SCA-CNN: Spatial and Channel-wise Attention in Convolutional Networks for Image Captioning
来源: CVPR2017
关键词:imaging captioning; attention mechanism
原文
Motivation
visual attention已经在image/video captioning 和 visual question answering 任务中取得了成功. 其合理之处在于人总是根据需要有选择性的观察图像的一部分.
文中将attention-based models 分为三类:
- Spatial Attention: weighted pooling 损失了空间信息; attention is only applied in the last conv-layer.
- Semantic Attention: these models require external resources to train these semantic attributes.
- Multi-layer Attention: To overcome the weakness of large respective field size in the last conv-layer attention, Seo et al. [22] proposed a multi-layer attention networks.
但是,目前的attention-based image captioning model仅仅是考虑到spatial characteristic.比如, re-weight the last conv-layer feature map of a CNN encoding an input image.因此,本文提出了SCA-CNN,利用了多层3D feature maps的每个feature entry.
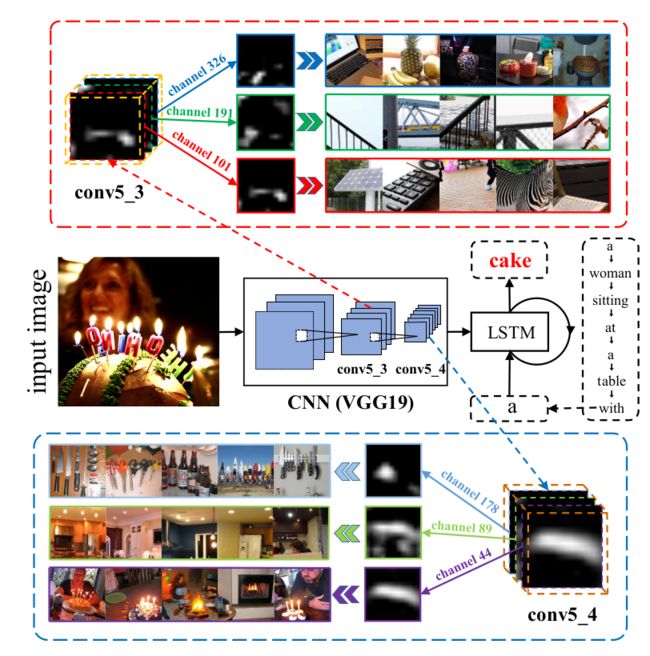
如上图所示, 首先, 不同的filter从不同的角度提取特征,channel-wise attention可以根据需要选择语义相关的特征.
For example, when we want to predict cake, our channel-wise attention(e.g., in the conv5_3/conv5_4 feature map) will assign more weights on channel-wise feature maps generated by filters according to the semantics like cake, fire, light, and candle-like shapes.
第二, 一个feature map取决于低层的feature maps, 所以层间注意力机制是很自然的.
For example, it is beneficial to emphasize on lower-layer channels corresponding to more elemental shapes like array and cylinder that compose cake
Spatial and Channel-wise Attention CNN
本文的做法总结为一句话就是:在encoder-decoder模型的基础上makes the original CNN multi-layer feature maps adaptive to the sentence context through channel-wise attention and spatial attention at multiple layers.
在第 l l 层, spatial and channel-wise attention weights γl γ l 是经过以 ht−1 h t − 1 和 Vl V l 为参数的函数计算得到的. ht−1∈Rd h t − 1 ∈ R d 是LSTM的上一个隐状态. Vl V l 是当前层的CNN features. 本文中的注意力机制通过下面式子来表达:
为了节省计算空间,作者提出了近似计算方法,spatial attention weights αl α l 和 channel-wise attention weights βl β l 分别计算:
Spatial Attention
不失一般性.我们丢掉下标 l l ,并且把 V V 变为 m=WH m = W H 个 C C 维向量, V=[v1,v2,...,vm] V = [ v 1 , v 2 , . . . , v m ] . Φs Φ s 可通过下面的方式计算:

Channel-wise Attention
CNN中的filter可以看做不同的pattern dector. 因此,对filter maps进行channel-wise attention可以看做对语义相关的特征的选择.
首先将 V V reshape为 U=[u1,u2,...uC] U = [ u 1 , u 2 , . . . u C ] , 其中, ui∈RW×H u i ∈ R W × H , 再对每个feature map进行mean pooling得到 v v :

根据channel-wise attention and spatial attention的先后顺序,可以分为Channel-Spatial(C-S)和Spatial-Channel(S-C)两种类型的模型。
Result
略
Conclusions
优点:在spatial, channel-wise, and multi-layer三个层面都引入了attention机制,而不仅仅是spatial层面;相关工作总结的很好;实验比较翔实。
问题:增加attention的层数后易发生过拟合。