Weakly-Supervised Discovery of Geometry-Aware Representation for 3D Human Pose Estimation CVPR 2019
gold:
learn a geometry-aware 3D representation G \mathcal{G} G for the human pose
discover the geometry relation between paired images ( I t i , I t j ) ( I^i_t,I^j_t) (Iti,Itj)
which are acquired from synchronized and calibrated cameras
- i , j i,j i,j:different view point
- t t t:acquiring time acquiring
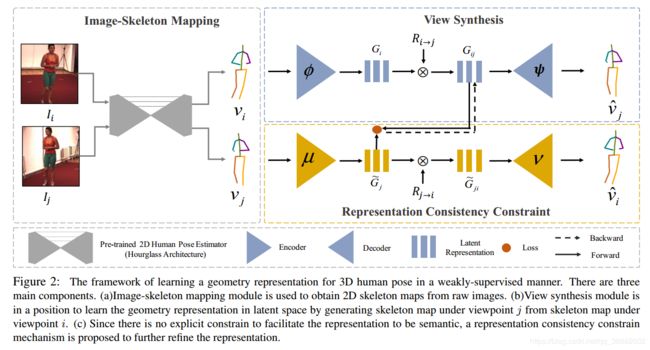
main components
- image skeleton mapping
- skeleton-based view synthesis
- representation consistency constraint
image-skeleton mapping
input raw image pair ( I t i , I t j ) ( I^i_t,I^j_t) (Iti,Itj) with size of W × H W\times H W×H
- i , j i,j i,j:different view point ,(synchronized and calibrated cameras i , j i,j i,j)
C t i , C t j C^i_t,C^j_t Cti,Ctj: K K K keypoint heatmaps from a pre-trained 2D human pose eastimator
We follow previous works [45, 20, 18] to train the 2D estimator on MPII dataset.
constructed 8 pixels width 2D skeleton maps from heatmaps
binary skeleton maps pair ( S t i , S t j ) ( S^i_t,S^j_t) (Sti,Stj), S t ( ⋅ ) ∈ { 0 , 1 } ( K − 1 ) × W × H S_t^{(\cdot)}\in\{0,1\}^{(K-1)\times W \times H} St(⋅)∈{0,1}(K−1)×W×H
Geometry representation via view synthesis
training set T = { ( S t i , S t j , R i → j ) } \mathcal T = \{(S^i_t,S^j_t,R_{i\to j})\} T={(Sti,Stj,Ri→j)}
- pairs of two views of projection of same 3D skeleton ( S t i , S t j ) (S^i_t,S^j_t) (Sti,Stj)
- relative rotation matrix R i → j R_{i\to j} Ri→j from coordinate system of camera i i i to j j j
Straightforward way for learning representation in unsupervised/weakly-supervised manner is to utilize auto-encoding mechanism reconstrcting input image.
- no geometry structure information
- nor provides more useful information for 3D pose estimation than 2D coordinates
novel ‘skeleton-based view synthesis’ generate image under a new viewpoint.
Given an image under the known viewpoint as input
source domain : (input image) S i = { S t i } i = 1 V \mathcal S^i = \{S^i_t\}^V_{i=1} Si={Sti}i=1V
- V V V :amount of viewpoints
target domain :generate image S j = { S t j } i = 1 V \mathcal S^j = \{S^j_t\}^V_{i=1} Sj={Stj}i=1V
- j ̸ = i j \not=i j̸=i
encoder ϕ : S i → G \phi:\mathcal S^i \to \mathcal G ϕ:Si→G
- source skeleton S t i → S i S^i_t \to \mathcal S^i Sti→Si into a latent space G i ∈ G G_i\in \mathcal G Gi∈G
decoder ψ : R i → j × G → S i \psi:\mathcal R_{i\to j} \times \mathcal G \to \mathcal S_i ψ:Ri→j×G→Si
- ratation matrix R i → j R_{ i \to j } Ri→j
- G i G_i Gi as the set of m m m discrete points on 3 η \eta η-dimensional space
in practice: G = [ g 1 , g 2 , . . . g M ] T , g m = ( x m , y m , z m ) G = [g_1,g_2,...g_M]^T,g_m = (x_m,y_m,z_m) G=[g1,g2,...gM]T,gm=(xm,ym,zm)
L ℓ 2 ( ϕ ⋅ ψ , θ ) = 1 N T ∑ ∥ ψ ( R i → j × ϕ ( S t i ) ) − S t j ∥ L_{\ell2}(\phi \cdot\psi,\theta)=\frac{1}{N^T}\sum\lVert\psi(R_{i\to j}\times\phi(S^i_t))-S^j_t\rVert Lℓ2(ϕ⋅ψ,θ)=NT1∑∥ψ(Ri→j×ϕ(Sti))−Stj∥
Representation consistency constraint
image skeleton mapping + view synthesis (previous two steps)lead to unrealistic generation on target pose when there are large self occlusions in source view
Since there is no explicit constraint on latent space to facilitate G \mathcal G G to be semantic
We assume there exists an inverse mapping (one-to-one) between source domain and target domain, on the condition of the known relative rotation matrix. We could find:
a encoder μ : S j → G \mu:\mathcal S^j \to \mathcal G μ:Sj→G
- maps target skeleton S t j S^j_t Stj to latent space G ~ j ∈ G \tilde G_j \in \mathcal G G~j∈G
a decoder ν : R j → i × G → S t i \nu:R_{j\to i}\times G \to S^i_t ν:Rj→i×G→Sti
- maps representation G ~ j \tilde G_j G~j back to source skeleton S t i S^i_t Sti
- G ~ i \tilde G_i G~i and G i G_i Gi should be the same shared representation on G \mathcal G G with different rotation-related coefficients ------namely representation consistency
l r c = ∑ m = 1 M ∥ f × G i − G ~ i ∥ 2 l_{rc}=\sum_{m=1}^M\lVert f \times G_i -\tilde G_i \rVert^2 lrc=m=1∑M∥f×Gi−G~i∥2
- f = R i → j f = R_{i \to j} f=Ri→j rotation-related transformation that map G i G_i Gi to G ~ j \tilde G_j G~j
- a bidirectional encoderdecoder framework
- g e n e r a t o r ( ϕ , ψ ) generator(\phi,\psi) generator(ϕ,ψ), G i j G_{ij} Gij:rotated G i G_i Gi
- g e n e r a t o r ( μ , ν ) generator(\mu,\nu) generator(μ,ν)
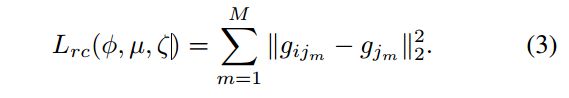
total loss of the bidirectional model

where θ and ζ denotes the parameters of two encode-decoder networks, respectively.
3D human pose estimation by learnt representation
given: monocular image I I I
goal : b = { ( x p , y p , z p ) } p = 1 P \bold b = \{(x^p,y^p,z^p)\}^P_{p=1} b={(xp,yp,zp)}p=1P,P body joints, b ∈ B \bold b \in \mathcal B b∈B
function F : I → B \mathcal F:\mathcal I \to \mathcal B F:I→B to learn the pose regression
2 fully connect layer