数据可视化(三):Python就业分析
前言
Python作为当下流行的一门语言,凭借其简单的语法和丰富的库而赢得天下。
本文所谈
- Python优缺点
- Python就业
- 结论
一、Python优缺点
优点
在搜索引擎上搜索即可获得许多答案,这里总计几点:
1.Python是一种脚本语言,写好了就可以直接运行,省去了编译链接的麻烦。
2. Python提供了非常完善的基础代码库,覆盖了网络、文件、GUI、数据库、文本等大量内容,被形象地称作“内置电池(Batteries included)”。用Python开发,许多功能不必从零编写,直接使用现成的即可。
3. 使用Python写程序很容易懂,类似英语语法,适合人类阅读,这是很多人的共识。
4. 代码更加得简洁。
5. ……
缺点
- 相比于其他主流语言,运行速度较为慢,多为项目初期迅速成型使用或初创公司或小项目使用
- 在代码量过大的时候无法确定变量类型
- 后期维护困难
- 很难读懂别人的代码
- ……
缺点大多数来自在岗Python的前辈们
二、Python就业
通过爬取boss直聘-北京地区339份Python相关招聘,通过Pycharts可视化,以此来看看Python在社会招聘中的环境。


Python薪资

统计工资前十:
可以看出20-40K是当前Python工资集中区域

我们取出最多的20-40k工资的数据来统计该条目下要求得工作经验:
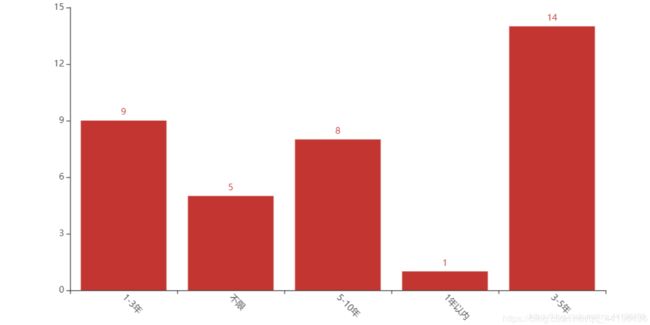
可以看出工作经验要求在3-5年的招聘公司最多
来看一下在20-40K下1-3年和不限的要求:
1.在学历方面:

2 技能要求:

3.以下这些公司招聘1-3年和不限工作经验:
['一起教育科技', '旷视MEGVII', '旷视科技(Face++)', '爱奇艺', '医渡云', 'Aibee', '旷视MEGVII']
其中硕士学历招聘来自爱奇艺:
| 岗位 | 薪资 | 招聘公司 | 其他能力 |
|---|---|---|---|
| Python | 20-40k | 爱奇艺 | ‘视频编解码’, ‘视频算法’, ‘Kubernetes’, ‘Docker’, ‘Mesos’ |
10-25K:


大佬领域-最高工资:
| 岗位 | 薪资 | 工作经验 | 招聘公司 | 其他能力 |
|---|---|---|---|---|
| python专家(J12716) | 50-70K | 10年以上 | 传智播客 | ‘视频编解码’, ‘Django’, ‘分布式技术’, ‘Linux’, ‘数据分析’, ‘Tornado’ |
除了Python,HR还要求你会:
HR要求能力中最多的能力:

可见主要还是用来后端开发
Python就业的学历要求:

大多数公司要求本科学历起步。
Python就业的工作经验要求:

Python程序员的招聘主要集中在工作经验为1-5年
哪些公司在招Python语言为主的程序员:
总计有250家在招聘,其中取前20.

旷视和华为招聘最多
旷视公司招聘详情:

旷视的核心技术是计算视觉及传感技术相关的人工智能算法,包括但不限于人脸识别、人体识别、手势识别、文字识别、证件识别、图像识别、物体识别、车牌识别、视频分析、三维重建、智能传感与控制等技术。 [2] 旷视通过底层AI算法引擎和AIoT操作系统的建设实现技术商业化。 [2]
核心客户包括阿里巴巴 [8] 、蚂蚁金服 [8] 、菜鸟网络 [9] 、富士康 [8] 、中信银行 [8] 、联想 [8] 、华为 [8] 、OPPO [10] 、vivo [8] 、小米 [8] 、凯德 [8] 、华润集团 [11] 、鲜生活
华为公司招聘详情:

其他大厂
- 腾讯

- 阿里

- 百度

- 搜狐

结论
从薪资方面来说
主要分布在20-40k,但基本上班第一年的话是开不到这么高的……
从学历方面来说
本科起点是大多数公司的要求,没有进一步爬取是否要求985、211,但计算机基本上除了机器学习以为不是太吃学历
从公司方面来说
小到创业公司大到大厂都有需求
从能力方面来说
总体来看是倾向于后端,flask、django等主流框架要求掌握还有一些设计理念……不可否认,go语言有取代python语言的趋势……
不足
数据仅有北京地区339份,无法代表整个市场全貌
最后
boss爬虫就是简单的request-xpath爬虫,写的比较烂,主要难度是boss在爬取第五页往后,会改变cookies,感觉是2页改变一次,需要手动更换,可以用selenium.
import requests,json,time
from lxml import etree
url='https://www.zhipin.com/c101010100/?'
list_url=[]
onelist=[]
def geturl():
for i in range(1,30):
urls=f'query=python&page={i}&ka=page-{i}'
list_url.append(url+urls)
print('url获取完成')
def spider():
dic={}
cookiesnew='lastCity=101010100; sid=sem_pz_bdpc_dasou_title; __zp_seo_uuid__=976e64d1-1bb5-42c1-831d-debb272746a6; __c=1587478249; __g=sem_pz_bdpc_dasou_title; Hm_lvt_194df3105ad7148dcf2b98a91b5e727a=1586788824,1587049843,1587456549,1587478249; __l=l=%2Fwww.zhipin.com%2Fbeijing%2F%3Fsid%3Dsem_pz_bdpc_dasou_title&r=https%3A%2F%2Fsp0.baidu.com%2F9q9JcDHa2gU2pMbgoY3K%2Fadrc.php%3Ft%3D06KL00c00fDdiHC088qh0KZEgsZ-OG4X000007hOm-C00000W5onYv.THdBULP1doZA80K85yF9pywd0Znqujb3mvcsmH0snj7-nWDdP0Kd5HfswWDkwWFawDm3n1IawH03wbmdnRc3PH0LPjmkwRRY0ADqI1YhUyPGujY1n1f1PWTsnHckFMKzUvwGujYkP6K-5y9YIZK1rBtEILILQMGCpgKGUB4WUvYE5LPGujd1uydxTZGxmhwsmdqbmgPEINqYpgw_ufKWThnqPHbdrHD%26tpl%3Dtpl_11534_21264_17382%26l%3D1516420953%26attach%3Dlocation%253D%2526linkName%253D%2525E6%2525A0%252587%2525E5%252587%252586%2525E5%2525A4%2525B4%2525E9%252583%2525A8-%2525E6%2525A0%252587%2525E9%2525A2%252598-%2525E4%2525B8%2525BB%2525E6%2525A0%252587%2525E9%2525A2%252598%2526linkText%253DBOSS%2525E7%25259B%2525B4%2525E8%252581%252598%2525E2%252580%252594%2525E2%252580%252594%2525E6%252589%2525BE%2525E5%2525B7%2525A5%2525E4%2525BD%25259C%2525EF%2525BC%25258C%2525E6%252588%252591%2525E8%2525A6%252581%2525E8%2525B7%25259F%2525E8%252580%252581%2525E6%25259D%2525BF%2525E8%2525B0%252588%2525EF%2525BC%252581%2526xp%253Did(%252522m3343670121_canvas%252522)%25252FDIV%25255B1%25255D%25252FDIV%25255B1%25255D%25252FDIV%25255B1%25255D%25252FDIV%25255B1%25255D%25252FDIV%25255B1%25255D%25252FH2%25255B1%25255D%25252FA%25255B1%25255D%2526linkType%253D%2526checksum%253D140%26ie%3Dutf-8%26f%3D8%26tn%3Dbaidu%26wd%3Dboss%25E7%259B%25B4%25E8%2581%2598%26oq%3D81.0.4044.69%26rqlang%3Dcn%26inputT%3D2417%26sug%3Dboss%2525E7%25259B%2525B4%2525E8%252581%252598%2525E5%2525AE%252598%2525E7%2525BD%252591&g=%2Fwww.zhipin.com%2Fbeijing%2F%3Fsid%3Dsem_pz_bdpc_dasou_title&friend_source=0&friend_source=0; __a=66278293.1579593066.1587456549.1587478249.208.16.39.39; Hm_lpvt_194df3105ad7148dcf2b98a91b5e727a=1587482408; __zp_stoken__=1ea4GEI7MGkL3rzMmzKhZG5zatkOchpq1UHpvoZX6EDo37Efj6gkwTHqo13UREh19Qc7GyFpcFNqBYBS4OipVI9fJvaSVcqiwhwAbHy2iBh9Faa8WwYTsyymC%2B4CkBrkv9pd'
for n in list_url[14:]:
print('当前爬取{}'.format(n))
header={'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/79.0.3945.88 Safari/537.36',
'accept-encoding':'gzip, deflate, br',
'accept-language':'zh-CN,zh;q=0.9',
'cookie':cookiesnew,
'referer':n,
'sec-fetch-dest':'document',
'sec-fetch-mode':'navigate',
'sec-fetch-site':'same-origin',
'sec-fetch-user':'?1',
'upgrade-insecure-requests':'1'}
contents={}
res=requests.get(n,headers=header).text
dom=etree.HTML(res)
titles=dom.xpath(f'//*[@id="main"]/div/div[2]/ul/li[1]/div/div[1]/div[1]/div/div[1]/span[1]/a/text()')
if titles==[]:
cookiesnew=''
cookiesnew=input('输入新的cookie')
res=requests.get(n,headers=header).text
dom=etree.HTML(res)
for i in range(1,31):
title=dom.xpath(f'//*[@id="main"]/div/div[2]/ul/li[{i}]/div/div[1]/div[1]/div/div[1]/span[1]/a/text()')
where=dom.xpath(f'//*[@id="main"]/div/div[2]/ul/li[{i}]/div/div[1]/div[2]/div/h3/a/text()')
wages=dom.xpath(f'//*[@id="main"]/div/div[2]/ul/li[{i}]/div/div[1]/div[1]/div/div[2]/span/text()')
workedyears=dom.xpath(f'//*[@id="main"]/div/div[2]/ul/li[{i}]/div/div[1]/div[1]/div/div[2]/p/text()[1]')
edu=dom.xpath(f'//*[@id="main"]/div/div[2]/ul/li[{i}]/div/div[1]/div[1]/div/div[2]/p/text()')
company=dom.xpath(f'//*[@id="main"]/div/div[2]/ul/li[{i}]/div/div[1]/div[2]/div/h3/a/text()')
ability=dom.xpath(f'//*[@id="main"]/div/div[2]/ul/li[{i}]/div/div[2]/div[1]/span/text()')
contents={
'title':title,
'wages':wages,
'workedyears':workedyears,
'edu':edu,
'company':company,
'ability':ability
}
onelist.append(contents)
else:
for i in range(1,31):
title=dom.xpath(f'//*[@id="main"]/div/div[2]/ul/li[{i}]/div/div[1]/div[1]/div/div[1]/span[1]/a/text()')
where=dom.xpath(f'//*[@id="main"]/div/div[2]/ul/li[{i}]/div/div[1]/div[2]/div/h3/a/text()')
wages=dom.xpath(f'//*[@id="main"]/div/div[2]/ul/li[{i}]/div/div[1]/div[1]/div/div[2]/span/text()')
workedyears=dom.xpath(f'//*[@id="main"]/div/div[2]/ul/li[{i}]/div/div[1]/div[1]/div/div[2]/p/text()[1]')
edu=dom.xpath(f'//*[@id="main"]/div/div[2]/ul/li[{i}]/div/div[1]/div[1]/div/div[2]/p/text()')
company=dom.xpath(f'//*[@id="main"]/div/div[2]/ul/li[{i}]/div/div[1]/div[2]/div/h3/a/text()')
ability=dom.xpath(f'//*[@id="main"]/div/div[2]/ul/li[{i}]/div/div[2]/div[1]/span/text()')
contents={
'title':title,
'wages':wages,
'workedyears':workedyears,
'edu':edu,
'company':company,
'ability':ability
}
onelist.append(contents)
geturl()
spider()
可视化见Pycharts_demohttp://gallery.pyecharts.org/#/README
最最后
如果本文对你有所收货,那就点个赞吧