sklearn.svm 多分类
>>> from sklearn import svm
X = [[0,0], [1,1],[2,2],[3,3]]
Y = [0, 1,2,3]
clf = SVC( probability=True)
clf.fit(X,Y)
print(clf.predict([[0,0], [1,1],[2,2],[3,3]]))
print(clf.predict_proba([[0,0], [1,1],[2,2],[3,3]]))
打印如下:
[0 1 2 3]
[[ 0.15246393 0.23705461 0.30392427 0.30655719]
[ 0.2550524 0.16488868 0.25497241 0.3250865 ]
[ 0.32594085 0.25411181 0.16480942 0.25513792]
[ 0.30659971 0.30340014 0.23672633 0.15327383]]
---------------------
作者:m0_37870649
来源:CSDN
原文:https://blog.csdn.net/m0_37870649/article/details/81747614
版权声明:本文为博主原创文章,转载请附上博文链接!
one to one 方案
clf = SVC(decision_function_shape='ovo')
clf.fit(X, Y)
SVC(C=1.0, cache_size=200, class_weight=None, coef0=0.0,
decision_function_shape='ovo', degree=3, gamma='auto', kernel='rbf',
max_iter=-1, probability=False, random_state=None, shrinking=True,
tol=0.001, verbose=False)
one to rest
clf.decision_function_shape = "ovr"
SVC方法decision_function给每个样本中的每个类一个评分,当我们将probability设置为True之后,我们可以通过predict_proba和predict_log_proba可以对类别概率进行评估。
不均衡问题
我们可以通过class_weight和sample_weight两个关键字实现对特定类别或者特定样本的权重调整
StandardScaler类是一个用来讲数据进行归一化和标准化的类。
所谓归一化和标准化,即应用下列公式:
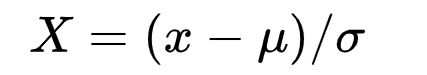
使得新的X数据集方差为1,均值为0
fit_transform方法是fit和transform的结合,fit_transform(X_train) 意思是找出X_train的和,并应用在X_train上。
这时对于X_test,我们就可以直接使用transform方法。因为此时StandardScaler已经保存了X_train的
作者:抬头看月亮
链接:https://www.jianshu.com/p/2a635d9e894d
来源:简书
简书著作权归作者所有,任何形式的转载都请联系作者获得授权并注明出处。