《算法图解》学习笔记
《算法图解》学习笔记
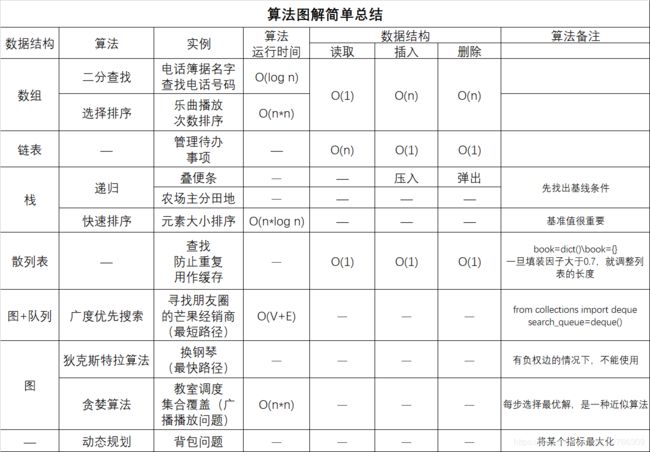
- 第一章 算法简介(二分查找,大O表示法)
- 第二章 选择排序(数组和链表,选择排序)
- 第三章 递归(递归,栈)
- 第一节 递归
- 第二节 栈
- 第四章 快速排序(分而治之,快速排序,合并算法)
- 第一节 分而治之(divide and conquer,递归式问题解决方法)
- 第二节 快速排序(一种分而治之的算法)
- 第三节 合并算法
- 第五章 散列表
- 第一节 散列函数
- 第二节 应用案例
- 第三节 冲突(collision)
- 第四节 性能
- 第六章 广度优先搜索(图,最短路径,队列)
- 第七章 狄克斯特拉算法(加权图,最快路径,环)
- 第八章 贪婪算法(教室调度问题,背包问题,集合覆盖问题,NP完全问题)
- 第九章 动态规划
- 第一节 背包问题
- 第二节 最长公共子串
- 第十章 K最近邻算法(特征,回归,机器学习简介)
- 第十一章 接下来如何做(树,反向索引,傅里叶变换,并行算法,MapReduce,布隆过滤器,SHA算法,局部敏感的散列算法,密钥交换,线性规划)
第一章 算法简介(二分查找,大O表示法)
- 二分查找:输入是一个有序的元素列表
- 大O表示法:指出了算法运行时间的增速(是最糟情况下的运行时间)
大O表示法省略其中的常数:其中的n其实是c*n,c为算法固定的时间量,称为常量。
//二分查找法
import numpy as np
def binary_search(a,item):
low=0
high=len(a)-1
while low<=high:
//检查中间的元素
mid=int((low+high)/2)
guess=a[mid]
//根据大小修改数字
if guess == item:
return mid
if guess > item:
high=mid-1
else:
low=mid+1
return None
a=[1,3,7,8,9]
print(binary_search(a,3))
第二章 选择排序(数组和链表,选择排序)
- 数组(随机访问):所有数据在内存中都是相连的。
优点:随机读取元素时,数组效率很高
缺点:额外位置浪费内存+位置不够需转移数组 - 链表(顺序访问):每个元素都存储了下一个元素的地址
优点:插入元素方便+读取所有元素效率高
缺点:需要跳跃读取时效率很低
| 常见操作 | 数组 | 链表 |
|---|---|---|
| 读取 | O(1) | O(n) |
| 插入 | O(n) | O(1) |
| 删除 | O(n) | O(1) |
- 选择排序:运行时间O( n 2 n^2 n2):
//选择排序,数组元素从小至大排序
def findSmallest(arr):
smallest = arr[0]
smallest_index=0
for i in range(1,len(arr)):
if arr[i]<smallest:
smallest=arr[i]
smallest_index=i
return smallest_index
def selectionSort(arr):
newArr=[]
for i in range(len(arr)):
smallest=findSmallest(arr)
newArr.append(arr.pop(smallest))
return newArr
print (selectionSort([5,3,6,2,10]))
第三章 递归(递归,栈)
第一节 递归
- 递归:递归并没有性能上的优势,只是让解决方案更加的清晰
- 递归条件:函数调用自己
基线条件:函数不再调用自己的条件,避免形成无限循环
第二节 栈
- 调用栈(call stack):存储多个函数的变量,有压入和弹出两种操作
调用一个函数时,当前函数暂停并处于未完成状态,该函数所有变量的值都还在内存中。
def greet(name):
print ("hello")
greet2(name)
print("getting ready to say bye")
bye()
、、、、、
调用greet("me")时
1.为greet()分配内存
2.为greet2()调用内存,第二个内存块位于第一个内存块之上,完成这个函数后,栈顶的内存块被弹出
3.打印print,调用bye(),再次分配内存块在greet()内存块之上
、、、、
- 递归调用栈:存储详细的信息可能占用大量的内存,栈越高使用内存越多(可用尾递归解决)
def fact(x):
if x==1:
return 1
else:
return x*fact(x-1)
第四章 快速排序(分而治之,快速排序,合并算法)
第一节 分而治之(divide and conquer,递归式问题解决方法)
示例
- 农场主分田地:将一块地均匀的分成方块,分出的方块尽可能大
两个步骤:
(1)找出基线条件,条件尽可能简单
(2)不断将问题分解,直到符合基线条件 - 数组数字相加:将数组内所有数字相加
(1)基线条件
A.数组不包含任何元素,则总和为0
B.数组只包含一个元素,则总和为其元素本身
(2)每次递归调用都离空数组更近一点
计算列表中除第一个数字外的其它数字的总和,将其与第一个数字相加,再返回结果。
#习题:编写列表的和,计数,最大值
#数字总和
def sum(list):
if list==[]:
return 0
return list[0] + sum(list[1:])
#计数总和
def count(list):
if list==[]:
return 0
return 1+count(list[1:])
#最大值
def max(list):
if len(list) == 2:
return list[0] if list[0] >list[1] else list[1]
sub_max =max(list[1:])
return list[0] if list[0] >sub_max else sub_max
第二节 快速排序(一种分而治之的算法)
算法步骤
- 基线条件:数组为空或只包含一个元素
- 从数组中选择一个元素,这个元素被称为基准值(pivot)。可以将数组的第一个元素作为基准值,找出比基准值大和小的元素进行分区。
- 对两个子数组进行快速排序。
#快速排序
def quicksort(array):
if len(array)<2:
return array
else:
pivot=array[0]
less =[i for i in array[1:] if i<=pivot]
greater =[i for i in array[1:] if i>pivot]
return quicksort(less) +[pivot]+quicksort(greater)
print (quicksort([10,5,2,3]))
第三节 合并算法
- 大O表示法中的常量一般影响不大,但是对快速查找和合并查找的影响很大,对于简单查找和二分查找常量几乎无关紧要。
- 平均情况和最糟情况:跟栈的层数有关。在快速排序中,随机选择数组元素作为基准值,平均运行时间将为 O ( n ∗ l o g n ) O(n\ast\ logn) O(n∗ logn),在数组有序的情况下选择了第一个元素作为基准值,那么运行时间将会是最糟情况 O ( n ∗ n ) O(n\ast n) O(n∗n)
第五章 散列表
第一节 散列函数
引言:
- 数组和链表可以用于查找,栈不能用于查找(?)
- 如果想要查找的速度为O(1),那么就需要散列函数
散列函数:将输入映射到数字
例子:杂货店找商品的价格
- 散列函数需要满足的要求:
(1)必须是一致的
(2)将不同的输入映射到不同的数字 - 散列函数准确指出价格存储位置的原因
(1)散列函数总是将同样的输入映射到相同的索引
(2)散列函数将不同的输入映射到不同的索引
(3)散列函数直到数组有多大,只返回有效的索引
散列表:包含额外逻辑的数据结构,也被称为散列映射、映射、字典和关联数组。
数组和链表可以直接映射到内存,散列表使用散列函数确定元素的存储位置。
#python的散列表为字典
book=dict()
或
book={}
第二节 应用案例
- 用于查找(例子:创建电话簿)
课外:使用散列表让网址映射到IP地址,这个过程称为DNS解析 - 防止重复(例子:投票站投票)
#检查是否投过票
voted={}
def check_vote(name):
if voted.get(name):
print ("kick them out")
else:
voted[name]=Ture
print("let them vote")
- 用作缓存
缓存指网站将数据记住而不用重新计算
#访问facebook页面
cache={}
def get_page(url):
if cache.get(url):
return cache[url]
else:
data=get_data_from_server(url)
cache[url]=data
return data
第三节 冲突(collision)
- 定义:给两个键分配的位置相同。
- 处理方式:如果两个键映射到了一个位置,就在这个位置存储一个链表。
- 如何避免更多的冲突?
- 较低的填装因子:填装因子度量的是散列表中有多少位置是空的
(1)填装因子=散列表包含的元素数/位置总数
(2)一旦填装因子增大,就需要在散列表中添加位置,被称为调整长度。
(3)经验:一旦填装因子大于0.7,就调整列表的长度 - 良好的散列函数
良好的散列函数让数组中的值呈均匀分布(可研究一下SHA函数)
第四节 性能
散列表的性能
| 常见操作 | 平均情况 | 最糟情况 |
|---|---|---|
| 查找 | O(1) | O(n) |
| 插入 | O(1) | O(n) |
| 删除 | O(1) | O(n) |
第六章 广度优先搜索(图,最短路径,队列)
- 图:由节点和边组成,相邻的节点被称为邻居。
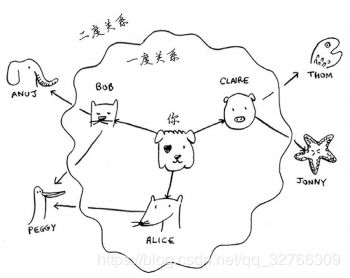
- 广度优先搜索(例子:寻找朋友圈中的芒果经销商)
在广度搜索的执行过程中,搜索范围从起点开始逐渐向外延伸,一度关系在二度关系加入之前加入查找名单。实现过程需要按添加顺序进行检查,可实现这种目的的数据结构为队列。
运行时间为 O ( V + E ) O(V+E) O(V+E)
- 队列:队列类似于栈,不能随机的访问队列中的元素
队列只支持入队和出队两种操作
队列是**先进先出(FIFO)的数据结构,栈是后进先出(LIFO)**的数据结构 - 实现图
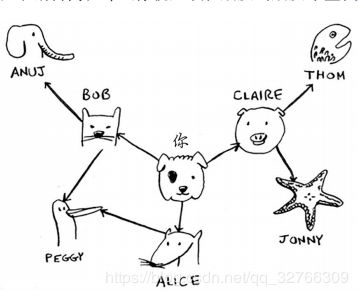
#每个节点与邻近节点相连,使用散列表结构
#散列表是无序的,添加键值对的顺序是无关紧要的
graph={}
graph["you"]=["alice","bob","claire"]
graph["bob"]=["anuj","peggy"]
graph["alice"]=["peggy"]
graph["claire"]=["thom","jonny"]
graph["anuj"]=[]
graph["peggy"]=[]
graph["thom"]=[]
graph["jonny"]=[]
#实现算法
from collections import deque
def search(name):
#创建队列
search_queue=deque()
#将邻居都加入这个搜索队列中
search_queue+=graph[name]
searched=[]
while search_queue:
#只要队列不为空就取出其中的第一个人
person =search_queue.popleft()
if person not in searched:
if person_is_seller(person):
print(person+" is a mango seller")
return True
else:
search_queue+=graph[person]
searched.append(person)
return False
#判断是不是芒果经销商
def person_is_seller(name):
return name[-1]=='m'
第七章 狄克斯特拉算法(加权图,最快路径,环)
- 狄克斯特拉算法步骤:
(1)找出最便宜的节点x
(2)计算经节点x前往其各个邻居所需的时间
(3)重复这个过程
(4)计算最终路径
狄克斯特拉算法只适用于有向无环图 - 案例:换钢琴,需要先找出钢琴的父节点
- 有负权边的情况下,不能使用狄克斯特拉算法,因为在第一步会处理掉更便宜的节点,节点一旦被处理,意味着没有前往该节点更便宜的途径。可以使用贝尔曼-福德算法。
- 实现算法:
#创建图的散列表
graph={}
graph["start"]={}
graph["start"]["a"]=6
graph["start"]["b"]=2
graph["a"]={}
graph["a"]["fin"]=1
graph["b"]={}
graph["b"]["a"]=3
graph["b"]["fin"]=5
graph["fin"]={}
#创建开销表,开销指从起点出发前往该节点需要多少时间
#表示无穷大
infinity=float("inf")
costs={}
costs["a"]=6
costs["b"]=2
costs["fin"]=infinity
#存储父节点的散列表
parents={}
parents["a"]="start"
parents["b"]="start"
parents["fin"]=None
#创建数组记录处理过的节点
processed=[]
#找出开销最小的节点
def find_lowest_cost_node(costs):
lowest_cost=float("inf")
lowest_cost_node=None
for node in costs:
cost=costs[node]
if cost<lowest_cost and node not in processed:
lowest_cost=cost
lowest_cost_node=node
return lowest_cost_node
node=find_lowest_cost_node(costs)
while node is not None:
cost=costs[node]
neighbors=graph[node]
for n in neighbors.keys():
new_cost=cost+neighbors[n]
if costs[n]>new_cost:
costs[n]=new_cost
parents[n]=node
processed.append(node)
node=find_lowest_cost_node(costs)
第八章 贪婪算法(教室调度问题,背包问题,集合覆盖问题,NP完全问题)
- 教室调度问题:将尽可能多的课程安排在某间教室上。
贪婪算法即每步都选择局部最优解,最终得到的就是全局最优解 - 背包问题:贪婪问题不能获得最优解
- 集合覆盖问题:让全美50个州都能收听到广播节目,每个广播台播出都需要支付费用,力图在尽可能少的广播台播出。每个广播台都覆盖特定的额区域,不同广播台的区域可能重叠。
使用贪婪算法的步骤:
(1)选出覆盖了最多未覆盖州的广播台
(2)重复第一步,直到覆盖了所有州。
在这个例子中,贪婪算法是一种近似算法,运行时间为 O ( n ∗ n ) O(n*n) O(n∗n)
#集合覆盖问题
#创建列表,包含要覆盖的州
#传入数组,转换为集合,因为集合不能包含重复的元素
states_needed=set(["mt","wa","or","id","nv","ut","ca","az"])
#可供选择的广播台,用散列表来表示
stations={}
stations["kone"]=set(["id","nv","ut"])
stations["ktwo"]=set(["wa","id","mt"])
stations["kthree"]=set(["or","nv","ca"])
stations["kfour"]=set(["nv","ut"])
stations["kfive"]=set(["ca","az"])
#使用集合来存储最终选择的广播台
final_stations=set()
while states_needed:
best_station=None
states_covered=set() #包含该广播台覆盖的所有未覆盖的州
for station,states in stations.items(): #返回可遍历的(键, 值) 元组数组。
covered=states_needed & states#计算交集
#检查该广播台覆盖的州是否比best_covered多
if len(covered)>len(states_covered):
best_station=station
states_covered=covered
states_needed-=states_covered
final_stations.add(best_station)
print(final_stations)
- NP完全问题(例子:旅行商问题):对于NP完全问题,还没有找到快速解决办法,最佳的做法是近似算法
第九章 动态规划
第一节 背包问题
- 简单算法:尝试各种可能的商品组合,并找出价值最高的组合,算法运行时间为 O ( 2 n ) O(2^n) O(2n)。
- 动态规划:动态规划先解决子问题,再解决大问题。
(1)当可以偷商品的一部分时,无法使用动态规划处理,可用贪婪算法处理。
(2)动态规划当且仅当每个子问题都是离散且不依赖于其它子问题时才管用。
(3)背包问题最终结果最多只需合并两个子背包,但子背包可能又包含子背包。
(4)动态规划可在给定约束条件下找到最优解。
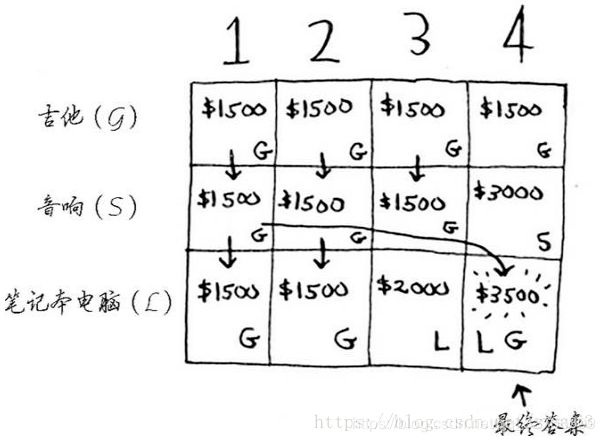
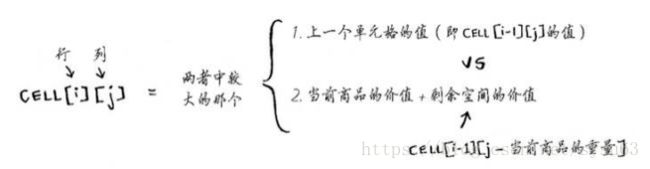
第二节 最长公共子串
- 最长公共子串
案例:寻找输错单词原本要输入的单词
步骤:
(1)单元格中的值是什么?字母是否相同,相同值为左上角邻居的值加1
(2)如何将这个问题划分为子问题?比较子串。
(3)网格的坐标轴是什么?单词的字母
在动态规划中,要将某个指标最大化 - 最长公共子序列:寻找两个单词中都有的序列包含的字母数。
- 编辑距离(拓展):拼写检查到用户上传的资料是否盗版。
第十章 K最近邻算法(特征,回归,机器学习简介)
- 特征抽取:计算两点间的距离,采用毕达哥拉斯公式。
- 回归(regression):在实际中计算距离时,一般使用余弦相似度公式,不比较两个矢量的距离,而是比较两个矢量的角度。
- 一般有N个用户,应该考虑sqrt(N)个邻居
- 机器学习:OCR,过滤垃圾邮件(朴素贝叶斯分类器)和预测股票市场。
第十一章 接下来如何做(树,反向索引,傅里叶变换,并行算法,MapReduce,布隆过滤器,SHA算法,局部敏感的散列算法,密钥交换,线性规划)
1.树:二分查找需要将新的用户名插入数组重新排序,如果无需插入后排序,可以使用二叉查找树。
(1)对于其中每一个节点,左子节点的值都比它小,而右子节点的值都比它大。
(2)二叉查找树不能随机访问。
| 常见操作 | 数组 | 二叉查找树 |
|---|---|---|
| 查找 | O ( log n ) O(\log n) O(logn) | O ( log n ) O(\log n) O(logn) |
| 插入 | O ( n ) O(n) O(n) | O ( log n ) O(\log n) O(logn) |
| 删除 | O ( n ) O(n) O(n) | O ( log n ) O(\log n) O(logn) |
- 反向索引:一个散列表,将单词映射到包含它的页面,这种数据结构叫做反向索引。
- 傅里叶变换:比喻给你一杯冰沙,傅里叶变换能告诉你其中包含哪些成分。
- 并行算法:算法的提升速度不是线性的,因为其并行性管理开销和负载均衡。
- MapReduce(一种分布式算法):基于映射函数和归并函数。
(1)映射函数:将一个数组转换为另一个数组
arr1=[1,2,3,4,5]
#将数组元素翻倍
arr2=map(lambda x: 2*x, arr1)
(2)归并函数:将一个数组转换为一个元素
arr1=[1,2,3,4,5]
#数组元素相加
reduce(lambda x,y:x+y,arr1)
- 布隆过滤器和HyperLoglog:查找网页时,散列表查找的时间虽短,但是搜索网站需要的散列表非常大,需要占用大量的存储空间。
(1)布隆过滤器:一种概率型数据结构,占用空间很少,但结果不一定完全准确。
可能出现错报,但不会出现漏报。
(2)HyperLoglog:近似的计算集合中不同的元素数,也无法给出准确的答案。 - SHA算法(安全散列算法):给定一个字符串,SHA返回其散列值。
(1)SHA是一个散列函数,生成一个散列值。创建散列表的散列函数根据字符串生成数组索引,SHA根据字符串生成另一个字符串。
(2)例子:比较文件、检查密码(根据这个算法的单向性,无法根据散列值推断原始字符) - 局部敏感的散列算法:使用Simhash,对字符串做细微的修改时,生成的散列值也只存在细微的差别,可以通过比较散列值来判断两个字符串的相似程度。
- Diffie-Hellman密钥交换:双方无需知道加密算法,加密后的消息只有使用私钥才能解密。
- 线性规划:用于在给定约束条件下最大限度的改善指定的指标。