《Densely Self-guided Wavelet Network for Image Denoising》论文阅读
一、论文
《Densely Self-guided Wavelet Network for Image Denoising》
摘要
在过去的几年中,深度卷积神经网络在图像去噪方面取得了令人瞩目的成功。 在本文中,我们提出了一种用于真实世界图像降噪的密集自导小波网络(DSWN)。 DSWN的基本结构是自上而下的自指导体系结构,它能够有效地合并多尺度信息并提取良好的局部特征以恢复干净的图像。 而且,这种结构需要较少的参数,并且使我们可以获得比Unet结构更好的有效性。 为了避免信息丢失并获得更好的接收场大小,我们将小波变换嵌入到DSWN中。 另外,我们将密集残差学习应用于卷积块,以增强所提出网络的特征提取能力。 在DSWN的全分辨率级别上,我们采用双分支结构来生成最终输出。 它们中的一个分支倾向于关注黑暗区域,而另一分支则在明亮区域表现更好。 这种双分支策略能够处理不同曝光下的噪声。 拟议的网络已通过BSD68,Kodak24和SIDD +基准测试验证。 其他实验结果表明,所提出的网络优于大多数最新的图像去噪解决方案。
介绍
图像去噪是低级视觉的基本任务,也是许多其他视觉任务的重要预处理步骤。 传统方法[1]通常通过域变换[2],非局部算法,马尔可夫随机场(MRF等解决图像去噪问题。但是,这些方法需要手动设置参数并参考复杂的优化方法 测试阶段的问题。
随着深度学习技术的飞速发展,已经开发了许多高级方法[5-7],并取得了令人瞩目的成功。 通过涉及残差学习策略并将批处理归一化(BN)和ReLU激活函数添加到深度架构中,DnCNN [8]被提出用于处理高斯盲消噪并实现更高的峰值信噪比(PSNR)比传统的最先进方法[9]。
为了追求高度精确的降噪结果,已提出了一些后续工作来消除加性高斯白噪声(AWGN)[10,11]。 为了涉及多尺度信息,一些最先进的端到端方法[12-14]应用Unet [15]作为其基本结构,并在每个级别中添加一些密集的残差块。 尽管这些方法在基准数据集上具有竞争性性能,但它们繁重的计算和内存占用量阻碍了它们的应用。
为了在降噪性能和计算资源的消耗之间寻求更好的折衷,通过自顶向下的指导策略提出了自导神经网络(SGN)[16]用于图像降噪任务。 在任何卷积运算之前,SGN会使用PixelUnShuffle [17]生成多分辨率输入。 以低分辨率提取的大规模上下文信息逐渐传播到高分辨率子网络中,以指导这些规模的特征提取过程。 使用这种结构,与Unet相比,SGN能够以更少的运行时间和GPU内存实现更好的降噪性能。
受SGN的启发,我们提出了一种密集的自导波小波网络(DSWN)(如图2所示),该网络能够提高SGN的性能(图1),并要求使用密集自导波小波网络进行图像去噪Wei Wei1,2 琼琼1赵智芝3 1SenseTime研究2哈尔滨工业大学3香港城市大学[email protected] | [email protected] | [email protected]的运行时要比基于Unet结构的最新的密集网络要少[13]。 在DSWN中,我们在每个级别中嵌入了紧密连接的残差块(DCR)[13](如图3所示)。 为了获得更好的性能,我们采用了更多具有完整分辨率级别跳过连接的DCR模块。 我们将离散小波变换(DWT)和逆离散小波变换(IDWT)转换为DSWN,以取代SGN中的混洗操作。 其动机是DWT / IDWT不仅可以避免信息丢失,而且可以在效率和恢复性能之间取得更好的折衷,从而扩大了接收范围。 另外,小波已经被用于传统方法中的去噪任务[2]。利用小波变换来合并多尺度信息,使网络具有时频分析功能。 在全分辨率级别,我们设计了一个双分支结构,包括一个残差学习分支和一个端到端学习分支。 这样的结构能够帮助我们的网络以不同的曝光率处理去噪任务。 我们的主要贡献概述如下:
我们设计了一个密集的自导小波网络,该网络优于传统方法,并且比大多数具有密集块的最新去噪网络更有效。
用小波变换代替PixelShuffle进行比例变换,实现更高的PSNR并保留更多细节。
我们提出了全分辨率级别的双分支结构。 残余学习分支倾向于在明亮区域中保留更多细节,并且端到端学习分支能够补充黑暗区域信息并进一步提高去噪性能。
相关工作
在本节中,我们简要介绍一些与我们的研究相关的作品。 首先,我们回顾一些基于深度学习的降噪网络。 然后,我们讨论合并多尺度信息的一些先前的工作。
用于图像去噪的深度神经网络
近年来,研究表明,深度学习技术通过提取更合适的图像特征,在图像去噪方面优于传统方法[6]。毛等 等 设计了一个具有对称跳过连接的卷积编码器-解码器网络来执行图像去噪[18]。 通过引入一个内存块通过自适应学习过程显式地挖掘持久性内存,MemNet [11]能够学习不同接受域下当前状态的多层次表示。 通过将残差学习策略和批处理归一化以及ReLU激活函数添加到深度架构中,DnCNN [8]被提出来处理高斯混合去噪。 使用可调噪声级图作为输入,FFDNet [19]能够处理各种噪声级并消除空间变化的噪声。考虑到泊松-高斯模型和机内处理流水线,CBDNet [7]通过嵌入噪声估计网络进一步提高了盲降噪能力。为了克服配对训练数据的不足,Chen等。 文献[20]通过Generative Adversarial Network(GAN)和Noise2Noise [5]模拟了噪声样本,提出了一种无需任何干净数据的恢复学习策略。 最后,张等人。 [21]提出了一种残差密集网络(RDN),它使用残差学习和密集连接作为其基本结构,最大程度地提高了特征重用性,并实现了高斯噪声图像去噪性能的显着提高。
融合多尺度信息
为了提取用于图像去噪和单图像超分辨率(SISR)任务的多尺度信息,提出了PixelShuffle和小波变换来代替合并和内插以避免信息丢失。通过自指导策略和PixelShuffle,SGN [16]大大提高了内存和运行时效率。 Bae等。 提出了一种用于图像去噪和SISR的小波残差网络(WavResNet)[22],并发现小波子带对学习卷积神经网络(CNN)有好处。 类似地,提出了一种深度小波超分辨率(DWSR)方法[23]来恢复子带上丢失的细节。 WavResNet和DWSR都只考虑单级小波分解。 通过将小波变换嵌入到CNN架构中,MWCNN [24]考虑了多级小波变换,以获得更好的接收场大小,并避免了下采样信息损失。 通过将DWT和IDWT嵌入CNN,MWCNN拥有更多的能力来对空间上下文和子带间相关性进行建模。 在本文中,我们提出的网络采用与MWCNN相同的方法来合并多尺度信息,其架构与MWCNN完全不同。
二、网络结构
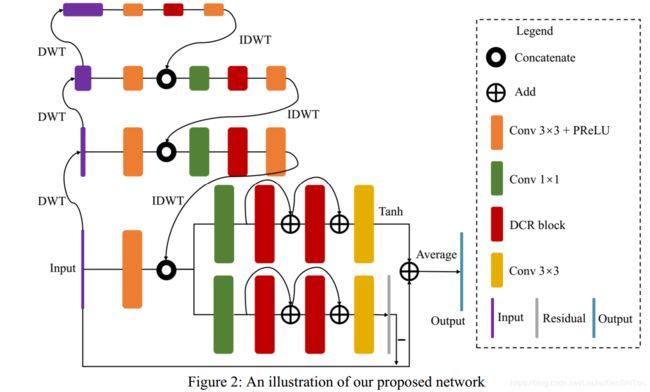

我们提出的降噪网络如图2所示。自上而下的自导体系结构用于更好地利用图像多尺度信息。 以低分辨率提取的信息逐渐传播到高分辨率子网中,以指导特征提取过程。 代替PixelShuffle和PixelUnShuffle,DWT和IDWT用于生成多尺度输入。 在进行任何卷积运算之前,DSWN使用小波变换将输入图像变换为三个较小的图像在全分辨率层,我们采用由残留学习分支和端到端学习分支组成的双分支结构。 在本文的其余部分,我们仅将这两个分支称为残差分支和end2end分支。 对于我们的网络,我们观察到残留分支集中在明亮区域,而end2end分支集中在黑暗区域。 因此,我们以全分辨率级别使用这两个分支来进一步提高性能,尤其是当网络需要同时处理具有不同ISO的噪点图像时。 此外,我们发现批量归一化对降噪性能有害,因此在此网络中不使用任何归一化层。 对于每个级别,我们将密集连接的残差(DCR)[13]添加一个或两个块,如图3所示。
DSWN的最高层以最小的空间分辨率工作,以提取大规模信息。 顶部子网包含两个Conv + PReLU层(图2中的橙色框)和DCR块(图2中的红色框)。 DCR块同时应用密集的连通性和残差学习,以准确消除输入图像的噪声并解决消失梯度问题。在中间两个级别,使用1×1卷积核层合并从不同分辨率提取的信息。 中间子网的网络结构类似于顶部子网的结构。 至于全分辨率级别,我们将合并所有比例尺的信息后,通过跳接连接添加更多的DCR块,以增强DSWN的特征提取能力。 对于残差分支,DSWN在输入图像和最终估计之间具有全局残差连接。 我们在end2end分支的末尾添加了Tanh激活函数。 最终输出是残差分支和end2end分支的简单平均结果。 通过增加梯度损失,我们的网络能够在不降低PSNR的情况下更好地保留细节。为了保证比较实验的公平性,在本文的实验部分,我们的网络仅使用L1损失进行训练。
三、代码(还未公布)
可以参考SGN代码:https://github.com/CurryYuan/Self-Guided-Network-for-Fast-Image-Denoising/tree/master/SGN