
感知机和神经网络
感知机
鉴于感知机和神经网络的相似性,我们从感知机的角度来出发,先来看看感知机的结构是什么样的
我们对照感知机的公式
可以发现,从输入层到输出层,其实就是感知机的函数模型,当然了,这个到的权重就是,或者是直接把看出是一个偏置项(当然,本身就是偏置项),因此我们就将感知机模型转化成了这样的网络结构,而这样的网络结构,其实也就是没有隐藏层的神经网络,待会我们再介绍,现在先来看一下感知机是如何解决逻辑问题的
因为是一个符号函数,它对于小于0的都会输出为-1,并且我们做逻辑问题的输入和输出都是0 or 1,所以我们将其进行简单的修改,让其对小于0的输出都为0,于是得到如下:
与此同时,对于的问题,我们将统一设定为+1,其传入下一层的权重为,此时,我们便可以开始着手解决逻辑“与”,“或”,“非”的问题了
- 对于逻辑“与”问题,我们可以令,此时我们,这里我们借用吴恩达老师的表格,如下所示:
 逻辑“与”的实现
逻辑“与”的实现 - 对于逻辑“或”问题,我们可以令,此时我们,于是得到如下:
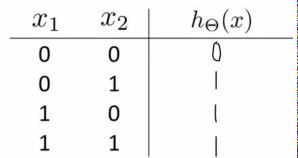 逻辑“或”的实现
逻辑“或”的实现 - 对于逻辑“非”问题,我们可以令,此时我们
而对于异或问题,按书上介绍所说,感知机是不能解决以异或问题为代表的非线性可分问题的,所以我们先来看一下什么是异或问题
异或问题与多层感知机(MLP)
异或问题形式化成数学公式是,即取值相同时为0,取值不同时为1。而异或问题实际上是一个非线性可分问题,即不存在一条曲面可以将数据集正确的划分,如下图所示:
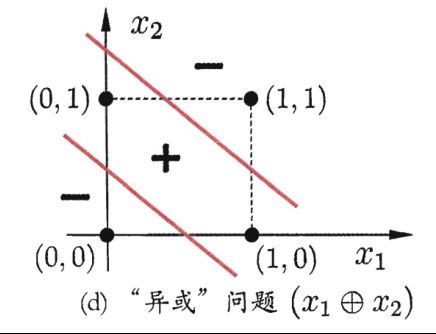
我们可以看出,对于图上的4个点(0,0),(1,0),(0,1),(1,1),感知机是不可能生成一条直线可以将其正确划分的,但是我们是否可以发现,因为异或问题形式化公式是这样的,我们完全可以将其拆成一个个子问题来解决,比如令,此时,而中,我们又可以将视为一个整体,中的也是,所以我们可以发现,其实要实现异或问题,也就是多用几个感知机的问题,即先用感知机生成和,然后再用感知机生成和,最后再用感知机生成,这样,我们就解决了异或问题,如下图所示

图上没有标出权重,不然就太乱了,大致是这样的过程,从输入层,是输入值,每个值都会用一条有权重的边指向下一层的点,其中,权重值是不一样的,比如我们要实现,假设就是,则从射来的边的权重就分别为10,-20,0,以此类推,就是,就是,就是,到了第二个隐含层,就是,就是,最终,我们会在输出层中得到异或问题的答案。(注意:这里的异或问题解决的方法比西瓜书上稍微复杂了一点,但我觉得这样的解决方案似乎更贴近之前感知机在逻辑“与”,“或”,“非”上的解决,所以就自己画了个图)
多层前馈神经网络
此时,我们应该能够直观地了解到多层感知机( Multi-layer Perceptron)的效果,而多层感知机其实也就是我们的神经网络,在西瓜书中它有一个确切的定义,即每层神经元与下一层神经元全互连,神经元之间不存在同层链接,也不存在跨层链接,这样的神经网络结构通常称为“多层前馈神经网络”。这里我们还必须补充一下相关概念的知识点:
- 神经元指的是每一层中的单个结点;
- 除了输入层和输出层外,中间的层称为隐含层,而拥有不同数目隐含层的神经网络称呼也不一样,如下图所示,单个隐含层的称为单隐层前馈网络,两个隐含层的称为双隐层前馈网络;
- 前一层的神经元和后一层的神经元链接边的权重称为连接权
- 每一层的最上面都会有一个or ,这个称之为偏置项,不是神经元,这个偏置项不会接收前一层任何神经元传入的值,但自己会发出数值给下一层神经元
 摘自西瓜书
摘自西瓜书
另外,如果对多层感知机还是没有一个直观认识的话,那么我们可以用下图感受一下
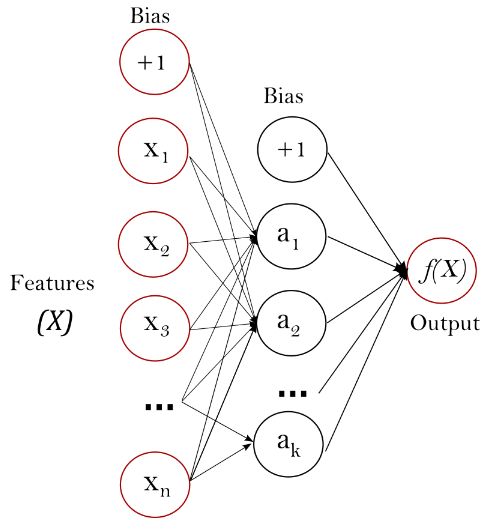 摘自sklearn官方文档
摘自sklearn官方文档
基于反向传播(BP)算法的神经网络
基于以上,我们了解了多层感知机的由来和一点点神经网络的雏形,下边我们来介绍一下神经网络学习中著名的BP(error Backpagation)算法,即反向传播算法(也称误差逆传播算法)。另外,这个算法的工作是先根据一个样本点进行前向传播,寻找到该样本点的输出函数和预测值,然后进行反向传播,利用代价函数计算每一层的神经元的误差值,进而更新每个边的连接权和阈值,重新进行下一个样本点的前向传播,一直让目标朝着代价函数最小化的方向前进,直到找到迭代次数达到上限or代价函数降低的某一个设定的最小值以下结束
前向传播
在之前多层感知机的介绍中,我们了解到了多层感知机的工作机能,其大致过程就是从输入层开始,一层层地通过隐含层的计算,最终到达输出层输出预测值,而这个过程就是前向传播的整个流程,但是,以上我们讲解的都过于粗糙,所以,接下来我们需要从下图仔细讲解整个前向传播的过程:
- 首先,我们给出一个样本点,有d个特征,我们将其排列对齐,作为输入层的数值
- 然后经过初始化后的连接权可以计算出下一层神经元的输入数值,比如下图中的,就是隐含层中第h个隐层神经元(暂时称这个神经元为)的输入,其中是到的连接权
- 计算出的输入值后,因为每个神经元都有一个阈值,所以我们需要先输入值减去阈值,然后利用激活函数(activation function),计算出神经元的输出值,即,而这个就是激活函数,只是在多层感知机中,激活函数使用的是符号函数,而在BP算法中,我们需要引入凸函数的性质,函数并不具备这样的性质,所以我们使用sigmoid函数来替代
- 计算出所有隐含层的输出值后,我们通过,计算出每一个的输入值,然后在用的激活函数从而得到的输出值
- 注意:这里的输出层有多个是因为它作为多类别输出所造成的,比如根据吴恩达老师所说,我们假设输出层有三个 ,每个代表一类,其中 得到输出为,则该应该是输出第三类,同样的,如果最终输出是,则该应该是输出第二类
- 疑问:如果输出是呢?我觉得这就需要和实际数据集的输出类别个数决定了,如果类别过多了,那么就可以将其用二进制的方式表示其类别,而表示的就是第四类
 摘自西瓜书
摘自西瓜书
反向传播
正如一开始所说,反向传播是利用代价函数计算每一层神经元的误差值,从而更新参数,那么我们就需要看一下,到底有哪些参数是需要更新的,并且是如何更新的。当然,我们必须先有损失函数才可以,这里我们先假设代价函数是用均方误差来计算
- 注意:这里的1/2是为了后续的计算方便,且代价函数也没有考虑正则化项
整个神经网络有哪些参数需要更新:
- :隐层到输出层的连接权
- :输出层第个神经元的阈值
- :输入层第个神经元与隐层第个神经元之间的连接权
- :隐层第个神经元的阈值
现在,我们以隐层到输出层的连接权为例,基于梯度下降的方法进行推导
- 参数的更新式如下
- 其中,假设给定学习率,有
- 现在,为例计算上面的整个,我们根据求导的链式法则将式子进行如下分解
1.其中,是输出层中第个神经元的输入值;是输出层中第个神经元的输出值
2.因为,所以我们得到
3.又因为激活函数sigmoid的一个性质为,所以,我们可以令,于是得到
- 现在,为例计算上面的整个,我们根据求导的链式法则将式子进行如下分解
- 因此,基于以上的推导,我们可以得到
类似地,我们可以得到其他参数的更新式
- 其中
BP算法伪代码

算法实现需要注意的要点
下面都是一些在算法实现需要注意的地方,目前自己都还没有做实验,所以都只是理论上理解下来的,所以整理在下面
参数的随机初始化
根据吴恩达老师在视频中所说,如果一开始我们假设所有参数为0,那么这样的参数初始化方法虽然对逻辑斯蒂回归行得通,但是对于神经网络来说是行不通的。因为如果我们令所有的初始参数为0(或全部参数都为一样的值),那么这就意味着第二层的所有神经元都会有相同的值,(注意:因为吴恩达在视频中没有讲到神经元的阈值,所以这里的所有参数指的是上一层到下一层的连接权,而神经元得到的相同值是指上一层经过连接权输入给下一层神经元的输入值),如下所示:
- 设输入层的神经元为,偏置项为,隐含层的神经元为,其中连接到的连接权为,而连接到的连接权为,偏置项连接到的连接权为
- 的输入值为
的输入值为 - 因为所有参数都是一样的,即,所以我们可以发现最终这样的结果对于接下来的训练是没有意义的,因此我们需要随机初始化参数,一般是让初始参数为正负之间的随机值
激活函数的选择
在整个神经网络中有两种激活函数,一种是用于隐含层上的激活函数,一种是用于输出层上的激活函数,这两层神经元的激活函数的选择是有一些些不同的,比如:
- 隐含层上的激活函数选择
- tanh函数(Hyperbolic Tangent),即双曲正切函数,公式如下
- 注:sklearn官方文档上的说明是tanh函数,而有些博客上表示也可以使用sogmoid函数,但似乎更多的人认为尽量不要用sigmoid函数,因为目前已经有了更好的函数Relu
- 输出层上的激活函数选择
- 二分类问题:sigmoid函数
- 多分类问题:softmax函数
- 注:sigmoid函数是softmax函数的一种特殊情况,sigmoid是将一个real
value映射到(0,1)的区间(or(-1,1)的区间),由此做二分类,而
softmax是将一个K维的real value向量的每一个元素进行映射,然后将返回
的结果经过归一化处理得到一个向量,向量中的每个元素代表的是属于某个类的可能性,而在输出的时候,这个结果会输出向量中可能性最大的那个,如,其中是(0,1)上的常数最终我们返回对应的类别
- 注:sigmoid函数是softmax函数的一种特殊情况,sigmoid是将一个real
- 在回归问题的解决上,sklearn的官方文档似乎表达的就一句话,摘录如下;但是,我也不大理解这是啥意思,感觉像是在说可以让f(x)=x,但是有些博客上说这样的线性函数会让神经网络在非线性回归中的魅力无法发挥,emmmm,我也不太懂,以后再补吧
In regression, the output remains as f(x) ; therefore, output
activation function is just the identity function.
另外,我们在使用反向传播更新参数权重时,计算过程中会涉及到激活函数的求导计算,所以激活函数的选择将会影响收敛速度,并且,使用sigmoid函数的过程本身就会有一定的问题,问题如下:
- 容易出现梯度消失
- 函数输出不是zero-centered
- 幂运算相对比较耗时
为什么会出现上面的问题,我们先看一下sigmoid函数的图像
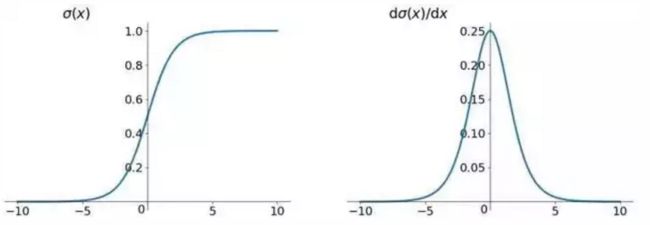
左边是函数本身,右边是sigmoid函数的导函数图像,基于此,我们可以发现sigmoid导函数的最大值只有0.25,也就是说我们的神经网络如果隐含层比较多的话,那么梯度的数值会每经过一层下降四分之一,经过10层就只能为原先的1/1048576,这就是梯度消失的主要原因;对于为什么是函数输出不是zero-centered会造成梯度下降很慢,这个原因知乎上一些答主说是在斯坦福CS231n深度视觉识别课程视频第六集第9分钟左右,这里贴出链接,以后再补( 传送门)
至于为什么幂运算比较耗时,其实这是sigmoid函数自身的问题,可以很明显的看到
因此,我们的另一种选择是ReLU函数,也是目前来说用的最多的激活函数,详细的介绍都在下面的链接博客里,我们可以通过一张图来直观的感受以下速度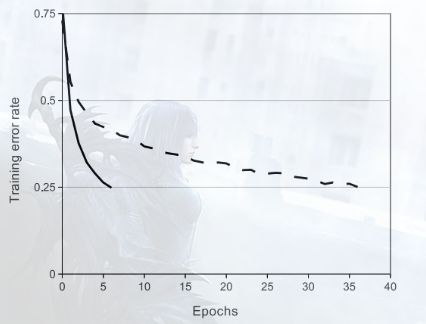
图中实线是ReLu函数,虚线是sigmoid函数,sigmoid函数需要35轮迭代才下降到0.25的程度,对于ReLU仅仅需要5轮,可见速度之快
损失函数的选择
根据sklearn官方文档所说,对于分类问题,我们使用的是交叉熵(Cross-Entropy)代价函数,对于回归问题,则是使用均方误差损失函数。在上面的参数更新的梯度推导中,我们假设的是均方误差作为损失函数,而事实上,如果是分类问题的话,使用交叉熵代价函数得到的效果会更好,梯度下降的速度会更快
- 注1:这里并没有解释为何回归问题用均方误差,分类问题交叉熵则更好,目前还没找到更好的补充资料,待以后补上吧
- 注2:交叉熵代价函数的公式是:带有正则项的交叉熵代价函数可参考吴恩达视频上的公式:
- 其中,这两个式子里,和都是表示单个神经元的输出值,是预测值,表示的是每一层中排除掉偏置项的连接权
至于为什么交叉熵要比均方误差更好,简单说来是因为交叉熵有一个特性,它会在模型误差较大的时候梯度下降得更快,误差较小的时候梯度下降得更慢,而具体的我们可以参考如下的博客,写得极为详细! (传送门)
实际使用中的其他一些小技巧
关于数据预处理方面,因为多层感知机对特征放缩(feature scaling)是十分敏感的,因此我们在进行数据预处理时必须先对数据集进行特征放缩,如下所示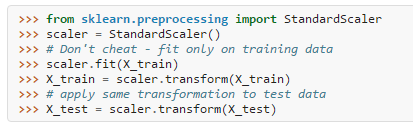
关于收敛速度方面,我们以上所讨论的激活函数的选择和损失函数的选择,它们的目的都是为了加快收敛速度,但以上都是基于梯度下降的前提来去进行的,其实根据资料所说,我们甚至还有更多的选择,比如sklearn官方文档上给出了一些在实际应用中的建议,如下
- 对于小规模的数据集,使用L-BFGS算法可以收敛得更快
- 对于规模相对大一些的数据,Adam算法是更好的选择,并且收敛更快
- 另外一种情况,如果学习率参数被调整的很好,那么SGD则是相对上面的算法最好的选择
参考资料:
【1】《机器学习》周志华
【2】《机器学习视频》吴恩达
【3】Neural network models (supervised)
【4】 神经网络中的激活函数的作用和选择
【5】交叉熵代价函数(cross-entropy cost function)
【6】理解交叉熵损失(Cross-Entropy)
【7】交叉熵代价函数(作用及公式推导)