Datawhale-零基础入门NLP-新闻文本分类Task05
该任务是用Word2Vec进行预处理,然后用TextCNN和TextRNN进行分类。TextCNN是利用卷积神经网络进行文本文类,TextCNN是用循环神经网络进行文本分类。
1.Word2Vec
文本是一类非结构化数据,文本表示模型有词袋模型(Bag of Words)、主题模型(Topic Model)、词嵌入模型(Word Embedding)。
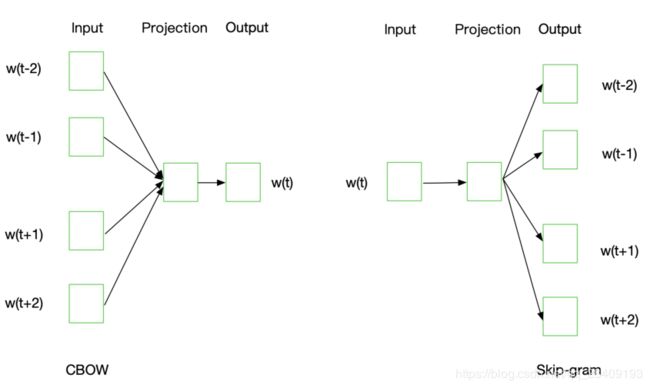
词嵌入是一类将词向量化的模型的统称,核心思想是将每个词都映射成低维空间上的一个稠密向量,Word2Vec是常见的词嵌入模型之一。Word2Vec有两个网络结构CBOW和Skip-gram。
CBOW的目标是根据上下文出现的词语来预测当前词的生成概率,Skip-gram是根据当前词来预测上下文中各词的生成概率。
2.TextCNN
对于文本来说,局部特征就是由若干单词组成的滑动窗口,类似于N-gram。卷积神经网络的优势在于能够自动对N-gram特征进行组合和筛选,获得不同抽象层次的语义信息。由于在每次卷积中采用了共享权重的机制,因此它的训练速度较快。
TextCNN是由输入层,卷积层,池化层,输出层组成,结构如下:
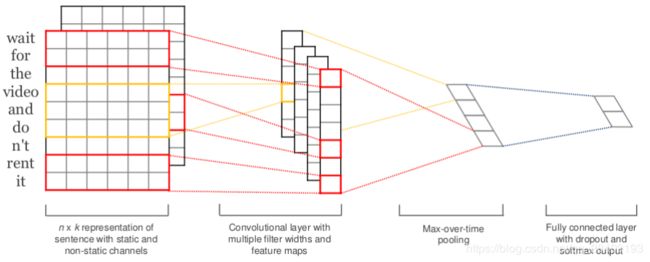
(1)输入层
输入层是一个N*K的矩阵,其中N为文章所对应的单词总数,K是每个词对应的表示向量的维度。每个词的K维向量可以是预先在其他语料库训练好的,也可以作为未知的参数由网络训练得到。因此,该输入层采用了两个通道的形式,即有两个N*K的输入矩阵,其中一个用预先训练好的词嵌入表达,并且在训练过程中不再变化;另一个 会随网络的训练过程而变化。
(2)卷积层
在输入的两个N*K的矩阵上,我们定义不同的滑动窗口进行卷积操作。每一次卷积操作相当于一个特诊向量的提取,通过定义不同的滑动窗口,就可以提取出不同的特征向量。
(3)池化层
池化层可以采用1-Max池化,即为从每个滑动窗口产生的特征向量中筛选出一个最大的特征,然后将这些特征拼接起来构成向量表示。也可以选用K-Max池化(选出每个向量中最大的K个特征),或者平均池化等,达到的效果是将不同长度的句子通过池化得到一个定长的向量表示。
(4)输出层
得到文本的向量表示之后,后面的网络结构就和具体任务相关了。文本分类是接入全连接层,并使用SoftMax激活函数输出每个类别的概率。
3.TextRNN
传统文本处理任务中丢失了输入的文本序列中每个单词的顺序,两个单词之间的长距离依赖关系还是很难学习到。循环神经网络却能很好地处理文本数据变长并且有序的输入序列。常用的循环神经网络有RNN,双向RNN,LSTM,GRU等。
循环神经网络(Recurrent Neural Network,RNN)是将网络隐藏层的输出重新连接到隐藏层形成闭环。它模拟了人阅读一篇文章的顺序,将前面有用的信息编码到状态变量中,从而有一定的记忆能力。典型结构为:
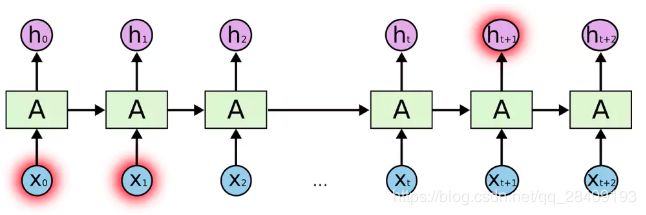
循环神经网络是采用BPTT(Back Propagation Through Time,基于时间的反向传播)求解的,然后使用BPTT学习的循环神经网络不能成功捕捉到长距离的依赖关系,由于sigmoid函数具有饱和性,在进行大量训练之后,就会出现梯度消失问题。如果计算矩阵的最大特征值大于1,随着训练,每层的梯度大小会呈指数增长,导致梯度爆炸;反之,如特征值小于1,则出现梯度消失。因此,LSTM,GRU是通过加入门控机制来弥补梯度上的损失。
长短期记忆网络(Long Short Term Memory,LSTM)是循环神经网络的扩展,由于循环神经网络有梯度消失和梯度爆炸的问题,学习能力有限,LSTM可以对有价值的信息进行长期记忆,从而减少循环神经网络的学习难度。LSTM是一组记忆块(memory blocks)的循环子网构成,每一个记忆块包含了一个或多个自连接的记忆细胞及三个乘法控制单元-输入门、输出门、遗忘门,提供着读、写、重置的功能。
输入门控制当前计算的新状态以多大程度更新到记忆单元;当信息经过输入单元激活后会和输入门进行相乘,以确定是否写入当前信息;
输出门控制着当前的输出有多大程度上取决于当前的记忆单元;其与当前细胞记忆信息进行相乘,以确定是否输出信息;
遗忘门控制着前一步记忆单元中的信息有多大程度被遗忘掉;其与细胞之前的记忆信息进行乘法运算,以确定是否保留之前的信息;
记忆块的结构:

其中,σ是sigmoid函数,tanh是tanh函数,![]() 是相乘,
是相乘,![]() 是相加。
是相加。
第1个部分,通过一个sigmoid函数,决定丢弃的信息,第2部分,在生成候选记忆时,使用了双曲线正切函数Tanh作为激活函数,确定更新信息,第3部分,更新了细胞状态,第4 部分是将结果进行输出并传递给下一个记忆块。
参考:
《百面机器学习》——诸葛越
《深度学习实战》——杨云