CUDA编程(一)第一个CUDA程序
CUDA编程(一)
第一个CUDA程序 Kernel.cu
CUDA是什么?
CUDA(Compute Unified Device Architecture),是显卡厂商NVIDIA推出的运算平台。是一种通用并行计算架构,该架构使GPU能够解决复杂的计算问题。说白了就是我们可以使用GPU来并行完成像神经网络、图像处理算法这些在CPU上跑起来比较吃力的程序。通过GPU和高并行,我们可以大大提高这些算法的运行速度。
有的同学可能知道,在CPU和GPU上跑同一个神经网络,由于其大量的浮点数权重计算以及可高并行化,其速度的差距往往在10倍左右,原本需要睡一觉才能看到的训练结果也许看两集动漫就OK了。
GPU并行在图像处理方面更是应用广泛,大家知道图像处理实际上是对图像的二维矩阵进行处理,图像的尺寸都是几百乘几百的,很容易就是上万个像素的操作,随便搞个什么平滑算法,匹配算法等等的图像算法在CPU上跑个几十秒都是很正常的,对于图像处理,神经网络这种大矩阵计算,往往是可以并行化的,通过GPU并行化处理往往能够成倍的加速。
综上所述,去学习一下怎么在GPU上开个几千个线程过把优化瘾还是一件很惬意的事情,更何况CUDA为我们提供了这么优秀的计算平台,可以直接使用C/C++写出在显示芯片上执行的程序,还是一件很赞的事情。
不过CUDA编程需要注意的点是很多的,有很多因素如果忽略了会大大降低速度,写的不好的CUDA程序可能会比CPU程序还慢。所以优化和并行是一门很大的学问,需要我们去不断学习与了解。
CUDA安装
CUDA发展到现在说实话已经比较成熟了,当然在使用的时候偶尔会出现各种各样的问题(充满血与泪),但就谈安装来说已经很简单了,这里以VS2013和CUDA 7.0为例(现在已经到CUDA7.5了,我需要使用ZED摄像头,而它只支持7.0,所以电脑上装的7.0)。
首先我们随便用搜索引擎搜索CUDA就会找到CUDA Toolkit的下载首页:
https://developer.nvidia.com/cuda-downloads
之后选择系统下载就好:

下载结束之后一路安装就好,注意:安装选项那里要选择自定义然后把所有都勾选上:

现在的CUDA安装还是很简单的,等安装结束之后就会发现CUDA for Visual Studio已经安装成功了,我们也不需要去添加什么环境变量,这些工作安装程序都帮我们做好了~之后我们打开VS,也不需要繁琐的各种引库的过程了,我们只需要新建一个CUDA工程就可以了~
创建好工程之后,会发现已经自带了一个矩阵相乘的示例代码Kernel.cu,二话不说直接ctrl+f5编译运行,如果没报什么编译错误运行成功那就恭喜同学你跑了你的第一个我CUDA程序~Kernel.cu
注意:这里我再多说几句,我关于各种错误的解决经验。CUDA还是会经常出现各式各样的问题的,我自己就遇到过好几个。
(1)首先最简单的一个,你的工程路径不能有中文。。。好多个版本了都没解决这个问题。
(2)然后,还有一个很傻X的问题,如果你的C:\Users\****\AppData这个路径,****部分因为你的Microsoft账户是中文的,有时候你装完系统登录完账号,这个文件夹会是中文的。。比如王尼玛会有一个尼玛文件夹。出现这种情况会出现一个什么什么Unicode的错误,然后基本上是没救了,反正我最终没能改掉那个文件夹的名字。。。。有知道怎么改的同学一定要告诉我一下。。
(3)有时候还会出现下面这个错误,这个也很奇葩,我隔了一周没写CUDA程序,然后再写的时候原来没问题的程序都编译不过了,周天就给我来了这么个开门黑,重装了各种版本的CUDA仍然不行,弄了两天才莫名其妙的弄好,这个貌似是因为.net的问题,我在控制面板-卸载程序-启用或关闭Windows功能 里把.net4.5关了,打开了.Net3.5 , 重启,然后,还是不行,我已经准备要重装电脑了,去吃了个晚饭回来,莫名其妙行了。

(4)我还遇到过核函数进不去的情况,也是莫名其妙出现的,就是下面会讲到的__global__函数,最后被迫重装了遍CUDA,然后还是不行,重启,结果行了。
总之大家看到我遇到的奇葩问题就知道了,这玩意有时候还是很脆弱的,什么杀毒软件,系统更新啥的都可能随时干掉你的CUDA,所以防患于未然还是把这些玩意都关了吧。
我知道CUDA安装的还是比较慢的,安装的时候还是来看一下关于GPU和CUDA架构的一些基础知识吧~
CPU&GPU
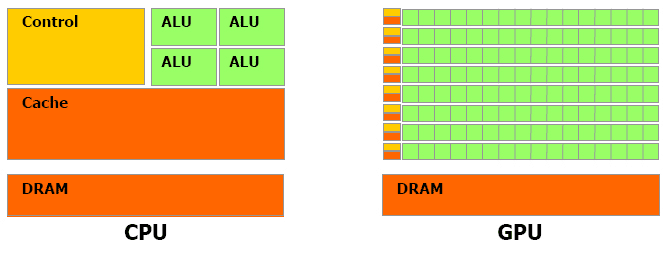
上图是CPU与GPU的对比图,对于浮点数操作能力,CPU与GPU的能力相差在GPU更适用于计算强度高,多并行的计算中。因此,GPU拥有更多晶体管,而不是像CPU一样的数据Cache和流程控制器。这样的设计是因为多并行计算的时候每个数据单元执行相同程序,不需要那么繁琐的流程控制,而更需要高计算能力,这也不需要大cache。但也因此,每个GPU的计算单元的结构是十分简单的,因此对程序的可并行性的要求也是十分苛刻的。
这里我们再介绍一下使用GPU计算的优缺点(摘自《深入浅出谈CUDA》,所以举的例子稍微老了一点,但不影响意思哈):
使用显示芯片来进行运算工作,和使用 CPU 相比,主要有几个好处:
显示芯片通常具有更大的内存带宽。例如,NVIDIA 的 GeForce 8800GTX 具有超过50GB/s 的内存带宽,而目前高阶 CPU 的内存带宽则在 10GB/s 左右。
显示芯片具有更大量的执行单元。例如 GeForce 8800GTX 具有 128 个 “stream processors”,频率为 1.35GHz。CPU 频率通常较高,但是执行单元的数目则要少得多。
和高阶 CPU 相比,显卡的价格较为低廉。例如一张 GeForce 8800GT 包括512MB 内存的价格,和一颗 2.4GHz 四核心 CPU 的价格相若。
当然,使用显示芯片也有它的一些缺点:
显示芯片的运算单元数量很多,因此对于不能高度并行化的工作,所能带来的帮助就不大。
显示芯片目前通常只支持 32 bits 浮点数,且多半不能完全支持 IEEE 754 规格, 有些运算的精确度可能较低。目前许多显示芯片并没有分开的整数运算单元,因此整数运算的效率较差。
显示芯片通常不具有分支预测等复杂的流程控制单元,因此对于具有高度分支的程序,效率会比较差。
目前 GPGPU 的程序模型仍不成熟,也还没有公认的标准。例如 NVIDIA 和AMD/ATI 就有各自不同的程序模型。
CUDA架构
host 和 kernel:

在 CUDA 的架构下,一个程序分为两个部份:host 端和 device 端。Host 端是指在 CPU 上执行的部份,而 device 端则是在显示芯片上执行的部份。Device 端的程序又称为 “kernel”。通常 host 端程序会将数据准备好后,复制到显卡的内存中,再由显示芯片执行 device 端程序,完成后再由 host 端程序将结果从显卡的内存中取回。
由于 CPU 存取显卡内存时只能透过 PCI Express 接口,因此速度较慢(PCI Express x16 的理论带宽是双向各 4GB/s),因此不能太常进行这类动作,以免降低效率。
thread-block-grid 结构:
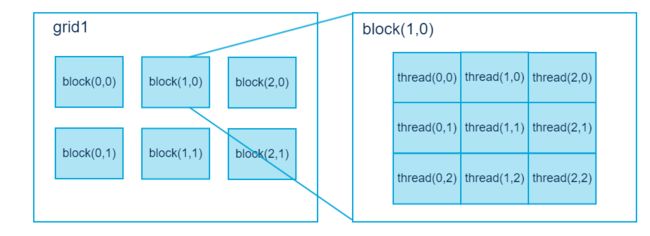
在 CUDA 架构下,显示芯片执行时的最小单位是thread。数个 thread 可以组成一个block。一个 block 中的 thread 能存取同一块共享的内存,而且可以快速进行同步的动作。
每一个 block 所能包含的 thread 数目是有限的。不过,执行相同程序的 block,可以组成grid。不同 block 中的 thread 无法存取同一个共享的内存,因此无法直接互通或进行同步。因此,不同 block 中的 thread 能合作的程度是比较低的。不过,利用这个模式,可以让程序不用担心显示芯片实际上能同时执行的 thread 数目限制。例如,一个具有很少量执行单元的显示芯片,可能会把各个 block 中的 thread 顺序执行,而非同时执行。不同的 grid 则可以执行不同的程序(即 kernel)。
每个 thread 都有自己的一份 register 和 local memory 的空间。同一个 block 中的每个thread 则有共享的一份 share memory。此外,所有的 thread(包括不同 block 的 thread)都共享一份 global memory、constant memory、和 texture memory。不同的 grid 则有各自的 global memory、constant memory 和 texture memory。
执行模式:
由于显示芯片大量并行计算的特性,它处理一些问题的方式,和一般 CPU 是不同的。主要的特点包括:
内存存取 latency 的问题:CPU 通常使用 cache 来减少存取主内存的次数,以避免内存 latency 影响到执行效率。显示芯片则多半没有 cache(或很小),而利用并行化执行的方式来隐藏内存的 latency(即,当第一个 thread 需要等待内存读取结果时,则开始执行第二个 thread,依此类推)。
分支指令的问题:CPU 通常利用分支预测等方式来减少分支指令造成的 pipeline bubble。显示芯片则多半使用类似处理内存 latency 的方式。不过,通常显示芯片处理分支的效率会比较差。
因此,最适合利用 CUDA 处理的问题,是可以大量并行化的问题,才能有效隐藏内存的latency,并有效利用显示芯片上的大量执行单元。使用 CUDA 时,同时有上千个 thread 在执行是很正常的。因此,如果不能大量并行化的问题,使用 CUDA 就没办法达到最好的效率了。
总结:
再写下去篇幅就太长了,本篇博客主要还是介绍了CUDA的安装以及一些基本的CUDA的架构,大家趁着CUDA安装的空可以仔细看一下CUDA的结构,这对后面的编程还是很重要的,下面我会从一个很小的程序写起,不断地把上面介绍到的东西都加进去,希望能帮助到大家的学习。
参考资料:《深入浅出谈CUDA》