「Python爬虫系列讲解」十四、基于开发者工具 Network 的数据抓包技术
本专栏是以杨秀璋老师爬虫著作《Python网络数据爬取及分析「从入门到精通」》为主线、个人学习理解为主要内容,以学习笔记形式编写的。
本专栏不光是自己的一个学习分享,也希望能给您普及一些关于爬虫的相关知识以及提供一些微不足道的爬虫思路。
专栏地址:Python网络数据爬取及分析「从入门到精通」
更多爬虫实例详见专栏:Python爬虫牛刀小试

前文回顾:
「Python爬虫系列讲解」一、网络数据爬取概述
「Python爬虫系列讲解」二、Python知识初学
「Python爬虫系列讲解」三、正则表达式爬虫之牛刀小试
「Python爬虫系列讲解」四、BeautifulSoup 技术
「Python爬虫系列讲解」五、用 BeautifulSoup 爬取电影信息
「Python爬虫系列讲解」六、Python 数据库知识
「Python爬虫系列讲解」七、基于数据库存储的 BeautifulSoup 招聘爬取
「Python爬虫系列讲解」八、Selenium 技术
「Python爬虫系列讲解」九、用 Selenium 爬取在线百科知识
「Python爬虫系列讲解」十、基于数据库存储的 Selenium 博客爬虫
「Python爬虫系列讲解」十一、基于登录分析的 Selenium 微博爬虫
「Python爬虫系列讲解」十二、基于图片爬取的 Selenium 爬虫
「Python爬虫系列讲解」十三、用 Scrapy 技术爬取网络数据
目录
1 了解相关概念
1.1 数据包
1.1.1 Headers
1.1.2 Preview 和 Response
1.2 抓包
2 基于开发者工具 Network 的数据抓包实例
3 本文小结
前十三讲主要介绍了运用正则表达式、BeautifulSoup 技术、Selenium 技术等的基本爬取方法,这些都是基于开发者工具 Elements 进行的爬取。而在实际应用过程中,可能会发现,我们所需要的语料信息往往会被封装在一些数据包中进行传输,对于这些目标数据,如果再基于 Elements 进行爬取,未免显得有些臃肿;因此,为了很好地解决这一问题,本文将介绍一种基于开发者工具 Network 的数据抓包技术。
1 了解相关概念
1.1 数据包
包(Packet) 是 TCP/IP 协议通信传输中的数据单位,一般也称 “数据包”(Data Packet)。
TCP/IP 协议是工作在 OSI 模型第三层(网络层)、第四层(传输层)上的,帧工作在第二层(数据链路层)。上一层的内容由下一层的内容来传输,所以在局域网中,“包” 是包含在 “帧” 里的。
本文讲解的,就是爬取目标数据包的基本方法;如下图所示,键盘按下 F12 键并点击 Network 即可查看该页面加载的所有数据包

上图中红框圈起来的部分就是数据抓包常用查看的 3 个具体位置。第一个红框是Network标签页,Network标签页对于分析网站请求的网络情况、查看某一请求的请求头和响应头还有响应内容很有用,特别是在查看Ajax类请求的时候,非常有帮助。第二个红框是对数据包的细分类:比如 All 可查看所有数据包、XHR 是查看动态加载页面的一些数据包等,第三个红框是数据包部分。
那么,对于数据包部分,下面介绍其每一列的含义:
- 第一列 Name:请求的名称,一般会将 URL 的最后一 部分内容当作名称。
- 第二列 Status:响应的状态码,这里显示为 200,代表响应是正常的。通过状态码,我们可以判断发送了请求之后是否得到了正常的响应。
- 第三列 Type:请求的文档类型。这里为 document,代表我们这次请求的是一个 HTML 文档,内容就是一些 HTML 代码。
- 第四列 initiator:请求源。用来标记请求是由哪个对象或进程发起的。
- 第五列 Size:从服务器下载的文件和请求的资源大小。如果是从缓存中取得的资源,则该列会显示 from cache。
- 第六列 Time:发起请求到获取响应所用的总时间。
- 第七列 Waterfall:网络请求的可视化瀑布流。
点击某一具体数据包,发现有 Headers、Preview、Response、Initiator、Timing 等 5 项内容。
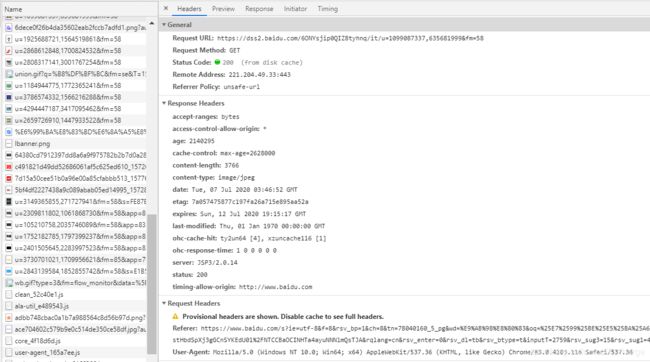
1.1.1 Headers
对于 headers 中的信息,从大的方面又分为 General、Response Headers、Request Headers 等 3 类。
General:放置常规信息
Request URL:资源的请求 url
Request Method:HTTP方法
| GET |
发送请求来获得服务器上的资源,请求体中不会包含请求数据,请求数据放在协议头中。另外get支持快取、缓存、可保留书签等。 |
| POST |
和get一样很常见,向服务器提交资源让服务器处理,比如提交表单、上传文件等,可能导致建立新的资源或者对原有资源的修改。提交的资源放在请求体中。 |
| HEAD |
本质和get一样,但是响应中没有呈现数据,而是http的头信息,主要用来检查资源或超链接的有效性或是否可以可达、检查网页是否被串改或更新,获取头信息等,特别适用在有限的速度和带宽下 |
| PUT |
和post类似,html表单不支持,发送资源与服务器,并存储在服务器指定位置,要求客户端事先知道该位置;比如post是在一个集合上(/province),而put是具体某一个资源上(/province/123)。所以put是安全的,无论请求多少次,都是在123上更改。 |
| DELETE |
请求服务器删除某资源。和put都具有破坏性,可能被防火墙拦截。如果是 HTTP 协议则无需担心 |
| CONNECT |
HTTP/1.1协议中预留给能够将连接改为管道方式的代理服务器。就是把服务器作为跳板,去访问其他网页然后把数据返回回来,连接成功后,就可以正常的get、post了。 |
| OPTIONS |
获取http服务器支持的http请求方法,允许客户端查看服务器的性能,比如ajax跨域时的预检等 |
| TRACE |
回显服务器收到的请求,主要用于测试或诊断。一般禁用,防止被恶意攻击或盗取信息 |
Status Code:响应状态码
- 200:(状态码) OK
- 301:资源(网页等)被永久转移到其它URL
- 401:访问资源的权限不够。
- 403:没有权限访问资源。
- 404:需要访问的资源不存在。
- 405:需要访问的资源被禁止。
- 500:内部服务器错误
Remote Address:请求的远程地址
Referrer Policy:在页面引入图片、JS 等资源,或者从一个页面跳到另一个页面,都会产生新的 HTTP 请求,浏览器一般都会给这些请求头加上表示来源的 Referrer 字段。新的 Referrer Policy 规定了五种 Referrer 策略:No Referrer、No Referrer When Downgrade、Origin Only、Origin When Cross-origin、和Unsafe URL。
- No Referrer:任何情况下都不发送Referrer信息
- No Referrer When Downgrade:仅当发生协议降级(如 HTTPS 页面引入 HTTP 资源,从 HTTPS 页面跳到 HTTP 等)时不发送Referrer 信息。这个规则是现在大部分浏览器默认所采用的
- Origin Only:发送只包含 host 部分的 Referrer。启用这个规则,无论是否发生协议降级,无论是本站链接还是站外链接,都会发送 Referrer 信息,但是只包含协议 + host 部分(不包含具体的路径及参数等信息)
- Origin When Cross-origin:仅在发生跨域访问时发送只包含 host 的 Referrer,同域下还是完整的。它与 Origin Only 的区别是多判断了是否 Cross-origin。需要注意的是协议、域名和端口都一致,才会被浏览器认为是同域
- Unsafe URL:无论是否发生协议降级,无论是本站链接还是站外链接,统统都发送 Referrer 信息。正如其名,这是最宽松而最不安全的策略
Response Headers:
- Cache-Control:告诉浏览器或者其他客户,什么环境可以安全地缓存文档
- Connection:当 client 和 server 通信时对于长链接如何进行处理
- Content-Encoding:数据在传输过程中所使用的压缩编码方式
- Content-Type:数据的类型
- Date:数据从服务器发送的时间
- Expires:应该在什么时候认为文档已经过期,从而不再缓存它?
- Server:服务器名字。Servlet 一般不设置这个值,而是由 Web 服务器自己设置
- Set-Cookie:设置和页面关联的 cookie
- Transfer-Encoding:数据传输的方式
Request Headers:
- Accept:表示浏览器支持的 MIME 类型
- Accept-Encoding:浏览器支持的压缩类型
- Accept-Language:浏览器支持的语言类型,并且优先支持靠前的语言类型
- Cache-Control:指定请求和响应遵循的缓存机制
- Connection:当浏览器与服务器通信时对于长连接如何进行处理:close/keep-alive
- Cookie:向服务器返回 cookie,这些 cookie 是之前服务器发给浏览器的
- Host:请求的服务器 URL
- Referer:该页面的来源 URL
- User-Agent:用户客户端的一些必要信息
1.1.2 Preview 和 Response
一般情况下我们看 Network 里面的 Preview 和 Response 的结果似乎一模一样。
不管是请求页面,请求页面还是请求 js 还是请求 css,二者的结果都一样。直到今天从服务器端向 web 前端发送一段 json 格式的数据,才发现 Preview 的特殊功效。
在 Preview(预览功能) 中,控制台会把发送过来的 json 数据自动转换成 javascript 的对象格式。
而且可以层层展开,方便前端工程师遍历调用(特别是在多维的情况下)。

后面三部分一般用不到,这里就不在赘述了,有兴趣的读者可以自行查阅学习。
1.2 抓包
抓包(packet capture)就是将网络传输发送与接收的数据包进行截获、重发、编辑、转存等操作,也用来检查网络安全。抓包也经常被用来进行数据截取等。
事实上,市面上有很多的抓包工具。抓包工具是拦截查看网络数据包内容的软件。通过对抓获的数据包进行分析,可以得到有用的信息。流行的抓包工具有很多,比较出名的有wireshark、sniffer、httpwatch、iptool等。这些抓包工具功能各异,但基本原理相同。我们的计算机通过向网络上传和从网络下载一些数据包来实现数据在网络中的传播。通常这些数据包会由发出或者接受的软件自行处理,普通用户并不过问,这些数据包一般也不会一直保存在用户的计算机上。抓包工具可以帮助我们将这些数据包保存下来,如果这些数据包是以明文形式进行传送或者我们能够知道其加密方法,那么我们就可以分析出这些数据包的内容以及它们的用途。
2 基于开发者工具 Network 的数据抓包实例
这里就引用我之前写过的一片博文做一讲解:
具体而言,本部分实例采用爬取B站视频弹幕并绘制词云图。
b站视频选取的是5月7日的热门视频:我的NBA手办真的会打球!!!
第一步,F12键找到弹幕对应的list标签。
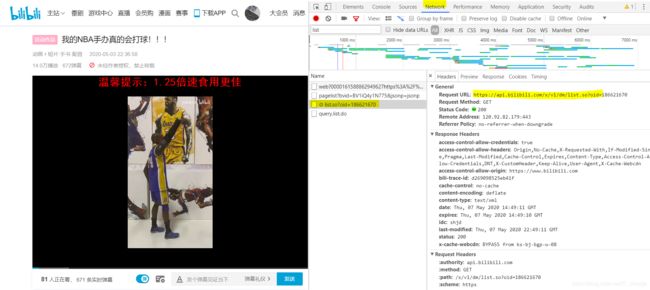
打开list标签 Request URL,得到一条条的弹幕,这正是我们所谓的目标页面。


第二步,获取弹幕网URL,采用正则表达式的匹配模式,得到所有弹幕并输出到指定文件夹的指定文件中。
导入包库
import requests #发出请求
import re #内置库 用于匹配正则表达式
import csv #文件格式获取 URL
url = 'https://api.bilibili.com/x/v1/dm/list.so?oid=186621670'设置请求头,伪装爬虫程序,避开反爬虫机制

headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/81.0.4044.129 Safari/537.36"
}
发送请求,获得响应
response = requests.get(url,headers=headers)
html_doc = response.content.decode('utf-8')正则表达式匹配
re.compile('(.*?)') 保存爬取数据
with open('F:/b站视频弹幕.txt','a',newline='',encoding='utf-8-sig') as file:
writer = csv.writer(file)
danmu = []
danmu.append(i)
writer.writerow(danmu)
第三步,采用jieba库分词,并用wordcloud库美化得到图片文件。
mk = imageio.imread(r'F:/basketball.png')
w = wordcloud.WordCloud(width=1000,
height=700,
background_color='white',
font_path='C:/Windows/SIMLI.TTF',
mask=mk,
scale=15,
stopwords={' '},
contour_width=5,
contour_color='red'
)
w.generate(string)
w.to_file('gaijinwordcloud.png')下面给出完整代码:
import imageio as imageio #加载图片
import requests #发出请求
import re #内置库 用于匹配正则表达式
import csv #文件格式
import jieba #中文分词
import wordcloud #绘制词云
# 目标网站(即我们获取到的URL)
url = 'https://api.bilibili.com/x/v1/dm/list.so?oid=186803402'
# 设置请求头 伪装浏览器
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/81.0.4044.129 Safari/537.36"
}
# 发起请求 获得响应
response = requests.get(url,headers=headers)
html_doc = response.content.decode('utf-8')
# 正则表达式的匹配模式
res = re.compile('(.*?)')
# 根据模式提取网页数据
danmu = re.findall(res,html_doc)
# 保存数据
for i in danmu:
with open('b站弹幕.csv','a',newline='',encoding='utf-8-sig') as file:
writer = csv.writer(file)
danmu = []
danmu.append(i)
writer.writerow(danmu)
# 显示数据
f = open('F:/b站视频弹幕.txt',encoding='utf-8')
txt = f.read()
txt_list = jieba.lcut(txt)
# print(txt_list)
string = ' '.join((txt_list))
print(string)
# 很据得到的弹幕数据绘制词云图
mk = imageio.imread(r'F:/basketball.png')
w = wordcloud.WordCloud(width=1000,
height=700,
background_color='white',
font_path='C:/Windows/SIMLI.TTF',
mask=mk,
scale=15,
stopwords={' '},
contour_width=5,
contour_color='red'
)
w.generate(string)
w.to_file('gaijinwordcloud.png') 代码运行最终效果展示:



至此,完整的基于开发者工具 Network 的数据抓包实例也全部讲解完毕了,而且整个 Python 爬取网络数据部分的知识也介绍完了,更多爬虫知识还需结合实际需求和项目进行深入学习,爬取自己所需的数据集。
3 本文小结
在实际爬取过程中,往往会遇到向上述实例所讲的那样,目标数据全部被封装在一个数据包中,这时,若采用之前讲述的 Elements 下的爬取方式可能会使代码冗肿量大,不利于编写修改,这时我们采用基于开发者工具 Network 的数据抓包技术就可以完美的解决这一问题。
欢迎留言,一起学习交流~
感谢阅读
END