一个简单易懂的多智能体强化学习建模过程的例子
这里基于一篇论文分享一种强化学习的建模过程,它是将通信当中的资源分配问题建立成强化学习方法,首先大概读一遍这个题目,叫“基于多智能体强化学习的无人机网络资源分配”,这里的network是通信网络不是神经网络,资源分配是指通信网络中,频谱资源、信道、带宽、天线功率等等是有限的,怎么管理这些资源来保证能够通信的同时优化整个网络吞吐量、功耗,这个就是网络资源分配。这里多智能体就是涉及博弈论的思想。主要内容是分析这篇论文的一个建模过程。

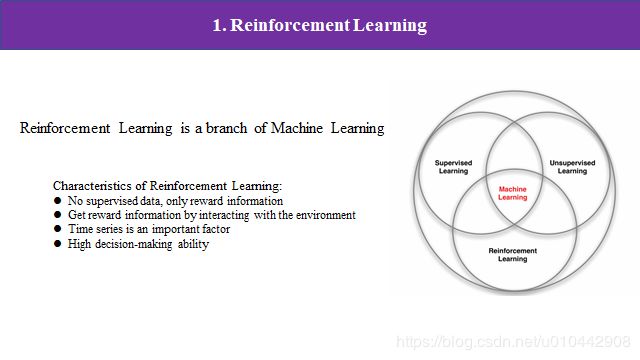
强化学习也是机器学习的一种,它属于以行为主义为代表的人工智能方法,相比于别的机器学习方法,我总结了他大概有四个特点:首先他和监督学习不同,监督学习他需要带标签的样本,但是强化学习的数据不带标签,只是环境在agent的动作下给了奖励信号;其次,他和无监督学习也不同,无监督学习试图通过没有标签的数据得到一种隐含结构,而强化学习只是通过与环境交互,最大化回报找到一种策略,并不是找出数据中的结构。然后是时隙的概念在强化学习中非常重要,针对不同的时隙划分方法他都有对应的算法。最后一个,我们知道神经网络或者深度学习,通过多层网络结构和非线性变换组合特征,对事物的感知和表示,而强化学习,通过最大化智能体系从环境中获得的累计奖励值来完成检测最优策略,所以,深度学习有较高的感知能力,而强化学习有较高的决策能力。
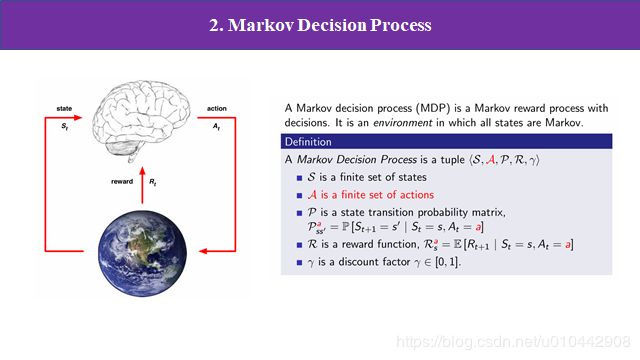
左边图片显示的是强化学习作用的一般过程,然后我们首先定义一个智能体,它有一系列的动作,将这个动作作用于环境,环境就会发生改变,然后环境改变的同时,我们的agent会收到一个奖励信息,然后agent通过对环境的一个感知,也就是状态的输入和这个基于刚才得到的奖励信号,然后对下一步的动作做出决策,如此循环的过程就是强化学习的一个基本过程。我们把这个过程建立成把马尔科夫决策过程,决策过程一般包含五个元素,状态的集合S,动作集合a状态转移概率p,回报r,和折扣因子gama,
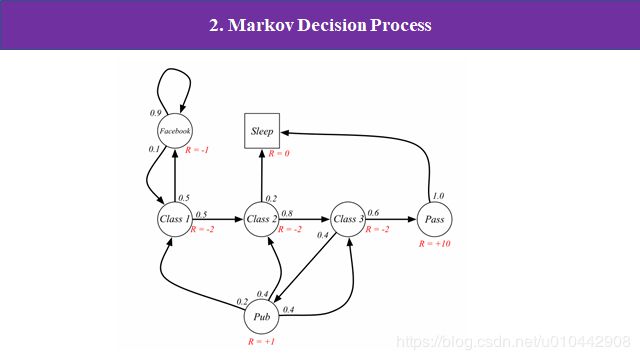
下面举个简单例子(来源David Silver),假如我们今天有一节大课,然后他有三节小课,我们上第一节第一小节课的时候有个同学,他可能有50%的概率,在上课的时候玩手机你就刷微信刷微博,当他刷微信刷微博的时候摁可能就比较开心,然后他又有90%的概率继续刷微信刷微博。就这样持续一个过程,突然他发现就是老师提了个问题阿,那么他就有10%的概率,然后又回到这个第一小学的课堂的内容,然后他上了第一小节课,也有可能50%的概率,那么继续上第二小姐的课,在我们第二小节,可能他又有点累了,他有0.2的概率,睡睡觉,然后剩下80%的概率继续上第三小节课啊,上完第三上第三小节课的时候,那又有可能一年四的概率,你去参加什么party阿60%的概率,他就通过了这么大客或者通过了考试,那么通过考试呢,那么后面你就可以就医去睡觉了,去玩了是吧,这就是一个嗯,比较直接的马克福过程。在每一个状态的时候,我们可以根据他的动作,就是定义一个奖励值就是这里图中显示的红色的啊,他每每做出一个动作,根据你动作的好坏,他然后就定一个大小不一的奖励。
有了上面的框架,那接下来我们要进行定量分析,所以要定义一些函数。首先是策略,他是从状态到每个动作的选择概率之间的映射,也表示一系列特定动作的集合,体现为概率的形式,所以他的值是0到1。然后是回报,每一时刻有即时奖励,就是这里的R,那么回报是各时刻收益的总和,但是这里引入一个额外的概念,折扣因子,这个值在0到1之间。在我们算t时刻回报时,如果一昧追求回报最大化,那距离t时刻比较远的即时奖励显得很重要,但事实上未来时刻的奖励对此刻影响是不重要的,所以需要乘上折扣因子。通过提取因子和合并,我们可以得到此刻回报与下一刻回报的关系。然后是两个价值函数:状态价值函数和动作价值函数,字面意思上,一个是衡量智能体处于一个状态的价值和智能体选定一个动作所带来的价值,状态价值是基于状态s和策略π对回报的期望,期望是什么?就是概率乘上对应的值再累加,我们可以看右边上图,空心圆代表智能体所处的状态,实心圆代表智能体所选的动作,比如智能体处于状态s,他有三种动作可选,分别对应一个选择概率π,那么每一个动作后又有可能产生两种状态,对应概率p,那么状态s的价值函数就等于状态s撇的价值乘上概率再累加,就是公式所对应。动作价值函数类似如下图,他基于一个动作开始,这个动作可能产生两种状态,每个状态又有两个动作可选,那动作a的价值函数等于动作a撇的价值乘上概率再累加。我们建立强化学习任务的目的是什么?就是通过最大化回报寻找出一个策略。有了上面的价值函数然后求最大就可以得到对应的策略了,分别加最优状态价值函数和最优动作价值函数。那么两个最优价值函数的关系由最后这个公式给出,代表的意思是:最优策略下的状态价值一定等于这个状态下最优动作的期望回报。也就是说我分别对两个价值函数求最优,得到的结果都是等价的,都是最优策略。

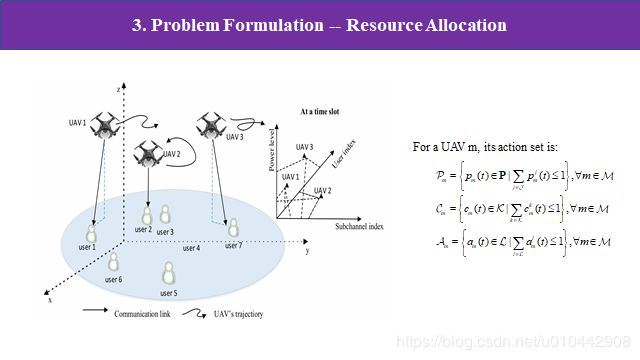
有了上面的马尔科夫决策框架和一些定量的函数,接下来我们看下这篇论文是怎么把强化学习的模型建立在通信网络的资源分配问题上的。首先论文基于的大应用背景就是图中所示的,空中有m个无人机UAV,他们的轨迹是预先规划好的,地面总共有l个用户,然后考虑的网络是空对地通信的下行链路的资源分配,每个无人机选择若干用户进行信息交互,完成用户间的信息交互,但无人机之间是没有通信的,也就是每个无人机都不知道其他无人机的状态。对于每个无人机,他要从若干功率、若干用户和若干子信道中选择一个或多个,也就是图中显示的三个维度的动作集,也就是说论文的目的是寻找M个无人机中,每个无人机对应哪些功率值、用户数和子信道让整个通信网络的资源最大化利用,同时无人机之间是没有信息交互的,但根据通信原理,他们的信号是存在干扰的。
基于上面的目的,接下来是如何定量分析,怎么评价选择一个动作所带来价值的多少呢,也就是说,怎样评价一个信道和用户通信的好坏呢?在通信领域,一般有个概念叫信道的信噪比(其实不仅通信里有,图像处理、好多地方都用到),通俗来讲就是一个信道中有用的信号比上噪声或者干扰,比值越大,信道质量越好。这篇论文是这么定义的:一个信道的信噪比等于信道增益乘功率比上干扰与衰减的和。这里的干扰就是除本无人机,接收到其他无人机的信号就为干扰。一个无人机总信干噪比就对用户数和信道数进行累加。有了信噪比就好办了,而且每个无人机的信噪比是可以测到的,那么就可以定义回报,这里的即时收益是:当我们给定一个阈值,当信噪比大于这个阈值时就定义有收益,小于则没收益为0,那么有收益具体为多少呢?W是信道总带宽,k是信道数,带宽越高、信噪比越高那收益值越高,而功率是消极值,所以收益和功率是负相关的。那么价值函数就是上面定义的,对回报取期望,所以最终的目标是最大化收益找到最佳策略。这里的策略是三个维度的动作集合。

刚才我们定义回报时,它是包含信噪比当中的干扰的,这个干扰是来自其他无人机的信道,但是这个量虽然可以测量,但我们不知道其他无人机的子信道和功率水平以及信道增益,但是我们的目标是寻求整个网络的联合策略。所以怎么知道其他无人机的动作也是必须的,但是无人机相互间没有进行通信。这篇论文通过建立随机非合作博弈来解决这个矛盾。上面我们是从一个无人机的角度建立价值函数,接下来我们把联合策略融入回报和价值函数,对公式进行改写。首先假设每一个无人机的动作空间扩大至联合动作空间,分别表示所选用户、子信道和功率水平。那么信噪比改写成这样,这里θ-m是其他无人机的动作,G(t)是信道增益。这里我们再定义一个无人机状态,信噪比大于给定阈值时状态为1,其他状态为0。那么回报和上面是一样的,只不过里面的动作空间是联合策略下的空间。
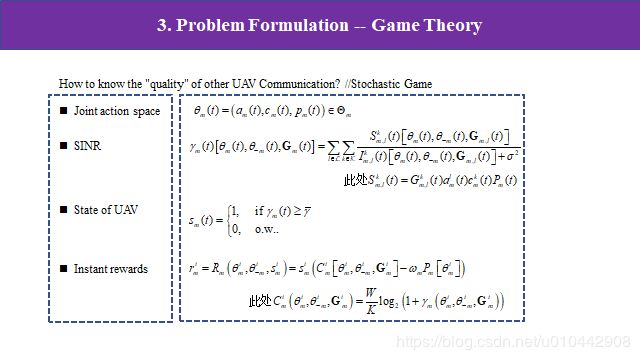
无人机 m 的优化目标是随着时间的推移使其期望回报最大化,我们对状态价值函数进行改写,在所建立的随机博弈中,玩家(uav)具有个体期望报酬,这取决于联合策略,而不取决于玩家的个体策略。因此,不能简单地期望玩家最大化他们的期望回报,因为不可能所有玩家同时达到这个目标。在随机博弈中,让整体最优的解就是纳什均衡解。在纳什均衡解的情况下,每个无人机的行动是对其他无人机选择的最佳反应,也就是说只要其他玩家无人机继续采用原来策略不变,该玩家无法通过改变自身策略获得更大回报时,这个策略是纳什均衡点。有了这个规则,我们不需要知道其他无人机的动作就可以找到自身的纳什均衡策略了。

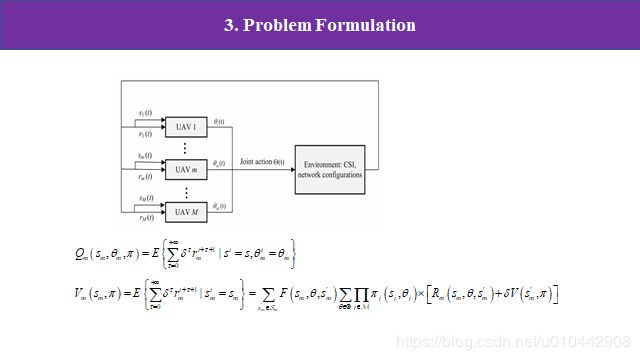
所以整个网络的框架就如图所示,具体来说,对于每一个无人机 m,左侧是在时隙 t 时的局部观察信息-状态 s t m 和奖励 r t m;右侧是在时隙 t 时无人机 m 的动作。当所有其他玩家选择固定策略时,随机博弈中玩家面临的决策问题相当于马尔可夫决策过程。所有 agent 独立地执行一个决策算法,但共享一个共同的结构。
下面就是经典Q算法求解上面的价值函数,最终得到最优策略。

源论文:
Cui, Jingjing & Liu, Yuanwei & Nallanathan, Arumugam. (2019). Multi-Agent Reinforcement Learning Based Resource Allocation for UAV Networks. IEEE Transactions on Wireless Communications. PP. 10.1109/TWC.2019.2935201.
https://arxiv.org/abs/1810.10408