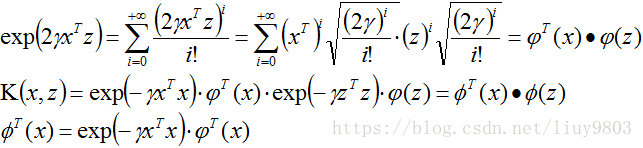机器学习之SVM软间隔模型、核函数
SVM的软间隔(soft margin)模型
当线性数据集中存在少量的异常点,导致数据集不是线性可分,或者即使恰好找到某个核函数使得训练集在特征空间中线性可分,也很难断定这个结果是不是由于过拟合所造成的。解决方法之一是允许SVM在一些样本上分错,因此引入软间隔的概念来解决此类问题。
硬间隔:要求所有样本满足约束,函数距离大于等于1;
软间隔:允许某些样本不满足约束y(i)(wTx(i)+b)≥1,对于训练集中的每个样本都引入一个松弛变量ξi≥0,使得函数距离加上松弛变量后的值大于等于1。松弛变量越大,表示样本点离超平面越近,如果松弛变量大于1,那么表示允许该样本点被分错,目标函数转换为:

其中C>0是超参惩罚参数,C越大表示对误分类的惩罚越大,即允许分错的样本越少。C值的给定需要调参。
同线性可分SVM,构造软间隔最大化的约束问题对应的Lagrange函数如下:
![]()
优化目标函数与其对偶问题为:
![]() ;
; ![]()


再对上式求α的极大值,即得对偶问题:
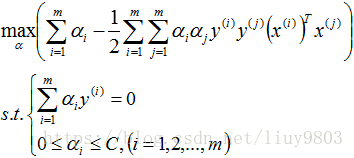
软间隔SVM的KKT条件:
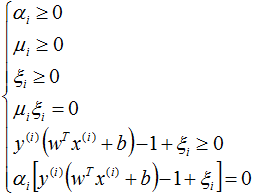
根据KKT条件中的对偶互补条件 α(y(wTx+b)-1+ξ)=0 可知αi>0的样本为支持向量,软间隔模型的支持向量的位置根据αj、ξj不同的取值,有可能落在间隔边界上、或者在间隔边界与分离超平面之间、或者在超平面误分一侧:
(1)αj
(2)αj=C,0<ξj<1,则分类正确,xj在间隔边界与分离超平面之间;
(3)αj=C,ξj=1,则xj在分离超平面上;
(4)αj=C,ξj>1,则xj位于分离超平面误分一侧。

SVM软间隔模型的算法流程
设m个线性可分的样本数据{(x(1),y(1)),(x(2),y(2)),...,(x(m),y(m))},y→{-1,+1}
选择一个惩罚系数C>0,构造约束优化问题:

使用SMO算法求出最优解α*;
找出所有的支持向量集合S,支持向量对应的αj>0:
![]()
更新参数w*,b*的值,求b*时等号两边同时乘以支持向量的类标签:

构建最终的分类器:
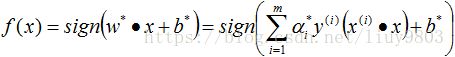
SVM软间隔模型总结
可以解决线性数据中携带异常点的分类模型构建问题;
通过引入惩罚项系数及松弛变量,可以增加模型的泛化能力,健壮性好;
如果给定的惩罚项系数C越小,在模型构建的时候就允许存在越多分类错误的样本,也就是表示此时模型的准确率比较低;如果给定的C越大,表示在模型构建的时候,允许分类错误的样本越少,也就表示此时模型的准确率比较高。
非线性可分SVM
当数据不是线性可分时,使用核技巧(kernel trick)对数据集进行非线性变换,将非线性问题变为线性问题,从而可以使用线性可分SVM模型或者软间隔线性可分SVM模型求解原来的非线性问题。
核函数
设χ是输入空间,H为特征空间(高维/无穷维),如果存在一个从χ到H的映射
ϕ(x): χ→H
使得对所有x,z∈χ,函数K(x,z)满足条件
K(x,z)=ϕ(x)·ϕ(z)
则称K(x,z)为核函数,ϕ(x)为映射函数。
核函数在解决线性不可分问题的时候,采取的方式是:只定义核函数K(x,z),而不显式地定义映射函数ϕ,通常直接计算K(x,z)比较容易,而通过ϕ(x)和ϕ(z)的内积计算K(x,z)并不容易。
在线性SVM的对偶问题中,目标函数和最终分类器只涉及输入实例与实例之间的内积,因此可以用核函数来代替直接求内积的方法,使用低维空间上的计算避免在高维特征空间中向量内积的很大的计算量。
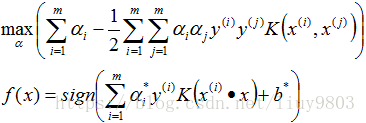
常用核函数的种类有
线性核函数:
![]()
多项式核函数:其中γ、c、d属于超参,需要调参定义
![]()
高斯核函数(径向基核函数RBF):其中σ、γ>0为超参

拉普拉斯核函数:
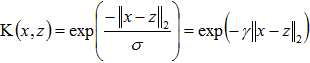
Sigmoid核函数:
![]()
核函数总结
可以自定义核函数,条件是必须为正定核函数,即K(x,z)对应的Gram矩阵K=[K(xi,xj)]m*m是半正定矩阵(统计学习方法P121);

核函数的价值在于:虽然也是将特征从低维映射到高维,但事先在低维上进行计算,而将实质上的分类效果表现在了高维上,避免了直接在高维空间中的复杂计算
通过核函数,可以将非线性可分的数据转换为线性可分的数据。
高斯核公式的证明
令z=x,那么进行多为变换后,应该是同一个向量,从而可以得到以下公式:
![]()
对第三项进行Taylor展开,得到: