1.实验要求
输入为一个以类C语言编写的源程序
输出为一组二元组序列构成的文本文件,一行为一个二元组,二元组中间以逗号隔开
实验报告上要求附上DFA
2.语言说明:
保留字:unsigned、break、return、void、case、float、char、for、while、continue、if、default、do、int、switch、double、long、else
运算符:+,-,*,/,>,>=,<,<=,==,!=,&&,||,!
界限符:{ }( ); ,
常量:十进制无符号数
标识符:以字母或下划线开始,后面跟上字母或数字
3. 实验原理
词法分析是编译的第一阶段。词法分析器的主要任务是读入源程序的输入字符,将它们组成词素,生成并输出一个词法单元序列,这个词法单元序列被输出到语法分析器进行语法分析。另外,由于词法分析器在编译器中负责读取源程序,因此除了识别词素之外,它还会完成一些其他任务,比如过滤掉源程序中的注释和空白,将编译器生成的错误消息与源程序的位置关联起来等。词法分析器的作用如下:
读入源程序的输入字符,将它们组成词素,生成并输出一个词法单元序列;
过滤掉源程序中的注释和空白;
将编译器生成的错误消息与源程序的位置关联起来;
4.DFA设计: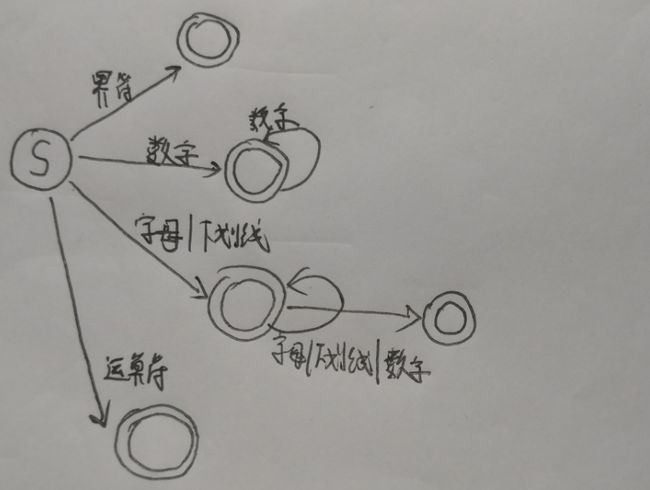
5.实验代码
#include
#include
#include
输入的类C词法
char word[10];
char pro[100][100] = { "PROGRAM",
"BEGIN", "END", "VAR", "INTEGER", "WHILE", "IF", "THEN",
"ELSE", "DO", "PROCEDURE" ,
"char","int","if","else","var"
,"return","break","do","while","for","double","float","short"};
int n = 0;
word[n++] = a[i++];
while ((a[i] >= 'A'&&a[i] <= 'Z') || (a
[i] >= '0' && a[i] <= '9')||(a[i]>='a'&&a[i]<='z'))
{
word[n++] = a[i++];
}
word[n] = '\0';
i--;
程序运行输出结果:
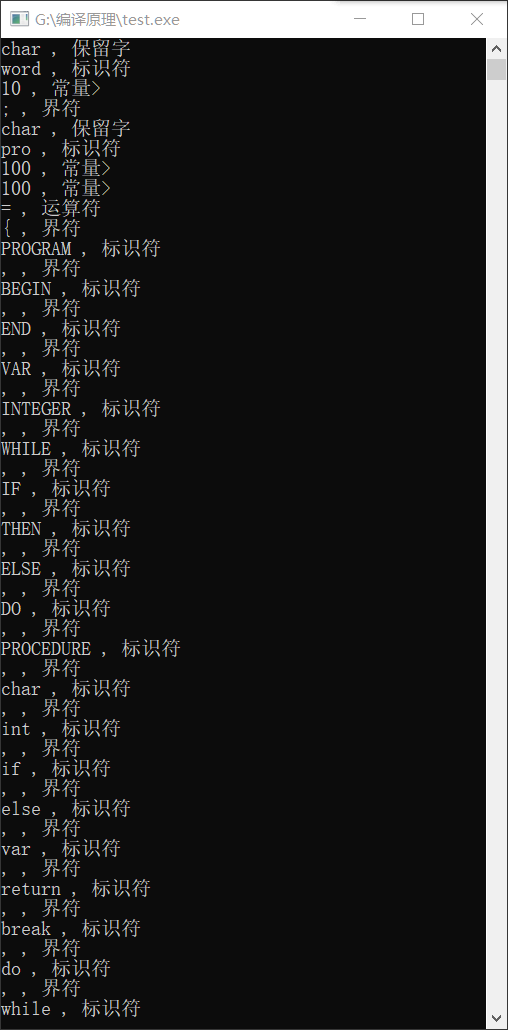
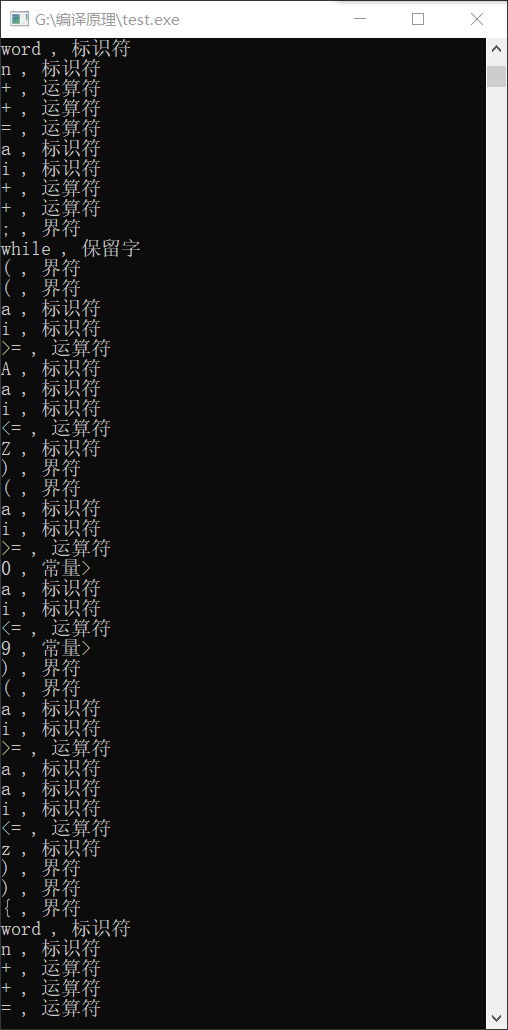
6.分析讨论:
(1)遇见问题:二目运算符无法识别 ,导致拆分识别为两个单目运算符;第二个问题就是如果识别的词法带有注释,会报错。
(2)解决方法: 修改识别运算符代码部分加入双目运算符的识别
(3)后续改进思路:一个不方便的地方就是没能实现通过输入文件名读取文件的数据,每次读入新的文件仍需要修改代码。