【网络爬虫】爬取豆瓣电影Top250评论
前言
本爬虫大致流程为:
(1)分析网页——分析网站结构
(2)发送请求——通过requests发送请求
(3)响应请求——得到请求响应的页面
(4)解析响应——分析页面,得到想要的数据
(5)存储文本——以txt格式存储
使用环境
- anaconda3
- python3.6
- jupyter notebook
用到的库
- requests
- lxml
- urllib
- re
库的安装很简单,自行百度
中文简体和繁体转换所需Python库,用于将评论中的繁体字转为简体字
下载zh_wiki.py 和 langconv
- zh_wiki.py: https://github.com/skydark/nstools/blob/master/zhtools/zh_wiki.py
- langconv.py: https://github.com/skydark/nstools/blob/master/zhtools/langconv.py
下载后,将这两个py文件放在代码同一个目录下,即可
(1)分析网页
豆瓣电影Top250打开如下图:
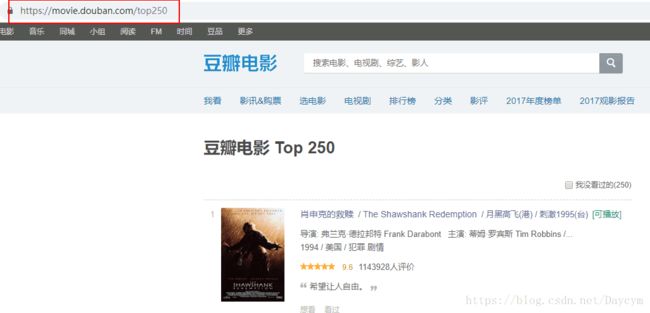
下面我们点击下一页,观察网址的变化
一开始打开第一页时为 https://movie.douban.com/top250 ,我们点击第2页后再点击第1页,发现如下:
- 第1页:https://movie.douban.com/top250?start=0&filter=
- 第2页:https://movie.douban.com/top250?start=25&filter=
- 第3页:https://movie.douban.com/top250?start=50&filter=
我们发现,只有start变量在变化,而且每次加25,正好是每页电影的个数
要想获得每部电影的评论,我们首先要进入这部电影评论的地方
下面我们就要看每部电影的评论
随便点击一部电影,https://movie.douban.com/subject/1292052/
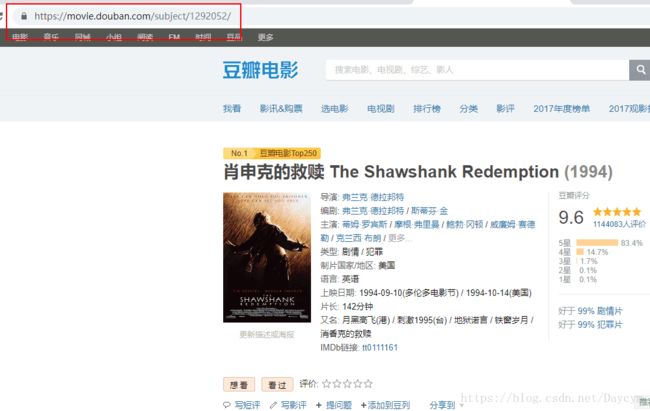
查看全部评论
同样,一开始第一页的参数不全,我们先点评论第2页,再点第1页,如上图:
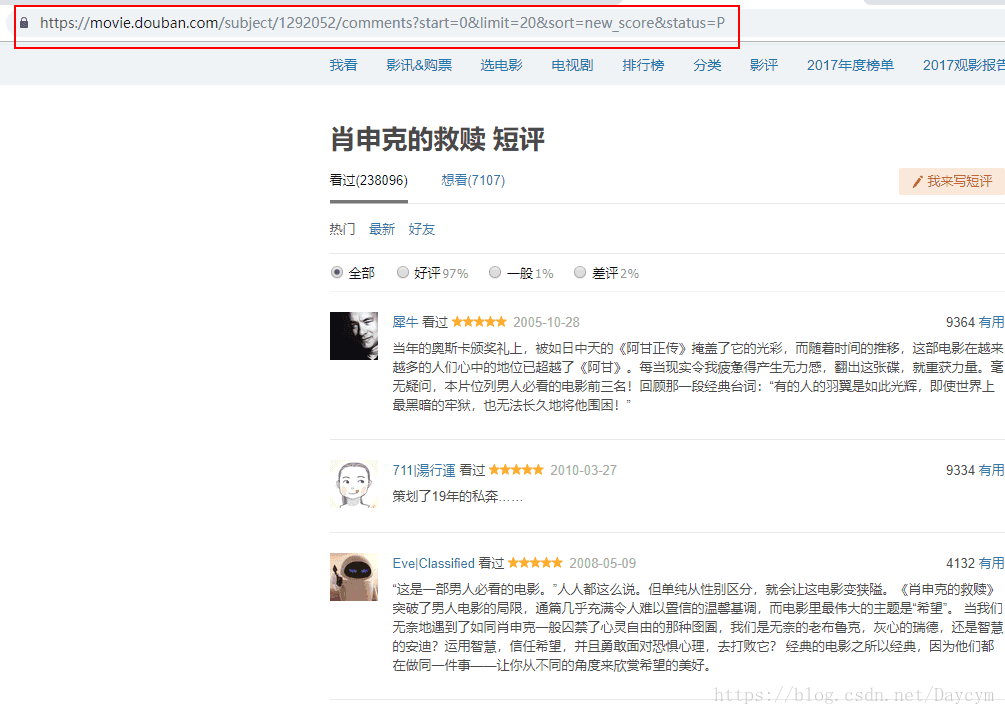
我们发现,每页评论的链接如下:
第1页:https://movie.douban.com/subject/1292052/comments?start=0&limit=20&sort=new_score&status=P
第2页:https://movie.douban.com/subject/1292052/comments?start=20&limit=20&sort=new_score&status=P
第3页:https://movie.douban.com/subject/1292052/comments?start=40&limit=20&sort=new_score&status=P
只有start变量在变,每次增加20,正好是每页的评论数目
再点击其他一部,https://movie.douban.com/subject/1291546/
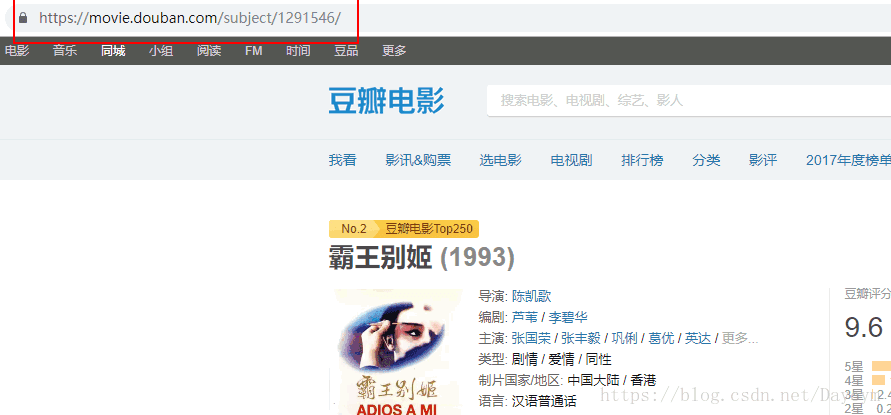
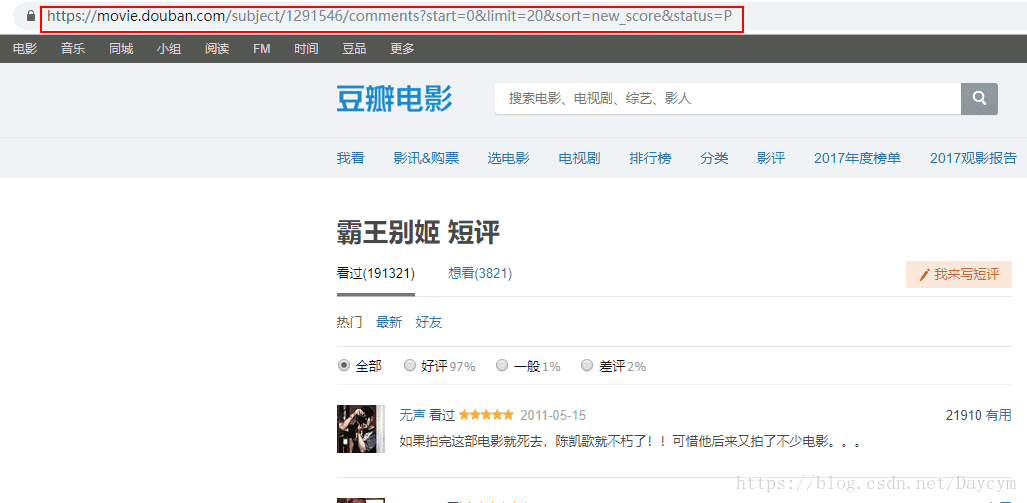
我们发现,https://movie.douban.com/subject/1291546/comments?start=0&limit=20&sort=new_score&status=P
每部电影之间除了中间的数字1291546不一样,这个应该是电影的编号,在每个编号下,评论链接的变化规律是一样的
要是我们知道每一部电影的编号,那岂不是所有的问题都解决了?
很庆幸,这个编号是很容易获取的。
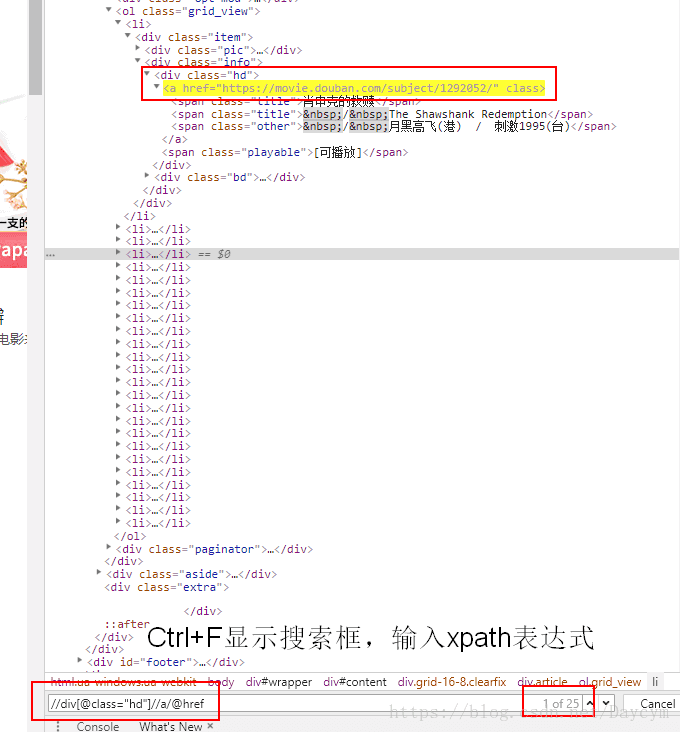
在top250页面下打开开发者工具(F12)
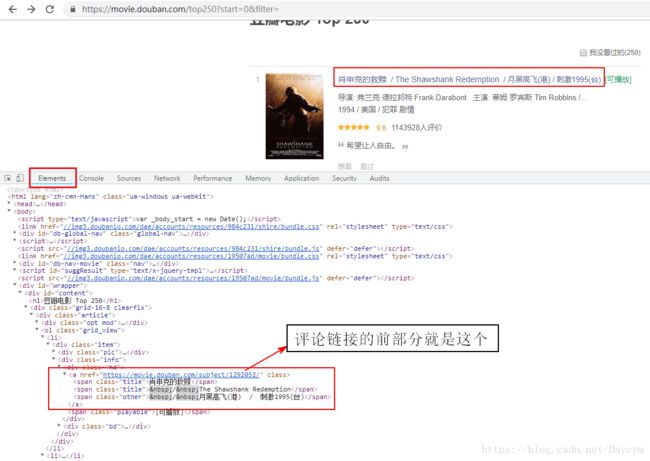
图中红框内,便是评论链接的前部分,那我们就可通过top页面,获取每一个中每部电影的评论链接
通过一系列链接的拼接就可以获得每部电影的评论地址,然后再通过评论链接获取评论页面,再获取评论文本,这样就可以了
流程如下:
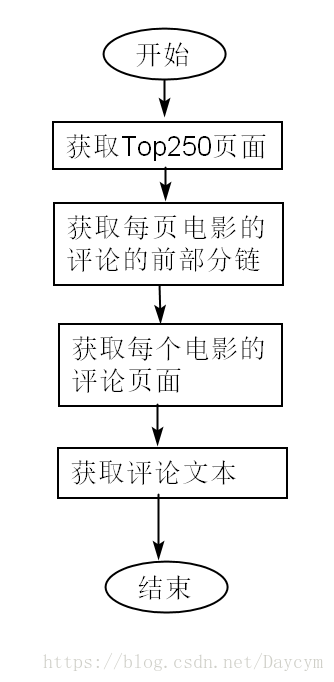
(2)发送请求,响应请求,解析网页
需要导入的库:
import requests # 请求库
from urllib.parse import urlencode # 解析链接
from lxml import etree # 解析页面
import langconv
import re # 正则表达式,用去匹配去除评论中的符合
- 获取Top250页面
# 获取电影排行页面
def get_top_page(start):
params = {
'start': start,
'filter': '',
}
url = 'https://movie.douban.com/top250?' + urlencode(params)
print(url)
try:
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/68.0.3440.106 Safari/537.36'
}
response = requests.get(url,headers=headers)
if response.status_code == 200:
return response.text
return None
except RequestException:
print('get_top_page() Error')
return None
# 测试
top_page = get_top_page(0) # 获取第1页的页面html
print(top_page)
- 获取每页电影链接
# 获取每页每部电影的评论链接前部分
def get_comment_link(top_page):
html = etree.HTML(top_page)
result = html.xpath('//div[@class="hd"]//a/@href') # 分析上面得到的页面获得
return result
# 测试
comment_link = get_comment_link(top_page)
print(comment_link)
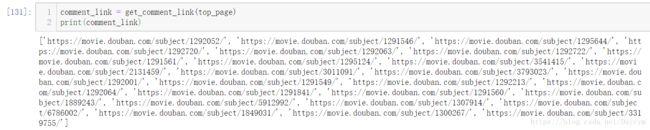
这样我们就获得了第1页里面每部电影的评论链接的前部分
- 获取评论页面
# 根据评论链接,获取评论页面
def get_comment_page(comment_link,start):
params = {
'start': start,
'limit': '20',
'sort':'new_score',
'status':'P'
}
url = comment_link +'comments?'+ urlencode(params)
try:
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/68.0.3440.106 Safari/537.36'
}
response = requests.get(url,headers=headers)
if response.status_code == 200:
return response.text
return 'Error'
except RequestException:
print('get_comment_page() Error')
return None
- 根据评论页面获取评论
# 根据评论页面获取评论
def get_comment(comment_page):
html = etree.HTML(comment_page)
result = html.xpath('//div[@class="mod-bd"]//div/div[@class="comment"]/p/span/text()') # 类似前面的方法,找节点
return result
(3)存储数据
- 繁体字转为简体字
import langconv
def Traditional2Simplified(sentence): # 将sentence中的繁体字转为简体字
sentence = langconv.Converter('zh-hans').convert(sentence)
return sentence
- 评论数据清理
import re
# 清理一下评论数据
def clear(string):
string = string.strip() # 去掉空格等空白符号
string = re.sub("[A-Za-z0-9]", "", string) # 去掉英文字母 数字
string = re.sub(r"[!!?。。,&;"★#$%&'()*+-/:;<=>@[\]^_`{|}~⦅⦆「」、、〃「」『』【】"
r"〔〕〖〗〘〙#〚〛〜〝〞/?=~〟,〰–—‘’‛“”„‟…‧﹏.]", " ", string) # 去掉中文符号
string = re.sub(r"[!\'\"#。$%&()*+,-.←→/:~;<=>?@[\\]^_`_{|}~", " ", string) # 去掉英文符号
return Traditional2Simplified(string).lower() # 所有的英文都换成小写
- 存为txt文件
# 存储评论
def save_to_txt(results):
for result in results:
result = clear(result)
# print(result)
with open('comment1.txt','a',encoding='utf-8') as file:
file.write(result)
file.write('\n'+'='*50+'\n')
完整代码
import requests # 请求库
from urllib.parse import urlencode # 解析链接
from lxml import etree # 解析页面
import langconv
import re # 正则表达式,用去匹配去除评论中的符合
# 获取电影排行页面
def get_top_page(start):
params = {
'start': start,
'filter': '',
}
url = 'https://movie.douban.com/top250?' + urlencode(params)
print(url)
try:
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/68.0.3440.106 Safari/537.36'
}
response = requests.get(url,headers=headers)
if response.status_code == 200:
return response.text
return None
except RequestException:
print('get_top_page() Error')
return None
# 获取每页每部电影的评论链接
def get_comment_link(top_page):
html = etree.HTML(top_page)
result = html.xpath('//div[@class="hd"]//a/@href') # 通过..获取父节点
return result
# 根据评论链接,获取评论页面
def get_comment_page(comment_link,start):
params = {
'start': start,
'limit': '20',
'sort':'new_score',
'status':'P'
}
url = comment_link +'comments?'+ urlencode(params)
try:
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/68.0.3440.106 Safari/537.36'
}
response = requests.get(url,headers=headers)
if response.status_code == 200:
return response.text
return 'Error'
except RequestException:
print('get_comment_page() Error')
return None
# 根据评论页面获取评论
def get_comment(comment_page):
html = etree.HTML(comment_page)
result = html.xpath('//div[@class="mod-bd"]//div/div[@class="comment"]/p/span/text()') # 通过..获取父节点
return result
# 将sentence中的繁体字转为简体字
def Traditional2Simplified(sentence):
sentence = langconv.Converter('zh-hans').convert(sentence)
return sentence
# 清理一下评论数据
def clear(string):
string = string.strip() # 去掉空格等空白符号
string = re.sub("[A-Za-z0-9]", "", string) # 去掉英文字母 数字
string = re.sub(r"[!!?。。,&;"★#$%&'()*+-/:;<=>@[\]^_`{|}~⦅⦆「」、、〃「」『』【】"
r"〔〕〖〗〘〙#〚〛〜〝〞/?=~〟,〰–—‘’‛“”„‟…‧﹏.]", " ", string) # 去掉中文符号
string = re.sub(r"[!\'\"#。$%&()*+,-.←→/:~;<=>?@[\\]^_`_{|}~", " ", string) # 去掉英文符号
return Traditional2Simplified(string).lower() # 所有的英文都换成小写
# 存储评论
def save_to_txt(results):
for result in results:
result = clear(result)
# print(result)
with open('comment.txt','a',encoding='utf-8') as file:
file.write(result)
file.write('\n'+'='*50+'\n')
# 运行
print("爬取开始...")
for start in range(0,250,25): # 可以爬取第一页,减少爬虫时间
print("正在爬取第"+str(int(start/25+1))+"页!!!")
#print(start)
top_page = get_top_page(start)
comment_link = get_comment_link(top_page)
#print(comment_link)
for i in range(25):
print("正在爬取第"+str(i)+"个电影!!!")
#print(comment_link[i])
for j in range(0,100,20):
comment_page = get_comment_page(comment_link[i],j)
results = get_comment(comment_page)
save_to_txt(results)
print("爬取第"+str(i)+"个电影结束")
爬取结果
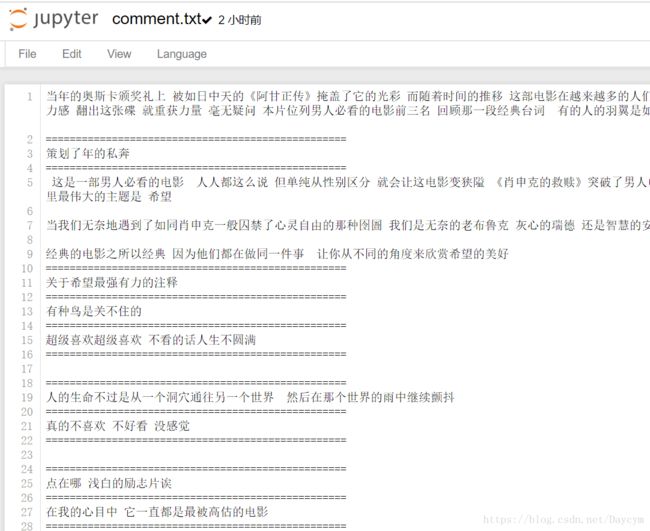
我没爬完,可以通过修改参数,只爬取第一页每部电影的前100条评论
总结
\quad\quad 在做这个爬虫前,我看了一些相关的书,了解大致流程,和一些库的使用,很明显代码不是最简化的,但是对于一个初学者来说挺有成就感,希望再接再厉,继续加油!!!
- 在爬取的过程中,可能出现IP被封锁,网站可能设定了IP访问次数限制——解决方法:可以使用代理
- 只爬取了评论,可以将电影名称和评论对应起来,另外,还可以将好评/坏评分别标记每条评论,以便以后对文本数据进行一些情感分析啥的,这样就不用自己条件标签了
- 还可以以其他方式存储数据,如数据库