音视频系列3:编解码技术
1. 基础知识
FOURCC是一个4个字节32位的标识符,通常用来标示视频数据流的格式,播放软件可以通过查询FOURCC代码并寻找对于解码器来播放特定视频流,取值通常由各个格式标准自行定义,如DIV3、DIVX等。
DCT类似于只使用实数且长度为两倍的离散傅里叶变换,常在信号和图像处理或对数据进行有损压缩时候使用,其 f n f_n fn常用形式为 f m = Σ k = 0 n − 1 x k cos [ π / n ( k + 0.5 ) ] f_m=\Sigma ^{n-1}_{k=0}x_k\cos[\pi/n(k+0.5)] fm=Σk=0n−1xkcos[π/n(k+0.5)],DCT变换本身是可逆的,它最大的特点是“能量集中”,由于大多数声音或图像信号的能量集中在变换后的低频部分,以此对高频部分进行舍弃,可以达到压损率大而损失较少,保留信息更多的目的。
量化指将信号的连续取值近似为多个离散值,在MPEG-2编码中,量化过程就是以某个量化步长除以DCT系数,量化步长越小就保留了更多的信息,但数据量就越大,因为不同的DCT系数对人的感知重要性并不相同,所以对DCT变换中的不同系数需要采取不同的量化精度。
Z字扫描(Zigzag Scan),由于量化过程。如果数据可以被期待在某一个区域中的相似特征出现频率较高而非沿着直线行进,则采用Z字扫描可以有效提高压缩效率,因为聚集在一起的特征只需要保存其差异即可,而非保存所有特征的所有信息。
游程编码(RLE,Run Length Encoding)来源于一种简单的思想,用变长的编码来取代连续出现的重复信息,譬如“AAABBBBCCDEEEEE”,即可被压缩成“A3B4C2D1E5”,应用于音视频领域时,它需要输入的是经过变换,连续重复数据较多的情况。
熵编码(Entropy Encoding)与游程编码均是无损压缩方法,主要类型的熵编码方式对每一个符号创建并分配唯一的前缀码,并替换成可变长度前缀无关的输出,霍夫曼编码即是熵编码的一种,算术编码也属于熵编码,为得到好的压缩效果,需要尽可能精确地知道每个输入单元出现的概率,而对概率的估计越准确,压缩效率就越高,此时既可以在压缩前进行全文统计,亦可以动态计算,如按照已经编码的概率计算,还可以计算未编码部分的概率等。
运动估计,主要用于描述编码关系上相邻的两帧差别,即前一帧每个块如何移动到后面一帧,设法搜索到它们之间的相对偏移,即所谓运动矢量,利用运动矢量,将参考帧的宏块移动到对应位置,即可生成被压缩图像的预测,因为在自然情况下,通常运动存在一定规律,故预测图像和被压缩图像之间差分值较低,可以帮助去除帧间冗余度。
码率控制,视频的码率越高,往往质量越高,但为了减少传输和存储的成本,人们希望压缩得到的视频越小越好,故而设置合适的码率,取得质量和大小的平衡就非常重要,好的编码器可以让编出的视频尽可能符合预先设置的码率。不同的编码器会采取不同策略来控制所编视频的码率,不仅控制其中某一视频片段的码率,也包括整体输出的文件大小。
RDO即率失真优化,Rate Distortion Optimization的缩写,其目标是使用某些策略近似地找到不超过某个码率情况下失真达到最小的模式,后面的SAD、SATD等即是近似的计算方法。
振铃效应是一种由于高频信息的丢失,在重构的图像边缘异于原始图像的情形,HEVC引入了SAO技术避免直接增加高频分量精度,从像素域入手,对重构曲线中出现的波谷波峰像素添加正负值补偿,减小了高频分量的失真,改善了振铃效应。在标准中,SAO以CTB为单位,选择了合适的分类器将重建像素划分类别,对不同类别像素使用不同的补偿值(包括边界补偿和边带补偿),并进行参数融合以提高质量。
CRA(Clean Random Access)帧,这是一个I帧,但它可以参考CRA之前的帧,不需要刷新解码器。
RASL(Random Access Skipped Leading)帧,RASL帧是CRA帧的前导,可以参考关联的CRA帧之前的帧,因此IDR帧只能有RADL的前导,CRA则可有RADL和RASL作为前导。
RADL(Random Access Decodable Leading)帧,它是IRAP帧的前导,只能参考关联的IRAP帧和对应的RADL帧。
BLA(Broken Link Access)帧,当访问CRA帧时,RASL需要参考CRA编码顺序之前的帧,但实际并无法获得,则被定义为BLA帧,此时舍弃其前面的所有帧。
编码器的发展过程中,通常每一代编码器的设计目标是比之前的编码器压缩效率提升一倍。广播电视级SD(Standard Definition,即标清,448像素×336像素或512像素×288像素等分辨率)质量的视频,以往常使用MPEG2编码方式,其码率约等于3.75Mbit/s,高清视频则需要15Mbit/s以上。而作为领先两代的H.264,则可以在3~6Mbit/s的码率范围得到很好的1080p视频压缩质量,再进一步,VP9和HEVC在同等质量下码率还可以再节约30%~50%。
2. 视频编码
视频的压缩方法主要包括去除空间上、时间上、统计上以及感知上的冗余信息等几个主要努力方向。视频由一系列连续的图像组成,在某一幅图像之中就存有大量的冗余,例如某一个像素点与周围的许多像素点就存在相似或连续的关系,在连续的一系列图像中也存在相关性。绝大多数现代视频编码器结合了空间域和时间域上的压缩,考虑到编解码器所需要的计算复杂度、对延迟的要求(有的编码器需要分析较长的一段内容才可以进行编码,有的编码器可能达到几乎没有滞后)、对质量是否存在特殊要求(如移动镜头时的图像细节)等做出折中的设计。
对于空间域上的压缩,其常用的技术和图片压缩技术十分相似,后续将详细介绍。而视频压缩独有的内容很大程度上集中在时间域上的压缩,也称帧间压缩,其主要思想是用一个或多个周围的帧来协助压缩当前帧,如果帧上没有移动的区域,就意味着冗余部分天然存在,数据只需编码或存储一次,即可在解码时重建多个帧。
现代的视频编码器里存在**GOP(Group of Pictures)**的概念,代表了一组连续的图像帧,通常而言,GOP中的第1帧编码为I帧,此外还有P帧和B帧的概念。I帧表示关键帧(Key Frame),其解码时不需要引用来自其他帧的信息即可完成(与图片编解码较为相像);P帧表示前向参考帧(Predictive Frame),体现了当前帧与前面参考帧的区别,需要依赖前面的I帧或P帧才可以解码;B帧通常又叫作双向参考帧(Bi-directional Interpolated Prediction Frame),记录了当前帧与前后帧的不同,需要依赖其前后两个方向的I帧或P帧才可以完成解码。
可想而知,解码时依赖其他帧的信息越多,说明当前帧的冗余越少,压缩率越高,一个简单的估算可以认为I帧、P帧、B帧的大小比例可达到9∶3∶1。
下图描述了一个GOP的例子,展示了典型的帧序列和它们之间的参考关系,这里将引申出来DTS和PTS的概念,即Decode Timestamp(解码时间戳)和Presentation Timestamp(显示时间戳)。因为B帧需要参考后面的P帧才能正确解码,因此在解码的顺序上,后面的P帧将被先行解码并缓存,但在显示时,该B帧仍然应该先被显示出来。假设帧的原始序列为I、B1、B2、P1、B3、B4、P2……,这与显示的顺序完全一致,每一帧的PTS与实际视频录制的相对时间一致,而解码的顺序将是I、P1、B1、B2、P2、B3、B4……,DTS也将予以体现,以告知解码器每一帧应该被解码的时间。

在H.264和HEVC中,还定义了一种IDR帧,其含义是,从IDR帧开始,所有后面的帧都不会参考该IDR帧之前的帧,而普通的I帧可以被其前后两个方向的其他帧所引用。
在介绍了GOP的概念之后,让我们以MPEG-2为例看一下现代视频编码器涉及的主要技术。历史上流行过许多种视频编解码算法,如MPEG-1Part 2(即用于VCD视频压缩的算法标准)、MPEG-2Part 2(即H.262,用于DVD的压缩算法标准)、RV(见前文编码格式介绍)、VC1(亦见前文编码格式介绍)、H.263(在视频会议领域曾广泛应用)、MPEG-4Part 2(即DivX、Xvid所用的格式)等。当前流行的编码器格式数量已大为减少,只有H.264/AVC、VP8/9、H.265/HEVC等寥寥几种,多家公司组成联盟,或在标准组织的框架下推动编解码技术的提升,期待格式可以得到最广泛的支持和运用已成为业界常态。其中,MPEG-2编码器由于已经具备了现代编码器的诸多特征,比较适合作为示例。
具体来说,MPEG-2编码器使用了DCT(Discrete Cosine Transform,离散余弦变换)[注释]、运动补偿和霍夫曼编码,对数据从大到小定义了Sequence、GOP、Picture、Slice、宏块(MacroBlock)、Block等多个层次。GOP的概念上面已予介绍,在MPEG-2中宏块定义了4∶2∶0、4∶2∶2、4∶4∶4不同结构,Block则代表了8×8个采样值。
在帧内编码时,MPEG-2只应用DCT变换和量化步骤,而帧间编码时,首先将原图和预存的预测图进行比较,计算出运动矢量,和参考帧一并生成原图的预测图。然后由原图和预测图的差值得到差分图像,进行DCT变换和量化步骤。最后经历无损编码阶段得到最终的结果。
3. 音频编码
音频编解码虽然格式众多,但与视频相比,缺乏脉络可循的技术换代,大致而论,MP3和AAC就可以代表不同的时期,虽然考虑到YouTube和其他少数几家公司,Vorbis/OGG格式也占据了不可忽视的份额。但是另一方面,杜比公司并未简单地围绕压缩效率上做文章,其在Dolby Digital、Dolby Digital Plus、Dolby Digital Atoms这一系列上另辟蹊径,不论在电影、电视,还是在线视频上,均有广泛的支持者。
如同经过编解码后视频质量会下降一样,音频编解码可能引入一定的失真和噪声,好的编码器可以尽量避免这一点。人耳的听觉频率范围大致在20~20000Hz,在该频率范围之外的声音人耳是无法听到的,可以视为冗余信号,此外人耳存在频率掩蔽的效应,当某个频率的声音能量小于某个值,将不会被人听到。当存在能量较大的声音的时候,周围频率的阈值会提高。类似地,在较强信号发生的时间段,较弱信号亦将被掩蔽,从而人耳无法听到。
音频信号的压缩,通常是波形编码、参数编码等多种技术混合的编码方式,其中波形编码是根据采样的数据,建立一定的波形以符合原始波形,保留较多的细节和过渡特征。参数编码则是根据不同信号源,提取特征参数(例如共振峰、线性预测系数等)并编码。实践中许多编码器混合使用了多种波形和参数编码的技术,并将信号分解为不同频率范围,而根据不同的分布特性采取不同压缩策略,以在提升压缩率的同时保留好的声音质量。
与视频编码相比,由于音频所占的码率比例较低,计算复杂度也不高,业界对发展更好的音频编码格式动力并不充分,或许这一领域的机会更多在于实时通信和虚拟现实相关的音频应用,且与传输技术结合相互影响。
4. 图像压缩
对于一张图像,可以进行有损或无损的压缩,无损压缩可以完全地保留图片里的信息量,解码观看图片时和原图可做到完全一致,方法有游程编码、熵编码或自适应字典算法等。
对于大量的图像尤其是自然界的图像而言,压缩带来的微小损失可以接受(甚至眼睛完全无法感知),采用有损压缩的算法,可以大幅度减小图片的大小,节约传输的带宽和存储空间。常见的有损方法包括色彩空间转换、色度抽样、分形压缩、DCT或小波变换等,除高效地实现图像压缩外,好的压缩算法和格式还需要兼顾可扩展性(如质量、分辨率渐进)等目标。
BMP是由微软开发的,常见的无损图片格式之一,内部使用的就是RGB格式,对24Bit或32Bit的RGB存储而言,数据区直接排列着每一个像素对应的RGB或RGBA的值(顺序实际为BGR和BGRA),但如同前文提到的,无损图片文件体积很大,一个800像素×600像素的24Bit图片需要占据约1.4MB的空间,并不是很适合在存储或传播的场合使用。PNG是另一种无损压缩的图片格式,由RFC2083标准描述,其中最广为人知的是它对Alpha通道的透明/半透明特性的支持,同样,因为体积较大,也仅适合在非常需要半透明效果的场合。
JPG/JPEG是值得重点关注的有损压缩的图片格式,它已流行多年,主要思路是舍弃人眼难以感知的颜色(高频)信息。JPEG格式里面支持的是YUV类型的图像,可以支持顺序式或渐进式(推荐使用,在下载时用户可以先看到模糊但完整的图片)编码,以及阶梯式编码。在图像压缩时,JPEG文件首先将图像的模式转换为YUV,随后进行DCT变换,将图像分离出高频和低频信息,对变换后的频率系数再进行量化,其中选取合适的质量因子可以决定编码完成的图像质量,最后按照Z字形对矩阵中的值进行游程编码。使用JPEG格式额外的有利之处在于,许多浏览器或硬件设备对JPEG文件的渲染早有针对性的优化,对用户在客户端的体验大有好处。
SVG是一种适合应用于网页的矢量图形标准,不同的用户观看图片时使用的浏览器分辨率可能大不相同,且网页有可能被放大缩小以关注更多的细节,单一分辨率的图片在预定分辨率下观感良好,但放大后就显得粗糙。虽然可以准备一些高清晰度的原始素材,并利用ImageMagick之类软件帮助实时调整图片到想要的大小,但这种临时的转换请求既有些浪费,也颇为降低响应时间,尤其对于Logo和图标来讲,应用SVG或许是更该考虑的选择。
针对有极致压缩优化需求的用户,还可以考虑WEBP和BPG等格式,WEBP衍生自视频编码格式VP8,由Google在BSD授权下开源,相比JPEG而言,同样质量的图片WEBP可节省25%~40%的大小。在Chrome、Opera浏览器和Android系统上,都内置了它的支持,但其他浏览器不能直接支持则是一大弊端,意味着服务端需要针对同一图像存储不同的格式。当然,当前支持WEBP的浏览器市场份额在50%以上,采用这一格式可以让很多用户得到较好的网页和图片加载时间,还是比较值得。
BPG格式是FFMpeg发起者Fabrice创建的一种图片格式,主要参考了H.265/HEVC的编码方法中的部分工具,它在某些情况下具有最好的压缩比,并有一个效率不错的基于JavaScript的解码器。在下列的一份比较测试中可见,在质量相同的情况下,压缩小图片时,BPG格式颇占优势,而针对较大的图片,WEBP不论压缩比还是(软件)解码效率都较高。还应考虑注意的文件格式包括HEIF,也脱胎于HEVC编码标准,苹果公司已在WWDC宣布其旗下设备全面支持HEIF。
近年来,深度学习技术也被加入图像识别技术中,如Google就发布了名为Guetzli的项目,在兼容JPEG格式的情况下,可以显著地降低图片大小(可见上文测试),缺点是图像压缩时间实在太长,但这不失为一种好的思路,在通过人为推导算法不容易得到提升的领域,应用较新的技术,可能会带来额外的提升。
5. 视频压缩
5.1 H264
H.264/AVC作为当前市场上最为流行的编解码标准,它的设计目标,不仅是在压缩效率上胜出市场上的其他编码器(例如它的实际压缩效率为MPEG2编码的2~3倍,也超出RV10至少50%),而且提供足够的灵活性,包括适应较高或较低的带宽、可应用于文件存储、在线视频服务、视频会议等。它实际定义了1~6.2一系列的Profile等级,每个Profile都有其不同的分辨率、码率、帧率等范围。
H.264当前主要支持YUV420和8Bit精度(较新修订的标准增加了对10Bit的支持),其输入单位是帧或场(Field),当针对隔行扫描的视频帧时,需要引入场的概念。H.264支持固定帧编码、固定场编码、图像自适应帧/场编码(PAFF)和宏块自适应帧/场编码(MBAFF)。H.264中每一帧可以被编成一个或多个Slice,每个Slice又包含多个宏块。每个宏块包含16×16的亮度像素、8×8的Cb和8×8的Cr分量。Slice分为以下类型:I Slice、P Slice、B Slice、SP Slice、SI Slice。其中I、P、B的含义较易理解,I Slice中只包含I宏块,P Slice中可包括P和I宏块,B Slice中可包含B和I宏块,而SP和SI Slice属于扩展功能,用于不同码率流之间的切换。

H.264与下一代的H.265十分类似,均采用混合式编码结构,对于空间冗余,视频帧通过变换和量化即可进行压缩,相对其他编码格式,H.264新引入帧内预测,以宏块为基本单位,将同一帧的邻近像素作为参考,产生对当前宏块的预测值,再对预测误差进行编码,提高了压缩率。为了一致化编解码,编码器使用的预测数据是经过反变换和量化后的重建图像。对于时间冗余,编码器利用连续帧进行运动估计和运动补偿。下面分别介绍H.264的主要技术,包括预测、变换、量化、环路滤波和熵编码。

(1)帧内/间预测
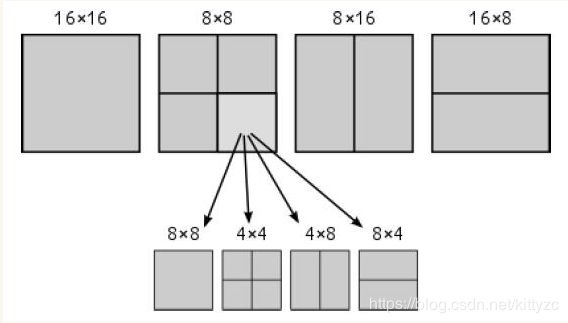
首先是帧内和帧间预测,编码器在此引入了大量特性。对于帧内预测,H.264先根据相邻的宏块进行预测,包括1种直接预测和8种方向预测。针对帧间预测,H.264在邻近帧中寻找和该块最为相似的块,常用的方法包括全匹配法、二维对数法、三步搜索法、邻域搜索法、菱形搜索法等。对每一个16×16的宏块,运动补偿可以采用不同的大小和形状,共7种模式(即16×16、16×8、8×16、8×8、8×4、4×8、4×4,通过RDO[注释]方法选择得到)。对每一种分割都尝试在搜索范围内寻找估计块,计算代价,选择最小代价的分割进行预测编码。计算匹配的方法包括SAD(绝对误差法)、SATD(经哈德曼变换的残差绝对值和)、SSD(平方差和)等。
进行运动估计时,可先用整像素精度进行搜索,找到最佳匹配块后,再在该位置周围进行1/2像素乃至1/4、1/8像素精度的搜索以寻找最佳匹配点,即所谓的树状分级搜索。通过树状搜索找到最佳匹配点后,根据最佳匹配块和当前块的位置,计算得到运动矢量。根据周围的块对MV进行预测也可以得到预测MV(即MVp),最终被编码的对象是运动矢量的插值MVD=MV-MVp。
此外,在预测中,编码器还支持运动矢量超出图像边界,支持多帧预测,可选择5个不同的参考帧,取消了参考图像和现实图像顺序的相关性,允许进行加权预测,对跳过区域的运动采用推测方法进行以及对B帧采用直接运动补偿等多项特性。
(2) 变换
在变换和反变换环节,H.264采用基于4×4像素块的整数DCT变换,与浮点运算相比,整数DCT变换会带来一些额外误差,但也避免了取舍位数造成的误差,总体影响不大,而换得减少运算复杂度的好处。标准同时支持分级块变换,譬如低频色度信号可用8×8像素块,低频亮度信号可用16×16像素块等。不同于以往编码器中变换与反变换间存在的误差,H.264实现了完全匹配。
(3)量化
在变换之后需要对数据进行量化,量化的意图是通过多对一的映射以降低码率,包括均匀和非均匀量化、自适应量化。在H.264中对亮度(Luma)可选52种不同的量化步长,QP取值为0~51,对色度(Chroma)可取0~39。当QP取0时意味着最精细,取最大值意味着最粗糙。H.264采用标量量化技术,将每个图像点映射成一个较小的数值,量化公式为Zij=round(Yij/Qstep),其中Zij是量化后的系数,round()代表取整,Yij是变换后得到的系数,也即量化的输入,Qstep是量化步长。在量化后,数据经过Z字扫描或双扫描(仅在较小量化级的块内使用)存储。
(4)环路滤波
由于包括H.264在内的许多视频编码器都基于宏块,存在变换和运动补偿导致的块效应(即视觉上不连续的沿块边界,见图3-14),如果不进行处理,这些不连续性将随着预测过程扩散,环路滤波可以有效消除块效应,是编码过程中极为重要的一环,这项技术又被称作De-blocking Filter(去块效应滤波)或Reconstruction Filter(重构滤波)。由DCT变换时,高频系数被量化为0的形式,导致边缘在跨界处出现锯齿,称为梯形噪声,另一种因量化导致平缓的亮度块DC系数发生跳跃,造成平坦区域的色调改变,称为格形噪声。环路滤波针对亮度宏块和色度宏块进行,按先亮度后色度,先垂直后水平进行,过程如下:
1.估算边界强度,即根据边界位置以及宏块信息估计两边的像素差距。
2.区分真假边界,即边界是块效应导致还是视频图像原有边界。
3.滤波运算,根据边界类型不同采用不同的算法,改变2~6个不同的像素。
(5)熵编码
H.264支持两种不同的基于上下文的熵编码方式,即在所有Profile上适用的CAVLC(又称作UVLC)和在中高档Profile上可以选择的CABAC。其中CAVLC除量化系数外,使用统一的编码表,未考虑编码符号间的相关性,与使用编解码器共享特征(譬如运动矢量),建立随视频帧统计特性调整的概率模型的CABAC方法比较,压缩性能要略差一些,但算法复杂程度较低。
在H.264的编码实践中,不论是入门使用、学习研究,还是商业项目,都可以考虑从最广泛应用的开源编码器x264开始。x264提供了UI工具和命令行工具,后者较为常用,它提供了多种参数供人使用,其中包含一些预先设置的参数集合,所有参数亦可以手动设置,覆盖预设参数集合中的一个或多个参数。由于x264已被集成到FFMpeg中,通过FFMpeg也可以灵活调用,但二者命令参数并不相同。
x264的预设参数从快到慢包含ultrafast、superfast、veryfast、faster、fast、medium、slow、slower、veryslow、placebo 10个集合,而–tune参数可以针对film、animation、grain、stillimage、psnr、ssim、fastdecode、zerolatency等不同视频源或场景进行特定优化。
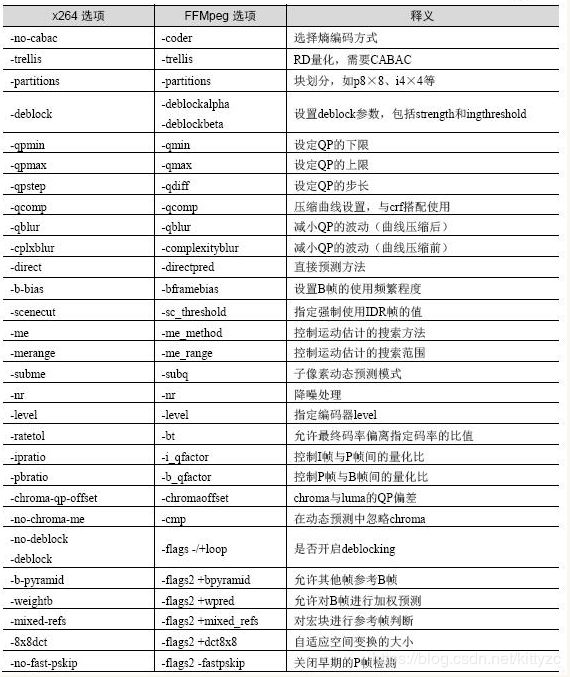
x264和FFMpeg部分调用参数的比较和释义如表所示

5.2 H265
HEVC(High Efficiency Video Coding,高效率视频编码)又称作H.265,是更新一代以期望压缩效率高于H.264一倍为目标设计的编解码标准。HEVC于2012年2月完成Committee Draft,2013年1月完成Final Draft,基本达到设计目标,对在线视频应用来说,在低码率情况下,针对H.264尤其存在明显的质量优势。下图展示了400kbit/s、1080p条件下H.264和HEVC编码质量的对比:

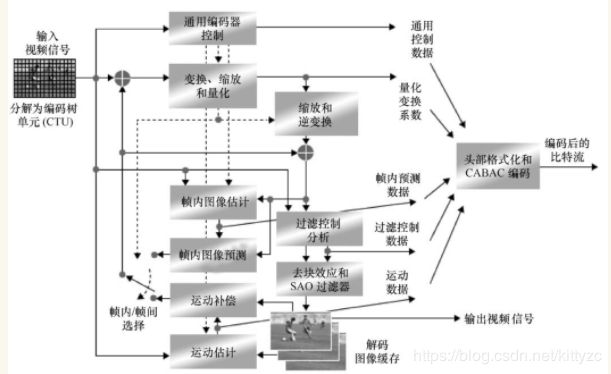
HEVC采用与H.264相似的混合编码架构,包含帧内和帧间预测、变换和量化、去区块滤波和熵编码等,但在绝大多数环节上进行了大幅度的更新,加入了许多新的解码工具,可以支持4K甚至8K分辨率,下面介绍它与H.264的主要区别。
(1)块划分
在编码架构中,与之前以宏块为基础不同,HEVC引入了CU(Coding Unit,编码单元)、PU(Predict Unit,预测单元)和TU(Transform Unit,转换单元)的概念。一幅图像仍然可以被划分成多个Slice,每个Slice可以进一步划分为多个Slice Segment(SS),其中包括一个独立SS和多个参考SS,每个SS则还可包含至少一个CTU(Coding Tree Unit,编码树单)。
此外,HEVC还将图像划分为Tile,但与Slice不同,Tile的形状只允许为长方形,每个Slice的CTU都属于某一个Tile,或每个Tile的CTU都属于某一个Slice,二者必居其一。Slice和Tile的划分可以参考下图。

CTU的大小由编码器指定,可以较原先的宏块为大,每个CTU包含亮度CTB(Coding Tree Block)和对应的色度CTB,尺寸可达64×64,而编码器支持使用类四叉树的结构将CTB划分成更小的块(见图3-20)。在CU结构下,可以再划分PU和PB,类似地CU也可再划分为更小的TB。

(2)预测
对于帧内预测,HEVC提高到了35种帧内预测模式,对帧间预测引入了Merge、Skip、AMVP等模式。HEVC仍然支持1/4亮度像素精度和1/8色度像素精度的MV,对1/2像素和1/4像素使用八阶或七阶滤波器而对1/8像素位置定义了一种四阶滤波器,对所有分像素位置使用独立的插值,不再支持隐式的权值预测而必须显式地发送缩放或位移后的预测值。
预测编码通过预测模型消除像素间的相关,对实际图像与预测值之间的差值再行编码和传送,如输入为像素x(n),则首先利用已编码像素的重建值得到当前像素的预测值p(n),对二者的差值d(n)=x(n)-p(n)进行量化和熵编码,同时对量化后的残差与预测值p(n)得到当前像素的重建值x′(n)以待后用。
在HEVC的编码中,帧内预测模支持5种大小的PU,包括4×4、8×8、16×16、32×32、64×64,共计支持包括33个角度的方向预测、DC预测和Planar预测等35种模式。当选择进行帧内预测时,每个PB都具备自己的帧内预测模式,具体预测过程则以TU为单位,PU可以按照四叉树形式划分TU,且同一PU内所有TU共享同一模式,首先获取相邻参考像素,当像素不存在或不可用时使用邻近像素进行填补,其次对不同的TU选择不同数量的模式进行滤波,随后利用不同的预测模式得到计算像素值。
帧间预测编码与帧内预测相似,区别在于其利用的参考像素来源于已编码的前后多帧的数据。其中运动矢量即欲编码的像素与参考像素之间的位移,不仅将用于运动补偿,也将传递到解码器以便重建图像。
在HEVC中,使用全搜索及TZSearch算法[注释]进行运动估计,针对MV的预测使用Merge模式和AMVP模式两种新的模式。Merge模式同时利用时间域和空间域上相邻PU的运动参数,当前PU的MV由直接计算候选MV并选取失真率最小者得到,不存在运动矢量残差MVD,而AMVP模式(Advanced Motion Vector Predictor,即运动矢量预测)同样使用候选MV列表,区别在于在对选出的最优预测MV进行差分编码,获取MVD。
(3)其他编码技术
在变换量化时,编码标准支持基于四叉树结构的自适应变换技术(Residual Quad-treeTransform,RQT),为最优TU模式提供了很高的灵活性,在能量集中和保留细节方面给予平衡,并支持将变换和量化过程相互结合,滤波模块则引入了SAO(Sample Adaptive Offset,采样自适应补偿)技术改善振铃效应。
此外,值得一提的新技术还包括ACS和IBDI。ACS技术(Adaptive Coefficient Scanning,自适应系数扫描)包括对角、水平和垂直扫描,它将一个TU划分成4×4块,按照相同顺序进行扫描,对帧内预测区域的4×4和8×8大小的TU,当预测接近水平方向时采用垂直扫描,反之接近垂直方向时选用水平扫描,其他方向或帧间预测时使用对角扫描,如此针对不同情况,采取不同扫描方法。
IBDI(Internal Bit Depth Increase,内部比特深度增加)在编码器的输入端将像素深度增加,并在解码端将像素深度恢复至原有比特数,以提高编码精度,并降低帧内和帧间预测误差。
最后,HEVC只使用CABAC进行熵编码,由于引入并行处理架构,速度较以前得到很大改善。
(4)封装
在HEVC中仍然支持NAL层,分为VCL和Non-VCL NAL两类,对应一个每帧图像的数据和与多帧图像相关的控制信息。Non-VCL NAL包含VPS(Video Parameter Set,视频参数集)、SPS和PPS。

在H.264中可以通过IDR帧实现随机访问,HEVC里定义了新的CRA帧、RASL帧、RADL帧、BLA帧等概念(参见第一节)。
5.3 VP9
虽然VP8由于Google的推广背书受到了广泛的关注,但当时它的一些特性缺失(如缺乏B帧的支持、权重预测、没有8×8的变换、自适应量化、环路滤波的自适应强度以及主观质量优化等)让其相对于H.264处于明显的弱势,再加上对Google关于专利权声明的质疑,并无多少公司真正地使用VP8编码视频。然而数年过去,拜HEVC推广缓慢和专利费阴影所赐,经过Google多项重大提升的新编码器VP9,以及更多的人正在试图跟踪和评估的AV1,被许多公司当作值得认真考虑的选项。
VP9的开发肇始于2011年,在2013年被集成到Chrome浏览器中,相比VP8有着巨大的提升,它支持Profile 0~3四种编码配置,其中Profile 0支持4:2:0,Profile 1支持硬件播放环境及4∶2∶2和4∶4∶4采样,Profile 2和Profile 3支持10bit采样。当前除YouTube外,Netflix也在Android等支持的设备上大量应用了VP9格式。
VP9将图像分成64×64大小的Super Block,与HEVC类似,可以使用四叉树编码结构水平或垂直细分Super Block的结构直至4×4大小。

VP9的帧内预测遵循TB分区,编码器支持10种不同的预测模式,包括直流、水平、垂直、TM以及6个定向的预测模式,在PB范围内,扫描每一个4×4的TB进行预测和重构。帧间预测使用1/8像素进行运动补偿,支持NEW、NEAR、NEAREST、ZERO四种预测模式,允许建立包含两个矢量的候选参考MV列表并以此进行选择预测,并支持在部分帧中使用复合预测(即双向预测的变体)。针对每个块可以选择3种不同的子像素插值滤波器,分别适应于高对比场景,保留其边缘尖锐部分以及相邻帧某处非自然不一致的尖锐情况。此外,在VP9中当前帧和参考帧允许不一致,可使用Scale_factor进行缩放。
VP9格式支持3种变换类型,包括DCT、ADST(非对称离散正弦变换)和哈夫曼变换。对于帧内编码,ADST被用于和DCT结合形成二维混合变换类型,哈夫曼变换的场景则是在低量化值时进行无损编码。编码器提供了8bit、10bit、12bit三个量化表,根据不同变换类型使用不同的扫描类型。
对编码环节,VP9采用8位算数引擎编码,若给定一个n元码表即可建立一棵二进制树,通过遍历这棵树并利用上下文模型进行编码。编码器引入了Segment的概念,Super Block拥有相同属性时拥有同样的ID,每帧图像限制为8个不同的Segment ID,其属性包括量化因子、环路滤波强度、预测时的参考帧、TB大小和是否为Skip模式等。
VP9使用与HEVC相似的架构,并采用一些独特的技术使得二者在压缩效率上各有千秋,利用libvpx与libeve(前者系开源VP9编码器、后者系商业VP9编码器)编码均比x265在高分辨率情况下有一定优势,而远远超过H.264的编码效率。
5.4 AV1
AOM即开放媒体联盟(Alliance for Open Media),由包括Amazon、Cisco、Google、Intel、Microsoft、Mozilla、Netflix在内的多家公司组建,当前又加入了Adobe、Broadcom、Hulu、NVIDIA、Polycom等多家公司,目标是提出较HEVC更先进的编码器并完全免费、避开专利限制。AOM当前的主要工作即是开发AV1编码器,已于2018年初正式发布,发布方式是直接以接近商业应用水平的代码与文档一起,置于BSD协议之下。
AV1同样使用Super Block,按四叉树结构组织,可被分割到4×4的块,帧内和帧间的变换均可最小使用4×4块,但最大支持的块扩展到128×128的大小,并允许10种分割方式(下图对比了VP9和AV1的块划分)。当进行帧内预测时,编码器支持56个角度的通用预测,参考选定方向的像素,应用1/256像素精度的2-tap线性滤波器,在每个可用角度查表,支持Paeth预测、Smooth预测和Palette预测。

进行帧间预测时,AV1从相邻的一系列MV中指定索引,为列表中的MV按远近和与当前块的重叠量进行排序,对所选的MV索引进行编码。与VP9允许指定3个参考帧不同,AV1缓存8个参考帧,针对每个块允许使用7个参考帧。Overlapped Block MotionCompensation(即重叠块运动补偿)可能是编码器使用的较复杂的技术之一,它利用邻居的预测值改进当前块的预测,以在接近边界处得到更好的预测,以及得到更为平滑的预测及残差。

针对全局或扭曲的运动,编码器使用特征匹配和RANSAC(随机抽样一致性算法)计算每个参考帧的全局运动参数,支持多种运动模型和自由度。Guided Restoration技术让编码器在编码前降采样,在更新前再升回,并进行环路恢复,可以带来较高的增益。此外AV1还允许对水平和垂直方向上的插值过滤器进行独立选择。
AV1在变换、量化和编码环节,支持DCT、ADST、反向ADST和Identity四种变换方法,增加了针对4×8、8×4、8×16、16×8、16×32、32×16等矩形块的转换;支持非线性量化和Delta QP Signaling技术;在滤波时,和VP9不同,AV1针对每个颜色空间的滤波器Level都可以不一样;最后,其熵编码环节用15bit表示概率,允许对每个符号进行概率更新。
AV1在编码流程中加入了不同的Filter工具和后处理过程,主要包括CDEF(约束方向增强滤波器)、环路恢复滤波器、超分辨率处理和胶粒合成。
6. 音频压缩
相比以往大为流行的MP3,AAC于编码流程上引入了多项新的技术,在压缩率、音质、解码效率、音轨与采样率支持等方向上全面超出。
首先,AAC编码器可通过滤波器组得到频域的频谱系数,并通过TNS(Temporal Noise Shaping,时域噪声修正)技术修正量化噪声的分布,对语音信号剧烈变化时音质提升巨大。与视频编码器的流程类似,AAC的编码器同样借助了预测、量化、以及熵编码等技术。
在MPEG-4中,AAC加入了LTP(Long Term Prediction)技术和PNS(Perceptual Noise Subsitution,即忽略类似噪声信号的量化)技术,对低码率下的音质和编解码效率作了进一步提升。此外,MPEG-4中最主要的变化,就是支持了AAC+(也即HE-AAC)。
HE-AAC混合了AAC与SBR、PS技术(加入PS则被称作HE-AACv2)。SBR是Spectral Band Replication的缩写,因为音乐的能量主要集中在低频部分,高频段虽然重要但幅度很小,SBR针对频谱切分成不同频段,对低频保留主要成分,对高频部分放大编码以保证音质,整体上提高了效率。PS指Parametric Stereo,对两个声道的声音去掉相关性,仅保留其中一个声道的全部信息,对另一声道仅描述声道之间的差值。
AAC的编码过程,大致而言是将音频数据通过PQF(多相积分滤波)技术分离为不同子带,对每个子带传输独立的增益,由增益整形后的子带数据根据不同信号以MDCT(改进的离散余弦变换),使用转换Kaiser-Bessel(KBD)类窗和正弦窗进行转换,由非均匀量化器实现量化。
与AV1的胶粒合成思路类似,AAC中的PNS(Perceptual Noise Subsititution,知觉噪声替换)技术能以参数编码模拟噪声,即在识别音频中的噪声后将之从编码流程中去除,而采用某些参数告知解码器,由解码器使用随机方式重新生成类似噪声。
在解码时基本为编码的逆过程,首先进行无噪声解码(即哈夫曼解码),其次进行反量化,然后判断联合立体声的模式(AAC具备两种联合立体声的表达模式,M/S和Intensity模式)进行解码,根据是否使用PNS的判别结果进行计算修正,再应用TNS进行瞬态噪声整形,最后将频域数据填入IMDCT滤波器转换为时域,并进行加窗和叠加。如果使用SBR编码,此时还需进行频段复制,得到左右声道的PCM码流。
针对AAC的解码应用,常见的编解码器有按GPL协议开源的FAAC和FAAD2,已被集成到FFMpeg、GStreamer和VLC Player中。同时,除用于编码立体声音轨外,AAC也可以转换如AC3或DTS等多声道的音频。AAC没有使用费用,仅编解码器的提供商需要收取不多的授权费用,对在线视频服务而言极为友好。