Spark SQL:RDD、DataFrame和DataSet的区别,相互转化、 SparkSql中的UDF、 UDAF函数
一、RDD、DataFrame、DataSet
1. RDD
RDD,全称为 Resilient Distributed Datasets,即分布式数据集,是 Spark 中最基 本的数据抽象,它代表一个不可变、 可分区、里面的元素可以并行计算的集合。在 Spark 中,对数据的所有操作不外乎创建 RDD、转化已有 RDD 以及调用 RDD 操作
进行求值。每个 RDD 都被分为多个分区,这些分区运行在集群中的不同的节点上。 RDD 可以包含 Python、Java、Scala 中任意类型的对象,甚至可以包含用户自定义 的对象。RDD 具有数据流模型的特点:自动容错、位置感知性调度和可伸缩性。RDD 允许用户在执行多个查询时显式地将工作集缓存在内存中,后续的查询能够重用工 作集,这极大地提升查询速度。
RDD 支持两种操作:transformation 操作和 action 操作。RDD 的 transformation 操作是返回一个新的 RDD 的操作,比如 map 和 filter(),而 action 操作则是向驱动 器程序返回结果或者把结果写入外部系统的操作,比如 count()和 first()。
2. DataFrame
DataFrame 是一个分布式数据容器。相比于 RDD,DataFrame 更像传统数据库 中的二维表格,除了数据之外,还记录数据的结构信息,即 schema。同时,与 Hive 类似,DataFrame 也支持嵌套数据类型(struct,array 和 map)。从 API 易用性的角 度上看,DataFrame API 提供的是一套高层的关系操作,比函数式的 RDD API 要更 加友好,门槛更低。由于与 R 和 Pandas 中的 DataFrame 类似,Spark DataFrame 很 好地继承了传统单机数据分析的开和体验。
RDD和DataFrame:
以Person实体为例探究
当我们以两种不同的方式读取到Person数据,Person会作为RDD的类型参数,但是Spark无法知晓内部结构,而dataFrame可以清楚加载到Person实体的内部结果和具体的数据:
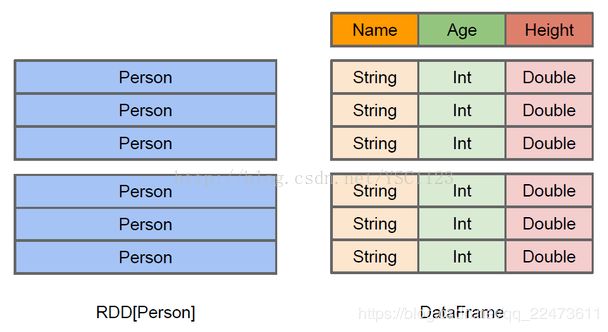
RDD虽然以Person为类型参数,但是Spark框架并不了解Person类的内部结构;右侧的DataFrame却提供了详细的结构信息,使得Spark Sql可以清楚地知道数据集中有哪些列,每列的名称和类型分别是什么。
DataFrame中多了数据集的结构信息即Schema,所以我们在获取到DataFrame结果集之后可以通过printSchema方法来查看当前数据文件的结构信息。所以我们可以这样理解,RDD是分布式的Java对象集合(这也就是为什么RDD会有Broadcast广播变量的方法),DataFrame是分布式的Row对象的集合。
DataFrame 处理提供了比 RDD 更为丰富的 算子以外,更重要的是提升了执行效率、减少数据读取以及执行计划的优化,比如 filter 下推、裁剪等。
2.DataSet和DataFrame的对比
DataSet可以理解成DataFrame的一种特例,DataFrame = DataSet[Row],主要区别是DataSet每一个record存储的是一个强类型值而不是一个Row。
所以可以通过 as 方 法将 DataFrame 转换为 DataSet。Row 是一个类型,跟 Car、Person 这些类型一样, 所有的表结构信息都用 Row 来表示。
DataFrame和DataSet可以相互转化,
df.as[ElementType]这样可以把DataFrame转化为DataSet,
ds.toDF()这样可以把DataSet转化为DataFrame。
Dataset介绍
DataSet 是 DataFrame API 的一个拓展,是 Spark 最新的数据抽象。DataSet 具有 用户友好的 API 风格,既具有类型安全检查也具有 DataFrame 的查询优化特性。 DataSet 支持编解码器,当需要访问非堆上的数据时可以避免反序列化整个对象,提 高了效率。
样例类被用来在 DataSet 中定义数据的结构信息,样例类中每个属性的名称直 接映射到 DataSet 中的字段名称。
DataSet 是强类型的。比如可以有 DataSet[Car],DataSet[Person]
DataFrame 只知道字段,但是不知道字段的类型,所以在执行这些操作的时候 是没有办法在编译的时候检查是否类型失败的,比如你可以对一个 String 类型进行 加减法操作,在执行的时候才会报错,而 DataSet 不仅仅知道字段,而且知道字段 类型,所以有更为严格的错误检查。就更 JSON 对象和类对象之间的类比。
Dataset是从Spark 1.6开始引入的一个新的抽象,当时还是处于alpha版本;然而在Spark 2.0,它已经变成了稳定版了。下面是DataSet的官方定义:
A Dataset is a strongly typed collection of domain-specific objects that can be transformed
in parallel using functional or relational operations. Each Dataset also has an untyped view
called a DataFrame, which is a Dataset of Row.
Dataset是特定域对象中的强类型集合,它可以使用函数或者相关操作并行地进行转换等操作。每个Dataset都有一个称为DataFrame的非类型化的视图,这个视图是行的数据集。上面的定义看起来和RDD的定义类似,RDD的定义如下:
RDD represents an immutable,partitioned collection of elements that can be operated on in parallel
RDD也是可以并行化的操作,DataSet和RDD主要的区别是:DataSet是特定域的对象集合;然而RDD是任何对象的集合。DataSet的API总是强类型的;而且可以利用这些模式进行优化,然而RDD却不行。
Dataset的定义中还提到了DataFrame,DataFrame是特殊的Dataset,它在编译时不会对模式进行检测。在未来版本的Spark,Dataset将会替代RDD成为我们开发编程使用的API(注意,RDD并不是会被取消,而是会作为底层的API提供给用户使用)。
✎.RDD:
不支持SparkSql操作。RDD一般和spark mlib同时使用
✎.DataFrame:
1. 与RDD和Dataset不同,DataFrame每一行的类型固定为Row,只有通过解析才能获取各个字段的值,无法直接获取每一列值
testDF.foreach{
line =>
val col1=line.getAs[String]("col1")
val col2=line.getAs[String]("col2")
}2. DataFrame和DataSet均支持SparkSql的操作,比如select,groupby之类的,还能注册临时表、进行sql语句操作
dataDF.createOrReplaceTempView("tmp")
spark.sql("select ROW,DATE from tmp where DATE is not null order by DATE").show(100,false)3. DataFrame和DataSet支持一些方便的保存方式,比如保存成csv,可以带上表头,这样每一列的字段名一目了然:
//保存
val saveoptions = Map("header" -> "true", "delimiter" -> "\t", "path" -> "hdfs://172.xx.xx.xx:9000/test")
datawDF.write.format("com.databricks.spark.csv").mode(SaveMode.Overwrite).options(saveoptions).save()
//读取
val options = Map("header" -> "true", "delimiter" -> "\t", "path" -> "hdfs://172.xx.xx.xx:9000/test")
val datarDF= spark.read.options(options).format("com.databricks.spark.csv").load() ✎.DataSet与DataFrame
1. DataFrame也可以叫做DataSet[Row],每一行的类型都是Row,不解析我们就无法知晓其中有哪些字段,每个字段又是什么类型。我们只能通过getAs[类型]或者row(i)的方式来获取特定的字段内容
2. 而在Dataset中,每一行的类型是不一定的,在自定义了case class之后就可以很自由的获取每一行的信息
case class Coltest(col1:String,col2:Int) extends Serializable //定义字段名和类型
/**
rdd
("a", 1)
("b", 1)
("a", 1)
* */
val test: Dataset[Coltest]=rdd.map{line=>
Coltest(line._1,line._2)
}.toDS
test.map{
line=>
println(line.col1)
println(line.col2)
}到此为止,三者的区别就讲完了,在数据处理过程中,小编很少用到DataSet,处理文本文件使用第一种读取方式比较多,第二种读取方式一般用来读取parquet。
3. RDD、DataFrame、Dataset相互转化:
RDD、DataFrame、Dataset三者有许多共性,有各自适用的场景常常需要在三者之间转换
DataFrame/Dataset转RDD:
val rdd1=testDF.rdd
val rdd2=testDS.rdd
RDD转DataFrame:
import spark.implicits._
val testDF: DataFrame = rdd.map {line=>
(line._1,line._2)
}.toDF("col1","col2")
一般用元组把一行的数据写在一起,然后在toDF中指定字段名
RDD转Dataset:
import spark.implicits._
case class Person(col1:String,col2:Int)extends Serializable //定义字段名和类型
val testDS: Dataset[Person] = rdd.map {line=>
Person(line._1,line._2)
}.toDS
可以注意到,定义每一行的类型(case class)时,已经给出了字段名和类型,后面只要往case class里面添加值即可
Dataset转DataFrame:
这个也很简单,因为只是把case class封装成Row
import spark.implicits._
val testDF = testDS.toDF
DataFrame转Dataset:
import spark.implicits._
case class Coltest(col1:String,col2:Int)extends Serializable //定义字段名和类型
val testDS = testDF.as[Coltest]
这种方法就是在给出每一列的类型后,使用as方法,转成Dataset,这在数据类型是DataFrame又需要针对各个字段处理时极为方便
Spark 2.0介绍:从RDD API迁移到DataSet API
Spark 2.0介绍:Dataset介绍和使用
二、RDD转换成DataFrame的2种方式
1.根据反射推断schema,,,RDD转Dataset:
这个方式简单,但是不建议使用,因为在工作当中,使用这种方式是有限制的。
对于以前的版本来说,case class最多支持22个字段如果超过了22个字段,我们就必须要自己开发一个类,实现product接口才行。因此这种方式虽然简单,但是不通用;因为生产中的字段是非常非常多的,是不可能只有20来个字段的。
object createDF {
// 方法1 根据包括case class数据的RDD转换成DataFrame
// case class定义表的schema,case class的属性会被读取并且成为列的名字
case class Person(name: String, age: Int)
def main(args: Array[String]): Unit = {
val conf = new SparkConf().setAppName("sparkSQLTest").setMaster("local")
val sc = new SparkContext(conf)
val sqlContext = new SQLContext(sc)
//先将RDD转化成case class 数据类型,然后再通过toDF()方法隐式转换成DataFrame
import sqlContext.implicits._
val people = sc.textFile("E:/path/data/people.txt")
.map(_.split(","))
.map(p =>Person(p(0), p(1).trim.toInt)) //将rdd的每一行都转换成了一个people
.toDF() //必须先导入import spark.implicits._ 不然这个方法会报错
people.show()
val bdf: DataFrame = boyRDD.toDF
val bdf2: DataFrame = sqlContext.createDataFrame(boyRDD)
//变成DF后就可以使用两种API进行编程了
///////////////////////////////////////////////
val people: DataFrame = sc.textFile("E:/path/data/people.txt")
.map(_.split(",")).map { line =>
(line(0).toLong, line(1))
}.toDF("id", "name")
///////////////////////////////////////////////
val rdd: RDD[(Long, String, Int, Double)] = lines.map(line => {
val fields = line.split(",")
(line(0).toLong, line(1).toString(), line(2).toInt, line(3).toDouble)
})
val testDF: DataFrame = rdd.map { line =>
(line._1, line._2)
}.toDF("id", "name")
/////////////////////////////////////////////////////
testDF.select("id").show()
/////////////////////////////////////////////
val testDS: Dataset[Boy] = rdd.map { line =>
Boy(line._1, line._2, line._3, line._4)
}.toDS
val toDS: Dataset[Boy] = bDF.as[Boy]
//DSL风格
//SparkSQL提供了一个领域特定语言(DSL)以方便操作结构化数据
personDF.select(col("name")).show
personDF.select("name").show
personDF.select("name", "age").show
//4.过滤age大于等于25的,使用filter方法过滤
ersonDF.filter(col("age") >= 25).show
personDF.filter($"age" >25).show
//5.统计年龄大于30的人数
personDF.filter(col("age")>30).count()
personDF.filter($"age" >30).count()
//6.按年龄进行分组并统计相同年龄的人数
personDF.groupBy("age").count().show
//SQL风格
//DataFrame的一个强大之处就是我们可以将它看作是一个关系型数据表,然后可以通过在程序中使用spark.sql() 来执行SQL查询,结果将作为一个DataFrame返回
//如果想使用SQL风格的语法,需要将DataFrame注册成表:
personDF.createOrReplaceTempView("t_person")
//注册成一个表
people.registerTempTable("peopleTable")
//然后可以对表进行各种操作,比如打印出13到19岁青少年的姓名
val teenagers = sqlContext.sql("SELECT name, age FROM people WHERE age >= 13 AND age <= 19") //WHERE age BETWEEN 13 AND 19
teenagers.map(t => "Name: " + t(0)).collect().foreach(println)
// teenager(0)代表第一个字段
// 取值的第一种方式:index from zero
teenagers.map(teenager => "Name: " + teenager(0)).show()
// 取值的第二种方式: byName
teenagers.map(teenager => "Name: " + teenager.getAs[String]("name") + "," + teenager.getAs[Int]("age")).show()
}
} 2.使用Programmatically的方式指定Schema
创建一个DataFrame,使用编程的方式 这个方式用的非常多。通过编程方式指定schema ,对于第一种方式的schema其实定义在了case class里面了。
object createDF {
def main(args: Array[String]): Unit = {
val conf = new SparkConf().setAppName("sparkSQLTest").setMaster("local")
val sc = new SparkContext(conf)
val sqlContext = new SQLContext(sc)
//step1: 从原来的 RDD 创建一个行的 RDD
val peopleRow = sc.textFile("E:/path/data/people.txt ")
.map(_.split(","))
.map(p => Row(p(0), p(1).trim))
//将数据进行整理
val rowRDD: RDD[Row] = sc.textFile("E:/path/data/people.txt ")
.map(line => {
val fields = line.split(",")
val id = fields(0).toLong
val name = fields(1)
val age = fields(2).toInt
val fv = fields(3).toDouble
Row(id, name, age, fv)
})
//step2: 创建由一个 StructType 表示的模式, 并且与第一步创建的 RDD 的行结构相匹配
//构造schema用到了两个类StructType和StructFile,其中StructFile类的三个参数分别是(字段名称,类型,数据是否可以用null填充)
val schema = StructType(Array(
StructField("name", StringType, true),
StructField("age", IntegerType, true)
))
//step3.在行 RDD 上通过 createDataFrame 方法应用模式
val people = sqlContext.createDataFrame(peopleRow, schema)
peopleDF.show()
people.registerTempTable("peopleTable")
//将临时表的数据插入hive表user
sqlContext.sql("insert into table user SELECT name, age FROM people WHERE age >= 13 AND age <= 19")
//然后可以对表进行各种操作,比如打印出13到19岁青少年的姓名
val teenagers = sqlContext.sql("SELECT name, age FROM people WHERE age >= 13 AND age <= 19")
teenagers.map(t => "Name: " + t(0)).collect().foreach(println)
}
} 三、SparkSql中的UDF、UDAF函数
1、UDF:User-defined Function,用户自定义函数。一般为单输出类型,这里以scala代码为例:
/**
* @function 自定义UDF————依照姓名字符长短倒排学生姓名,并统计姓名字符长度
* 郑重声明,scala中自定义函数需继承UDF类
*/
object UDF {
def main(args: Array[String]): Unit = {
val spark = SparkSession.builder().master("local").appName("UDF").getOrCreate()
val nameList: List[String] = List[String]("zhangsan", "lisi", "wangwu", "zhaoliu", "tianqi")
import spark.implicits._
val nameDF: DataFrame = nameList.toDF("name")
nameDF.createOrReplaceTempView("students")
nameDF.show()
spark.udf.register("STRLEN",(name:String)=>{
name.length
})
spark.sql("select name ,STRLEN(name) as length from students order by length desc").show(100)
}
}
object UDFTest {
case class Person(name: String, age: Int)
def main(args: Array[String]): Unit = {
//常见SparkSession
val sparkSession: SparkSession = SparkSession.builder().appName("DataFrameTest").master("local[2]").getOrCreate()
//根据文件获取RDD
val personRDD: RDD[String] = sparkSession.sparkContext.textFile("C:\\Users\\39402\\Desktop\\person.txt")
/**
* 注册一个udf函数,
* toString:为自定义函数的引用名,
* (str: String) => str + "我是UDF自定义函数":这个是自定义的函数体,它是一个匿名函数
*/
sparkSession.udf.register("toString", (str: String) => str + "我是UDF自定义函数")
import sparkSession.implicits._
//引入隐式转换
//利用反射将RDD转换成DataFrame
val personDF: DataFrame = personRDD.map(_.split(",")).map(line => Person(line(0), line(1).toInt)).toDF()
//将DataFrame注册成一张表
personDF.createOrReplaceTempView("person")
//利用Spark的SQL来查询数据,其中toString就是我们自定义的UDF函数
sparkSession.sql("select toString(name),age from person").show()
}
}
2、UDAF:User- Defined Aggregation Funcation,用户定义聚合函数。注意关键词“聚合”,一般为多进单出类型;有使用数据库经验的小伙伴可以思考一下avg、sum、count、max、min这五个颇具代表性的聚合函数。
这里我们依然用scala代码来完成任务。
依然是统计学生(但例子与上面UDF并不相同),UDAF与UDF不同,它必须继承UserDefinedAggregateFunction,并重写以下8个方法:
object MyCustomUDAF extends UserDefinedAggregateFunction {
//:: Nil 作用就是为StructField常见Array集合,并放入进去
def inputSchema: StructType = StructType(StructField("age", IntegerType) :: Nil)
//输入数据类型
override def inputSchema: StructType = StructType(List(
//给输入变量定义变量名 和 数据类型
StructField("value", DoubleType)
))
//缓存字段类型,也就是每个分区的共享变量
def bufferSchema: StructType = StructType(
StructField("sum", IntegerType) ::StructField("count", IntegerType) :: Nil)
//中间结果的数据类型
override def bufferSchema: StructType = StructType(
List(
StructField("product", DoubleType), //相乘之后的积
StructField("counts", LongType) //参与运算的数字总数
))
//UDF输出数据类型
def dataType: DataType = IntegerType
//输入类型和输出类型是否一致
def deterministic: Boolean = true
//初始化分区中的共享变量
def initialize(buffer: MutableAggregationBuffer): Unit = {
//为每个分组的数据执行初始化值
buffer(0) = 0 //初始化每个分区上的年龄总和为0
buffer(1) = 0 //初始化每个分区上的人数为0
}
// 每个组,有新的值进来的时候,进行分组对应的聚合值的计算
//局部聚合 就是每个分区内的运算,每个分区中每一条记录,聚合的时候需要调用该方法
def update(buffer: MutableAggregationBuffer, input: Row): Unit = {
//将新输入进来的数据一之前合并的结果做聚合操作,
//buffer(0)就是上边定义的年龄总和sum,也就是每个分区上的年龄总和
buffer(0) = buffer.getInt(0) + input.getInt(0)
//buffer(1)就是上边定义的人的个数count,也就是每个分区上的人个数
buffer(1) = buffer.getInt(1) + 1
}
// 全局聚合,对分区结果进行合并
def merge(buffer1: MutableAggregationBuffer, buffer2: Row): Unit = {
// buffer1(0)就是所有分区的年龄总和
//下标为0的就是年龄总和
buffer1(0) = buffer1.getInt(0) + buffer2.getInt(0) //就是将没分区上的年龄相加
//buffer(1)就是所有分区的人个数
//下标为1就是人的个数
buffer1(1) = buffer1.getInt(1) + buffer2.getInt(1) // 就是将每个分区人个数聚合在一起,
}
//最终结算结果
def evaluate(buffer: Row): Any = {
buffer.getInt(0) / buffer.getInt(1)
}
}
object MyCustomUDAFMain {
def main(args: Array[String]): Unit = {
val sparkSession: SparkSession = SparkSession.builder().appName("DataFrameTest").master("local[2]").getOrCreate()
//根据文件获取RDD
val personRDD: RDD[String] = sparkSession.sparkContext.textFile("C:\\Users\\39402\\Desktop\\person.txt")
import sparkSession.implicits._
//引入隐式转换
//利用反射将RDD转换成DataFrame
val personDF: DataFrame = personRDD.map(_.split(",")).map(line => Person(line(0), line(1).toInt)).toDF()
sparkSession.udf.register("myCustomUDAF", MyCustomUDAF)
personDF.createOrReplaceTempView("person")
/**
* 输出结果为:15
*/
sparkSession.sql("select myCustomUDAF(age) from person").show()
}
}