机器学习第六篇:集成学习AdaBoost
1.理论知识:
集成学习根据学习器之间是否存在依赖关系划分为两类:
- 学习器之间存在强依赖关系、必须串行生成的序列化方法——Boosting
- 学习器之间不存在强依赖关系、可同时生成的并行化方法——Bagging和随机森林
这里主要介绍Boosting的主要代表Adaboost。
Adaboost采取加权多数表决的方法,加大分类误差率小的弱分类器的权值,使其在表决中起较大的作用。
算法如下:
- 初始化训练数据的权值分布:
![]()
- 根据权值分布D寻找使得误差率
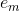 达到最小的
达到最小的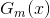 的分布
的分布 - 计算的系数
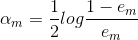
- 根据求得的alpha更新权值分布
![]()
![]()
其中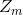 :
:
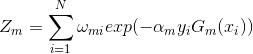
- 构建基本分类器的线性组合
![]()
最终得到分类器:
![]()
2.源代码实现:
首先获取数据,这里随便写一组数据做为我们的训练集:
def loadSimpData():
datMat = matrix([[ 1. , 2.1],
[ 2. , 1.1],
[ 1.3, 1. ],
[ 1. , 1. ],
[ 2. , 1. ]])
classLabels = [1.0, 1.0, -1.0, -1.0, 1.0]
return datMat,classLabels获取数据之后,根据算法我们首先初始化我们的D并且构建第一个G_1(x),进行验证的时候,这里的D可以先手动输入一下:
def stumpClassify(dataMatrix,dimen,threshVal,threshIneq):#just classify the data
#这个函数的主要作用就是构建G(x),我们只能用具体的矩阵来表达我们的G(x),告诉机器怎么做,并不可能达到书面的那种书写表达。比如当x<1.3是为-1,大于等于1.3为1那么对dataMatrix第一列的矩阵就为[-1,-1,1,1,1]这就是我们的G(x)
retArray = ones((shape(dataMatrix)[0],1))
if threshIneq == 'lt':
retArray[dataMatrix[:,dimen] <= threshVal] = -1.0
else:
retArray[dataMatrix[:,dimen] > threshVal] = -1.0
return retArray
def buildStump(dataArr,classLabels,D):
dataMatrix = mat(dataArr); labelMat = mat(classLabels).T
m,n = shape(dataMatrix)
numSteps = 10.0; #步长
bestStump = {}; #用于存放分类器的基本信息
bestClasEst = mat(zeros((m,1)))
minError = inf #init error sum, to +infinity
for i in range(n):#loop over all dimensions
rangeMin = dataMatrix[:,i].min(); rangeMax = dataMatrix[:,i].max();
stepSize = (rangeMax-rangeMin)/numSteps
for j in range(-1,int(numSteps)+1):#循环所有情况,旨在找出最小的e_m,找到最小的e_m,就对应找到了G(x)
for inequal in ['lt', 'gt']: #go over less than and greater than
threshVal = (rangeMin + float(j) * stepSize)
predictedVals = stumpClassify(dataMatrix,i,threshVal,inequal)#计算当前的阈值情况下的两种G(x),lt和gt
errArr = mat(ones((m,1)))
errArr[predictedVals == labelMat] = 0#相等的部分为0,不相等的不变
weightedError = D.T*errArr #计算当前G(x)下的e_m
#print "split: dim %d, thresh %.2f, thresh ineqal: %s, the weighted error is %.3f" % (i, threshVal, inequal, weightedError)
if weightedError < minError:#找到最小e_m,并保存相关信息
minError = weightedError
bestClasEst = predictedVals.copy()
bestStump['dim'] = i
bestStump['thresh'] = threshVal
bestStump['ineq'] = inequal
#因为我们最终需要的只是G(x)和alpha(后面计算),G(x)是用dim、thresh、ineq这三个变量来表达形成的,带入stumpClassify就能获得我们的G(x),间接的把G(x)存放了起来
return bestStump,minError,bestClasEst第一个分类器构建完成,之后我们就要根据产生的e_m来计算alpha和权值的更新:
def adaBoostTrainDS(dataArr,classLabels,numIt=40):
weakClassArr = []
m = shape(dataArr)[0]
D = mat(ones((m,1))/m) #init D to all equal
aggClassEst = mat(zeros((m,1)))
for i in range(numIt):#迭代次数
bestStump,error,classEst = buildStump(dataArr,classLabels,D)#classest就是我们的G(x)
#print "D:",D.T
alpha = float(0.5*log((1.0-error)/max(error,1e-16)))#根据算法公式,计算alpha
bestStump['alpha'] = alpha #alpha就是我们需要的另外一个重要的信息
weakClassArr.append(bestStump) #store Stump Params in Array
#print "classEst: ",classEst.T
expon = multiply(-1*alpha*mat(classLabels).T,classEst)
D = multiply(D,exp(expon))
D = D/D.sum()#D.sum()就是我们的z,这里很巧妙的都放在了一起计算
aggClassEst += alpha*classEst#这就是f(x) =\sum (alpha * G(x))
#print "aggClassEst: ",aggClassEst.T
aggErrors = multiply(sign(aggClassEst) != mat(classLabels).T,ones((m,1)))
#不相等返回true,当所有相等时,全部返回false,与ones相乘必然为0
errorRate = aggErrors.sum()/m
#print "total error: ",errorRate
if errorRate == 0.0: break#当全部为0时集成完成,就可以退出循环了
return weakClassArr,aggClassEst当我们构建完我们的分类器,来进行测试:
def adaClassify(datToClass,classifierArr):
dataMatrix = mat(datToClass)#测试数据
m = shape(dataMatrix)[0]
aggClassEst = mat(zeros((m,1)))
for i in range(len(classifierArr)):
classEst = stumpClassify(dataMatrix,classifierArr[i]['dim'],\
classifierArr[i]['thresh'],\
classifierArr[i]['ineq'])
#根据前面说到的,dim、thresh、ineq返回的矩阵就是我们的G(x)
aggClassEst += classifierArr[i]['alpha']*classEst
#aggClassEst = f(x) = \sum (alpha*G(x))
return sign(aggClassEst)这就是整个Adaboost的过程,有问题的小伙伴欢迎在下面留言