目的:了解深圳单简出租房屋的价格分布
成果(简单可视化):
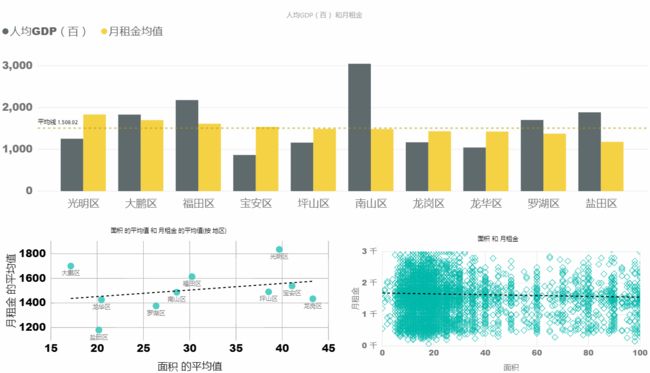
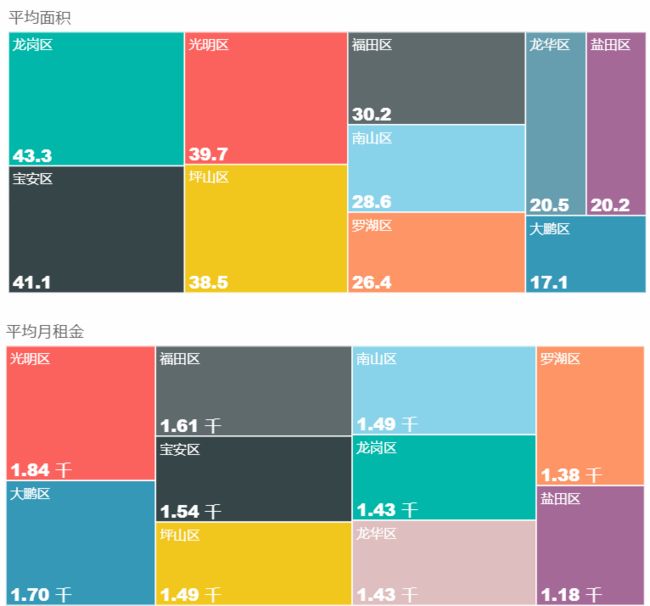

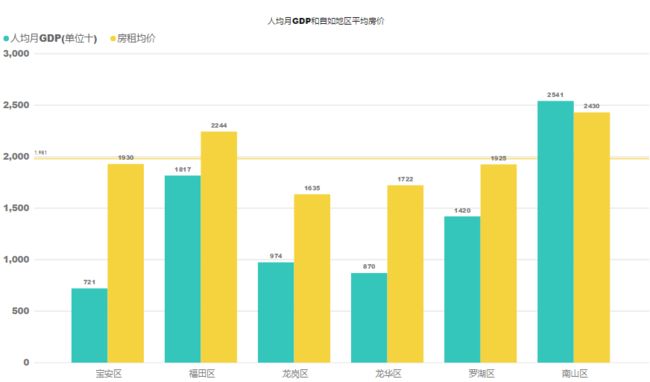
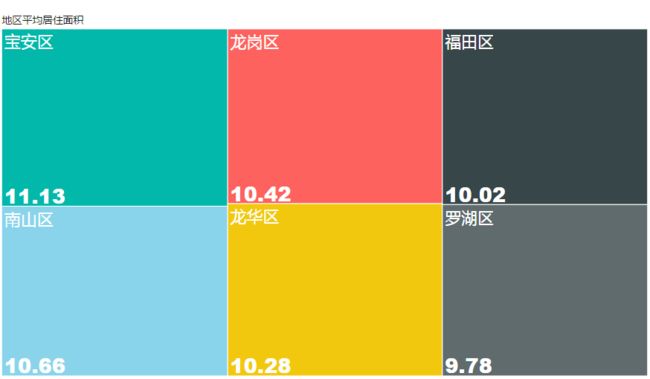
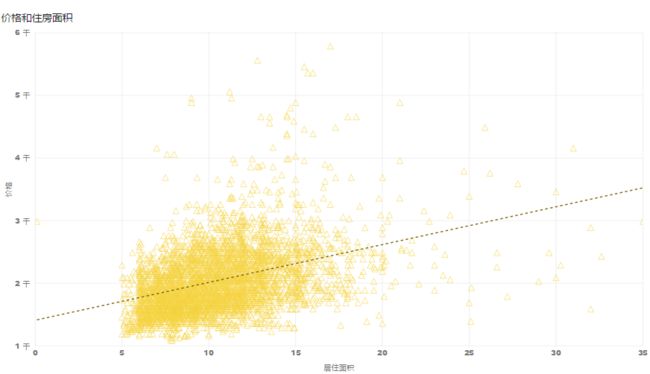
由于请求限制目前,目前样本只有1200个左右。有待。
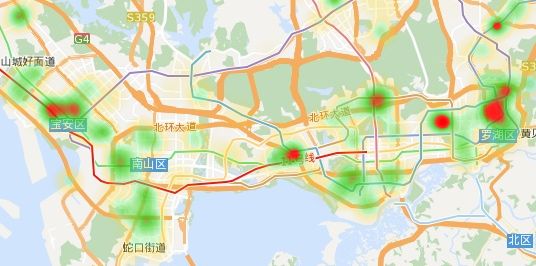
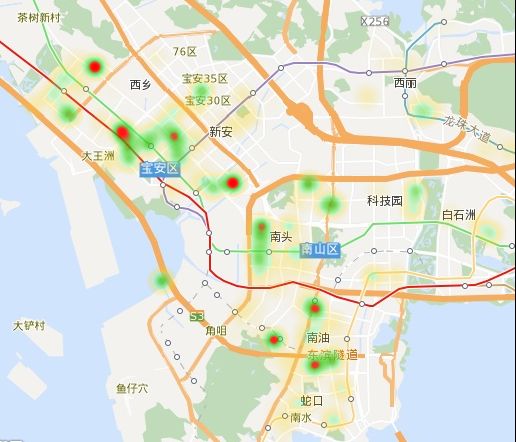
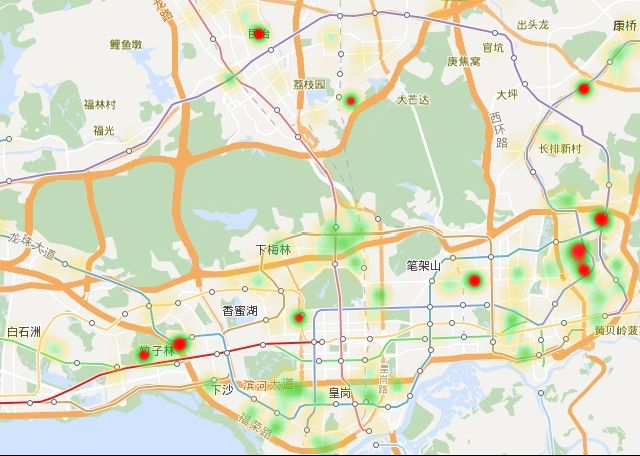
主要使用的库:BeautifulSoup,requests,Pool
IDE:Pycharm
浏览器:Opera Next
数据库:Mongodb
分析工具:Power BI,Excel
一,编写爬虫
(1)抓取各个地区的主页面
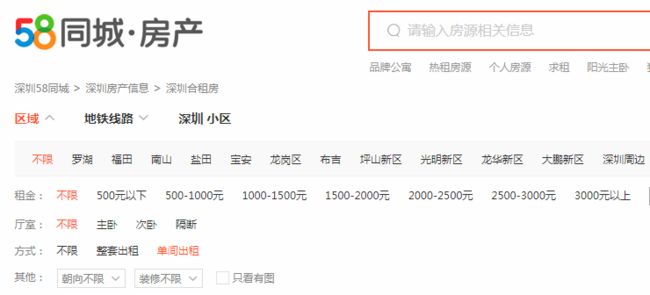
我们要把每个地区的主网页抓下来,导入需要的库
from bs4 import BeautifulSoup
import requests
先点一个地区看一下网址是什么样子的
我们得到了:sz.58.com/futian/hezu/
再看一下地区所在的标签
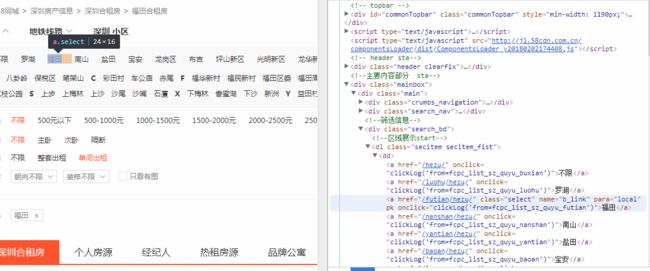
在dd下的a标签,url后部分是href部分
可以知道各个地区的url是:http://sz.58.com +'href'即http://sz.58.com + /futian/hezu/
定义一下主页部分:
host_url ='http://sz.58.com'
接下来可以定义抓取的函数了
def get_index_url(url):
wb_data =requests.get(url)
soup = BeautifulSoup(wb_data.text,'lxml')
links = soup.select('body > div.mainbox > div.main > div.search_bd > dl.secitem.secitem_fist > dd > a')#用copy中的copy selector
for linkin links:
page_url = host_url + link.get('href')
print(page_url)
我们把所有a中的href取出来和主页http://sz.58.com加在一起再打印出来,就得到了各个地区的合租主页了,其实这几个可以手动复制粘贴出来,但是Life is short,U need Python.这也是我们Python的一个原因。
打印出来把他直接复制出来定义成hezu_channel
hezu_channel ='''
http://sz.58.com/luohu/hezu/
http://sz.58.com/futian/hezu/
http://sz.58.com/nanshan/hezu/
http://sz.58.com/yantian/hezu/
http://sz.58.com/baoan/hezu/
http://sz.58.com/longgang/hezu/
http://sz.58.com/buji/hezu/
http://sz.58.com/pingshanxinqu/hezu/
http://sz.58.com/guangmingxinqu/hezu/
http://sz.58.com/szlhxq/hezu/
http://sz.58.com/dapengxq/hezu/
http://sz.58.com/shenzhenzhoubian/hezu/
'''
注意这里有一个'所有'下的链接,把它手动删除
(2)抓取各个地区的网页上的数据
由于我们想要的标题、价格、地址、面积信息都在页面上展示了就不用再下到详细页面去抓取了

现在导入链接mongodb的库pymongo,还有让爬虫休息一下避免被封ip的time库和random(让时间随机一下)
import pymongo
import random
import time
先在mongodb创建库
client = pymongo.MongoClient('localhost',27017)
work = client['work']
hezu2 = work['hezu2']
写一个函数能抓取一个页面的信息,变量为前面得到的channel_list和页码(待会对页码做个循环就可以遍历所有页了)
我们先看一下网页结构:http://sz.58.com/futian/hezu/
点击第二页:http://sz.58.com/futian/hezu/pn2/
我们试试把pn2给成pn1,结果是跳到第一页,可以知道对channel_list中的url加上pn{}就可以翻页了
于是页面构成变为:channel_list+pn{}
写一个函数包含着两个变量
def get_url_all_infom(channel,pages):
list_view ='{}pn{}'.format(channel,str(pages))#要看的页url
wb_data = requests.get(list_view)#请求
soup = BeautifulSoup(wb_data.text,'lxml')#解析
由于有些地区的页码没有70页(如坪山) ,我们要判断如果没有就跳过,唯一标识就是页码栏了
看一下源代码的位置
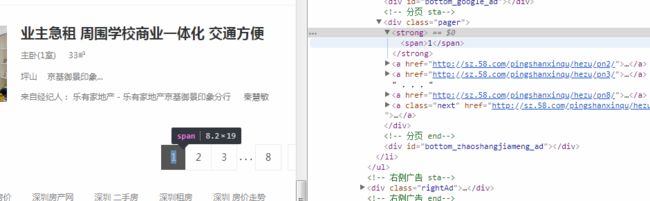
这里有一个strong,我们看看是不是唯一的,搜索发现的确是唯一的,而对pn9的页面是没有的,我们可以把‘strong’作为唯一标识
如果在soup发现了这个标识就抓取,没有的话就打印ERROR
if soup.find('strong'):
try:
except:
print('ERROR')
接下来是抓取元素
一样的,我们找到所对应的标签,这里要调整的是我们要抓取标签下的所有子标签
titles = soup.select('li > div > h2 > a')
areas = soup.select('body > div.mainbox > div.main > div.content > div.listBox > ul > li > div.des > p.add')
zones = soup.select('body > div.mainbox > div.main > div.content > div.listBox > ul > li > div.des > p.room')
links = soup.select('li > div > h2 > a')
prices = soup.select('body > div.mainbox > div.main > div.content > div.listBox > ul > li > div.listliright > div.money > b')
把这些东西装进一个字典
for title, area, price, zone, linkin zip(titles, areas, prices, zones, links):
title = title.text,#直接把文本提取出来
area = area.text + list_view.split('/')[-3],#同理,但是这里的位置没有区名,我们从访问的url提取,用split根据/把url拆开再取倒数第三个(http://sz.58.com/**pingshanxinqu**/hezu/pn2/)
price = price.text,#这里可以用int转成数值,但是可能出现价格为‘面议’的情况,所以直接这样处理
zone = zone.text.split(' ')[-1],#面积标签下还有是否是主卧次卧,我们只要面积
link = link.get('href')#可以把这个租房的地址也取出来
要通过一定的方法把要的东西筛选出来,具体看注释。
然后对字典里的逐一插入数据库
hezu2.insert_one({'title':title,'area':area,'price':price,'zone':zone,'link':link})
睡上一些时间
i=int(random.choice([20,22,23]))
time.sleep(i)
完整代码:
def get_url_all_infom(channel,pages):
list_view ='{}pn{}'.format(channel,str(pages))
wb_data = requests.get(list_view)
soup = BeautifulSoup(wb_data.text,'lxml')
if soup.find('strong'):
try:
titles = soup.select('li > div > h2 > a')
areas = soup.select('body > div.mainbox > div.main > div.content > div.listBox > ul > li > div.des > p.add')
zones = soup.select('body > div.mainbox > div.main > div.content > div.listBox > ul > li > div.des > p.room')
links = soup.select('li > div > h2 > a')
prices = soup.select('body > div.mainbox > div.main > div.content > div.listBox > ul > li > div.listliright > div.money > b')
for title, area, price, zone, linkin zip(titles, areas, prices, zones, links):
title = title.text,
area = area.text + list_view.split('/')[-3],
price = price.text,
zone = zone.text.split(' ')[-1],
link = link.get('href')
hezu2.insert_one({'title':title,'area':area,'price':price,'zone':zone,'link':link})
i=int(random.choice([20,22,23]))
time.sleep(i)
except:
print('ERROR')
我们使用多进程处理,新建一个main.py调动所有要用的函数
#-*- coding: utf-8 -*-
from multiprocessingimport Pool
from parsingimport get_url_all_infom#抓取信息并插入数据库的函数
from shenzhen_extractimport hezu_channel_list#各个地区的主页列表
def get_all_from(channel):#提取各地区里的1到70页的链接
for iin range(1,71):
get_url_all_infom(channel,i)#用这个函数提取地区所有链接
if __name__ =='__main__':
pool = Pool()
# pool = Pool(processes=4)
pool.map(get_all_from,hezu_channel_list.split())#map函数可以用第一个参数中的函数一一处理第二个参数的元素(用split把他们拆分一一放进get_all_from)
我们再编写一个监控脚本,当数据库中的数据不发生变化时发出警告(可能是58同城监视到了要求输入验证码,可以手动输入一下)
import time
from parsingimport hezu2
import winsound#是一个发出声音的函数
print('ok~')
t=0
while True:
print(hezu2.find().count())
i = int(hezu2.find().count())
time.sleep(5)
print(hezu2.find().count())
time.sleep(5)
if i == int(hezu2.find().count()):
winsound.Beep(1000,5000)#1000位频率,5000为时间
(3)终端运行爬虫
先运行main.py,到所在文件夹调用命令python main.py
再运行counts.py
(4)改进与问题
多进程只对多核处理器有用
BeautifulSoup解析速度过慢,可改用lxml库
异步非阻塞方式提高请求效率
异步网络和多个ip请求