AudioTrack播放音频的流程
之前从事手机方案开发的时候对Audio这块只有个大概的印象,并没有去仔细地看过。
当播放音乐的时候,尤其是缓冲音频数据时,我们会用到AudioTrack类。
首先得new一个对象出来,
AudioTrack mPlayer = new AudioTrack(3, 44100, AudioFormat.CHANNEL_IN_STEREO, AudioFormat.ENCODING_PCM_16BIT, mTrackBufflen, 1);
先来看下这个初始化函数中做了哪些事情。主要位于android_media_AudioTrack.cpp中的setup()函数中。
1.获取当前对应设备的frame size和sample rate
2.检查输入的参数正确性,如声道、pcm位数
3.初始化一个AudioTrack对象` sp lpTrack = new AudioTrack();
4.这里出现两个类型的源:MODE_STREAM和MODE_STATIC,
STREAM的意思是由用户在应用程序通过write方式把数据一次一次得写到audiotrack中。这个和我们在socket中发送数据一样,应用层从某个地方获取数据,例如通过编解码得到PCM数据,然后write到audiotrack。
这种方式的坏处就是总是在JAVA层和Native层交互,效率损失较大。
而STATIC的意思是一开始创建的时候,就把音频数据放到一个固定的buffer,然后直接传给audiotrack,后续就不用一次次得write了。AudioTrack会自己播放这个buffer中的数据。
`
5.调用AudioTrack.cpp中的set函数。
在set函数中,主要处理的地方有以下几点
5.1 通过aps获取当前情景模式下的输出profile。
5.2 打开对应的output,
这里先把一大堆的什么Thread之类的简单介绍下,反正我已经晕了:
*一个AudioTrack会new一个MixedThread/DirectOutputThread之类的对象,然后他打开的output拥有一个mPlaybackThreads变量,里面加入了所有的new出来的MixedThread/DirectOutputThread之类的对象,具体干活的是这些子Thread。
一个AudioTrack对象会有一个Track对象
通过下面的类图可以看到父类RecordThread和PlaybackThread是最主要的。这两个Thread会有一个mTracks数组对象包含了所有的Track对象,还有一个mActiveTrack来代表当前哪个是正在活动的Track。PlaybackThread额外有一个mActiveTracks来保存当前active的Track队列,可能是混音时需要一层层叠加吧*
output = mpClientInterface->openOutput(profile->mModule->mHandle,
&outputDesc->mDevice,
&outputDesc->mSamplingRate,
&outputDesc->mFormat,
&outputDesc->mChannelMask,
&outputDesc->mLatency,
outputDesc->mFlags,
offloadInfo);audio_io_handle_t output = AudioSystem::getOutput(
streamType,
sampleRate, format, channelMask,
flags,
offloadInfo);
5.2.1 调用AF中的
audio_io_handle_t AudioFlinger::openOutput()
{
****省略****
status_t status = hwDevHal->open_output_stream(hwDevHal,
id,
*pDevices,
(audio_output_flags_t)flags,
&config,
&outStream);**//5.2.1.1**
if (status == NO_ERROR && outStream != NULL) {
****省略****
thread = new DirectOutputThread(this, output, id, *pDevices);**//5.2.1.2**
****省略****
} else {
thread = new MixerThread(this, output, id, *pDevices);
ALOGV("openOutput() created mixer output: ID %d thread %p", id, thread);
}
mPlaybackThreads.add(id, thread);**//5.2.1.2**
}
5.2.1.1 此时会找到真正对应的profile中处理的函数,具体如果是默认状态下回是audio_hw.c
out = (struct stub_stream_out *)calloc(1, sizeof(struct stub_stream_out));实际工作就是创建了一个包含该流参数和一些控制函数的结构体。
5.2.1.2 new 一个MixerThread并加入mPlaybackThreads,这里涉及到各种不同种类的thread。附上一张图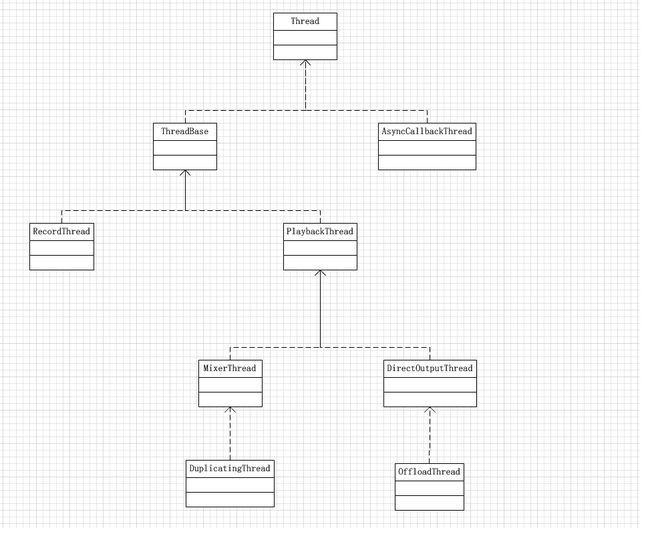
5.3 开始创建属于自己的真正的Track。
status_t status = createTrack_l(streamType,
sampleRate,
format,
frameCount,
flags,
sharedBuffer,
output,
0 /*epoch*/)实际调用audioFlinger->createTrack()函数。
PlaybackThread *thread = checkPlaybackThread_l(output);
track = thread->createTrack_l(client, streamType, sampleRate, format,
channelMask, frameCount, sharedBuffer, lSessionId, flags, tid, clientUid, &lStatus);
trackHandle = new TrackHandle(track);
return trackHandle;//AudioTrack通过trackHandle来操作Track对象AF中获取到刚才我们加入进去的MixerThread对象(注意DirectOutputThread和他的区别),并调用createTrack_l()
track = new Track(this, client, streamType, sampleRate, format,
channelMask, frameCount, sharedBuffer, sessionId, uid, *flags);
mTracks.add(track);在PlaybackThread类和RecordThread类中分别都有一个变量 SortedVector< sp > mTracks; 这里的Track类实现在Tracks.cpp中。
AudioTrack对象初始化好之后,接下来是play(),等待数据写入。
这个函数最终会调用到Tracks.cpp中的AudioFlinger::PlaybackThread::Track类中的start()。
status_t AudioFlinger::PlaybackThread::Track::start(AudioSystem::sync_event_t event,
int triggerSession)
{
PlaybackThread *playbackThread = (PlaybackThread *)thread.get();
status = playbackThread->addTrack_l(this);
}这里调用了这个track所属的mixedthread的addTrack_l函数,我们会发现在该函数里,将这个Track加入了mActiveTracks。
然后调用broadcast_l()通知正在等待的线程。(mWaitWorkCV是信号量)
这个通知的最终接收者就是刚才我们new出来的MixedThread,(但是我还没找到这个线程是从什么时候开始跑的。。。)这里有个循环,会一直接收write()捡来的数据。
具体的步骤见如下注释:
bool AudioFlinger::PlaybackThread::threadLoop()
{
ALOGV("%s going to sleep", myName.string());
mWaitWorkCV.wait(mLock);
ALOGV("%s waking up", myName.string());
mMixerStatus = prepareTracks_l(&tracksToRemove);
//当发现mix过程返回ready的话,正式开始mix
if (mMixerStatus == MIXER_TRACKS_READY) {
// threadLoop_mix() sets mCurrentWriteLength
threadLoop_mix();
} else if ((mMixerStatus != MIXER_DRAIN_TRACK)
&& (mMixerStatus != MIXER_DRAIN_ALL)) {
// threadLoop_sleepTime sets sleepTime to 0 if data
// must be written to HAL
threadLoop_sleepTime();
if (sleepTime == 0) {
mCurrentWriteLength = mixBufferSize;
}
}
//处理好了,可以写入output了
threadLoop_write();
}prepareTracks_l()是个庞大的函数。。反正我已经晕了。主要是遍历每个当前playthread中的active track,当一个track的最小buffer数据已经ready的话,就让AudioMixer干活将声音混合在一起,最后得到一个可以播放的声音吧。
for (size_t i=0 ; i<count ; i++) {
const sp<Track> t = mActiveTracks[i].promote();
if ((framesReady >= minFrames) && track->isReady() &&
!track->isPaused() && !track->isTerminated())
{
mAudioMixer->setBufferProvider(name, track);
mAudioMixer->enable(name);
mAudioMixer->setParameter(name, param, AudioMixer::VOLUME0, (void *)vl);
mAudioMixer->setParameter(name, param, AudioMixer::VOLUME1, (void *)vr);
mAudioMixer->setParameter(name, param, AudioMixer::AUXLEVEL, (void *)va);
mAudioMixer->setParameter(
name,
AudioMixer::TRACK,
AudioMixer::FORMAT, (void *)track->format());
mAudioMixer->setParameter(
name,
AudioMixer::TRACK,
AudioMixer::CHANNEL_MASK, (void *)track->channelMask());
}
}当数据READY的时候,调用threadLoop_mix(),这里分为两个不同的sink,没仔细看,可能是不同类型的设置吧。。。
if (mNormalSink != 0) {
status = mNormalSink->getNextWriteTimestamp(&pts);
} else {
status = mOutputSink->getNextWriteTimestamp(&pts);
}
if (status != NO_ERROR) {
pts = AudioBufferProvider::kInvalidPTS;
}
// mix buffers...
mAudioMixer->process(pts);这里的process(pts)是一个回调函数,应该是先调用我们在mix的enable()时设置的process__validate函数.
void AudioMixer::process__validate(state_t* state, int64_t pts)
{
while (en) {
const int i = 31 - __builtin_clz(en);
en &= ~(1<state->tracks[i];
//设置各个track不同类型的处理函数。
if ((n & NEEDS_MUTE__MASK) == NEEDS_MUTE_ENABLED) {
t.hook = track__nop;
} else {
if ((n & NEEDS_AUX__MASK) == NEEDS_AUX_ENABLED) {
all16BitsStereoNoResample = false;
}
if ((n & NEEDS_RESAMPLE__MASK) == NEEDS_RESAMPLE_ENABLED) {
all16BitsStereoNoResample = false;
resampling = true;
t.hook = track__genericResample;
ALOGV_IF((n & NEEDS_CHANNEL_COUNT__MASK) > NEEDS_CHANNEL_2,
"Track %d needs downmix + resample", i);
} else {
if ((n & NEEDS_CHANNEL_COUNT__MASK) == NEEDS_CHANNEL_1){
t.hook = track__16BitsMono;
all16BitsStereoNoResample = false;
}
if ((n & NEEDS_CHANNEL_COUNT__MASK) >= NEEDS_CHANNEL_2){
t.hook = track__16BitsStereo;
ALOGV_IF((n & NEEDS_CHANNEL_COUNT__MASK) > NEEDS_CHANNEL_2,
"Track %d needs downmix", i);
}
}
//设置接下来要调用到的处理函数
state->hook = process__nop;
if (countActiveTracks) {
if (resampling) {
if (!state->outputTemp) {
state->outputTemp = new int32_t[MAX_NUM_CHANNELS * state->frameCount];
}
if (!state->resampleTemp) {
state->resampleTemp = new int32_t[MAX_NUM_CHANNELS * state->frameCount];
}
state->hook = process__genericResampling;
} else {
if (state->outputTemp) {
delete [] state->outputTemp;
state->outputTemp = NULL;
}
if (state->resampleTemp) {
delete [] state->resampleTemp;
state->resampleTemp = NULL;
}
state->hook = process__genericNoResampling;
if (all16BitsStereoNoResample && !volumeRamp) {
if (countActiveTracks == 1) {
state->hook = process__OneTrack16BitsStereoNoResampling;
}
}
}
//调用各自track的处理函数
state->hook(state, pts);
} 关于怎么处理混音的部分,很多参数我看不懂,随便看一个吧
void AudioMixer::process__OneTrack16BitsStereoNoResampling(state_t* state,
int64_t pts)
{
while (numFrames) {
//取write下来的数据并保存
t.bufferProvider->getNextBuffer(&b, outputPTS);
//释放原先的数据
t.bufferProvider->releaseBuffer(&b);
}
}最后处理完之后,就调用 threadLoop_write(),后面就是hal层的事情了。
bytesWritten = mOutput->stream->write(mOutput->stream,
mMixBuffer + offset, mBytesRemaining);做好这些工作后,接下来就是往里写数据了,我们使用write()方法,对应writeToTrack()。如果是STREAM方式初始化AudioTrack的话,sharedBuffer() 是返回0的,反之则不同。
jint writeToTrack(const sp<AudioTrack>& track, jint audioFormat, jbyte* data,
jint offsetInBytes, jint sizeInBytes) {
// regular write() or copy the data to the AudioTrack's shared memory?
if (track->sharedBuffer() == 0) {
written = track->write(data + offsetInBytes, sizeInBytes);
} else {
memcpy(track->sharedBuffer()->pointer(), data + offsetInBytes, sizeInBytes);
}
return written;
这里的buffer就是会被上面所说的循环取到的,具体的共享未看。