weka和matlab完成完整分类实验
本文简单介绍数据集介绍、weka的使用、weka与LIBSVM、matlab与LIBSVM以及分类的若干细节问题。
1. 数据集介绍
打开网址UCI数据集,如下图。

从右下角可以看到Iris这个数据集,这是使用最多的数据集,目前下载量超过了82万。
打开之后跳转到这个数据集的详细信息,如下图。

下面的表格具有如下信息
- 数据是多变量的
- 数据用实数表示
- 这是个分类问题
- 一共有150条数据
- 每条数据有四种属性
- 所有数据都没有缺失
- 这是个关于生活的分类问题,是鸢尾花的分类
从表格下面可以得到更多关于这个数据集的信息,比如数据集的来源、数据集的介绍、数据集中数据的含义以及使用该数据集的论文。
从数据的含义可以看出每条数据都有四种属性,分别是花萼的长度、花萼的宽度、花瓣的长度和花瓣的宽度,单位是厘米。
这是个三分类问题,表示Setosa、VersiColour和Virginica这三种鸢尾花,每种花有50条数据,一共150条数据。
点击图2中的Data Folder,如下图。

下载其中的iris.data和iris.names。
打开其中的iris.data,如下图。

2. 数据处理
下载安装weka,首先检测电脑是否安装java运行时环境jre,在windows操作系统下打开cmd,输入java -version,如果已安装选择不带jre的weka,否则选择带jre的weka。
打开后首页如下图。

点击Explorer,再点击open file,打开iris.data,显示如下图的错误。

这需要修改.data格式为.arff格式,在iris.data最前面添加如下内容。
@RELATION iris
@ATTRIBUTE sepallength REAL
@ATTRIBUTE sepalwidth REAL
@ATTRIBUTE petallength REAL
@ATTRIBUTE petalwidth REAL
@ATTRIBUTE class {Iris-setosa,Iris-versicolor,Iris-virginica}
@DATA并且将.data的后缀名强制改成.arff。
从weka中打开iris.arff,如下图。

关于weka每一个按钮的作用,每一个区域的含义参考使用weka进行数据挖掘这篇帖子,介绍的非常详细。
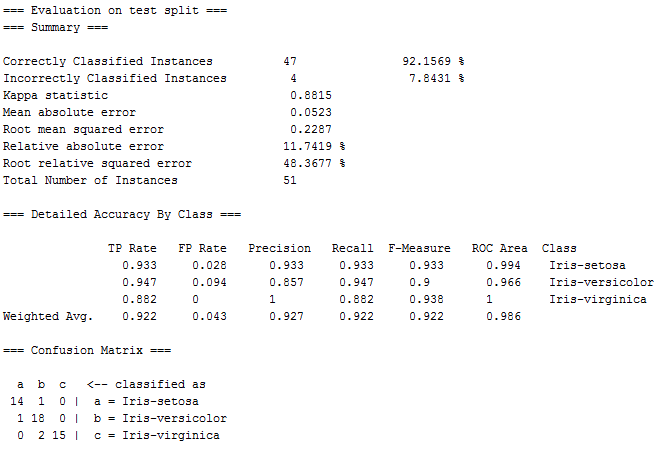
点击最上方的Classify按钮,选择Logistic(逻辑回归)分类方法,在Test options中选择Percentage split,66%。这样weka自动将大约2/3的数据作为训练集,大约1/3的数据作为测试集,采用逻辑回归作为分类方法,结果如下图。
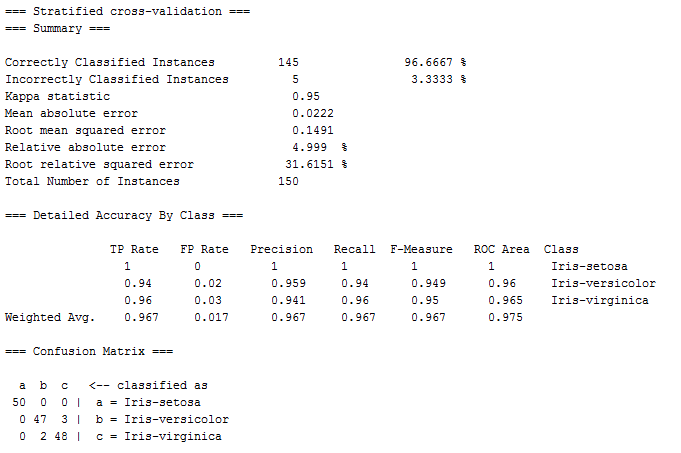
另外也可以选择Cross-validation,Folds设置为10,这是10-fold的交叉验证,首先随机将所有数据随机分成10份,将其中9份作为训练集,另外1份作为测试集,按照逻辑回归进行10次分类实验,最终保证每个数据都能作为测试集并且仅有一次,将10次分类结果综合起来得到最终的分类结果,如下图,显示了分类结果中最重要的部分。

- Correctly Classified Instances表示分类正确率
- Incorrectly Classified Instances表示分类错误率
- TP Rate是True Positive Rate的缩写,表示本来是正样本,结果也被分类成正样本的比例
- FP Rate是False Positive Rate的缩写,表示本来是负样本,结果却被分类成了正样本的比例
- Precision表示查准率,公式为Precision = TPTP+FP ,含义是被分类为正样本中真正的正样本的比例
- Recall表示查全率,公式为Recall = TPTP+FN ,FN Rate是False Negative Rate的缩写,表示本来是正样本,结果却被分类成负样本的比例,所以Recall的含义是真正的正样本占整个数据集(分类正确的和错误的)中正样本的比例
- F-Measure的公式是 2∗P∗RP+R ,是很常用的判断分类效果好坏的指标
- 最下方有比较直观的分类结果矩阵,斜对角上的数据表示分类正确的数量,其余表示分类错误的数量
3. weka+LIBSVM
在weka中,除了Logistic分类方法外,还可以选择Libsvm这种分类方法,需要到台湾大学林智仁教授的网站下载这个工具包。
否则会出现Problem evaluating classifier:libsvm classes not in CLASSPATH的错误,可以参考解决方法,实验结果如下图。
4. matlab+LIBSVM
通常情况下需要调整Libsvm中-c和-g这两个参数来获得更好的分类效果,在weka中只能手动调整这两个参数,这样效率很低,所以更好的方法是在matlab中采用Libsvm的方法,参考配置流程。
配置完成后,首先另外创建一个.txt文档,包括之前iris.data的内容,但不包括iris.arff中前面的声明部分,另外将.txt中所有英文的分类替换成数字,这样matlab才能处理,Iris-setosa替换成1,Iris-versicolor替换成2,Iris-virginica替换成3。
用matlab来完成Iris的分类并且寻找最佳的-c和-g两个参数,博客参考Libsvm中c&g的调整,程序参考Github,实验结果如下。
best cost = 3.0314
best gamma = 0.0625
best accuracy = 98.6667%
cost in weka = 1.0
gamma in weka = 0.0从实验结果看出,通过调整-c和-g两个参数将weka中默认参数的分类准确率提高了2%。
5. 总结
本文介绍了数据集的来源和处理,并且用weka自带的两种方法进行了分类实验,其中libsvm的方法在matlab上进行了改进,提高了2%的正确率。