以从多个角度来展现同一物体
3、形变(Deformation):很多东西的形状并非一成不变,会有很大的变化
4、光照条件(Illumination conditions):在像素层面上,光照的影响很大
5、遮挡(Occlusion):目标物体可能被挡住。有时候只有物体的一小部分
6、背景干扰(Background clutter):物体可能混入背景之中,使之难以被辨认
7、类内差异(intra-class variation):一类物体的个体之间的外形差异很大,比如椅子。这一类物体有很多不同的对象,每个都有自己的外形
图像分类流程
图像分类就是输入一个元素为像素值的数组,然后给它分配一个分类标签。完整流程如下:
1、输入:输入是包含N个图像的集合,每个图像的标签是K种分类标签中的一种。这个集合称为训练集(收集图像和标签的数据集)
2、学习:这一步的任务是使用训练集来学习每个类到底长什么样。一般该步骤叫做训练分类器或者学习一个模型(使用机器学习训练分类器)
3、评价:让分类器来预测它未曾见过的图像的分类标签,并以此来评价分类器的质量。我们会把分类器预测的标签和图像真正的分类标签对比。分类器预测的分类标签和图像真正的分类标签如果一致,那就是好事,这样的情况越多越好,准确率也会越来越高。(评估新图像上的分类器)
Nearest Neighbor分类器
图像分类数据集:CIFAR-10。这个数据集包含了60000张32X32的小图像。每张图像都有10种分类标签中的一种。这60000张图像被分为包含50000张图像的训练集和包含10000张图像的测试集。在下图中你可以看见10个类的10张随机图片
左边:从CIFAR-10数据库来的样本图像。右边:第一列是测试图像,然后第一列的每个测试图像右边是使用Nearest Neighbor算法,根据像素差异,从训练集中选出的10张最类似的图片。Nearest Neighbor算法将会拿着测试图片和训练集中每一张图片去比较,然后将它认为最相似的那个训练集图片的标签赋给这张测试图片。
L1距离: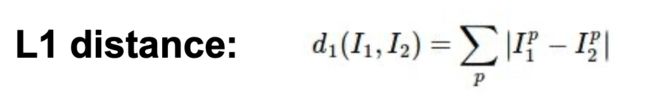
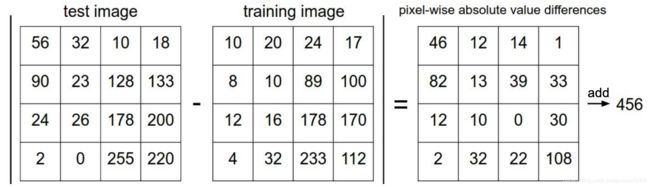
import numpy as np
class NearestNeighbor:
def _init_(self):
pass
def train(self,X,y):
self.Xtr = X
self.ytr = y
def predict(self,X):
num_test = X.shape[0]
Ypred = np.zeros(num_test,dtype = self.ytr.dtype)
for i in xrange(num_test):
distances = np.sum(np.abs(self.Xtr - X[i,:]),axis = 1)
min_index = np.argmin(distances)
Ypred[i] = self.ytr[min_index]
return Ypred
L2距离:
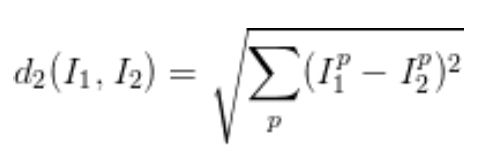
__L1和L2的比较:__在面对两个向量之间的差异时,L2比L1更加不能容忍这些差异,也就是说,相对于1个巨大的差异,L2距离更加倾向于接受多个中等程度的差异
k-Nearest Neighbor分类器
找最相似的k个图片的标签,然后让他们针对测试图片进行投票,最后把票数最高的标签作为对测试图片的预测。从直观感受上可以看到,更高的k值可以让分类的效果更平滑,使得分类器对于异常值更有抵抗力。(注:k值并不是越大越好,因为更大的k会减慢检验结果的过程)

上述不同颜色区域代表的是使用L2距离的分类器的决策边界。白色的区域是分类模糊的例子。5-NN分类器将一些不规则都平滑了,使得它针对测试数据的泛化能力更好。
用于超参数调优的验证集
k-NN分类器需要设定k值,那么需要k值的选择,同时也需要对L1和L2的进行选择。所有这些选择,被称为__超参数(Hyperparameters)__
以CIFAR-10为例,我们可以用49000个图像作为训练集,用1000个图像作为验证集。验证集其实就是作为假的测试集来调优的。代码如下
Xval_rows = Xtr_rows[:1000, :] # take first 1000 for validation Yval = Ytr[:1000]
Xtr_rows = Xtr_rows[1000:, :] # keep last 49,000 for train
Ytr = Ytr[1000:]
validation_accuracies = []
for k in [1, 3, 5, 10, 20, 50, 100]:
# use a particular value of k and evaluation on validation data
nn = NearestNeighbor()
nn.train(Xtr_rows, Ytr)
acc = np.mean(Yval_predict == Yval)
print 'accuracy: %f' % (acc,)
# keep track of what works on the validation set
validation_accuracies.append((k, acc))
程序结束后,我们会作图分析出哪个k值最好,然后用k值来跑真正的测试集,并作出对算法的评价。
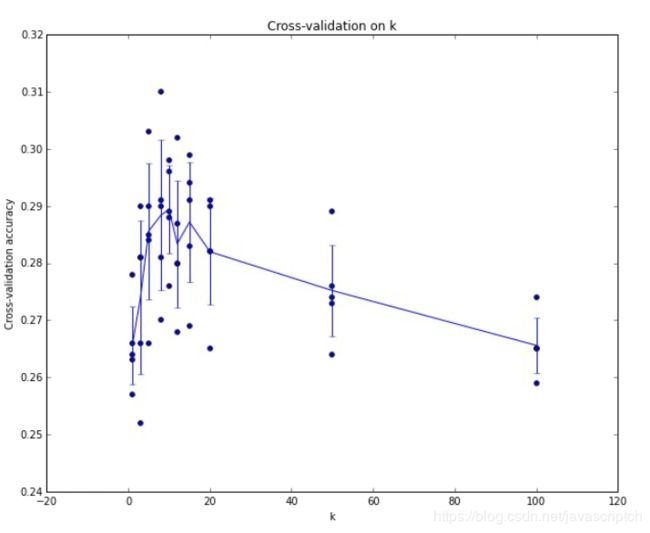
__交叉验证:__有时候训练集数量较小,人们会使用一种被称为交叉验证的方法。我们就不是取1000个图像,而是将训练集平均分成5份,其中4份用来训练,1份用来验证。然后我们循环着取其中4份来训练,其中1份来验证,最后取所有5次验证结果的平均值作为算法验证结果。下图是5份交叉验证对k值调优的例子。
Nearest Neighbor分类器的优劣
__优点:__易于理解,实现简单。其次,算法的训练不需要花时间,因为其训练过程只是将训练集数据存储起来。
缺点:测试要花费大量时间计算,因为每个测试图像需要和所有存储的训练图像进行比较
小结
1、介绍了图像分类问题,在该问题中,给出一个由被标注了分类标签的图像组成的集合,要求算法能预测没有标签的图形的分类标签,并根据算法预测准确率进行评价
2、介绍了一个简单的图像分类器:最近邻分类器 。分类器中存 在不同的超参数 比如 值或距离类型的选取 ,要想选取好的超参数不是一件轻而易举的事。
3、选取超参数的正确方法是:将原始训练集分为训练集和验证集,我们在验证集上尝试不同的 超参数,最后保留表现最好那个。
4、如果训练数据量不够,使用交叉验证方法,它能帮助我们在选取最优超参数的时候减少噪音。
5、一旦找到最优的超参数,就让算法以该参数在测试集跑且只跑一次,并根据测试结果评价算法。
6、最近邻分类器能够在CIFAR-10上得到将近40%的准确率。该算法简单易实现,但需要存储 所有训练数据,并且在测试的时候过于耗费计算能力。
7、最后,我们知道了仅仅使用L1和L2范数来进行像素比较是不够的,图像更多的是按照背景和 颜色被分类,而不是语义主体分身。