gpgpu-sim manual
http://gpgpu-sim.org/manual/index.php/Main_Page
https://github.com/gpgpu-sim/gpgpu-sim_distribution
Contents
- 1 Introduction
- 1.1 Contributors
- 1.1.1 Contributing Authors to this Manual
- 1.1.2 Contributors to GPGPU-Sim version 3.x
- 1.1 Contributors
- 2 Microarchitecture Model
- 2.1 Overview
- 2.1.1 Accuracy
- 2.1.2 Top-Level Organization
- 2.1.3 Clock Domains
- 2.2 SIMT Core Clusters
- 2.3 SIMT Cores
- 2.3.1 Front End
- 2.3.1.1 Fetch and Decode
- 2.3.1.2 Instruction Issue
- 2.3.1.3 SIMT Stack
- 2.3.1.4 Scoreboard
- 2.3.2 Register Access and the Operand Collector
- 2.3.3 ALU Pipelines
- 2.3.4 Memory Pipeline (LDST unit)
- 2.3.4.1 L1 Data Cache
- 2.3.4.2 Texture Cache
- 2.3.4.3 Constant (Read only) Cache
- 2.3.5 Thread Block / CTA / Work Group Scheduling
- 2.3.1 Front End
- 2.4 Interconnection Network
- 2.4.1 Concentration
- 2.4.2 Interface with GPGPU-Sim
- 2.5 Memory Partition
- 2.5.1 Memory Partition Connections and Traffic Flow
- 2.5.2 L2 Cache Model and Cache Hierarchy
- 2.5.3 Atomic Operation Execution Phase
- 2.5.4 DRAM Scheduling and Timing Model
- 2.5.4.1 FIFO Scheduler
- 2.5.4.2 FR-FCFS
- 2.5.4.3 DRAM Timing Model
- 2.6 Instruction Set Architecture (ISA)
- 2.6.1 PTX and SASS
- 2.6.2 PTXPlus
- 2.6.3 From SASS to PTXPlus
- 2.1 Overview
- 3 Using GPGPU-Sim
- 3.1 Simulation Modes
- 3.1.1 Performance Simulation
- 3.1.2 Pure Functional Simulation
- 3.1.3 Interactive Debugger Mode
- 3.1.4 Cuobjdump Support
- 3.1.5 PTX vs. PTXPlus
- 3.1.5.1 Addressing Modes
- 3.1.5.2 New Data Types
- 3.1.5.3 PTXPlus Instructions
- 3.1.5.4 PTXPlus Condition Codes and Instruction Predication
- 3.1.5.5 Parameter and Thread ID (tid) Initialization
- 3.2 Debugging via Prints and Traces
- 3.2.1 Environment Variables for Debugging
- 3.2.2 GPGPU-Sim debug tracing
- 3.3 Configuration Options
- 3.3.1 Interconnection Configuration
- 3.3.1.1 Topology Configuration
- 3.3.1.2 Booksim options added by GPGPU-Sim
- 3.3.1.3 Booksim Options ignored by GPGPU-Sim
- 3.3.2 Clock Domain Configuration
- 3.3.2.1 clock Special Register
- 3.3.1 Interconnection Configuration
- 3.4 Understanding Simulation Output
- 3.4.1 General Simulation Statistics
- 3.4.2 Simple Bottleneck Analysis
- 3.4.3 Memory Access Statistics
- 3.4.4 Memory Sub-System Statistics
- 3.4.5 Control-Flow Statistics
- 3.4.6 DRAM Statistics
- 3.4.7 Cache Statistics
- 3.4.8 Interconnect Statistics
- 3.5 Visualizing High-Level GPGPU-Sim Microarchitecture Behavior
- 3.6 Visualizing Cycle by Cycle Microarchitecture Behavior
- 3.7 Debugging Errors in Performance Simulation
- 3.7.1 Segmentation Faults, Aborts and Failed Assertions
- 3.7.2 Deadlocks
- 3.8 Frequently Asked Questions
- 3.1 Simulation Modes
- 4 Software Design of GPGPU-Sim
- 4.1 File list and brief description
- 4.1.1 Overall/Utilities
- 4.1.2 cuda-sim
- 4.1.3 gpgpu-sim
- 4.1.4 intersim
- 4.2 Option Parser
- 4.3 Abstract Hardware Model
- 4.3.1 Hardware Abstraction Model Objects
- 4.4 GPGPU-sim - Performance Simulation Engine
- 4.4.1 Performance Model Software Objects
- 4.4.1.1 SIMT Core Cluster Class
- 4.4.1.2 SIMT Core Class
- 4.4.1.2.1 Fetch and Decode Software Model
- 4.4.1.2.2 Schedule and Issue Software Model
- 4.4.1.2.3 SIMT Stack Software Model
- 4.4.1.2.4 Scoreboard Software Model
- 4.4.1.2.5 Operand Collector Software Model
- 4.4.1.2.6 ALU Pipeline Software Model
- 4.4.1.2.7 Memory Stage Software Model
- 4.4.1.2.8 Cache Software Model
- 4.4.1.2.9 Thread Block / CTA / Work Group Scheduling
- 4.4.1.3 Interconnection Network
- 4.4.1.4 Clock domain crossing for intersim
- 4.4.1.4.1 Ejecting a packet from network
- 4.4.1.4.2 Ejection interface details
- 4.4.1.4.3 Injecting a packet to the network
- 4.4.1.5 Memory Partition
- 4.4.1.5.1 Memory Partition Connections and Traffic Flow
- 4.4.1.5.2 L2 Cache Model
- 4.4.1.5.3 DRAM Scheduling and Timing Model
- 4.4.2 Interface between CUDA-Sim and GPGPU-Sim
- 4.4.3 Address Decoding
- 4.4.4 Output to AerialVision Performance Visualizer
- 4.4.5 Histogram
- 4.4.6 Dump Pipeline
- 4.4.1 Performance Model Software Objects
- 4.5 CUDA-sim - Functional Simulation Engine
- 4.5.1 Key Objects Descriptions
- 4.5.2 PTX extraction
- 4.5.2.1 From cubin
- 4.5.2.2 Using cuobjdump
- 4.5.3 PTX/PTXPlus loading
- 4.5.4 PTXPlus support
- 4.5.4.1 PTXPlus Conversion
- 4.5.4.2 Operation of cuobjdump_to_ptxplus
- 4.5.4.3 PTXPlus Implementation
- 4.5.5 Control Flow Analysis + Pre-decode
- 4.5.6 Memory Space Buffer
- 4.5.7 Global/Constant Memory Initialization
- 4.5.8 Kernel Launch: Parameter Hookup
- 4.5.9 Generic Memory Space
- 4.5.10 Instruction Execution
- 4.5.11 Interface to Source Code View in AerialVision
- 4.5.12 Pure Functional Simulation
- 4.6 Interface with outside world
- 4.6.1 Entry Point and Stream Manager
- 4.6.2 CUDA runtime library (libcudart)
- 4.6.3 OpenCL library (libopencl)
- 4.1 File list and brief description
Introduction
This manual provides documentation for GPGPU-Sim 3.x, a cycle-level GPU performance simulator that focuses on "GPU computing" (general purpose computation on GPUs). GPGPU-Sim 3.x is the latest version of GPGPU-Sim. It includes many enhancements to GPGPU-Sim 2.x. If you are trying to install GPGPU-Sim, please refer to the README file in the GPGPU-Sim distribution you are using. The README for most recent version of GPGPU-Sim can also be browsed online here.
This manual contains three major parts:
- A Microarchitecture Model section that describes the microarchitecture that GPGPU-Sim 3.x models.
- A Usage section that provides documentations on how to use GPGPU-Sim. This section provides information on the following:
- Different modes of simulation
- Configuration options (how to change high level parameters of the microarchitecture simulated)
- Simulation output (e.g., microarchitecture statistics)
- Visualizing microarchitecture behavior (useful for performance debugging)
- Strategies for debugging GPGPU-Sim when performance simulations crashes or deadlocks due to errors in the timing model.
- A Software Design section that explains the internal software design of GPGPU-Sim 3.x. The goal of that section is to provide a starting point for the users to extend GPGPU-Sim for their own research.
If you use GPGPU-Sim in your work please cite our ISPASS 2009 paper:
Ali Bakhoda, George Yuan, Wilson W. L. Fung, Henry Wong, Tor M. Aamodt,
Analyzing CUDA Workloads Using a Detailed GPU Simulator, in IEEE International
Symposium on Performance Analysis of Systems and Software (ISPASS), Boston, MA,
April 19-21, 2009.
To help reviewers you should indicate the version of GPGPU-Sim you used (e.g., "GPGPU-Sim version 3.1.0", "GPGPU-Sim version 3.0.2", "GPGPU-Sim version 2.1.2b", etc...).
The GPGPU-Sim 3.x source is available under a BSD style copyright from GitHub.
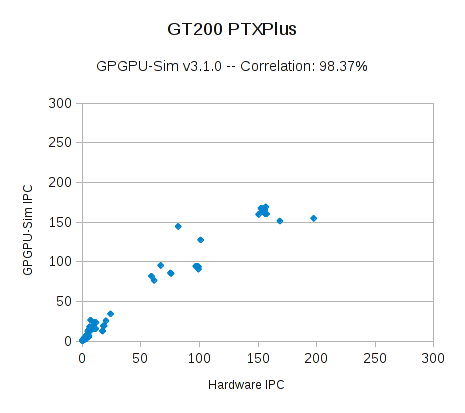
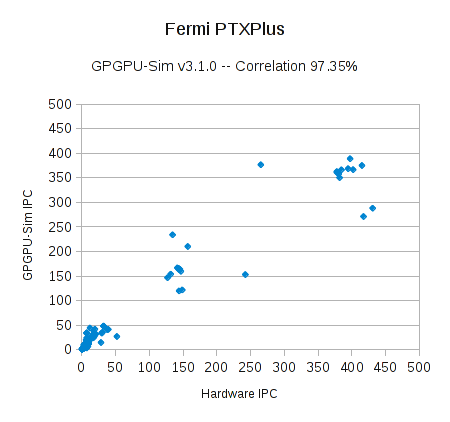
GPGPU-Sim version 3.1.0 running PTXPlus has a correlation of 98.3% and 97.3% versus GT200 and Fermi hardware on the RODINIA benchmark suite with scaled down problem sizes (see Figure 1 and Figure 2).
Please submit bug reports through the GPGPU-Sim Bug Tracking System. If you have further questions after reading the manual and searching the bugs database, you may want to sign up to the GPGPU-Sim Google Group.
Besides this manual, you may also want to consult the slides from our tutorial at ISCA 2012
Contributors
Contributing Authors to this Manual
Tor M. Aamodt, Wilson W. L. Fung, Inderpreet Singh, Ahmed El-Shafiey, Jimmy Kwa, Tayler Hetherington, Ayub Gubran, Andrew Boktor, Tim Rogers, Ali Bakhoda, Hadi Jooybar
Contributors to GPGPU-Sim version 3.x
Tor M. Aamodt, Wilson W. L. Fung, Jimmy Kwa, Andrew Boktor, Ayub Gubran, Andrew Turner, Tim Rogers, Tayler Hetherington
Microarchitecture Model
This section describes the microarchitecture modelled by GPGPU-Sim 3.x. The model is more detailed than the timing model in GPGPU-Sim 2.x. Some of the new details result from examining various NVIDIA patents. This includes the modelling of instruction fetching, scoreboard logic, and register file access. Other improvements in 3.x include a more detailed texture cache model based upon the prefetching texture cache architecture. The overall microarchitecture is first described, then the individual components including SIMT cores and clusters, interconnection network and memory partitions.
Overview
GPGPU-Sim 3.x runs program binaries that are composed of a CPU portion and a GPU portion. However, the microarchitecture (timing) model in GPGPU-Sim 3.x reports the cycles where the GPU is busy--it does not model either CPU timing or PCI Express timing (i.e. memory transfer time between CPU and GPU). Several efforts are under way to provide combined CPU plus GPU simulators where the GPU portion is modeled by GPGPU-Sim. For example, see http://www.fusionsim.ca/.
GPGPU-Sim 3.x models GPU microarchitectures similar to those in the NVIDIA GeForce 8x, 9x, and Fermi series. The intention of GPGPU-Sim is to provide a substrate for architecture research rather than to exactly model any particular commercial GPU. That said, GPGPU-Sim 3.x has been calibrated against an NVIDIA GT 200 and NVIDIA Fermi GPU architectures.
Accuracy
We calculated the correlation of the IPC (Instructions per Clock) versus that of real NVIDIA GPUs. When configured to use the native hardware instruction set (PTXPlus, using the -gpgpu_ptx_convert_to_ptxplus option),GPGPU-Sim 3.1.0 obtains IPC correlation of 98.3% (Figure 1) and 97.3% (Figure 2) respectively on a scaled down version of the RODINIA benchmark suite (about 260 kernel launches). All of the benchmarks described in [Che et. al. 2009] were included in our tests in addition to some other benchmarks from later versions of RODINIA. Each data point in Figure 1 and Figure 2 represents an individual kernel launch. Average absolute errors are 35% and 62% respectively due to some outliers.
We have included our spreadsheet used to calculate those correlations to demonstrate how the correlation coefficients were computed: File:Correlation.xls.
The GPU modeled by GPGPU-Sim is composed of Single Instruction Multiple Thread (SIMT) cores connected via an on-chip connection network to memory partitions that interface to graphics GDDR DRAM.
Top-Level Organization
An SIMT core models a highly multithreaded pipelined SIMD processor roughly equivalent to what NVIDIA calls an Streaming Multiprocessor (SM) or what AMD calls a Compute Unit (CU). The organization of an SIMT core is described in Figure 3 below.

Figure 3: Overall GPU Architecture Modeled by GPGPU-Sim
Clock Domains
GPGPU-Sim supports four independent clock domains: (1) the SIMT Core Cluster clock domain (2) the interconnection network clock domain (3) the L2 cache clock domain, which applies to all logic in the memory partition unit except DRAM, and (4) the DRAM clock domain.
Clock frequencies can have any arbitrary value (they do not need to be multiples of each other). In other words, we assume the existence of synchronizers between clock domains. In the GPGPU-Sim 3.x simulation model, units in adjacent clock domains communicate through clock crossing buffers that are filled at the source domain's clock rate and drained at the destination domain's clock rate.
SIMT Core Clusters
The SIMT Cores are grouped into SIMT Core Clusters. The SIMT Cores in a SIMT Core Cluster share a common port to the interconnection network as shown in Figure 4.

Figure 4: SIMT Core Clusters
As illustrated in Figure 4, each SIMT Core Cluster has a single response FIFO which holds the packets ejected from the interconnection network. The packets are directed to either a SIMT Core's instruction cache (if it is a memory response servicing an instruction fetch miss) or its memory pipeline (LDST unit). The packets exit in FIFO fashion. The response FIFO is stalled if a core is unable to accept the packet at the head of the FIFO. For generating memory requests at the LDST unit, each SIMT Core has its own injection port into the interconnection network. The injection port buffer however is shared by all the SIMT Cores in a cluster.
SIMT Cores
Figure 5 below illustrates the SIMT core microarchitecture simulated by GPGPU-Sim 3.x. An SIMT core models a highly multithreaded pipelined SIMD processor roughly equivalent to what NVIDIA calls an Streaming Multiprocessor (SM) [1] or what AMD calls a Compute Unit (CU) [2]. A Stream Processor (SP) or a CUDA Core would correspond to a lane within an ALU pipeline in the SIMT core.

Figure 5: Detailed Microarchitecture Model of SIMT Core
This microarchitecture model contains many details not found in earlier versions of GPGPU-Sim. The main differences include:
- A new front-end that models instruction caches and separates the warp scheduling (issue) stage from the fetch and decode stage
- Scoreboard logic enabling multiple instructions from a single warp to be in the pipeline at once
- A detailed model of an operand collector that schedules operand access to single ported register file banks (used to reduce area and power of the register file)
- Flexible model that supports multiple SIMD functional units. This allows memory instructions and ALU instructions to operate in different pipelines.
The following subsections describe the details in Figure 5 by going through each stage of the pipeline.
Front End
As described below, the major stages in the front end include instruction cache access and instruction buffering logic, scoreboard and scheduling logic, SIMT stack.
Fetch and Decode
The instruction buffer (I-Buffer) block in Figure 5 is used to buffer instructions after they are fetched from the instruction cache. It is statically partitioned so that all warps running on SIMT core have dedicated storage to place instructions. In the current model, each warp has two I-Buffer entries. Each I-Buffer entry has a valid bit, ready bit and a single decoded instruction for this warp. The valid bit of an entry indicates that there is a non-issued decoded instruction within this entry in the I-Buffer. While the ready bit indicates that the decoded instructions of this warp are ready to be issued to the execution pipeline. Conceptually, the ready bit is set in the schedule and issue stage using the scoreboard logic and availability of hardware resources (in the simulator software, rather than actually set a ready bit, a readiness check is performed). The I-Buffer is initially empty with all valid bits and ready bits deactivated.
A warp is eligible for instruction fetch if it does not have any valid instructions within the I-Buffer. Eligible warps are scheduled to access the instruction cache in round robin order. Once selected, a read request is sent to instruction cache with the address of the next instruction in the currently scheduled warp. By default, two consecutive instructions are fetched. Once a warp is scheduled for an instruction fetch, its valid bit in the I-Buffer is activated until all the fetched instructions of this warp are issued to the execution pipeline.
The instruction cache is a read-only, non-blocking set-associative cache that can model both FIFO and LRU replacement policies with on-miss or on-fill allocation policies. A request to the instruction cache results in either a hit, miss or a reservation fail. The reservation fail results if either the miss status holding register (MSHR) is full or there are no replaceable blocks in the cache set because all block are reserved by prior pending requests (see section Caches for more details). In both cases of hit and miss the round robin fetch scheduler moves to the next warp. In case of hit, the fetched instructions are sent to the decode stage. In the case of a miss a request will be generated by the instruction cache. When the miss response is received the block is filled into the instruction cache and the warp will again need to access the instruction cache. While the miss is pending, the warp does not access the instruction cache.
A warp finishes execution and is not considered by the fetch scheduler anymore if all its threads have finished execution without any outstanding stores or pending writes to local registers. The thread block is considered done once all warps within it are finished and have no pending operations. Once all thread blocks dispatched at a kernel launch finish, then this kernel is considered done.
At the decode stage, the recent fetched instructions are decoded and stored in their corresponding entry in the I-Buffer waiting to be issued.
The simulator software design for this stage is described in Fetch and Decode.
Instruction Issue
A second round robin arbiter chooses a warp to issue from the I-Buffer to rest of the pipeline. This round robin arbiter is decoupled from the round robin arbiter used to schedule instruction cache accesses. The issue scheduler can be configured to issue multiple instructions from the same warp per cycle. Each valid instruction (i.e. decoded and not issued) in the currently checked warp is eligible for issuing if (1) its warp is not waiting at a barrier, (2) it has valid instructions in its I-Buffer entries (valid bit is set), (3) the scoreboard check passes (see section Scoreboard for more details), and (4) the operand access stage of the instruction pipeline is not stalled.
Memory instructions (Load, store, or memory barriers) are issued to the memory pipeline. For other instructions, it always prefers the SP pipe for operations that can use both SP and SFU pipelines. However, if a control hazard is detected then instructions in the I-Buffer corresponding to this warp are flushed. The warp's next pc is updated to point to the next instruction (assuming all branches as not-taken). For more information about handling control flow, refer to SIMT Stack.
At the issue stage barrier operations are executed. Also, the SIMT stack is updated (refer to SIMT Stack for more details) and register dependencies are tracked (refer to Scoreboard for more details). Warps wait for barriers ("__syncthreads()") at the issue stage.
SIMT Stack
A per-warp SIMT stack is used to handle the execution of branch divergence on single-instruction, multiple thread (SIMT) architectures. Since divergence reduces the efficiency of these architectures, different techniques can be adapted to reduce this effect. One of the simplest techniques is the post-dominator stack-based reconvergence mechanism. This technique synchronizes the divergent branches at the earliest guaranteed reconvergence point in order to increase the efficiency of the SIMT architecture. Like previous versions of GPGPU-Sim, GPGPU-Sim 3.x adopts this mechanism.
Entries of the SIMT stack represents a different divergence level. At each divergence branch, a new entry is pushed to the top of the stack. The top-of-stack entry is popped when the warp reaches its reconvergence point. Each entry stores the target PC of the new branch, the immediate post dominator reconvergence PC and the active mask of threads that are diverging to this branch. In our model, the SIMT stack of each warp is updated after each instruction issue of this warp. The target PC, in case of no divergence, is normally updated to the next PC. However, in case of divergence, new entries are pushed to the stack with the new target PC, the active mask that corresponds to threads that diverge to this PC and their immediate reconvergence point PC. Hence, a control hazard is detected if the next PC at top entry of the SIMT stack does not equal to the PC of the instruction currently under check.
See Dynamic Warp Formation: Efficient MIMD Control Flow on SIMD Graphics Hardware for more details.
Note that it is known that NVIDIA and AMD actually modify the contents of their divergence stack using special instructions. These divergence stack instructions are not exposed in PTX but are visible in the actual hardware SASS instruction set (visible using decuda or NVIDIA's cuobjdump). When the current version of GPGPU-Sim 3.x is configured to execute SASS via PTXPlus (see PTX vs. PTXPlus) it ignores these low level instructions and instead a comparable control flow graph is created to identify immediate post-dominators. We plan to support execution of the low level branch instructions in a future version of GPGPU-Sim 3.x.
Scoreboard
The Scoreboard algorithm checks for WAW and RAW dependency hazards. As explained above, the registers written to by a warp are reserved at the issue stage. The scoreboard algorithm indexed by warp IDs. It stores the required register numbers in an entry that corresponds to the warp ID. The reserved registers are released at the write back stage.
As mentioned above, the decoded instruction of a warp is not scheduled for issue until the scoreboard indicates no WAW or RAW hazards exist. The scoreboard detects WAW and RAW hazards by tracking which registers will be written to by an instruction that has issued but not yet written its results back to the register file.
Register Access and the Operand Collector
Various NVIDIA patents describe a structure called an "operand collector". The operand collector is a set of buffers and arbitration logic used to provide the appearance of a multiported register file using multiple banks of single ported RAMs. The overall arrangement saves energy and area which is important to improving throughput. Note that AMD also uses banked register files, but the compiler is responsible for ensuring these are accessed so that no bank conflicts occur.Figure 6 provides an illustration of the detailed way in which GPGPU-Sim 3.x models the operand collector.
Figure 6: Operand collector microarchitecture
After an instruction is decoded, a hardware unit called a collector unit is allocated to buffer the source operands of the instruction.
The collector units are not used to eliminate name dependencies via register renaming, but rather as a way to space register operand accesses out in time so that no more than one access to a bank occurs in a single cycle. In the organization shown in the figure, each of the four collector units contains three operand entries. Each operand entry has four fields: a valid bit, a register identifier, a ready bit, and operand data. Each operand data field can hold a single 128 byte source operand composed of 32 four byte elements (one four byte value for each scalar thread in a warp). In addition, the collector unit contains an identifier indicating which warp the instruction belongs to. The arbitrator contains a read request queue for each bank to hold access requests until they are granted.
When an instruction is received from the decode stage and a collector unit is available it is allocated to the instruction and the operand, warp, register identifier and valid bits are set. In addition, source operand read requests are queued in the arbiter. To simplify the design, data being written back by the execution units is always prioritized over read requests. The arbitrator selects a group of up to four non-conflicting accesses to send to the register file. To reduce crossbar and collector unit area the selection is made so that each collector unit only receives one operand per cycle.
As each operand is read out of the register file and placed into the corresponding collector unit, a “ready bit” is set. Finally, when all the operands are ready the instruction is issued to a SIMD execution unit.
In our model, each back-end pipeline (SP, SFU, MEM) has a set of dedicated collector units, and they share a pool of general collector units. The number of units available to each pipeline and the capacity of the pool of the general units are configurable.
ALU Pipelines
GPGPU-Sim v3.x models two types of ALU functional units.
- SP units executes all types of ALU instructions except transcendentals.
- SFU units executes transcendental instructions (Sine, Cosine, Log... etc.).
Both types of units are pipelined and SIMDized. The SP unit can usually execute one warp instruction per cycle, while the SFU unit may only execute a new warp instruction every few cycles, depending on the instruction type. For example, the SFU unit can execute a sine instruction every 4 cycles or a reciprocal instruction every 2 cycles. Different types of instructions also has different execution latency.
Each SIMT core has one SP unit and one SFU unit. Each unit has an independent issue port from the operand collector. Both units share the same output pipeline register that connects to a common writeback stage. There is a result bus allocator at the output of the operand collector to ensure that the units will never be stalled due to the shared writeback. Each instruction will need to allocate a cycle slot in the result bus before being issued to either unit. Notice that the memory pipeline has its own writeback stage and is not managed by this result bus allocator.
The software design section contains more implementation detail of the model.
Memory Pipeline (LDST unit)
GPGPU-Sim Supports the various memory spaces in CUDA as visible in PTX. In our model, each SIMT core has 4 different on-chip level 1 memories: shared memory, data cache, constant cache, and texture cache. The following table shows which on chip memories service which type of memory access:
| Core Memory | PTX Accesses |
|---|---|
| Shared memory (R/W) | CUDA shared memory (OpenCL local memory) accesses only |
| Constant cache (Read Only) | Constant memory and parameter memory |
| Texture cache (Read Only) | Texture accesses only |
| Data cache (R/W - evict-on-write for global memory, writeback for local memory) | Global and Local memory accesses (Local memory = Private data in OpenCL) |
Although these are modelled as separate physical structures, they are all components of the memory pipeline (LDST unit) and therefore they all share the same writeback stage. The following describes how each of these spaces is serviced:
- Texture Memory - Accesses to texture memory are cached in the L1 texture cache (reserved for texture accesses only) and also in the L2 cache (if enabled). The L1 texture cache is a special design described in the 1998 paper [3]. Threads on GPU cannot write to the texture memory space, thus the L1 texture cache is read-only.
- Shared Memory - Each SIMT core contains a configurable amount of shared scratchpad memory that can be shared by threads within a thread block. This memory space is not backed by any L2, and is explicitly managed by the programmer.
- Constant Memory - Constants and parameter memory is cached in a read-only constant cache.
- Parameter Memory - See above
- Local Memory - Cached in the L1 data cache and backed by the L2. Treated in a fashion similar to global memory below except values are written back on eviction since there can be no sharing of local (private) data.
- Global Memory - Global and local accesses are both serviced by the L1 data cache. Accesses by scalar threads from the same warp are coalesced on a half-warp basis as described in the CUDA 3.1 programming guide. [4]. These accesses are processed at a rate of 2 per SIMT core cycle, such that a memory instruction that is perfectly coalesced into 2 accesses (one per half-warp) can be serviced in a single cycle. For those instructions that generate more than 2 accesses, these will access the memory system at a rate of 2 per cycle. So, if a memory instruction generates 32 accesses (one per lane in the warp), it will take at least 16 SIMT core cycles to move the instruction to the next pipeline stage.
The subsections below describe the first level memory structures.
L1 Data Cache
The L1 data cache is a private, per-SIMT core, non-blocking first level cache for local and global memory accesses. The L1 cache is not banked and is able to service two coalesced memory request per SIMT core cycle. An incoming memory request must not span two or more cache lines in the L1 data cache. Note also that the L1 data caches are not coherent.
The table below summarizes the write policies for the L1 data cache.
| L1 data cache write policy | ||
|---|---|---|
| Local Memory | Global Memory | |
| Write Hit | Write-back | Write-evict |
| Write Miss | Write no-allocate | Write no-allocate |
For local memory, the L1 data cache acts as a write-back cache with write no-allocate. For global memory, write hits cause eviction of the block. This mimics the default policy for global stores as outlined in the PTX ISA specification [5].
Memory accesses that hit in the L1 data cache are serviced in one SIMT core clock cycle. Missed accesses are inserted into a FIFO miss queue. One fill request per SIMT clock cycle is generated by the L1 data cache (given the interconnection injection buffers are able to accept the request).
The cache uses Miss Status Holding Registers (MSHR) to hold the status of misses in progress. These are modeled as a fully-associative array. Redundant accesses to the memory system that take place while one request is in flight are merged in the MSHRs. The MSHR table has a fixed number of MSHR entries. Each MSHR entry can service a fixed number of miss requests for a single cache line. The number of MSHR entries and maximum number of requests per entry are configurable.
A memory request that misses in the cache is added to the MSHR table and a fill request is generated if there is no pending request for that cache line. When a fill response to the fill request is received at the cache, the cache line is inserted into the cache and the corresponding MSHR entry is marked as filled. Responses for filled MSHR entries are generated at one request per cycle. Once all the requests waiting at the filled MSHR entry have been responded to and serviced, the MSHR entry is freed.
Texture Cache
The texture cache model is a prefetching texture cache. Texture memory accesses exhibit mostly spatial locality and this locality has been found to be mostly captured with about 16 KB of storage. In realistic graphics usage scenarios many texture cache accesses miss. The latency to access texture in DRAM is on the order of many 100's of cycles. Given the large memory access latency and small cache size the problem of when to allocate lines in the cache becomes paramount. The prefetching texture cache solves the problem by temporally decoupling the state of the cache tags from the state of the cache blocks. The tag array represents the state the cache will be in when misses have been serviced 100's of cycles later. The data array represents the state after misses have been serviced. The key to making this decoupling work is to use a reorder buffer to ensure returning texture miss data is placed into the data array in the same order the tag array saw the access. For more details see the original paper.
Constant (Read only) Cache
Accesses to constant and parameter memory run through the L1 constant cache. This cache is implemented with a tag array and is like the L1 data cache with the exception that it cannot be written to.
Thread Block / CTA / Work Group Scheduling
Thread blocks, Cooperative Thread Arrays (CTAs) in CUDA terminology or Work Groups in OpenCL terminology, are issued to SIMT Cores one at a time. Every SIMT Core clock cycle, the thread block issuing mechanism selects and cycles through the SIMT Core Clusters in a round robin fashion. For each selected SIMT Core Cluster, the SIMT Cores are selected and cycled through in a round robin fashion. For every selected SIMT Core, a single thread block will be issued to the core from the selected kernel if the there are enough resources free on that SIMT Core.
If multiple CUDA Streams or command queues are used in the application, then multiple kernels can be executed concurrently in GPGPU-Sim. Different kernels can be executed across different SIMT Cores; a single SIMT Core can only execute thread blocks from a single kernel at a time. If multiple kernels are concurrently being executed, then the selection of the kernel to issue to each SIMT Core is also round robin. Concurrent kernel execution on CUDA architectures is described in the NVIDIA CUDA Programming Guide
Interconnection Network
Interconnection network is responsible for the communications between SIMT core clusters and Memory Partition units. To simulate the interconnection network we have interfaced the "booksim" simulator to GPGPU-Sim. Booksim is a stand alone network simulator that can be found here. Booksim is capable of simulating virtual channel based Tori and Fly networks and is highly configurable. It can be best understood by referring to "Principles and Practices of Interconnection Networks" book by Dally and Towles.
We refer to our modified version of the booksim as Intersim. Intersim has it own clock domain. The original booksim only supports a single interconnection network. We have made some changes to be able to simulate two interconnection networks: one for traffic from the SIMT core clusters to Memory Partitions and one network for traffic from Memory partitions back to SIMT core clusters. This is one way of avoiding circular dependencies that might cause protocol deadlocks in the system. Another way would be having dedicated virtual channels for request and response traffic on a single physical network but this capability is not fully supported in the current version of our public release. Note: A newer version of Booksim (Booksim 2.0) is now available from Stanford, but GPGPU-Sim 3.x does not yet use it.
Please note that SIMT Core Clusters do not directly communicate which each other and hence there is no notion of coherence traffic in the interconnection network. There are only four packet types: (1)read-request and (2)write-requests sent from SIMT core clusters to Memory partitions and (3)read-replys and write-acknowledges sent from Memory Partitions to SIMT Core Clusters.
Concentration
SIMT core Clusters act as external concentrators in GPGPU-Sim. From the interconnection network's point of view a SIMT core cluster is a single node and the routers connected to this node only have one injection and one ejection port.
Interface with GPGPU-Sim
The interconnection network regardless of its internal configuration provides a simple interface to communicate with SIMT core Clusters and Memory partitions that are connected to it. For injecting packets SIMT core clusters or Memory controllers first check if the network has enough buffer space to accept their packet and then send their packet to the network. For ejection they check if there is packet waiting for ejection in the network and then pop it. These action happen in each units' clock domain. The serialization of packets is handled inside the network interface, e.g. SIMT core cluster injects a packet in SIMT core cluster clock domain but the router accepts only one flit per interconnect clock cycle. More implementation details can be found in the Software design section.
Memory Partition
The memory system in GPGPU-Sim is modelled by a set of memory partitions. As shown in Figure 7 each memory partition contain an L2 cache bank, a DRAM access scheduler and the off-chip DRAM channel. The functional execution of atomic operations also occurs in the memory partitions in the Atomic Operation Execution phase. Each memory partition is assigned a sub-set of physical memory addresses for which it is responsible. By default the global linear address space is interleaved among partitions in chunks of 256 bytes. This partitioning of the address space along with the detailed mapping of the address space to DRAM row, banks and columns in each partition is configurable and described in the Address Decoding section.
Figure 7: Memory Partition Components
The L2 cache (when enabled) services the incoming texture and (when configured to do so) non-texture memory requests. Note the Quadro FX 5800 (GT200) configuration enables the L2 for texture references only. On a cache miss, the L2 cache bank generates memory requests to the DRAM channel to be serviced by off-chip GDDR3 DRAM.
The subsections below describe in more detail how traffic flows through the memory partition along with the individual components mentioned above.
Memory Partition Connections and Traffic Flow
Figure 7 above shows the three sub-components inside a single Memory Partition and the various FIFO queues that facilitate the flow of memory requests and responses between them.
The memory request packets enter the Memory Partition from the interconnect via the ICNT->L2 queue. Non-texture accesses are directed through the Raster Operations Pipeline (ROP) queue to model a minimum pipeline latency of 460 L2 clock cycles, as observed by a GT200 micro-benchmarking study. The L2 cache bank pops one request per L2 clock cycle from the ICNT->L2 queue for servicing. Any memory requests for the off-chip DRAM generated by the L2 are pushed into the L2->dram queue. If the L2 cache is disabled, packets are popped from the ICNT->L2 and pushed directly into the L2->DRAM queue, still at the L2 clock frequency. Fill requests returning from off-chip DRAM are popped from DRAM->L2 queue and consumed by the L2 cache bank. Read replies from the L2 to the SIMT core are pushed through the L2->ICNT queue.
The DRAM latency queue is a fixed latency queue that models the minimum latency difference between a L2 access and a DRAM access (an access that has missed L2 cache). This latency is observed via micro-benchmarking and this queue simply modeling this observation (instead of the real hardware that causes this delay). Requests exiting the L2->DRAM queue reside in the DRAM latency queue for a fixed number of SIMT core clock cycles. Each DRAM clock cycle, the DRAM channel can pop memory request from the DRAM latency queue to be serviced by off-chip DRAM, and push one serviced memory request into the DRAM->L2 queue.
Note that ejection from the interconnect to Memory Partition (ROP or ICNT->L2 queues) occurs in L2 clock domain while injection into the interconnect from Memory Partition (L2->ICNT queue) occurs in the interconnect (ICNT) clock domain.
L2 Cache Model and Cache Hierarchy
The L2 cache model is very similar to the L1 data caches in SIMT cores (see that section for more details). When enabled to cache the global memory space data, the L2 acts as a read/write cache with write policies as summarized in the table below.
| L2 cache write policy | ||
|---|---|---|
| Local Memory | Global Memory | |
| Write Hit | Write-back for L1 write-backs | Write-evict |
| Write Miss | Write no-allocate | Write no-allocate |
Additionally, note that the L2 cache is a unified last level cache that is shared by all SIMT cores, whereas the L1 caches are private to each SIMT core.
The private L1 data caches are not coherent (the other L1 caches are for read only address spaces). The cache hierarchy in GPGPU-Sim is non-inclusive non-exclusive. Additionally, a non-decreasing cache line size going down the cache hierarchy (i.e. increasing cache level) is enforced. A memory request from the first level cache also cannot span across two cache lines in the L2 cache. These two restrictions ensure:
- A request from a lower level cache can be serviced by one cache line in the higher level cache. This ensures that requests from the L1 can be serviced atomically by the L2 cache.
- Atomic operations do not need to access multiple blocks at the L2
This restriction simplifies the cache design and prevents having to deal with live-lock related issues with servicing a request from L1 non-atomically.
Atomic Operation Execution Phase
The Atomic Operation Execution phase is a very idealized model of atomic instruction execution. Atomic instructions with non-conflicting memory accesses that were coalesced into one memory request are executed at the memory partition in one cycle. In the performance model, we currently model an atomic operation as a global load operation that skips the L1 data cache. This generates all the necessary register writeback traffic (and data hazard stalls) within the SIMT core. At L2 cache, the atomic operation marks the accessed cache line dirty (changing its status to modified) to generate the writeback traffic to DRAM. If L2 cache is not enabled (or used for texture access only), then no DRAM write traffic will be generated for atomic operations (a very idealized model).
DRAM Scheduling and Timing Model
GPGPU-Sim models both DRAM scheduling and timing. GPGPU-Sim implements two open page mode DRAM schedulers: a FIFO (First In First Out) scheduler and a FR-FCFS (First-Ready First-Come-First-Serve) scheduler, both described below. These can be selected using the configuration option -gpgpu_dram_scheduler.
FIFO Scheduler
The FIFO scheduler services requests in the order they are received. This will tend to cause a large number of precharges and activates and hence result in poorer performance especially for applications that generate a large amount of memory traffic relative to the amount of computation they perform.
FR-FCFS
The First-Row First-Come-First-Served scheduler gives higher priority to requests to a currently open row in any of the DRAM banks. The scheduler will schedule all requests in the queue to open rows first. If no such request exists it will open a new row for the oldest request. The code for this scheduler is located in dram_sched.h/.cc.
DRAM Timing Model
GPGPU-Sim accurately models graphics DRAM memory. Currently GPGPU-Sim 3.x models GDDR3 DRAM, though we are working on adding a detailed GDDR5. The following DRAM timing parameters can be set using the option -gpgpu_dram_timing_opt nbk:tCCD:tRRD:tRCD:tRAS:tRP:tRC:CL:WL:tCDLR:tWR. Currently, we do not model the timing of DRAM refresh operations. Please refer to GDDR3 specifications for more details about each parameter.
- nbk: number of banks
- tCCD: Column to Column Delay (RD/WR to RD/WR different banks)
- tRRD: Row to Row Delay (Active to Active different banks)
- tRCD: Row to Column Delay (Active to RD/WR/RTR/WTR/LTR)
- tRAS: Active to PRECHARGE command period
- tRP: PRECHARGE command period
- tRC: Active to Active command period (same bank)
- CL: CAS Latency
- WL: WRITE latency
- tCDLR: Last data-in to Read Delay (switching from write to read)
- tWR: WRITE recovery time
In our model, commands for each memory bank are scheduled in a round-robin fashion. The banks are arranged in a circular array with a pointer to the bank with the highest priority. The scheduler goes through the banks in order and issues commands. Whenever an activate or precharge command is issued for a bank, the priority pointer is set to the next bank guaranteeing that other pending commands for other banks will be eventually scheduled.
Instruction Set Architecture (ISA)
PTX and SASS
GPGPU-Sim simulates the Parallel Thread eXecution (PTX) instruction set used by NVIDIA. PTX is a pseudo-assembly instruction set; i.e. it does not execute directly on the hardware. ptxas is the assembler released by NVIDIA to assemble PTX into the native instruction set run by the hardware (SASS). Each hardware generation supports a different version of SASS. For this reason, PTX is compiled into multiple versions of SASS that correspond to different hardware generations at compile time. Despite that, the PTX code is still embedded into the binary to enable support for future hardware. At runtime, the runtime system selects the appropriate version of SASS to run based on the available hardware. If there is none, the runtime system invokes a just-in-time (JIT) compiler on the embedded PTX to compile it into the SASS corresponding to the available hardware.
PTXPlus
GPGPU-Sim is capable of running PTX. However, since PTX is not the actual code that runs on the hardware, there is a limit to how accurate it can be. This is mainly due to compiler passes such as strength reduction, instruction scheduling, register allocation to mention a few.
To enable running SASS code in GPGPU-Sim, new features had to be added:
- New addressing modes
- More elaborate condition codes and predicates
- Additional instructions
- Additional datatypes
In order to avoid developing and maintaining two parsers and two functional execution engines (one for PTX and the other for SASS), we chose to extend PTX with the required features in order to provide a one-to-one mapping to SASS. PTX along with the extentions is called PTXPlus. To run SASS, we perform a syntax conversion from SASS to PTXPlus.
PTXPlus has a very similar syntax when compared to PTX with the addition of new addressing modes, more elaborate condition codes and predicates, additional instructions and more data types. It is important to keep in mind that PTXPlus is a superset of PTX, which means that valid PTX is also valid PTXPlus. More details about the exact differences between PTX and PTXPlus can be found in #PTX vs. PTXPlus.
From SASS to PTXPlus
When the configuration file instructs GPGPU-Sim to run SASS, a conversion tool, cuobjdump_to_ptxplus, is used to convert the SASS embedded within the binary to PTXPlus. For the full details of the conversion process see #PTXPlus Conversion . The PTXPlus is then used in the simulation. When SASS is converted to PTXPlus, only the syntax is changed, the instructions and their order is preserved exactly as in the SASS. Thus, the effect of compiler optimizations applied to the native code is fully captured. Currently, GPGPU-Sim only supports the conversion of GT200 SASS to PTXPlus.
Using GPGPU-Sim
Refer to the README file in the top level GPGPU-Sim directory for instructions on building and running GPGPU-Sim 3.x. This section provides other important guidance on using GPGPU-Sim 3.x, covering topics such as different simulation modes, how to modify the timing model configuration, a description of the default simulation statistics, and description of approaches for analyzing bugs at the functional level via tracing simulation state and a GDB-like interface. GPGPU-Sim 3.x also provides extensive support for debugging performance simulation bugs including both a high level microarchitecture visualizer and cycle by cycle pipeline state visualization. Next, we describe strategies for debugging GPGPU-Sim when it crashes or deadlocks in performance simulation mode. Finally, it conclude with answers to frequently asked questions.
Simulation Modes
By default most users will want to use GPGPU-Sim 3.x to estimate the number of GPU clock cycles it takes to run an application. This is known as performance simulation mode. When trying to run a new application on GPGPU-Sim it is always possible that application may not run correctly--i.e., it is possible it may generate the wrong output. To help debugging such applications, GPGPU-Sim 3.x also supports a fast functional simulation only mode. This mode may also be helpful for compiler research and/or when making changes to the functional simulation engine. Orthogonal to the distinction between performance and functional simulation, GPGPU-Sim 3.x also support execution of the native hardware ISA on NVIDIA GPUs (currently GT200 and earlier only), via an extended PTX syntax we call PTXPlus. The following subsections describe these features in turn.
| CUDA Version | PTX | PTXPlus | cuobjdump+PTX | cuobjdump+PTXPlus |
|---|---|---|---|---|
| 2.3 | ? | No | No | No |
| 3.1 | Yes | No | No | No |
| 4.0 | No | No | Yes | Yes |
Performance Simulation
Performance simulation is the default mode of simulation and collects performance statistics in exchange for slower simulation speed. GPGPU-Sim simulates the microarchitecture described in the Microarchitecture Model section.
To select the performance simulation mode, add the following line to the gpgpusim.config file:
-gpgpu_ptx_sim_mode 0
For information regarding understanding the simulation output refer to the section on understanding simulation output.
Pure Functional Simulation
Pure functional simulations run faster than performance simulations but only perform the execution of the CUDA/OpenCL program and does not collect performance statistics.
To select the pure functional simulation mode, add the following line to the gpgpusim.config file:
-gpgpu_ptx_sim_mode 1
Alternatively, you can set the environmental variable PTX_SIM_MODE_FUNC to 1. Then execute the program normally as you would do in performance simulation mode.
Simulating only the functionality of a GPU device, GPGPU-Sim pure functional simulation mode execute a CUDA/OpenCL program as if it runs on a real GPU device, so no performance measures are collected in this mode, only the regular output of a GPU program is shown. As you expect the pure simulation mode is significantly faster than the performance simulation mode (about 5~10 times faster).
This mode is very useful if you want to quickly check that your code is working correctly on GPGPU-Sim, or if you want to experience using CUDA/OpenCL without the need to have a real GPU computation device. Pure functional simulation supports the same versions of CUDA as the performance simulation (CUDA v3.1) and (CUDA v2.3) for PTX Plus. The pure functional simulation mode execute programs as a group of warps, where warps of each Cooperative Thread Array (CTA) get executed till they all finish or all wait at a barrier, in the latter case once all the warps meet at the barrier they are cleared to go ahead and cross the barrier.
Software design details for Pure Functional Simulation can be found below.
Interactive Debugger Mode
Interactive debugger mode offers a GDB-like interface for debugging functional behavior in GPGPU-Sim. However, currently it only works with performance simulation.
To enable interactive debugger mode, set environment variable GPGPUSIM_DEBUG to 1. Here are supported commands:
| Command | Description |
|---|---|
| dp |
Dump pipeline: Display the state (pipeline content) of the SIMT core |
| q | Quit |
| b |
Set breakpoint at |
| d |
Delete breakpoint. |
| s | Single step execution to next core cycle for all cores. |
| c | Continue execution without single stepping. |
| w | Set watchpoint at . is specified as a hexadecimal number. |
| l | List PTX around current breakpoint. |
| h | Display help message. |
It is implemented in files debug.h and debug.cc.
Cuobjdump Support
As of GPGPU-Sim version 3.1.0, support for using cuobjdump was added. cuobjdump is a software provided by NVidia to extract information like SASS and PTX from binaries. GPGPU-Sim supports using cuobjdump to extract the information it needs to run either SASS or PTX instead of obtaining them through the cubin files. Using cuobjdump is supported only with CUDA 4.0. cuobjdump is enabled by default if the simulator is compiled with CUDA 4.0. To enable/disable cuobjdump, add one of the following option to your configuration file:
# disable cuobjdump
-gpgpu_ptx_use_cuobjdump 0
# enable cuobjdump
-gpgpu_ptx_use_cuobjdump 1
PTX vs. PTXPlus
By default, GPGPU-Sim 3.x simulates PTX instructions. However, when executing on an actual GPU, PTX is recompiled to a native GPU ISA (SASS). This recompilation is not fully accounted for in the simulation of normal PTX instructions. To address this issue we created PTXPlus. PTXPlus is an extended form of PTX, introduced by GPGPU-Sim 3.x, that allows for a near 1 to 1 mapping of most GT200 SASS instructions to PTXPlus instructions. It includes new instructions and addressing modes that don't exist in regular PTX. When the conversion to PTXPlus option is activated, the SASS instructions that make up the program are translated into PTXPlus instructions that can be simulated by GPGPU-Sim. Use of the PTXPlus conversion option can lead to significantly more accurate results. However, conversion to PTXPlus does not yet fully support all programs that could be simulated using normal PTX. Currently, only CUDA Toolkit later than 4.0 is supported for conversion to PTXPlus.
SASS is the term NVIDIA uses for the native instruction set used by the GPUs according to their released documentation of the instruction sets. This documentation can be found in the file "cuobjdump.pdf" released with the CUDA Toolkit.
To convert the SASS from an executable, GPGPU-Sim cuobjdump -- a software release along with the CUDA toolkit by NVIDIA that extracts PTX, SASS and other information from CUDA executables. GPGPU-Sim 3.x includes a stand alone program called cuobjdump_to_ptxplus that is invoked to convert the output of cuobjdump into PTXPlus which GPGPU-Sim can simulate. cuobjdump_to_ptxplus is a program written in C++ and its source is provided with the GPGPU-Sim distribution. See the PTXPlus Conversion section for a detailed description on the PTXPlus conversion process. Currently, cuobjdump_to_ptxplus supports the conversion of SASS for sm versions < sm_20.
To enable PTXPlus simulation, add the following line to the gpgpusim.config file:
-gpgpu_ptx_convert_to_ptxplus 1
Additionally the converted PTXPlus can be saved to files named "_#.ptxplus" by adding the following line to the gpgpusim.config file:
-gpgpu_ptx_save_converted_ptxplus 1
To turn off either feature, either remove the line or change the value from 1 to 0. More details about using PTXPlus can be found in PTXPlus support. If the option above is enabled, GPGPU-Sim will attempt to convert the SASS code to PTXPlus and then run the resulting PTXPlus. However, as mentioned before, not all programs are supported in this mode.
The subsections below describe the additions we made to PTX to obtain PTXPlus.
Addressing Modes
To support GT200 SASS, PTXPlus increases the number of addressing modes available to most instructions. Non-load/non-store are now able to directly access memory. The following instruction adds the value in register r0 to the value store in shared memory at address 0x0010 and stores the values in register r1:
add.u32 $r1, s[0x0010], $r0;
Operands such as s[$r2] or s[$ofs1+0x0010] can also be used. PTXPlus also introduces the following addressing modes that are not present in original PTX:
- g = global memory
- s = shared memory
- ce#c# = constant memory (first number is the kernel number, second number is the constant segment)
g[$ofs1+$r0] //global memory address determined by the sum of register ofs1 and register r0.
s[$ofs1+=0x0010] //shared memory address determined by value in register $ofs1. Register $ofs1 is then incremented by 0x0010.
ce1c2[$ofs1+=$r1] //first kernel's second constant segment's memory address determined by value in register $ofs1. Register $ofs1 is then incremented by the value in register $r1.
The implementation details of these addressing modes is described in PTXPlus Implementation.
New Data Types
Instructions have also been upgraded to more accurately represent how 64 bit and 128 bit values are stored across multiple 32 bit registers. The least significant 32 bits are stored in the far left register while the most significant 32 bits are stored in the far right registers. The following is a list of the new data types and an example of an add instruction adding two 64 bit floating point numbers:
- .ff64 = PTXPlus version of 64 bit floating point number
- .bb64 = PTXPlus version of 64 bit untyped
- .bb128 = PTXPlus version of 128 bit untyped
add.rn.ff64 {$r0,$r1}, {$r2,$r3}, {$r4,$r5};
PTXPlus Instructions
| PTXPlus Instructions | |
|---|---|
| nop | Do nothing |
| andn | a andn b = a and ~b |
| norn | a norn b = a nor ~b |
| orn | a orn b = a or ~b |
| nandn | a nandn b = a nand ~b |
| callp | A new call instruction added in PTXPlus. It jumps to the indicated label |
| retp | A new return instruction added in PTXPlus. It jumps back to the instruction after the previous callp instruction |
| breakaddr | Pushes the address indicated by the operand on the thread's break address stack |
| break | Jumps to the address at the top of the thread's break address stack and pops off the entry |
PTXPlus Condition Codes and Instruction Predication
Instead of the normal true-false predicate system in PTX, SASS instructions use 4-bit condition codes to specify more complex predicate behaviour. As such, PTXPlus uses the same 4-bit predicate system. GPGPU-Sim uses the predicate translation table from decuda for simulating PTXPlus instructions.
The highest bit represents the overflow flag followed by the carry flag and sign flag. The last and lowest bit is the zero flag. Separate condition codes can be stored in separate predicate registers and instructions can indicate which predicate register to use or modify. The following instruction adds the value in register $r0 to the value in register $r1 and stores the result in register $r2. At the same the, the appropriate flags are set in predicate register $p0.
add.u32 $p0|$r2, $r0, $r1;
Different test conditions can be used on predicated instructions. For example the next instruction is only performed if the carry flag bit in predicate register $p0 is set:
@$p0.cf add.u32 $r2, $r0, $r1;
Parameter and Thread ID (tid) Initialization
PTXPlus does not use an explicit parameter state space to store the kernel parameters. Instead, the input parameters are copied in order into shared memory starting at address 0x0010. The copying of parameters is performed during GPGPU-Sim's thread initialization process. The thread initialization process occurs when a thread block is issued to a SIMT core, as described in Thread Block / CTA / Work Group Scheduling. The Kernel Launch: Parameter Hookup section describes the implementation for this procedure. Also during this process, the values of special registers %tid.x, %tid.y and %tid.z are copied into register $r0.
Register $r0:
|%tid.z| %tid.y | NA | %tid.x |
31 26 25 16 15 10 9 0
Debugging via Prints and Traces
There are two built-in facilities for debugging gpgpu-sim. The first mechanism is through environment variables. This is useful for debugging elements of GPGPU-Sim that take place before the configuration file (gpgpusim.config) is parsed, however this can be a clumsy way to implement tracing information in the performance simulator. As of version 3.2.1 GPGPU-Sim includes a tracing system implemented in 'src/trace.h', which allows the user to turn traces on and off via the config file and enable traces by their string name. Both these systems are described below. Please note that many of the environment variable prints could be implemented via the tracing system, but exist as env variables becuase they are in legacy code. Also, GPGPU-Sim prints a large amount of information that is not controlled through the tracing system which is also a result of legacy code.
Environment Variables for Debugging
Some behavior of GPGPU-Sim 3.x relevant to debugging can be configured via environment variables.
When debugging it may be helpful to generate additional information about what is going on in the simulator and print this out to standard output. This is done by using the following environment variable:
export PTX_SIM_DEBUG=<#> enable debugging and set the verbose level
The currently supported levels are enumerated below:
| Level | Description |
|---|---|
| 1 | Verbose logs for CTA allocation |
| 2 | Print verbose output from dominator analysis |
| 3 | Verbose logs for GPU malloc/memcpy/memset |
| 5 | Display the instruction executed |
| 6 | Display the modified register(s) by each executed instruction |
| 10 | Display the entire register file of the thread executing the instruction |
| 50 | Print verbose output from control flow analysis |
| 100 | Print the loaded PTX files |
If a benchmark does not run correctly on GPGPU-Sim you may need to debug the functional simulation engine. The way we do this is to print out the functional state of a single thread that generates an incorrect output. To enable printing out functional simulation state for a single thread, use the following environment variable (and set the appropriate level for PTX_SIM_DEBUG):
export PTX_SIM_DEBUG_THREAD_UID=<#> ID of thread to debug
Other environment configuration options:
export PTX_SIM_USE_PTX_FILE= override PTX embedded in the binary and revert to old strategy of looking for *.ptx files (good for hand-tweaking PTX)
export PTX_SIM_KERNELFILE= use this to specify the name of the PTX file
GPGPU-Sim debug tracing
The tracing system is controlled by variables in the gpgpusim.config file:
| Variable | Values | Description |
|---|---|---|
| trace_enabled | 0 or 1 | Globally enable or disable all tracing. If enabled, then trace_components are printed. |
| trace_components | A comma separated list of tracing elements to enable, a complete list is available in src/trace_streams.tup | |
| trace_sampling_core | <0 through num_cores-1> | For elements associated with a given shader core (such as the warp scheduler or scoreboard), only print traces from this core |
The Code files that implement the system are:
| Variable | Description |
|---|---|
| src/trace_streams.tup | Lists the names of each print stream |
| src/trace.cc | Some setup implementation and initialization |
| src/trace.h | Defines all the high level interfaces for the tracing system |
| src/gpgpu-sim/shader_trace.h | Defines some convenient prints for debugging a specific shader core |
Configuration Options
Configuration options are passed into GPGPU-Sim with gpgpusim.config and an interconnection configuration file (specified with option -inter_config_file inside gpgpusim.config). GPGPU-Sim 3.0.2 comes with calibrated configuration files in the configs directory for the NVIDIA GT200 (configs/QuadroFX5800/) and Fermi (configs/Fermi/).
Here is a list of the configuration options:
Simulation Run Configuration |
||
|---|---|---|
| Option | Description | |
| -gpgpu_max_cycle <# cycles> | Terminate GPU simulation early after a maximum number of cycle is reached (0 = no limit) | |
| -gpgpu_max_insn <# insns> | Terminate GPU simulation early after a maximum number of instructions (0 = no limit) | |
| -gpgpu_ptx_sim_mode <0=performance (default), 1=functional> | Select between performance or functional simulation (note that functional simulation may incorrectly simulate some PTX code that requires each element of a warp to execute in lock-step) | |
| -gpgpu_deadlock_detect <0=off, 1=on (default)> | Stop the simulation at deadlock | |
| -gpgpu_max_cta | Terminates GPU simulation early (0 = no limit) | |
| -gpgpu_max_concurrent_kernel | Maximum kernels that can run concurrently on GPU | |
Statistics Collection Options |
||
| Option | Description | |
| -gpgpu_ptx_instruction_classification <0=off, 1=on (default)> | Enable instruction classification | |
| -gpgpu_runtime_stat |
Display runtime statistics | |
| -gpgpu_memlatency_stat | Collect memory latency statistics (0x2 enables MC, 0x4 enables queue logs) | |
| -visualizer_enabled <0=off, 1=on (default)> | Turn on visualizer output (use AerialVision visualizer tool to plot data saved in log) | |
| -visualizer_outputfile |
Specifies the output log file for visualizer. Set to NULL for automatically generated filename (Done by default). | |
| -visualizer_zlevel |
Compression level of the visualizer output log (0=no compression, 9=max compression) | |
| -save_embedded_ptx | saves ptx files embedded in binary as |
|
| -enable_ptx_file_line_stats <0=off, 1=on (default)> | Turn on PTX source line statistic profiling | |
| -ptx_line_stats_filename | Output file for PTX source line statistics. | |
| -gpgpu_warpdistro_shader | Specify which shader core to collect the warp size distribution from | |
| -gpgpu_cflog_interval | Interval between each snapshot in control flow logger | |
| -keep | keep intermediate files created by GPGPU-Sim when interfacing with external programs | |
High-Level Architecture Configuration (See ISPASS paper for more details on what is being modeled) |
||
| Option | Description | |
| -gpgpu_n_mem <# memory controller> | Number of memory controllers (DRAM channels) in this configuration. Read #Topology Configuration before modifying this option. | |
| -gpgpu_clock_domains |
Clock domain frequencies in MhZ (See #Clock Domain Configuration) | |
| -gpgpu_n_clusters | Number of processing clusters | |
| -gpgpu_n_cores_per_cluster | Number of SIMD cores per cluster | |
Additional Architecture Configuration |
||
| Option | Description | |
| -gpgpu_n_cluster_ejection_buffer_size | Number of packets in ejection buffer | |
| -gpgpu_n_ldst_response_buffer_size | Number of response packets in LD/ST unit ejection buffer | |
| -gpgpu_coalesce_arch | Coalescing arch (default = 13, anything else is off for now) | |
Scheduler |
||
| Option | Description | |
| -gpgpu_num_sched_per_core | Number of warp schedulers per core | |
| -gpgpu_max_insn_issue_per_warp | Max number of instructions that can be issued per warp in one cycle by scheduler | |
Shader Core Pipeline Configuration |
||
| Option | Description | |
| -gpgpu_shader_core_pipeline <# thread/shader core>: |
Shader core pipeline configuration | |
| -gpgpu_shader_registers <# registers/shader core, default=8192> | Number of registers per shader core. Limits number of concurrent CTAs. | |
| -gpgpu_shader_cta <# CTA/shader core, default=8> | Maximum number of concurrent CTAs in shader | |
| -gpgpu_simd_model <1=immediate post-dominator, others are not supported for now> | SIMD Branch divergence handling policy | |
| -ptx_opcode_latency_int/fp/dp |
Opcode latencies | |
| -ptx_opcode_initiation_int/fp/dp |
Opcode initiation period. For this number of cycles the inputs of the ALU is held constant. The ALU cannot consume new values during this time. i.e. if this value is 4, then that means this unit can consume new values once every 4 cycles. | |
Memory Sub-System Configuration |
||
| Option | Description | |
| -gpgpu_perfect_mem <0=off (default), 1=on> | Enable perfect memory mode (zero memory latency with no cache misses) | |
| -gpgpu_tex_cache:l1 |
Texture cache (Read-Only) configuration. Evict policy: L = LRU, F = FIFO, R = Random. | |
| -gpgpu_const_cache:l1 |
Constant cache (Read-Only) configuration. Evict policy: L = LRU, F = FIFO, R = Random | |
| -gpgpu_cache:il1 |
Shader L1 instruction cache (for global and local memory) configuration. Evict policy: L = LRU, F = FIFO, R = Random | |
| -gpgpu_cache:dl1 |
L1 data cache (for global and local memory) configuration. Evict policy: L = LRU, F = FIFO, R = Random | |
| -gpgpu_cache:dl2 |
Unified banked L2 data cache configuration. This specifies the configuration for the L2 cache bank in one of the memory partitions. The total L2 cache capacity = |
|
| -gpgpu_shmem_size |
Size of shared memory per SIMT core (aka shader core) | |
| -gpgpu_shmem_warp_parts | Number of portions a warp is divided into for shared memory bank conflict check | |
| -gpgpu_flush_cache <0=off (default), 1=on> | Flush cache at the end of each kernel call | |
| -gpgpu_local_mem_map | Mapping from local memory space address to simulated GPU physical address space (default = enabled) | |
| -gpgpu_num_reg_banks | Number of register banks (default = 8) | |
| -gpgpu_reg_bank_use_warp_id | Use warp ID in mapping registers to banks (default = off) | |
| -gpgpu_cache:dl2_texture_only | L2 cache used for texture only (0=no, 1=yes, default=1) | |
Operand Collector Configuration |
||
| Option | Description | |
| -gpgpu_operand_collector_num_units_sp | number of collector units (default = 4) | |
| -gpgpu_operand_collector_num_units_sfu | number of collector units (default = 4) | |
| -gpgpu_operand_collector_num_units_mem | number of collector units (default = 2) | |
| -gpgpu_operand_collector_num_units_gen | number of collector units (default = 0) | |
| -gpgpu_operand_collector_num_in_ports_sp | number of collector unit in ports (default = 1) | |
| -gpgpu_operand_collector_num_in_ports_sfu | number of collector unit in ports (default = 1) | |
| -gpgpu_operand_collector_num_in_ports_mem | number of collector unit in ports (default = 1) | |
| -gpgpu_operand_collector_num_in_ports_gen | number of collector unit in ports (default = 0) | |
| -gpgpu_operand_collector_num_out_ports_sp | number of collector unit in ports (default = 1) | |
| -gpgpu_operand_collector_num_out_ports_sfu | number of collector unit in ports (default = 1) | |
| -gpgpu_operand_collector_num_out_ports_mem | number of collector unit in ports (default = 1) | |
| -gpgpu_operand_collector_num_out_ports_gen | number of collector unit in ports (default = 0) | |
DRAM/Memory Controller Configuration |
||
| Option | Description | |
| -gpgpu_dram_scheduler <0 = fifo, 1 = fr-fcfs> | DRAM scheduler type | |
| -gpgpu_frfcfs_dram_sched_queue_size <# entries> | DRAM FRFCFS scheduler queue size (0 = unlimited (default); # entries per chip). (Note: FIFO scheduler queue size is fixed to 2). |
|
| -gpgpu_dram_return_queue_size <# entries> | DRAM requests return queue size (0 = unlimited (default); # entries per chip). | |
| -gpgpu_dram_buswidth <# bytes/DRAM bus cycle, default=4 bytes, i.e. 8 bytes/command clock cycle> | Bus bandwidth of a single DRAM chip at command bus frequency (default = 4 bytes (8 bytes per command clock cycle)). The number of DRAM chip per memory controller is set by option -gpgpu_n_mem_per_ctrlr. Each memory partition has (gpgpu_dram_buswidth X gpgpu_n_mem_per_ctrlr) bits of DRAM data bus pins. For example, Quadro FX5800 has a 512-bit DRAM data bus, which is divided among 8 memory partitions. Each memory partition a 512/8=64 bits of DRAM data bus. This 64-bit bus is split into 2 DRAM chips for each memory partition. Each chip will have 32-bit=4-byte of DRAM bus width. We therefore set -gpgpu_dram_buswidth to 4. |
|
| -gpgpu_dram_burst_length <# burst per DRAM request> | Burst length of each DRAM request (default = 4 data clock cycle, which runs at 2X command clock frequency in GDDR3) | |
| -gpgpu_dram_timing_opt |
DRAM timing parameters:
|
|
| -gpgpu_mem_address_mask | Obsolete: Select different address decoding scheme to spread memory access across different memory banks. (0 = old addressing mask, 1 = new addressing mask, 2 = new add. mask + flipped bank sel and chip sel bits) | |
| -gpgpu_mem_addr_mapping dramid@ |
Mapping memory address to DRAM model:
See configuration file for Quadro FX 5800 for example. |
|
| -gpgpu_n_mem_per_ctrlr <# DRAM chips/memory controller> | Number of DRAM chip per memory controller (aka DRAM channel) | |
| -gpgpu_dram_partition_queues | i2$:$2d:d2$:$2i | |
| -rop_latency <# minimum cycle before L2 cache access> | Specify the minimum latency (in core clock cycles) between when a memory request arrived at the memory partition and when it accesses the L2 cache / moves into the queue to access DRAM. It models the minimum L2 hit latency. | |
| -dram_latency <# minimum cycle after L2 cache access and before DRAM access> | Specify the minimum latency (in core clock cycles) between when a memory request has accessed the L2 cache and when it is pushed into the DRAM scheduler. This option works together with -rop_latency to model the minimum DRAM access latency (= rop_latency + dram_latency). | |
Interconnection Configuration |
||
| Option | Description | |
| -inter_config_file |
The file containing Interconnection Network simulator's options. For more details about interconnection configurations see Manual provided with the original code at [6]. NOTE that options under "4.6 Traffic" and "4.7 Simulation parameters" should not be used in our simulator. Also see #Interconnection Configuration. | |
| -network_mode | Interconnection network mode to be used (default = 1). | |
PTX Configurations |
||
| Option | Description | |
| -gpgpu_ptx_use_cuobjdump | Use cuobjdump to extract ptx/sass (0=no, 1=yes) Only allowed with CUDA 4.0 | |
| -gpgpu_ptx_convert_to_ptxplus | Convert embedded ptx to ptxplus (0=no, 1=yes) | |
| -gpgpu_ptx_save_converted_ptxplus | Save converted ptxplus to a file (0=no, 1=yes) | |
| -gpgpu_ptx_force_max_capability | Force maximum compute capability (default 0) | |
| -gpgpu_ptx_inst_debug_to_file | Dump executed instructions' debug information to a file (0=no, 1=yes) | |
| -gpgpu_ptx_inst_debug_file | Output file to dump debug information for executed instructions | |
| -gpgpu_ptx_inst_debug_thread_uid | Thread UID for executed instructions' debug output | |
Interconnection Configuration
GPGPU-Sim 3.x uses the booksim router simulator to model the interconnection network. For the most part you will want to consult the booksim documentation for how to configure the interconnect. However, below we list special considerations that need to be taken into account to ensure your modifications work with GPGPU-Sim.
Topology Configuration
Note that the total number of network nodes as specified in the interconnection network config file should match the total nodes in GPGPU-Sim. GPGPU-Sim's total number of nodes would be the sum of SIMT Core Cluster count and the number of Memory controllers. E.g. in the QuadroFX5800 configuration there are 10 SIMT Core Clusters and 8 Memory Controllers. That is a total of 18 nodes. Therefore in the interconnection config file the network also has 18 nodes as demonstrated below:
topology = fly;
k = 18;
n = 1;
routing_function = dest_tag;
The configuration snippet above sets up a single stage butterfly network with destination tag routing and 18 nodes. Generally, in both butterfly and mesh networks the total number of network nodes would be k*n.
Note that if you choose to use a mesh network you will want to consider configuring the memory controller placement. In the current release there are a few predefined mappings that can be enabled by setting "use_map=1;" In particular the mesh network used in our ISPASS 2009 paper paper can be configured using this setting and the following topology:
- a 6x6 mesh network (topology=mesh, k=6, n=2) : 28 SIMT cores + 8 dram channels assuming the SIMT core Cluster size is one
You can create your own mappings by modifying create_node_map() in interconnect_interface.cpp (and set use_map=1)
Booksim options added by GPGPU-Sim
These options are specific to GPGPU-Sim and not part of the original booksim:
- perfect_icnt: if set the interconnect is not simulated all packets that are injected to the network will appear at their destination after one cycle. This is true even when multiple sources send packets to one destination.
- fixed_lat_per_hop: similar to perfect_icnt above except that the packet appears in destination after "Manhattan distance hop count times fixed_lat_per_hop" cycles.
- use_map: changes the way memory and shader cores are placed. See Topology Configuration.
- flit_size: specifies the flit_size in bytes. This is used to identify the number of flits per packet based on the size of packet as passed to icnt_push() functions.
- network_count: Number of independent interconnection networks. Should be set to 2 unless you know what you are doing.
- output_extra_latency: Adds extra cycles to each router. Used to create Figure 10 of ISPASS paper.
- enable_link_stats: prints extra statistics for each link
- input_buf_size: Input buffer size of each node in flits. If left zero the simulator will set it automatically. See "Injecting a packet from the outside world to network"
- ejection_buffer_size: ejection buffer size. If left zero the simulator will set it automatically. See "Ejecting a packet from network to the outside world"
- boundary_buffer_size: boundary buffer size. If left zero the simulator will set it automatically. See "Ejecting a packet from network to the outside world"
These four options were set using #define in original booksim but we have made them configurable via intersim's config file:
- MATLAP_OUTPUT (generates Matlab friendly outputs), DISPLAY_LAT_DIST (shows a distribution of packet latencies), DISPLAY_HOP_DIST (shows a distribution of hop counts), DISPLAY_PAIR_LATENCY (shows average latency for each source destination pair)
Booksim Options ignored by GPGPU-Sim
Please note the following options that are part of original booksim are either ignored or should not be changed from default.
- Traffic Options (section 4.6 of booksim manual): injection_rate, injection_process, burst_alpha, burst_beta, "const_flit_per_packet", traffic
- Simulation parameters (section 4.7 of booksim manual): sim_type, sample_period, warmup_periods, max_samples, latency_thres, sim_count, reorder
Clock Domain Configuration
GPGPU-Sim supports four clock domains that can be controlled by the -gpgpu_clock_domains option:
- DRAM clock domain = frequency of the real DRAM clock (command clock) and not the data clock (i.e. 2x of the command clock frequency)
- SIMT Core Cluster clock domain = frequency of the pipeline stages in a core clock (i.e. the rate at which simt_core_cluster::core_cycle() is called)
- Icnt clock domain = frequency of the interconnection network (usually this can be regarded as the core clock in NVIDIA GPU specs)
- L2 clock domain = frequency of the L2 cache (We usually set this equal to ICNT clock frequency)
Note that in GPGPU-Sim the width of the pipeline is equal to warp size. To compensate for this we adjust the SIMT Core Cluster clock domain. For example we model the superpipelined stages in NVIDIA's Quadro FX 5800 (GT200) SM running at the fast clock rate (1GHz+) with a single-slower pipeline stage running at 1/4 the frequency. So a 1.3GHz shader clock rate of FX 5800 corresponds to a 325MHz SIMT core clock in GPGPU-Sim.
The DRAM clock domain is specified in the frequency of the command clock. To simplify the peak memory bandwidth calculation, most GPU specs report the data clock, which runs at 2X the command clock frequency. For example, Quadro FX5800 has a memory data clock of 1600MHz, while the command clock is only running at 800MHz. Therefore, our configuration sets the DRAM clock domain at 800.0MHz.
clock Special Register
In ptx, there is a special register %clock that reads the a clock cycle counter. On the hardware, this register is called SR1. It is a clock cycle counter that silently wraps around. In Quadro, this counter is incremented twice per scheduler clock. In Fermi, it is incremented only once per scheduler clock. GPGPU-Sim will return a value for a counter that is incremented once per scheduler clock (which is the same as the SIMT core clock).
In PTXPlus, the nvidia compiler generates the instructions accessing the %clock register as follows
//SASS accessing clock register
S2R R1, SR1
SHL R1, R1, 0x1
//PTXPlus accessing clock register
mov %r1, %clock
shl %r1, %r1, 0x1
This basically multiplies the value in the clock register by two. In PTX, however, the clock register is accessed directly. Those conditions must be taken into consideration when calculating results based on the clock register.
//PTX accessing clock register
mov r1, %clock
Understanding Simulation Output
At the end of each CUDA grid launch, GPGPU-Sim prints out the performance statistics to the console (stdout). These performance statistics provide insights into how the CUDA application performs with the simulated GPU architecture.
Here is a brief list of the important performance statistics:
General Simulation Statistics
| Statistic | Description |
|---|---|
| gpu_sim_cycle | Number of cycles (in Core clock) required to execute this kernel. |
| gpu_sim_insn | Number of instructions executed in this kernel. |
| gpu_ipc | gpu_sim_insn / gpu_sim_cycle |
| gpu_tot_sim_cycle | Total number of cycles (in Core clock) simulated for all the kernels launched so far. |
| gpu_tot_sim_insn | Total number of instructions executed for all the kernels launched so far. |
| gpu_tot_ipc | gpu_tot_sim_insn / gpu_tot_sim_cycle |
| gpu_total_sim_rate | gpu_tot_sim_insn / wall_time |
Simple Bottleneck Analysis
These performance counters track stall events at different high-level parts of the GPU. In combination, they give a broad sense of how where the bottleneck is in the GPU for an application. Figure 8 illustrates a simplified flow of memory requests through the memory sub-system in GPGPU-Sim,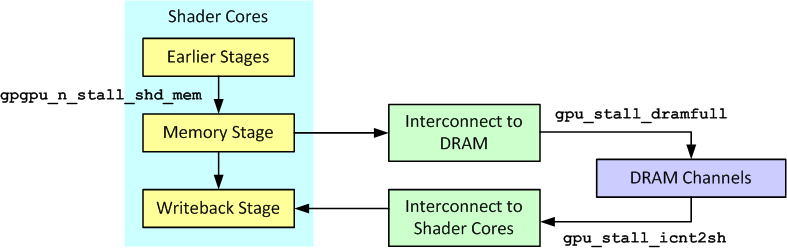
Figure 8: Memory request flow diagram
Here are the description for each counter:
| Statistic | Description |
|---|---|
| gpgpu_n_stall_shd_mem | Number of pipeline stall cycles at the memory stage caused by one of the following reasons:
|
| gpu_stall_dramfull | Number of cycles that the interconnect outputs to dram channel is stalled. |
| gpu_stall_icnt2sh | Number of cycles that the dram channels are stalled due to the interconnect congestion. |
Memory Access Statistics
| Statistic | Description |
|---|---|
| gpgpu_n_load_insn | Number of global/local load instructions executed. |
| gpgpu_n_store_insn | Number of global/local store instructions executed. |
| gpgpu_n_shmem_insn | Number of shared memory instructions executed. |
| gpgpu_n_tex_insn | Number of texture memory instructions executed. |
| gpgpu_n_const_mem_insn | Number of constant memory instructions executed. |
| gpgpu_n_param_mem_insn | Number of parameter read instructions executed. |
| gpgpu_n_cmem_portconflict | Number of constant memory bank conflict. |
| maxmrqlatency | Maximum memory queue latency (amount of time a memory request spent in the DRAM memory queue) |
| maxmflatency | Maximum memory fetch latency (round trip latency from shader core to DRAM and back) |
| averagemflatency | Average memory fetch latency |
| max_icnt2mem_latency | Maximum latency for a memory request to traverse from a shader core to the destinated DRAM channel |
| max_icnt2sh_latency | Maximum latency for a memory request to traverse from a DRAM channel back to the specified shader core |
Memory Sub-System Statistics
| Statistic | Description |
|---|---|
| gpgpu_n_mem_read_local | Number of local memory reads placed on the interconnect from the shader cores. |
| gpgpu_n_mem_write_local | Number of local memory writes placed on the interconnect from the shader cores. |
| gpgpu_n_mem_read_global | Number of global memory reads placed on the interconnect from the shader cores. |
| gpgpu_n_mem_write_global | Number of global memory writes placed on the interconnect from the shader cores. |
| gpgpu_n_mem_texture | Number of texture memory reads placed on the interconnect from the shader cores. |
| gpgpu_n_mem_const | Number of constant memory reads placed on the interconnect from the shader cores. |
Control-Flow Statistics
GPGPU-Sim reports the warp occupancy distribution which measures performance penalty due to branch divergence in the CUDA application. This information is reported on a single line following the text "Warp Occupancy Distribution:". Alternatively, you may want to grep for W0_Idle. The distribution is display in format:
| Statistic | Description |
|---|---|
| Stall | The number of cycles when the shader core pipeline is stalled and cannot issue any instructions. |
| W0_Idle | The number of cycles when all available warps are issued to the pipeline and are not ready to execute the next instruction. |
| W0_Scoreboard | The number of cycles when all available warps are waiting for data from memory. |
| WX (where X = 1 to 32) | The number of cycles when a warp with X active threads is scheduled into the pipeline. |
Code that has no branch divergence should result in no cycles with W"X" where X is between 1 and 31. See Dynamic Warp Formation: Efficient MIMD Control Flow on SIMD Graphics Hardware for more detail.
DRAM Statistics
By default, GPGPU-Sim reports the following statistics for each DRAM channel:
| Statistic | Description |
|---|---|
| n_cmd | Total number of command cycles the memory controller in a DRAM channel has elapsed. The controller can issue a single command per command cycle. |
| n_nop | Total number of NOP commands issued by the memory controller. |
| n_act | Total number of Row Activation commands issued by the memory controller. |
| n_pre | Total number of Precharge commands issued by the memory controller. |
| n_req | Total number of memory requests processed by the DRAM channel. |
| n_rd | Total number of read commands issued by the memory controller. |
| n_write | Total number of write commands issued by the memory controller. |
| bw_util | DRAM bandwidth utilization = 2 * (n_rd + n_write) / n_cmd |
| n_activity | Total number of active cycles, or command cycles when the memory controller has a pending request at its queue. |
| dram_eff | DRAM efficiency = 2 * (n_rd + n_write) / n_activity (i.e. DRAM bandwidth utilization when there is a pending request waiting to be processed) |
| mrqq: max | Maximum memory request queue occupancy. (i.e. Maximum number of pending entries in the queue) |
| mrqq: avg | Average memory request queue occupancy. (i.e. Average number of pending entries in the queue) |
Cache Statistics
For each cache (normal data cache, constant cache, texture cache alike), GPGPU-Sim reports the following statistics:
- Access = Total number of access to the cache
- Miss = Total number of misses to the cache. The number in parenthesis is the cache miss rate.
- PendingHit = Total number of pending hits in the cache. An pending hit access has hit a cache line in RESERVED state, which means there is already an inflight memory request sent by a previous cache miss on the same line. This access can be merged that previous memory access so that it does not produce memory traffic. The number in parenthesis is the ratio of accesses that exhibit pending hits.
Notice that pending hits are not counted as cache misses. Also, we do not count pending hits for cache that employs allocate-on-fill policy (e.g. read-only caches such as constant cache and texture cache).
GPGPU-Sim also calculates the total miss rate for all instances of the L1 data cache:
total_dl1_misses
total_dl1_accesses
total_dl1_miss_rate
Notice that data for L1 Total Miss Rate should be ignored when the l1 cache is turned off: -gpgpu_cache:dl1 none
Interconnect Statistics
In GPGPU-Sim, the user can configure whether to run all traffic on a single interconnection network, or on two separate physical networks (one relaying data from the shader cores to the DRAM channels and the other relaying the data back). (The motivation for using two separate networks, besides increasing bandwidth, is often to avoid "protocol deadlock" which otherwise requires additional dedicated virtual channels.) GPGPU-Sim reports the following statistics for each individual interconnection network:
| Statistic | Description |
|---|---|
| average latency | Average latency for a single flit to traverse from a source node to a destination node. |
| average accepted rate | Measured average throughput of the network relative to its total input channel throughput. Notice that when using two separate networks for traffics in different directions, some nodes will never inject data into the network (i.e. the output only nodes such as DRAM channels on the cores-to-dram network). To get the real ratio, total input channel throughput from these nodes should be ignored. That means one should multiply this rate with the ratio (total # nodes / # input nodes in this network) to get the real average accepted rate. Note that by default we use two separate networks which is set by network_count option in interconnection network config file. The two networks serve to break circular dependancies that might cause deadlocks. |
| min accepted rate | Always 0, as there are nodes that do not inject flits into the network due to the fact that we simulate two separate networks for traffic in different directions. |
| latency_stat_0_freq | A histogram showing the distribution of latency of flits traversed in the network. |
Note: Accepted traffic or throughput of a network is the amount of traffic delivered to the destination terminals of the network. If the network is below saturation all the offered traffic is accepted by the network and offered traffic would be equal to throughput of the network. The interconnect simulator calculates the accepted rate of each node by dividing the total number of packets received at a node by the total network cycles.
Visualizing High-Level GPGPU-Sim Microarchitecture Behavior
AerialVision is a GPU performance analysis tool for GPGPU-Sim that is includes with the GPGPU-Sim source code introduced in a ISPASS 2010 paper. A detailed manual describing how to use AerialVision can be found here.
Two examples of the type of high level analysis possible with AerialVision are illustrated below. Figure 9 illustrates the use of AerialVision to understand microarchitecture behavior versus time. The top row is average memory access latency versus time, the second row plots load per SIMT core versus time (vertical axis is SIMT core, color represents average instructions per cycle), the bottom row shows load per memory controller channel. Figure 10 illustrates the use of AerialVision to understand microarchiteture behavior at the source code level. This helps identify lines of code associated with uncoalesced or branch divergence.
  转存失败重新上传取消 转存失败重新上传取消 转存失败重新上传取消 转存失败重新上传取消
|
 转存失败重新上传取消 转存失败重新上传取消
|
To get GPGPU-Sim to generate a visualizer log file for the Time Lapse View, add the following option to gpgpusim.config:
-visualizer_enabled 1
The sampling frequency in this log file can be set by option -gpgpu_runtime_stat. One can also specify the name of the visualizer log file with option -visualizer_outputfile.
To generate the output for the Source Code Viewer, add the following option to gpgpusim.config:
-enable_ptx_file_line_stats 1
One can specify the output file name with option -ptx_line_stats_filename.
If you use plots generated by AerialVision in your publications, please cite the above linked ISPASS 2010 paper.
Visualizing Cycle by Cycle Microarchitecture Behavior
GPGPU-Sim 3.x provides a set of GDB macros that can be used to visualize the detail states of each SIMT core and memory partition. By setting the global variable "g_single_step" in GDB to the shader clock cycle at which you would like to start "single stepping" the shader clock, these macros can be used to observe how the microarchitecture states changes cycle-by-cycle. You can use the macros anytime GDB has stopped the simulator, but the global variable "g_single_step" is used in gpu-sim.cc to trigger a call to a hard coded software breakpoint instruction placed after all shader cores have advanced simulation by one cycle. Stopping simulation here tends to lead to more easy to interpret state.
Visibility at this level is useful for debugging and can help you gain deeper insight into how the simulated GPU micro architecture works.
These GDB macros are available in the .gdbinit file that comes with the GPGPU-Sim distribution. To use these macros, either copy the file to your home directory or to the same directory where GDB is launched. GDB will automatically detect the presence of the macro file, load it and display the following message:
** loading GPGPU-Sim debugging macros... **
| Macro | Description |
|---|---|
| dp |
Display pipeline state of the SIMT core with ID= |
| dpc |
Display the pipeline state, then continue to the next breakpoint. This version is useful if you set "g_single_step" to trigger the hard coded breakpoint where gpu_sim_cycle is incremented in gpgpu-sim::cycle() in src/gpgpu-sim/gpu-sim.cc. Repeatedly hitting enter will advance to show the pipeline contents in successive cycles. |
| dm |
Display the internal states of a memory partition with ID= |
| ptxdis |
Display PTX instructions between |
| ptxdis_func |
Display all PTX instructions inside the kernel function executed by thread |
| ptx_tids2pcs |
Display the current PCs of the threads in SIMT core |
Example of the output by dp: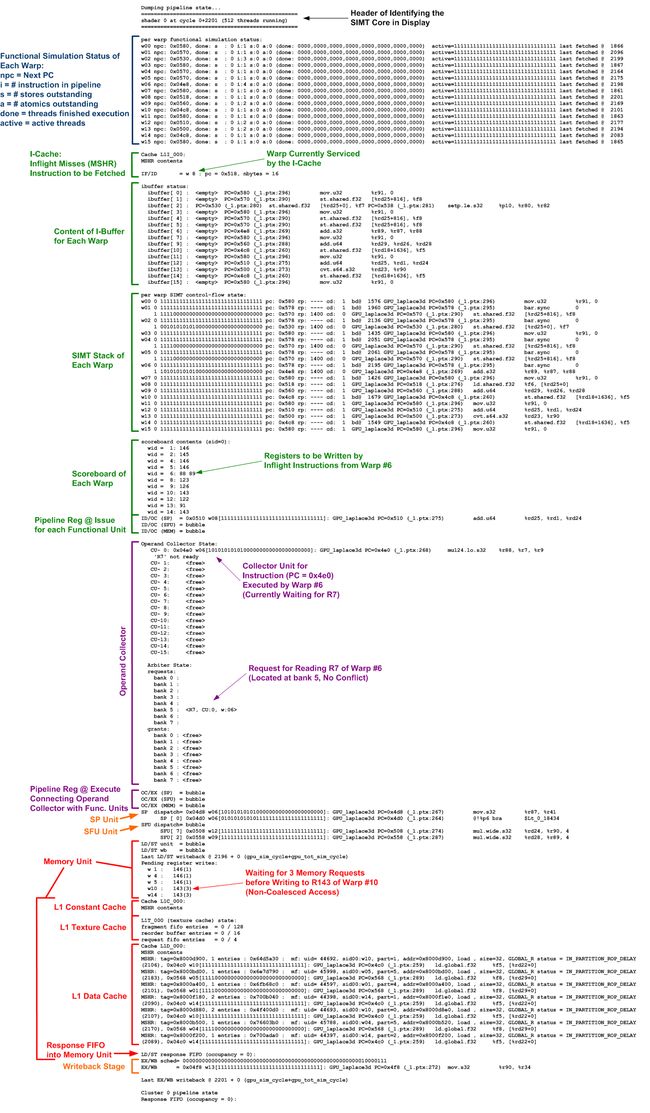 转存失败重新上传取消转存失败重新上传取消
转存失败重新上传取消转存失败重新上传取消
Figure 11: Example pipeline state print out in gdb