DL-Pytorch Task04:机器翻译及相关技术;注意力机制与Seq2seq模型;Transformer
目录
- 机器翻译及相关技术
- 数据预处理
- 分词
- 建立词典
- 载入数据集
- Encoder-Decoder
- Sequence to Sequence模型
- 损失函数
- 训练
- Beam Search
- 注意力机制与Seq2seq模型
- 注意力机制框架
- Softmax屏蔽
- 点积注意力
- 多层感知机注意力
- 引入注意力机制的Seq2seq模型
- 解码器
- 习题知识点
机器翻译及相关技术
将一段文本从一种语言自动翻译为另一种语言,用神经网络解决这个问题通常称为神经机器翻译(NMT)。机器翻译是通过循环神经网络来实现的,但是使用的并不是传统的循环神经网络。
主要特征:输出是单词序列而不是单个单词。 输出序列的长度可能与源序列的长度不同。
数据预处理
对数据集进行预处理,清洗数据,即去除或者替换一些容易使程序报错的乱码、在字母与标点之间添加空格、将所有字母转换成小写形式等操作。
替换操作用replace()函数。
str.replace(old, new[, max])
old – 将被替换的子字符串;new – 新字符串,用于替换old子字符串;max – 可选字符串, 替换不超过 max 次。
分词
经过数据预处理后的文本仍然是字符串,字符串的形式是机器无法理解的,因此需要进行分词操作,将字符串分词后形成由单词组成的列表。
此处用到了str.split()函数。
str.split(str="", num=string.count(str)).
str – 分隔符,默认为所有的空字符,包括空格、换行(\n)、制表符(\t)等;
num – 分割次数,默认为 -1, 即分隔所有。
建立词典
在分词操作中得到了由单词组成的列表,建立词典这一步操作是将文本中出现的所有词构成一个词典,即得到一个由单词id组成的列表。
def build_vocab(tokens):
tokens = [token for line in tokens for token in line]
return d2l.data.base.Vocab(tokens, min_freq=3, use_special_tokens=True)
建立词典用到了一个很重要的类。

简要介绍一下这个类中一些参数的含义以及用到的一些函数:
(1)use_special_tokens使用了一些特殊字符:
pad的作用是在采用批量样本训练时,对于长度不同的样本(句子),对于短的样本采用pad进行填充,使得每个样本的长度是一致的;
bos( begin of sentence)和eos(end of sentence)是用来表示一句话的开始和结尾;
unk(unknow)的作用是,处理遇到从未出现在预料库的词时都统一认为是unknow ,在代码中还可以将一些频率特别低的词也归为这一类。
建立词典时每个单词对应都有一个id,上面四个特殊字符已经被赋予了id为0、1、2、3,因此文本中的字符id应该从4开始。
(2)idx_to_token建立了一个从id到单词的映射,id可以作为列表的id,直接从字典中取出单词,用列表取元素的方法即可。
(3)token_to_idx建立了一个从单词到id的映射,因此需要使用字典结构dict(),输入一个单词输出单词对应的id。
(4)__getitem__和token_to_idx类似,不过对于__getitem__,输入的是一个单词列表,输出的是单词对应的id组成的一个列表。
载入数据集
一个句子在输入的时候要做到每一个batch里所有输入的句子长度是一样的,因为一个batch使用的是同一个时序大小的RNN,所以需要对句子进行pad,即长度不够的需要用pad进行填充。
补齐之后将每一个句子转换成一个id序列,即使用前面提到的__getitem__函数,这个函数是个魔法函数。
魔法函数是Python中定义的,以__ 开头,__结尾,形如__fun__()的函数,一般使用已经定义好了的即可。使用这样一些函数,可以让我们自定义的类有更加强大的特性。魔法函数一般是隐式调用的,不需要我们显示调用。
魔法函数不属于定义它的那个类,只是增强了类的一些功能。实现了特定的魔法函数之后,某些操作会变得特别简单。我们可以采用实现魔法函数来灵活地设计我们需要的类。
def build_array(lines, vocab, max_len, is_source):
lines = [vocab[line] for line in lines]
if not is_source:
lines = [[vocab.bos] + line + [vocab.eos] for line in lines]
array = torch.tensor([pad(line, max_len, vocab.pad) for line in lines])
valid_len = (array != vocab.pad).sum(1) #第一个维度
return array, valid_len
在这个代码段中vocab[line]就实现了__getitem__的功能。(我还是没有明白怎么调用的这个魔法函数…)。
is_source用来判断是翻译样本还是翻译目标语言,这里表示如果是target句子的话,就需要在每行句子前后加上开始和结束特殊字符。
Encoder-Decoder
encoder:输入到隐藏状态
decoder:隐藏状态到输出

在之前已经介绍过机器翻译存在输入与输出长度不等的问题,这个问题就需要使用Encoder-Decoder来解决。
Encoder将输入翻译成一个语义编码,语义编码就相当于是一个隐藏状态(hidden state),再由Decoder翻译输出,当输出到eos(即结束符)时输出就停止。
class Encoder(nn.Module):
def __init__(self, **kwargs):
super(Encoder, self).__init__(**kwargs)
def forward(self, X, *args):
raise NotImplementedError
class Decoder(nn.Module):
def __init__(self, **kwargs):
super(Decoder, self).__init__(**kwargs)
def init_state(self, enc_outputs, *args):
raise NotImplementedError
def forward(self, X, state):
raise NotImplementedError
Encoder-Decoder可以应用在对话系统、生成式任务中。
Sequence to Sequence模型
在Encoder-Decoderencoder和decoder都是循环神经网络结构,其中encoder输出得到语义编码,decoder也可以叫做一个生成式的语言模型。循环神经网络的隐藏层状态一般都要初始化为零,而在decoder中隐藏层状态则被初始化为encoder输出得到的语义编码,训练时把bos开始符作为decoder的第一个输入。
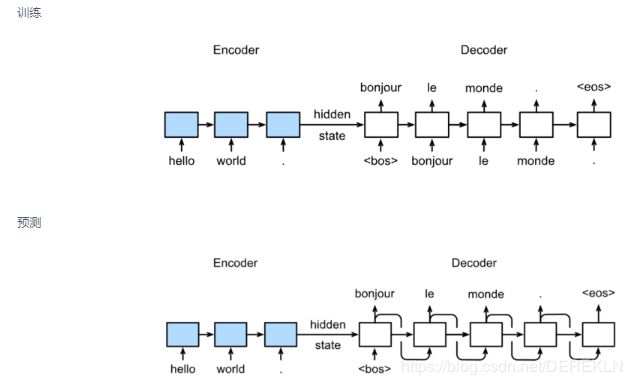
训练和预测时decoder的每一个时序单元输出都会伴有一个隐藏状态的更新,这个更新的隐藏状态需要参与到下一个时序单元的输出中。
具体模型为:

sources为输入样本单词对应的id列表,这个列表不能直接输入到网络中去,而是在Embedding层先将列表对应转化为一个个形状大小相同的词向量,
decoder和encoder类似,多了一个dense层,dense层用来输出训练或预测的单词。
Encoder
class Seq2SeqEncoder(d2l.Encoder):
def __init__(self, vocab_size, embed_size, num_hiddens, num_layers,
dropout=0, **kwargs):
super(Seq2SeqEncoder, self).__init__(**kwargs)
self.num_hiddens=num_hiddens
self.num_layers=num_layers
self.embedding = nn.Embedding(vocab_size, embed_size)
self.rnn = nn.LSTM(embed_size,num_hiddens, num_layers, dropout=dropout)
def begin_state(self, batch_size, device):
return [torch.zeros(size=(self.num_layers, batch_size, self.num_hiddens), device=device),
torch.zeros(size=(self.num_layers, batch_size, self.num_hiddens), device=device)]
def forward(self, X, *args):
X = self.embedding(X) # X shape: (batch_size, seq_len, embed_size)
X = X.transpose(0, 1) # RNN needs first axes to be time
# state = self.begin_state(X.shape[1], device=X.device)
out, state = self.rnn(X)
# The shape of out is (seq_len, batch_size, num_hiddens).
# state contains the hidden state and the memory cell
# of the last time step, the shape is (num_layers, batch_size, num_hiddens)
return out, state
Decoder
class Seq2SeqDecoder(d2l.Decoder):
def __init__(self, vocab_size, embed_size, num_hiddens, num_layers,
dropout=0, **kwargs):
super(Seq2SeqDecoder, self).__init__(**kwargs)
self.embedding = nn.Embedding(vocab_size, embed_size)
self.rnn = nn.LSTM(embed_size,num_hiddens, num_layers, dropout=dropout)
self.dense = nn.Linear(num_hiddens,vocab_size)
def init_state(self, enc_outputs, *args):
return enc_outputs[1]
def forward(self, X, state):
X = self.embedding(X).transpose(0, 1)
out, state = self.rnn(X, state)
# Make the batch to be the first dimension to simplify loss computation.
out = self.dense(out).transpose(0, 1)
return out, state
损失函数
在载入数据集产生batch时使用了padding将句子长度补齐,而在计算损失函数时需要避免补齐部分产生的loss,所以需要先将原来的句子超出有效长度的部分用0或者1进行替换。
def SequenceMask(X, X_len,value=0):
maxlen = X.size(1)
mask = torch.arange(maxlen)[None, :].to(X_len.device) < X_len[:, None]
X[~mask]=value
return X
X是一个batch的输入,X_len是有效长度。
定义损失函数:
class MaskedSoftmaxCELoss(nn.CrossEntropyLoss):
# pred shape: (batch_size, seq_len, vocab_size)
# label shape: (batch_size, seq_len)
# valid_length shape: (batch_size, )
def forward(self, pred, label, valid_length):
# the sample weights shape should be (batch_size, seq_len)
weights = torch.ones_like(label)
weights = SequenceMask(weights, valid_length).float()
self.reduction='none'
output=super(MaskedSoftmaxCELoss, self).forward(pred.transpose(1,2), label)
return (output*weights).mean(dim=1)
其中# pred shape: (batch_size, seq_len, vocab_size)为预测的结果,最后一个维度vocab_size的每个单元记录的是预测出结果对应建立的词典中每个词典的得分(可以理解为概率)。
训练
def train_ch7(model, data_iter, lr, num_epochs, device): # Saved in d2l
model.to(device)
optimizer = optim.Adam(model.parameters(), lr=lr)
loss = MaskedSoftmaxCELoss()
tic = time.time()
for epoch in range(1, num_epochs+1):
l_sum, num_tokens_sum = 0.0, 0.0
for batch in data_iter:
optimizer.zero_grad()
X, X_vlen, Y, Y_vlen = [x.to(device) for x in batch]
Y_input, Y_label, Y_vlen = Y[:,:-1], Y[:,1:], Y_vlen-1
Y_hat, _ = model(X, Y_input, X_vlen, Y_vlen)
l = loss(Y_hat, Y_label, Y_vlen).sum()
l.backward()
with torch.no_grad():
d2l.grad_clipping_nn(model, 5, device)
num_tokens = Y_vlen.sum().item()
optimizer.step()
l_sum += l.sum().item()
num_tokens_sum += num_tokens
if epoch % 50 == 0:
print("epoch {0:4d},loss {1:.3f}, time {2:.1f} sec".format(
epoch, (l_sum/num_tokens_sum), time.time()-tic))
tic = time.time()
要注意device这个参数,所有参与反向传播计算的参数都要放在同一个device上。
Y:bos word eos
Y_input:decoder的输入 bos word
Y_label:decoder输出的groundtruth真值 word eos
Y_vlen:原本认为的有效长度是 bos word eos的长度,实际label的有效长度是word eos的长度,所以需要减一
Y_hat:通过模型生成的预测的Y值
所以最终是利用Y_label、Y_hat、Y_vlen来计算loss。
with torch.no_grad():
d2l.grad_clipping_nn(model, 5, device)
这一段的作用是梯度裁剪。
Beam Search
在上一小节提到过,# pred shape: (batch_size, seq_len, vocab_size)为预测的结果,最后一个维度vocab_size的每个单元记录的是预测出结果对应建立的词典中每个词典的得分(可以理解为概率),选取得分最高的一个词作为输出。这样会产生一个问题是输出只考虑当前时序下的最优解,并没有将整个语句的语义连贯性考虑进去。
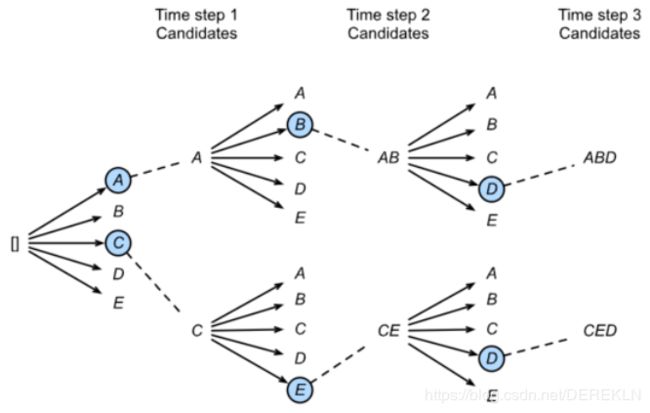
因此产生了维比特算法,这个方法是在对每一个时刻每一个得分对应的输出都统计一遍最后选取一个总体得分最高的为语句连贯性合理性最佳的输出,但是这样做会导致搜索空间太大。基于以上两种方案,提出了Beam Search(集束搜索)。
比如当beam=2时,每一次输出选取得分最高的两个进行下一步预测,在下一步预测也选取得分最高的两个进行下下一步预测最后得到结果。
注意力机制与Seq2seq模型
注意力机制框架
Attention 是一种通用的带权池化方法,输入由两部分构成:询问(query)和键值对(key-value pairs)。 k i ∈ R d k , v i ∈ R d r . \mathbf{k}_{i} \in \mathbb{R}^{d_{k}}, \mathbf{v}_{i} \in \mathbb{R}^{d_{r}} . ki∈Rdk,vi∈Rdr. Query q ∈ R d 9 \mathbf{q} \in \mathbb{R}^{d_{9}} q∈Rd9 , attention layer得到输出与value的维度一致 o ∈ R d v \mathbf{o} \in \mathbb{R}^{d_{v}} o∈Rdv. 对于一个query来说,attention layer 会与每一个key计算注意力分数并进行权重的归一化,输出的向量 o o o则是value的加权求和,而每个key计算的权重与value一一对应。
为了计算输出,我们首先假设有一个函数 α \alpha α 用于计算query和key的相似性,然后可以计算所有的 attention scores a 1 , … , a n a_1, \ldots, a_n a1,…,an by
a i = α ( q , k i ) . a_i = \alpha(\mathbf q, \mathbf k_i). ai=α(q,ki).
我们使用 softmax函数 获得注意力权重:
b 1 , … , b n = softmax ( a 1 , … , a n ) . b_1, \ldots, b_n = \textrm{softmax}(a_1, \ldots, a_n). b1,…,bn=softmax(a1,…,an).
最终的输出就是value的加权求和:
o = ∑ i = 1 n b i v i . \mathbf o = \sum_{i=1}^n b_i \mathbf v_i. o=i=1∑nbivi.
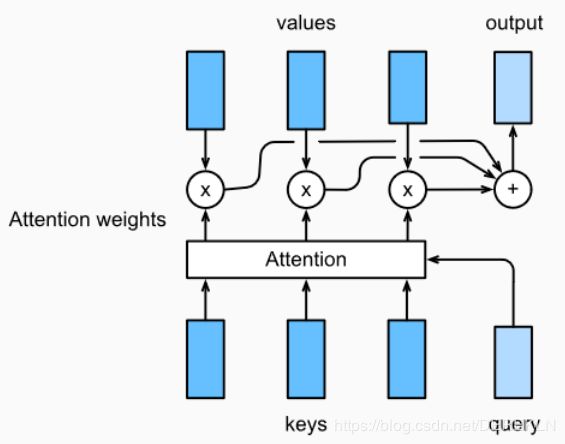
不同的attetion layer的区别在于score函数的选择,在本节的其余部分,我们将讨论两个常用的注意层 Dot-product Attention 和 Multilayer Perceptron Attention;随后我们将实现一个引入attention的seq2seq模型并在英法翻译语料上进行训练与测试。
Softmax屏蔽
def SequenceMask(X, X_len,value=-1e6):
maxlen = X.size(1)
#print(X.size(),torch.arange((maxlen),dtype=torch.float)[None, :],'\n',X_len[:, None] )
mask = torch.arange((maxlen),dtype=torch.float)[None, :] >= X_len[:, None]
#print(mask)
X[mask]=value
return X
这里先介绍torch.squeeze()和torch.unsqueeze()两个函数,详见squeeze函数。
其中mask = torch.arange((maxlen),dtype=torch.float)[None, :] >= X_len[:, None]Tensor的特殊索引方式详见Tensor中None索引。
点积注意力
The dot product 假设query和keys有相同的维度, 即 ∀ i , q , k i ∈ R d \forall i, \mathbf{q}, \mathbf{k}_{i} \in \mathbb{R}_{d} ∀i,q,ki∈Rd。通过计算query和key转置的乘积来计算attention score,通常还会除去 d \sqrt{d} d 减少计算出来的score对维度的依赖性,如下
α ( q , k ) = ⟨ q , k ⟩ / d \alpha(\mathbf{q}, \mathbf{k})=\langle\mathbf{q}, \mathbf{k}\rangle / \sqrt{d} α(q,k)=⟨q,k⟩/d
假设 Q ∈ R ∧ { m × d } \mathbf{Q} \in \mathbb{R}^{\wedge}\{m \times d\} Q∈R∧{m×d}有 m m m 个query, K ∈ R n × d \mathbf{K} \in \mathbb{R}^{n \times d} K∈Rn×d有 n n n 个keys. 我们可以通过矩阵运算的方式计算所有 m n mn mn 个score:
α ( Q , K ) = Q K T / d \alpha(\mathbf{Q}, \mathbf{K})=\mathbf{Q} \mathbf{K}^{T} / \sqrt{d} α(Q,K)=QKT/d
现在让我们实现这个层,它支持一批查询和键值对。此外,它支持作为正则化随机删除一些注意力权重。
多层感知机注意力
在多层感知器中,我们首先将 query and keys 投影到 R h ℝ^ℎ Rh .为了更具体,我们将可以学习的参数做如下映射 W k ∈ R h × d k , W q ∈ R h × d q , \mathbf{W}_{k} \in \mathbb{R}^{h \times d_{k}}, \mathbf{W}_{q} \in \mathbb{R}^{h \times d_{q}}, Wk∈Rh×dk,Wq∈Rh×dq, and v ∈ R h \mathbf{v} \in \mathbb{R}^{h} v∈Rh。将score函数定义
α ( k , q ) = v T tanh ( W k k + W q q ) \alpha(\mathbf{k}, \mathbf{q})=\mathbf{v}^{T} \tanh \left(\mathbf{W}_{k} \mathbf{k}+\mathbf{W}_{q} \mathbf{q}\right) α(k,q)=vTtanh(Wkk+Wqq)
然后将key 和 value 在特征的维度上合并(concatenate),然后送至 a single hidden layer perceptron 这层中 hidden layer 为 ℎ and 输出的size为 1 .隐层激活函数为tanh,无偏置.
引入注意力机制的Seq2seq模型
本节中将注意机制添加到sequence to sequence 模型中,以显式地使用权重聚合states。下图展示encoding 和decoding的模型结构,在时间步为t的时候。此刻attention layer保存着encodering看到的所有信息——即encoding的每一步输出。在decoding阶段,解码器的 t t t时刻的隐藏状态被当作query,encoder的每个时间步的hidden states作为key和value进行attention聚合. Attetion model的输出当作成上下文信息context vector,并与解码器输入 D t D_t Dt拼接起来一起送到解码器:
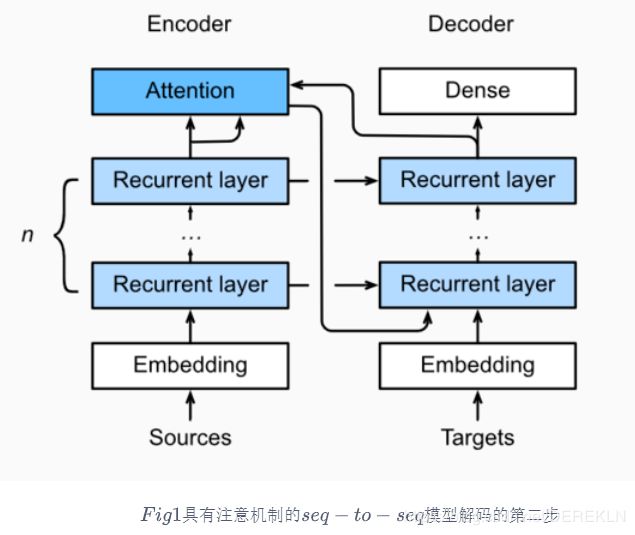
下图展示了seq2seq机制的所以层的关系,下面展示了encoder和decoder的layer结构:
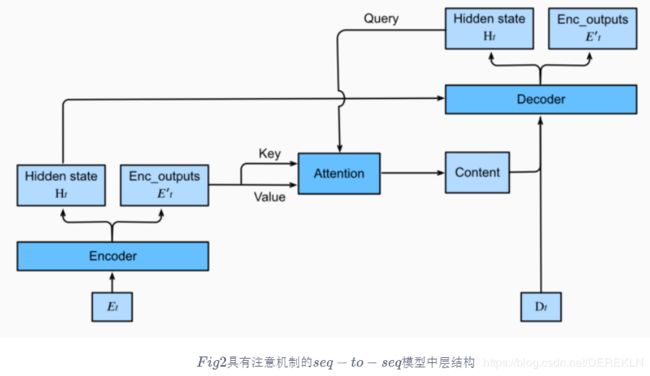
解码器
由于带有注意机制的seq2seq的编码器与之前章节中的Seq2SeqEncoder相同,所以在此处我们只关注解码器。我们添加了一个MLP注意层(MLPAttention),它的隐藏大小与解码器中的LSTM层相同。然后我们通过从编码器传递三个参数来初始化解码器的状态:
-
the encoder outputs of all timesteps:encoder输出的各个状态,被用于attetion layer的memory部分,有相同的key和values
-
the hidden state of the encoder’s final timestep:编码器最后一个时间步的隐藏状态,被用于初始化decoder 的hidden state
-
the encoder valid length: 编码器的有效长度,借此,注意层不会考虑编码器输出中的填充标记(Paddings)
在解码的每个时间步,我们使用解码器的最后一个RNN层的输出作为注意层的query。然后,将注意力模型的输出与输入嵌入向量连接起来,输入到RNN层。虽然RNN层隐藏状态也包含来自解码器的历史信息,但是attention model的输出显式地选择了enc_valid_len以内的编码器输出,这样attention机制就会尽可能排除其他不相关的信息。
习题知识点
(1)在Dot-product Attention中,key与query维度需要一致,在MLP Attention中则不需要。
(2)点积注意力层不引入新的模型参数,注意力掩码可以用来解决一组变长序列的编码问题。
(3)加入Attention机制的seq2seq模型的预测需人为设定终止条件,设定最长序列长度或者输出[EOS]结束符号,若不加以限制则可能生成无穷长度序列。每个时间步,解码器输入的语境向量(context vector)不相同,每个位置都会计算各自的attention输出。解码器RNN仍由编码器最后一个时间步的隐藏状态初始化。注意力机制本身有高效的并行性,但引入注意力并不能改变seq2seq内部RNN的迭代机制,因此无法加速模型训练。
(4)