Spark SQL源码剖析之SqlParser解析
在使用Spark的过程中,由于Scala语法复杂,而且更多的人越来越倾向使用SQL,将复杂的问题简单化处理,避免编写大量复杂的逻辑代码,所以我们想是不是可以开发一款类似Hive的工具,将其思想也应用在Spark之上,建立SQL来处理一些离线计算场景,由于Spark SQL应用而生。在本篇文章中,我们准备深入源码了解Spark SQL的内核组件以及其工作原理。
熟悉Spark的读者都知道,当我们调用了SQLContext的sql()函数的时候,就会调用Spark SQL的内核来处理这条sql语句,那么中间过程究竟是如何进行的呢?这里我们先抛出它的内核基本执行流程,然后分各个阶段深入了解。
首先我们观察SQLContext的源码,部分源码如下:
//字典表,用于注册表,对表缓存后便于查询
@transient
protected[sql] lazy val catalog: Catalog = new SimpleCatalog(true)
@transient
protected[sql] lazy val functionRegistry: FunctionRegistry = new SimpleFunctionRegistry(true)
//对未分析过的逻辑执行计划进行分析
@transient
protected[sql] lazy val analyzer: Analyzer =
new Analyzer(catalog, functionRegistry, caseSensitive = true) {
override val extendedResolutionRules =
ExtractPythonUdfs ::
sources.PreInsertCastAndRename ::
Nil
override val extendedCheckRules = Seq(
sources.PreWriteCheck(catalog)
)
}
//查询优化器,将逻辑计划进行优化
@transient
protected[sql] lazy val optimizer: Optimizer = DefaultOptimizer
//解析DDL语句,如何创建表
@transient
protected[sql] val ddlParser = new DDLParser(sqlParser.apply(_))
//进行SQL解析操作
@transient
protected[sql] val sqlParser = {
val fallback = new catalyst.SqlParser
new SparkSQLParser(fallback(_))
}
......
@transient
protected[sql] val planner = new SparkPlanner
@transient
protected[sql] lazy val emptyResult = sparkContext.parallelize(Seq.empty[Row], 1)
/**
* Prepares a planned SparkPlan for execution by inserting shuffle operations as needed.
*/
@transient
protected[sql] val prepareForExecution = new RuleExecutor[SparkPlan] {
val batches =
Batch("Add exchange", Once, AddExchange(self)) :: Nil
}
可以看到SQLContext由以下组件构成:
- Catalog:字典表,用于注册表,对表缓存后便于查询
- DDLParser:用于解析DDL语句,如创建表。
- SparkSQLParser:作为
SqlParser的代理,处理一些SQL中的关键字。 - SqlParser:用于解析select语句。
- Analyzer:对还未分析的逻辑执行计划进行分析。
- Optimizer:对已经分析过的逻辑执行计划进行优化。
- SparkPlanner:用于将逻辑执行计划转换为物理执行计划。
- prepareForExecution:用于将物理执行计划转换为可执行的物理执行计划。
它的整个执行流程如下:
- 首先使用
SqlParser将SQL解析为Unresolved LogicalPlan。 Analyzer结合数据字典Catalog进行绑定,生成Resolved LogicalPlan。- 使用
Optimizer对Resolved LogicalPlan进行优化,生成Optimizer LogicalPlan。 SparkPlanner将LogicalPlan转换为PhysicalPlan。- 使用
prepareForExecution将PhysicalPlan转换为可执行的物理执行计划。 - 调用
execute()执行可执行物理执行计划,生成SchemaRDD。
整个执行流程图如下:

在了解了它基本执行流程之后,我们看看它的各个组件的作用以及组成。
Catalog
它是一个接口,主要有以下方法:
trait Catalog {
//大小写是否敏感
def caseSensitive: Boolean
//表是否存在
def tableExists(tableIdentifier: Seq[String]): Boolean
//使用表名查找关系
def lookupRelation(
tableIdentifier: Seq[String],
alias: Option[String] = None): LogicalPlan
/**
* Returns tuples of (tableName, isTemporary) for all tables in the given database.
* isTemporary is a Boolean value indicates if a table is a temporary or not.
*/
def getTables(databaseName: Option[String]): Seq[(String, Boolean)]
def refreshTable(databaseName: String, tableName: String): Unit
//注册表
def registerTable(tableIdentifier: Seq[String], plan: LogicalPlan): Unit
//取消注册表
def unregisterTable(tableIdentifier: Seq[String]): Unit
//取消注册所有表
def unregisterAllTables(): Unit
protected def processTableIdentifier(tableIdentifier: Seq[String]): Seq[String] = {
if (!caseSensitive) {
tableIdentifier.map(_.toLowerCase)
} else {
tableIdentifier
}
}
protected def getDbTableName(tableIdent: Seq[String]): String = {
val size = tableIdent.size
if (size <= 2) {
tableIdent.mkString(".")
} else {
tableIdent.slice(size - 2, size).mkString(".")
}
}
protected def getDBTable(tableIdent: Seq[String]) : (Option[String], String) = {
(tableIdent.lift(tableIdent.size - 2), tableIdent.last)
}
}
它的常用实现类为SimpleCatalog类:
protected[sql] lazy val catalog: Catalog = new SimpleCatalog(true)
在这个类中,实现了上面接口中的方法,也包括注册表,从源码中可以看到,实际上将表名以及执行 计划加入HashSet数据结构的缓存当中。
class SimpleCatalog(val caseSensitive: Boolean) extends Catalog {
//放入缓存当中
val tables = new mutable.HashMap[String, LogicalPlan]()
override def registerTable(
tableIdentifier: Seq[String],
plan: LogicalPlan): Unit = {
val tableIdent = processTableIdentifier(tableIdentifier)
//注册表名,实际上将表名与执行计划放入缓存当中
tables += ((getDbTableName(tableIdent), plan))
}
override def unregisterTable(tableIdentifier: Seq[String]): Unit = {
val tableIdent = processTableIdentifier(tableIdentifier)
tables -= getDbTableName(tableIdent)
}
override def unregisterAllTables(): Unit = {
tables.clear()
}
override def tableExists(tableIdentifier: Seq[String]): Boolean = {
val tableIdent = processTableIdentifier(tableIdentifier)
tables.get(getDbTableName(tableIdent)) match {
case Some(_) => true
case None => false
}
}
......
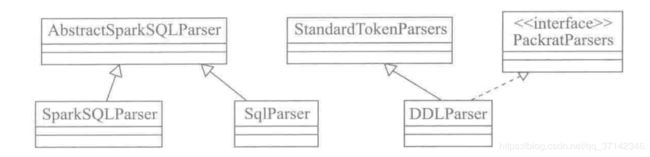
上面提到,它的入口函数是sql函数的调用,此时就会调用Parser对sql语句进行解析。在这个阶段,对SQL解析的类主要包括:
- DDLParser:临时表创建解析器,主要用来解析创建临时表的DDL语句。
- SqlParser:SQL语句解析器,解析select,insert等语句。
- SparkSQLParser:用于代理
SqlParser,对AS,CACHE,SET等关键字进行解析。
它们的类关系继承图如下:
回到SQLContext的sql函数调用处,源码如下:
def sql(sqlText: String): DataFrame = {
if (conf.dialect == "sql") {
DataFrame(this, parseSql(sqlText))
} else {
sys.error(s"Unsupported SQL dialect: ${conf.dialect}")
}
}
在这里又调用了parseSql函数
protected[sql] def parseSql(sql: String): LogicalPlan = {
ddlParser(sql, false).getOrElse(sqlParser(sql))
}
在DDLParser并没有这样的构造器,根据scala的语法我们可以知道,它调用了内部的apply方法,源码如下:
/**
* A parser for foreign DDL commands.
*/
private[sql] class DDLParser(
parseQuery: String => LogicalPlan)
extends AbstractSparkSQLParser with DataTypeParser with Logging {
def apply(input: String, exceptionOnError: Boolean): Option[LogicalPlan] = {
try {
//调用父类的apply方法
Some(apply(input))
} catch {
case ddlException: DDLException => throw ddlException
case _ if !exceptionOnError => None
case x: Throwable => throw x
}
}
......
由上面的继承关系图可以看出,它继承自AbstractSparkSQLParser,它也定义了apply方法,所以接着会调用父类的该方法:
private[sql] abstract class AbstractSparkSQLParser
extends StandardTokenParsers with PackratParsers {
def apply(input: String): LogicalPlan = {
// Initialize the Keywords.
lexical.initialize(reservedWords)
//scala的柯理化,如果input符合start模式则返回Success
phrase(start)(new lexical.Scanner(input)) match {
case Success(plan, _) => plan
case failureOrError => sys.error(failureOrError.toString)
}
}
.......
start模式是一系列复杂的表达式,有兴趣的读者可以查阅相关资料,其中一段源码如下所示:
protected lazy val start: Parser[LogicalPlan] =
( (select | ("(" ~> select <~ ")")) *
( UNION ~ ALL ^^^ { (q1: LogicalPlan, q2: LogicalPlan) => Union(q1, q2) }
| INTERSECT ^^^ { (q1: LogicalPlan, q2: LogicalPlan) => Intersect(q1, q2) }
| EXCEPT ^^^ { (q1: LogicalPlan, q2: LogicalPlan) => Except(q1, q2)}
| UNION ~ DISTINCT.? ^^^ { (q1: LogicalPlan, q2: LogicalPlan) => Distinct(Union(q1, q2)) }
)
| insert
)
DDLParser
该组件主要用来创建临时表,其内部定义了一些KeyWord,它是保存在HashSet缓存中:
// Keyword is a convention with AbstractSparkSQLParser, which will scan all of the `Keyword`
// properties via reflection the class in runtime for constructing the SqlLexical object
protected val CREATE = Keyword("CREATE")
protected val TEMPORARY = Keyword("TEMPORARY")
protected val TABLE = Keyword("TABLE")
protected val IF = Keyword("IF")
protected val NOT = Keyword("NOT")
protected val EXISTS = Keyword("EXISTS")
protected val USING = Keyword("USING")
protected val OPTIONS = Keyword("OPTIONS")
protected val DESCRIBE = Keyword("DESCRIBE")
protected val EXTENDED = Keyword("EXTENDED")
protected val AS = Keyword("AS")
protected val COMMENT = Keyword("COMMENT")
protected val REFRESH = Keyword("REFRESH")
//创建临时表,描述表,刷新表
protected lazy val ddl: Parser[LogicalPlan] = createTable | describeTable | refreshTable
protected def start: Parser[LogicalPlan] = ddl
可以看见,其ddl的模式是createTable、describeTable或者refreshTable。下面简单看看createTable的源码:
protected lazy val createTable: Parser[LogicalPlan] =
// TODO: Support database.table.
//create temporary table using options
(CREATE ~> TEMPORARY.? <~ TABLE) ~ (IF ~> NOT <~ EXISTS).? ~ ident ~
tableCols.? ~ (USING ~> className) ~ (OPTIONS ~> options).? ~ (AS ~> restInput).? ^^ {
case temp ~ allowExisting ~ tableName ~ columns ~ provider ~ opts ~ query =>
if (temp.isDefined && allowExisting.isDefined) {
throw new DDLException(
"a CREATE TEMPORARY TABLE statement does not allow IF NOT EXISTS clause.")
}
.......
SqlParser
该组件主要用来解析SQL语句。
protected val ABS = Keyword("ABS")
protected val ALL = Keyword("ALL")
protected val AND = Keyword("AND")
protected val APPROXIMATE = Keyword("APPROXIMATE")
protected val AS = Keyword("AS")
protected val ASC = Keyword("ASC")
protected val AVG = Keyword("AVG")
protected val BETWEEN = Keyword("BETWEEN")
protected val BY = Keyword("BY")
protected val CASE = Keyword("CASE")
protected val CAST = Keyword("CAST")
protected val COALESCE = Keyword("COALESCE")
protected val COUNT = Keyword("COUNT")
protected val DESC = Keyword("DESC")
protected val DISTINCT = Keyword("DISTINCT")
protected val ELSE = Keyword("ELSE")
protected val END = Keyword("END")
protected val EXCEPT = Keyword("EXCEPT")
protected val FALSE = Keyword("FALSE")
protected val FIRST = Keyword("FIRST")
protected val FROM = Keyword("FROM")
protected val FULL = Keyword("FULL")
protected val GROUP = Keyword("GROUP")
protected val HAVING = Keyword("HAVING")
protected val IF = Keyword("IF")
protected val IN = Keyword("IN")
protected val INNER = Keyword("INNER")
protected val INSERT = Keyword("INSERT")
protected val INTERSECT = Keyword("INTERSECT")
protected val INTO = Keyword("INTO")
protected val IS = Keyword("IS")
protected val JOIN = Keyword("JOIN")
protected val LAST = Keyword("LAST")
protected val LEFT = Keyword("LEFT")
protected val LIKE = Keyword("LIKE")
protected val LIMIT = Keyword("LIMIT")
protected val LOWER = Keyword("LOWER")
protected val MAX = Keyword("MAX")
protected val MIN = Keyword("MIN")
protected val NOT = Keyword("NOT")
protected val NULL = Keyword("NULL")
protected val ON = Keyword("ON")
protected val OR = Keyword("OR")
protected val ORDER = Keyword("ORDER")
protected val SORT = Keyword("SORT")
protected val OUTER = Keyword("OUTER")
protected val OVERWRITE = Keyword("OVERWRITE")
protected val REGEXP = Keyword("REGEXP")
protected val RIGHT = Keyword("RIGHT")
protected val RLIKE = Keyword("RLIKE")
protected val SELECT = Keyword("SELECT")
protected val SEMI = Keyword("SEMI")
protected val SQRT = Keyword("SQRT")
protected val SUBSTR = Keyword("SUBSTR")
.......
在SqlParser的start的中,定义着一系列的解析规则,其语法晦涩难懂。下面简单看一段:
protected lazy val start: Parser[LogicalPlan] =
( (select | ("(" ~> select <~ ")")) *
// ~顺序组合解析,比如A~B必须保证A在B的左边
//将UNION ALL替换为Union函数,^^^符号用于将匹配的值置换为原值
( UNION ~ ALL ^^^ { (q1: LogicalPlan, q2: LogicalPlan) => Union(q1, q2) }
//INTERSECT 替换为Intersect函数
| INTERSECT ^^^ { (q1: LogicalPlan, q2: LogicalPlan) => Intersect(q1, q2) }
| EXCEPT ^^^ { (q1: LogicalPlan, q2: LogicalPlan) => Except(q1, q2)}
| UNION ~ DISTINCT.? ^^^ { (q1: LogicalPlan, q2: LogicalPlan) => Distinct(Union(q1, q2)) }
)
| insert
)
protected lazy val insert: Parser[LogicalPlan] =
//~>匹配后只保留右边,比如A~>B,只保留B
INSERT ~> (OVERWRITE ^^^ true | INTO ^^^ false) ~ (TABLE ~> relation) ~ select ^^ {
case o ~ r ~ s => InsertIntoTable(r, Map.empty[String, Option[String]], s, o)
}
SparkSQLParser
SparkSQLParser用于来代理SqlParser对AS、CACHE等关键字的处理。
protected val AS = Keyword("AS")
protected val CACHE = Keyword("CACHE")
protected val CLEAR = Keyword("CLEAR")
protected val IN = Keyword("IN")
protected val LAZY = Keyword("LAZY")
protected val SET = Keyword("SET")
protected val SHOW = Keyword("SHOW")
protected val TABLE = Keyword("TABLE")
protected val TABLES = Keyword("TABLES")
protected val UNCACHE = Keyword("UNCACHE")
override protected lazy val start: Parser[LogicalPlan] = cache | uncache | set | show | others
从源码中可以看到,其start的匹配模式有cache,set,show等模式,其表达式和上面提到的类似。
在经过SqlParser处理之后 ,将SQL进行解析,完成一系列操作之后,就会使用Analyzer与数据字典Catalog进行绑定,然后对执行计划进行分析,那么,这部分内容,在后面的文章中会详细介绍,欢迎持续关注。
欢迎加入大数据学习交流群:731423890