什么是Apache Spark?这篇文章带你从零基础学起

导读:Apache Spark是一个强大的开源处理引擎,最初由Matei Zaharia开发,是他在加州大学伯克利分校的博士论文的一部分。Spark的第一个版本于2012年发布。
Apache Spark是快速、易于使用的框架,允许你解决各种复杂的数据问题,无论是半结构化、结构化、流式,或机器学习、数据科学。它也已经成为大数据方面最大的开源社区之一,拥有来自250多个组织的超过1000个贡献者,以及遍布全球570多个地方的超过30万个Spark Meetup社区成员。
在本文中,我们将提供一个了解Apache Spark的切入点。我们将解释Spark Job和API背后的概念。
作者:托马兹·卓巴斯(Tomasz Drabas),丹尼·李(Denny Lee)
如需转载请联系大数据(ID:hzdashuju)

01 什么是Apache Spark
Apache Spark是一个开源的、强大的分布式查询和处理引擎。它提供MapReduce的灵活性和可扩展性,但速度明显更高:当数据存储在内存中时,它比Apache Hadoop快100倍,访问磁盘时高达10倍。
Apache Spark允许用户读取、转换、聚合数据,还可以轻松地训练和部署复杂的统计模型。Java、Scala、Python、R和SQL都可以访问 Spark API。
Apache Spark可用于构建应用程序,或将其打包成为要部署在集群上的库,或通过笔记本(notebook)(例如Jupyter、Spark-Notebook、Databricks notebooks和Apache Zeppelin)交互式执行快速的分析。
Apache Spark提供的很多库会让那些使用过Python的pandas或R语言的data.frame 或者data.tables的数据分析师、数据科学家或研究人员觉得熟悉。非常重要的一点是,虽然Spark DataFrame会让pandas或data.frame、data.tables用户感到熟悉,但是仍有一些差异,所以不要期望过高。具有更多SQL使用背景的用户也可以用该语言来塑造其数据。
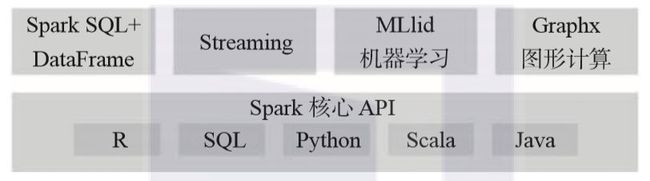
此外,Apache Spark还提供了几个已经实现并调优过的算法、统计模型和框架:为机器学习提供的MLlib和ML,为图形处理提供的GraphX和GraphFrames,以及Spark Streaming(DStream和Structured)。Spark允许用户在同一个应用程序中随意地组合使用这些库。
Apache Spark可以方便地在本地笔记本电脑上运行,而且还可以轻松地在独立模式下通过YARN或Apache Mesos于本地集群或云中进行部署。它可以从不同的数据源读取和写入,包括(但不限于)HDFS、Apache Cassandra、Apache HBase和S3:
▲资料来源:Apache Spark is the smartphone of Big Data
http://bit.ly/1QsgaNj
02 Spark作业和API
在本节中,我们将简要介绍Apache Spark作业(job)和API。
1. 执行过程
任何Spark应用程序都会分离主节点上的单个驱动进程(可以包含多个作业),然后将执行进程(包含多个任务)分配给多个工作节点,如下图所示:
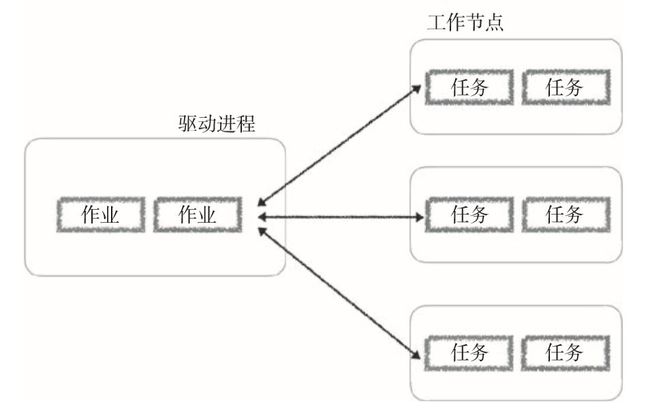
驱动进程会确定任务进程的数量和组成,这些任务进程是根据为指定作业生成的图形分配给执行节点的。注意,任何工作节点都可以执行来自多个不同作业的多个任务。
Spark作业与一系列对象依赖相关联,这些依赖关系是以有向无环图(DAG)的方式组织的,例如从Spark UI生成的以下示例。基于这些,Spark可以优化调度(例如确定所需的任务和工作节点的数量)并执行这些任务。
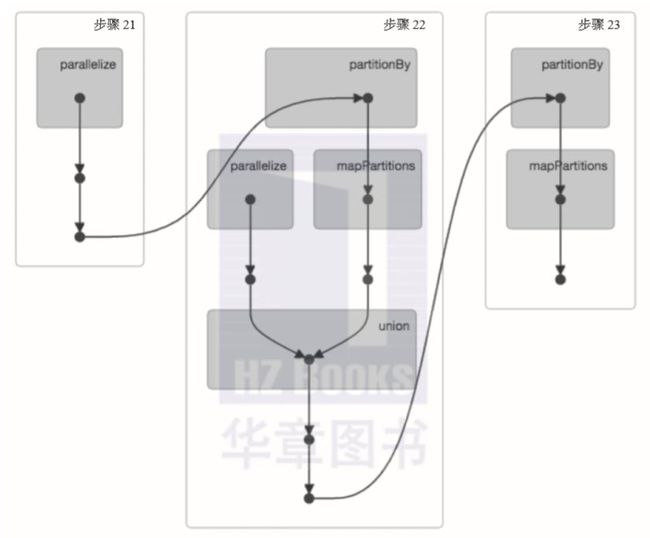
▲有关DAG调度器的更多信息,请参考:
http://bit.ly/29WTiK8
2. 弹性分布式数据集
弹性分布式数据集(简称RDD)是不可变Java虚拟机(JVM)对象的分布式集合,Apache Spark就是围绕着RDD而构建的。我们使用Python时,尤为重要的是要注意Python数据是存储在这些JVM对象中的。
这些对象允许作业非常快速地执行计算。对RDD的计算依据缓存和存储在内存中的模式进行:与其他传统分布式框架(如Apache Hadoop)相比,该模式使得计算速度快了一个数量级。
同时,RDD会给出一些粗粒度的数据转换(例如map(...)、reduce(...)和filter(...)),保持Hadoop平台的灵活性和可扩展性,以执行各种各样的计算。RDD以并行方式应用和记录数据转换,从而提高了速度和容错能力。
通过注册这些转换,RDD提供数据沿袭——以图形形式给出的每个中间步骤的祖先树。这实际上保护RDD免于数据丢失——如果一个RDD的分区丢失,它仍然具有足够的信息来重新创建该分区,而不是简单地依赖复制。
更多数据沿袭信息参见:
http://ibm.co/2ao9B1t
RDD有两组并行操作:转换(返回指向新RDD的指针)和动作(在运行计算后向驱动程序返回值)。
请参阅Spark编程指南,获取最新的转换和动作列表:
http://spark.apache.org/docs/latest/programming-guide.html#rdd-operations
某种意义上来说,RDD转换操作是惰性的,因为它们不立即计算其结果。只有动作执行了并且需要将结果返回给驱动程序时,才会计算转换。该延迟执行会产生更多精细查询:针对性能进行优化的查询。
这种优化始于Apache Spark的DAGScheduler——面向阶段的调度器,使用如上面截图中所示的阶段进行转换。由于具有单独的RDD转换和动作,DAGScheduler可以在查询中执行优化,包括能够避免shuffle数据(最耗费资源的任务)。
有关DAGScheduler和优化(特别是窄或宽依赖关系)的更多信息,有一个很好的参考是《Effective Transformations》第5章:
https://smile.amazon.com/High-Performance-Spark-Practices-Optimizing/dp/1491943203
3. DataFrame
DataFrame像RDD一样,是分布在集群的节点中的不可变的数据集合。然而,与RDD不同的是,在DataFrame中,数据是以命名列的方式组织的。
如果你熟悉Python的pandas或者R的data.frames,这是一个类似的概念。
DataFrame旨在使大型数据集的处理更加容易。它们允许开发人员对数据结构进行形式化,允许更高级的抽象。在这个意义上来说,DataFrame与关系数据库中的表类似。DataFrame提供了一个特定领域的语言API来操作分布式数据,使Spark可以被更广泛的受众使用,而不只是专门的数据工程师。
DataFrame的一个主要优点是,Spark引擎一开始就构建了一个逻辑执行计划,而且执行生成的代码是基于成本优化程序确定的物理计划。与Java或者Scala相比,Python中的RDD是非常慢的,而DataFrame的引入则使性能在各种语言中都保持稳定。
4. Catalyst优化器
Spark SQL是Apache Spark最具技术性的组件之一,因为它支持SQL查询和DataFrame API。Spark SQL的核心是Catalyst优化器。优化器基于函数式编程结构,并且旨在实现两个目的:简化向Spark SQL添加新的优化技术和特性的条件,并允许外部开发人员扩展优化器(例如,添加数据源特定规则,支持新的数据类型等等):
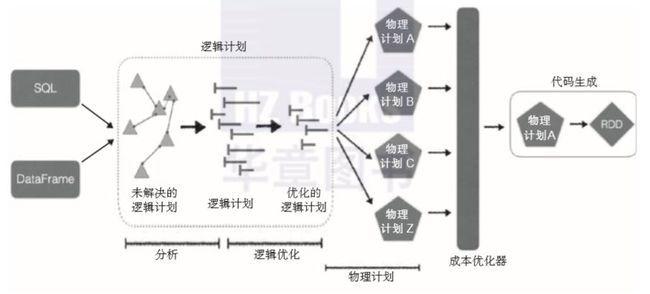
详细信息,请查看Deep Dive into Spark SQL’s Catalyst Optimizer :
http://bit.ly/271I7Dk
和Apache Spark DataFrames:
Simple and Fast Analysis of Structured Data
http://bit.ly/29QbcOV
6. 钨丝计划
Tungsten(钨丝)是Apache Spark执行引擎项目的代号。该项目的重点是改进Spark算法,使它们更有效地使用内存和CPU,使现代硬件的性能发挥到极致。
该项目的工作重点包括:
显式管理内存,以消除JVM对象模型和垃圾回收的开销。
设计利用内存层次结构的算法和数据结构。
在运行时生成代码,以便应用程序可以利用现代编译器并优化CPU。
消除虚拟函数调度,以减少多个CPU调用。
利用初级编程(例如,将即时数据加载到CPU寄存器),以加速内存访问并优化Spark的引擎,以有效地编译和执行简单循环。
更多详细信息,请参考Project Tungsten:
Bringing Apache Spark Closer to Bare Metal
https://databricks.com/blog/2015/04/28/project-tungstenbringing-spark-closer-to-bare-metal.html
Deep Dive into Project Tungsten: Bringing Spark Closer to Bare Metal [SSE 2015 Video and Slides
https://spark-summit.org/2015/events/deep-dive-into-project-tungsten-bringing-spark-closerto-bare-metal/
Apache Spark as a Compiler: Joining a Billion Rows per Second on a Laptop
https://databricks.com/blog/2016/05/23/apache-sparkas-a-compiler-joining-a-billion-rows-per-second-on-alaptop.html
本文摘编自《PySpark实战指南:利用Python和Spark构建数据密集型应用并规模化部署》,经出版方授权发布。
延伸阅读《PySpark实战指南》
点击上图了解及购买
转载请联系微信:DoctorData
推荐语:Pyspark的实用参考指南,深度挖掘Python+Spark的强大功能。
长按识别下方小程序码
发现更多好书


据统计,99%的大咖都完成了这个神操作
▼
更多精彩
在公众号后台对话框输入以下关键词
查看更多优质内容!
PPT | 报告 | 读书 | 书单 | 干货
大数据 | 揭秘 | Python | 可视化
人工智能 | 机器学习 | 深度学习 | 神经网络
AI | 1024 | 段子 | 区块链 | 数学
猜你想看
如果数据有质量,地球将成黑洞?
干货:一文看懂网络爬虫实现原理与技术(值得收藏)
一文了解人脸识别:从实现方法到应用场景都讲明白了
8本前沿技术书,助力这届「青年人」将科幻变成现实
Q: 关于Spark,你还想了解哪方面内容?
欢迎留言与大家分享
觉得不错,请把这篇文章分享给你的朋友
转载 / 投稿请联系:[email protected]
更多精彩,请在后台点击“历史文章”查看

 点击阅读原文,了解更多
点击阅读原文,了解更多