知识准备:
缓存就是数据交换的缓冲区(称作Cache),当某一硬件要读取数据时,会首先从缓存中查找需要的数据,如果找到了则直接执行,找不到的话则从内存中找。由于缓存的运行速度比内存快得多,故缓存的作用就是帮助硬件更快地运行。
Apache Geode是一个数据管理平台,可在广泛分布的云架构中实时,一致地访问数据密集型应用程序。
Apache Geode 和 Redis的比较:
geode是java生态圈,目的是高性能高可用,除了缓存,更像数据库,可以sql查询,硬盘可能仅在出现灾难时才用,大部分都在内存就处理了。
redis主要是缓存,没有冗余设计导致可靠性相对较低,主要用于web应用。
其中,支付宝,12306等大型分布式工程都毫无疑问会选择geode。
安装部署 (linux系统) :
tips:1)主机名和主机文件已正确配置为本机。
2)JDK为1.8版本或以上版本。
3)系统时钟设置为正确的时间,这一点对于故障排除有用的信息很关键。
1.从geode官网上的“发行版”页面下载.zip或.tar文件
2.解压缩.zip文件或展开.tar文件,其中path_to_product是绝对路径,文件名因版本号而异,此处是最新版本。对于.zip格式:
$ unzip apache-geode-1.3.0.zip -d path_to_product
3.设置JAVA_HOME环境变量
$ echo $JAVA_HOME
$ /usr/lib/java/jdk
4.将Geode脚本添加到PATH环境变量中
PATH=$PATH:$JAVA_HOME/bin:path_to_product/bin
export PATH
5.验证安装,注意输出已安装的Geode版本
$ gfsh
$ version v1.3.0
集群配置服务的原理:
定位器(locator):一个Geode进程,它告诉新的连接成员正在运行的成员的位置,并为服务器的使用提供负载均衡。默认情况下,定位器启动JMX Manager,该JMX Manager用于监视和管理Geode集群。集群配置服务使用定位器来保持集群配置并将配置分配给集群成员。
服务器(Server):分为2个级别:集群和组,组级别可以覆盖集群级别的配置
创建和使用集群:
1.创建一个工作目录(比如:/usr/local/workplace/module/my_geode,建议和path_to_product放在同一级目录下,便于以后配置和管理),切换到新目录,该目录将包含即将创建集群的配置信息
2.启动gfsh行命令工具
$ gfsh

3.在以下示例中启动一个定位器:

4.在以下示例中启动一个服务:

5.继续启动一个服务,server2:40405

6.list members:
TIPS:Command 'list members' was found but is not currently available (type 'help' then ENTER to learn about this command)此类问题一般是系统的CLASSPATH没配好,或者是之前使用过deploy命令设置过CLASSPATH,导致gfsh找不到对应的jar包。我的解决方式是重启了服务器,才得到解决,如有更高明的方法,欢迎批评指正!!!

7.创建一个复制,持久的区域(region:相当于传统数据库的数据表)

8.查看已将创建的区域:list regions
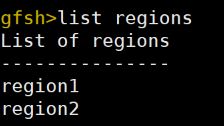
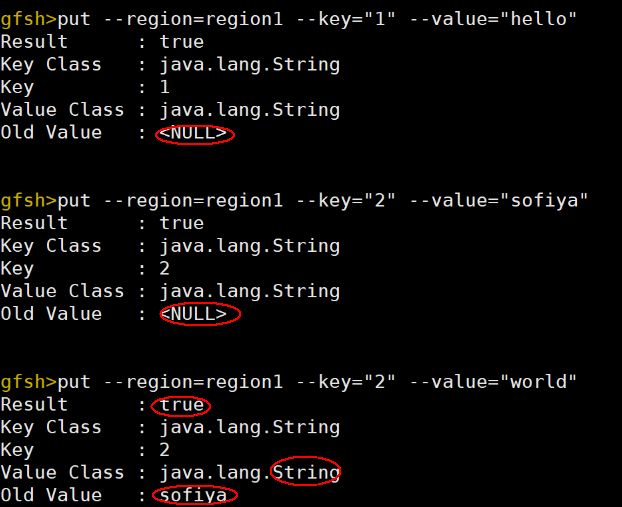
9.运用put命令将数据添加到对应的区域中
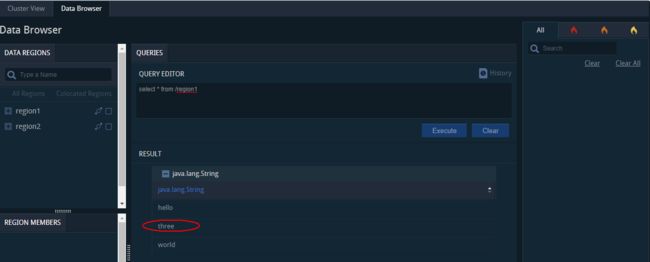
10.运行query命令查询数据:

11.用stop命令停止缓存服务器:

同理,执行 stop server --name=sevrer2
12.用start 命令重启server1,list regions

13.检查复制效果:

14.添加第三条数据,打开pulse应用程序(在web浏览器中),观察集群拓扑。应该可以看到1个locator和2个server。点击数据选项来查看各个region的信息。将下面的localhost替换成对应服务器的IP。
http://localhost:7070/pulse/login.html
默认用户密码:admin/admin
pulse对应的web界面如下,通过查询,数据有3条。
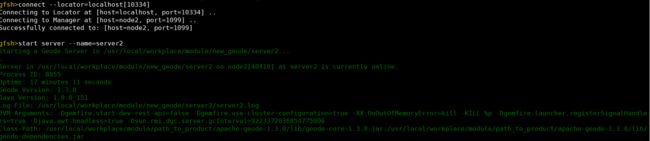
15.在第二个命令行窗口中,切换到工作目录(以my_gemfire为例),并且启动gfsh,连接集群,启动server2
16.put第四条数据上去,查看region状态

运行查询命令验证用put命令所放置的数据是可用的
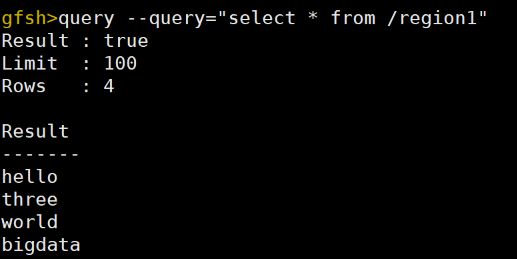
17.关闭系统包括locator

以上都是自己操作的结果,如有不准确的地方,烦请大神指正!