网络虚拟化如今是一个很热的话题,各大厂商都在忙着争抢这块蛋糕。涉及的技术包括包括网卡的虚拟化(Emulation, I/O pass-through, SR-IOV), 网络的虚拟接入技术(VN-Tag/VEPA),覆盖网络交换(VXLAN/NVGRE),以及软件定义的网络(SDN/OpenFlow)等等。具体的介绍大家可以参考EMC中国研究院之前的一篇博客——“网络虚拟化-正在进行的网络变革”,其中对网络虚拟化的现状作了一个很好的总结。
有一点不知道大家有没有注意到,这里所说的网络其实是狭义的数据通讯网络,包括通常所说的局域网(LAN)和广域网(WAN/Internet),所采用的协议有以太网(Ethernet,二层)和英特网(IP,三层)协议等等。然而在企业级的数据中心(或云计算的数据中心)里还有一类重要的网络,那就是存储网络(StorageNetwork),占统治地位就是基于FC技术的存储域网络(SAN)。存储网络的虚拟化似乎是一个被忽略的领域,虽然在这方面已经有一些工作开展,但总体上还是没有得到太多的关注。存储网络虚拟化的前景如何,到底是未经开垦的×××地(曾经的北大荒),还是不毛之地(撒哈拉沙漠)?
存储网络简介
存储网络通常也被称作存储域网络(StorageArea Network, SAN),是为块级别(blocklevel)数据存储提供统一访问的专用网络。其中的支撑技术就是光纤通道(FibreChannel,FC)技术。FC不是搭建存储网络的唯一选择,但却是业界应用中占统治地位的技术。FC通常包括两方面的含义:(1)传输媒介,能够提供长距离、高速、低延迟、低出错率的传输,以及通过硬件(HBA)实现传输协议(注:在这里光纤(fiber-optic)同样也不是必须的);(2)传输协议(FibreChannel Protocol,FCP),一个五层的网络协议栈(FC-0到FC-4,大家可以类比一下ISO的七层协议栈)。关于FCP这里只提一下其中比较重要的两层:(1)FC-2是数据传输层,可以在这里进行数据帧的流量控制(flowcontrol);(2)FC-4是上层协议映射层,实现对应用层协议(SCSI,IP等)的映射。细心的读者可能发现了问题,这里为什么会有IP协议呢?这里有个小插曲, FC协议最初是作为局域网(LAN)的主干网(backbone)技术设计的,用以代替百兆以太网(Ethernet)。当然结局大家都知道了,千兆和万兆以太网技术完胜。
基于以太网技术的LAN大家都比较熟悉,那么基于光纤通道技术的SAN与其相较到底有和异同呢?图1是数据中心中LAN和SAN的一个简化示意图,大家可以看到在SAN的构建中同样也采用了交换技术(Switching)。其实两者之间大多数的概念都是可以类比的,这里只提两个关键的不同点。其一, LAN是一个全联通的网络,任何两个节点(主机)之间都可能存在通讯;SAN从图论的角度来说是一个二分图(组1:主机,组2:存储系统),即组内部不存在任何通讯,所有的通讯都发生在组间。其二,LAN是一个尽力服务(best-effort)的网络,拥塞丢包都可能出现,可靠的数据传输依赖于上层协议(如TCP);而SAN则提供非常可靠的数据传输,上层协议(SCSI)对丢包的容忍性要差很多。
注:二分图,指顶点可以分成两个不相交的集使得在同一个集内的顶点不相邻的图。

图1 局域网(LAN)与存储域网(SAN)
表1局域网(LAN)与存储域网(SAN)
FC的基本通讯主要存在于两类端口之间,即N-Port(NodePort)和F-Port(FabricPort)。F-Port是FC交换机上的端口,用于连接N-Port。而N-Port是终端设备(主机或存储系统)的端口,通常位于主机适配卡(HostBus Adapter,HBA,图2)上,用于接入交换网络。每个N-Port有一个64位的全局唯一的名字(WorldwidePort Name,WWPN,参考以太网卡的MAC地址)。N-Port接入网络后会被分配一个24位的端口编号(N-PortID,可以类比DHCP得到的IP地址)。这个N-PortID被用于之后所有数据帧的寻址和投递。
光纤存储卡(FC HBA)的虚拟化
网络虚拟化的第一步就是接入设备的虚拟化,以支持多个虚拟机通过多租户(multi-tenancy)的方式同时接入交换网络。对数据通讯网络虚拟化(或服务器虚拟化)有所了解的读者,应该对虚拟机中的虚拟网卡有印象。那么在存储网络虚拟化的过程中,我们是不是也应该为虚拟机提供一个虚拟的HBA卡呢?答案是双重的,回答是或否都有其道理。

图2 光纤适配卡(FC HBA)
回答否或许看上去不是那么直观,但却是目前为止现实的选择。深层的原因在于应用程序对于两类网络的使用行为不同。我们知道应用程序在使用通讯网络的时候,会直接和二层(Ethernet)或三层(IP)打交道。而使用存储网络时,不同的是中间还有一层SCSI协议,大部分应用程序操作(读写)的实际上是SCSI磁盘(至少看上去是),底层的FC网络协议被虚拟化系统(如VMwarevSphere)完全隐藏起来了。这就是为什么网卡的虚拟化是必须的,而HBA的虚拟化需求就没有那么直接了。那么没有了虚拟HBA,虚拟机对存储系统中LUN的直接访问如何实现呢?我们将在下一节对NPIV的介绍中来回答这个问题。
既然如此,再花力气去虚拟化HBA是不是多此一举呢(目前为止尚不存在支持虚拟HBA的解决方案)?事实上,NPIV有其内在的不足,仅仅满足了基本的I/O需求,并不能满足所有应用程序的需求。关于虚拟HBA的讨论将在完成NPIV的介绍后展开。
虚拟网络接入——NPIV和NPV
虚拟接入要解决的问题是要把虚拟机的网络流量纳入传统网络交换设备的管理之中,让交换机可以识别出来自同一链路的不同虚拟机的流量,从而使QoS保证和安全隔离成为可能。N-PortID Virtualization(NPIV) 技术于2006年在IBM的Systemz9服务器上出现,允许管理员为每个Linux分区分配独立的虚拟端口名称(VirtualWWPN)。NPIV允许单个FCP的端口(Port)在域名服务器注册多个WWPN。每个虚拟的WWPN在登录后获得各自的端口编号(N-PortID)。每一对WWPN/NPID都可以用来做SAN的分区(zoning)和LUN的屏蔽(masking)。在网络上的其他节点看来,虚拟的和物理的WWPN不存在任何区别。
相对应的,在提供网络接入的边界交换机上,也需要提供相关的支持。链路另一端的交换端口(F-Port)会看到多个(虚拟)WWPN以及N-PortID,FC交换机必须知道如何来应对。交换机端的技术被称为N-PortVirtualization(NPV)。关于NPV技术的细节这里就不展开讨论了,有兴趣的可以看看这篇文章——“Understanding NPIV and NPV”
NPIV技术在实际存储网络的中的应用,需要各个环节的支持。图3是虚拟化平台对NPIV的支持,以VMwareESX为例,允许为每个虚拟机生成一个新的虚拟WWPN,前提是服务器上的FCHBA必须提供对NPIV的支持。
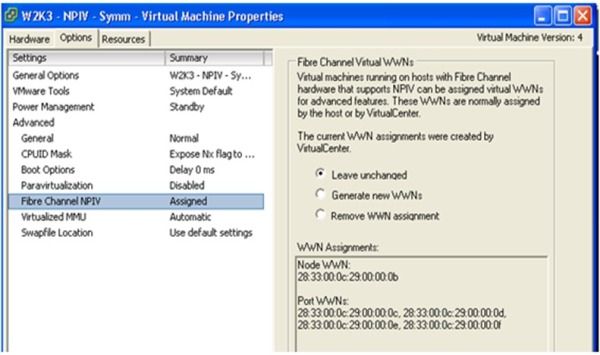
图3 虚拟化平台对NPIV的支持
为了让虚拟机能够“看到”要访问的存储系统,我们需要在FC交换机上为虚拟机的虚拟WWPN和存储系统访问端口的WWPN创建一个新的分区(zone),见图4。在实际的配置中,我们还需要把HBA上的物理WWPN也放在同一分区内(为什么???)。
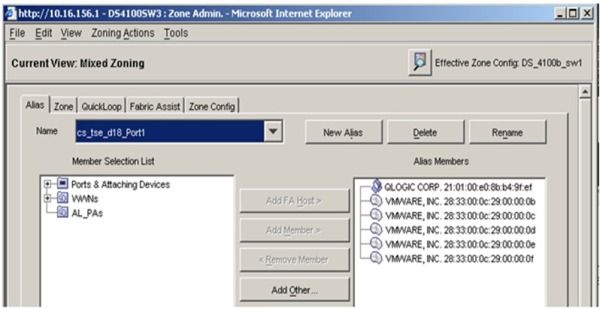
图4 FC交换机对NPIV的支持
最后,我们需要在存储系统上完成LUN的屏蔽(LUNmasking)。目的是为了给VM分配可以看到和访问的LUN(一个或多个)。图4是如何在EMCCLARiiON存储系统上完成相关的配置的一个示例。
图5 存储系统对NPIV的支持
要使NPIV真正发挥作用,还要为虚拟机添加至少一块RDM(RawDevice Mapping)格式的虚拟磁盘。RDM是把外部存储(LUN)直接映射给虚拟机,也就是说,虚拟机发出的SCSI命令都会原样发送给这个设备。至此,我们已经完成NPIV的配置工作,虚拟机内的操作系统和应用程序已经可以看到并使用一块新的SCSI虚拟磁盘。
NPIV主要是提供虚拟接入,也就是说让来自不同虚拟机的数据在网络的各个环节都可见,从而让以虚拟机为单位进行SAN的管理成为可能。然而我们在上面的例子里也看到,划分(zoning)给VM的LUN,同时也要划给ESX。由于虚拟机访问SAN必须依赖ESX,因而从这一点来说统一管理的意义就打了个折扣。
换个角度来看,NPIV也可以视作一种针对HBA的隐式虚拟化技术。然而这种有其内在的缺陷,那就是所有配置操作都需要虚拟化系统的介入。其一,为了添加虚拟机对一个LUN的访问,在交换机和存储系统中也要完成对物理WWPN的配置(Zoning和LUNmasking)。原因是我们需要先创建RDM磁盘(从列表中选取目标LUN),所以虚拟化系统(通过物理WWPN)必须也能“看到”目标LUN。其二,应用程序在运行时如果需要动态添加对一个LUN的访问,必须通过Hypervisor进行配置,虚拟机并没有任何自主权。配置和使用只能分离(不同的WWPN),这种模式并不符合SAN管理的传统。
显式的HBA虚拟化
通过显式的HBA的虚拟化,虚拟机内的操作系统可以看到一个虚拟的HBA设备。通过安装相应的驱动,虚拟机内的操作系统和应用程序就可以直接操作FCP的协议栈。相对基于NPIV的解决方案而言,这样的实现可以带来一些额外的好处。首先,FC网络的管理监控程序也可以运行在虚拟机内。其次,虚拟机可以独立实现LUN的配置(发现,添加和删除),不需要Hypervisor的介入。最后,由于虚拟平台不再需要操作虚拟机所访问的LUN,在交换机上进行Zoning的时候,只要把虚拟WWPN和目标存储系统的WWPN划分在一个zone里,不再需要加入物理WWPN;类似地,在存储系统中做LUNmasking的时候,也不再需要加入物理WWPN。物理的WWPN只需要和datastore所使用的那些LUN划分在一个zone里,这样对网络拓扑的划分更加明晰,网络资源的管理也会更加简单有效。
显式的HBA虚拟化并不意味着对NPIV的完全替代,实际上两者是相辅相成的。每个虚拟的HBA设备仍然需要一个虚拟的WWPN,最简单有效的方式莫过于直接用NPIV生成并分配给虚拟设备。虚拟化的方案可以参考网卡的虚拟化。第一种方式可以用软件模拟(Emulation),适应性最好,可以支持任何的物理HBA,缺点是实现较复杂且对系统性能影响较大。另外一种方式就是通过SR-IOV(Single-RootI/O Virtualization)技术实现,需要物理HBA和虚拟机平台对SR-IOV的同时支持。FCHBA对SR-IOV的支持目前虽然还没有正式的产品出现,但已经指日可待了:QLogic即将于2012年下半年推出2600系列的HBA,其中就有对SR-IOV的支持。虚拟平台方面,XEN和KVM已经实现了对SR-IOV的支持,Hype-V即将在下一版本支持,VMware的计划尚不明晰。SR-IOV技术可以让一个物理PCIe设备对上层软件提供多个独立的虚拟的PCIe设备并提供虚拟通道来实现并发的访问,有兴趣了解详细情况的可以看看——“What is SR-IOV?”
虚拟机动态迁移(Live Migration)的新挑战
最早的虚拟机动态迁移通常有以下的一些前提条件(以VMware为例):(1)源ESX和目标ESX必须置于同一vCenter管理下;(2)虚拟机所在的datastore必须是源ESX和目标ESX共享的;等等。如果虚拟机要使用NPIV技术,则必须使用通过RDM方式直接绑定到存储系统提供的LUN。这种情况下动态迁移是不是还能成功呢?
事实上,目前VMware已经有条件地提供了支持,只要额外满足以下条件:(1)源ESX和目标ESX上的HBA都支持NPIV;(2)虚拟机使用了NPIV技术;(3)虚拟机使用虚拟(非物理)兼容性的RDM;(4)源ESX和目标ESX上HBA的物理WWPN和虚拟机所使用的LUN必须划分在一个zone里。如果我们能够显式地将HBA虚拟化,那么最后一点条件也可以去掉。
软件定义的网络——存储交换机的进化
软件定义的网络(Software-definedNetworking,SDN)如今是业界的一个新宠儿,其代表性的实现就是OpenFlow。大家平时关注新闻的话,可能听说过Google最近的一个大动作——在今年的开放网络峰会(OpenNetworking Summit)上宣布在企业内部全面部署OpenFlow。SDN的作用并不仅限于将交换机的控制模块和数据模块分离,然后用一个流控制器进行流表的统一管理。更重要的是它提供了一种反馈机制,即网络路径可以动态地重新计算,以避免在某些节点上出现数据拥塞,从而能够确保卓越的客户体验和更好的服务水平协议。除此之外,SDN还提供了对可编程性的支持,使得安全、优化等高级特性的实现成为可能。存储交换机和以太网交换机的设计理念有颇多相似之处,那么SDN/ OpenFlow的思想是否也能够应用于存储交换机呢?这个问题目前目前好像甚少有人关注,欢迎大家来一起讨论。