CUDA编程(七)共享内存与Thread的同步
CUDA编程(七)
共享内存与Thread的同步
在之前我们通过block,继续增大了线程的数量,结果还是比较令人满意的,但是也产生了一个新的问题,即,我们在CPU端的加和压力变得很大,所以我们想到能不能从GPU上直接完成这个工作。
我们知道每个block内部的Thread之间是可以同步和通讯的,本篇我们将让每个block把每个thread的计算结果进行加和。所以本篇博客我们将研究CUDA架构中Thread另外两个非常重要的概念,共享内存Share Memory 以及 Thread 同步。
共享内存与Global内存
前面提过,一个 block 内的 thread 可以有共享的内存,也可以进行同步。我们正是可以利用这一点,让每个 block 内的所有 thread 把自己计算的结果加总起来。
那么Share Memory 和我们之前用的内存有什么区别呢?
GlobalMemory
其实我们之前复制到显存的都是global memory。在 CUDA 中,数据复制到的显卡内存的部份,称为global memory。
这些内存(global memory)是没有 cache 的(因为如果每个 multiprocessor 都有自己的global memory cache,将会需要 cache coherence protocol,会大幅增加 cache 的复杂度),所以存取global memory 所需要的时间(即 latency)是非常长的,通常是数百个 cycles,也正因此,我们之前才会想方设法的去隐藏或者减少这个latency。
在之前我们采取了两个主要的措施分别取隐藏和减少latency:
1 . 我们一方面通过大量线程并行的方法去不断读取内存(当一个 thread 读取内存,开始等待结果的时候,GPU 就可以立刻切换到下一个 thread,并读取下一个内存位置)来尽可能的隐藏latency。
2 . 另一方面我们采取了连续的内存存取模式,尽量减少latency,关于所谓的连续存储我们再详细说明一下:
其实更精确的说,global memory 的存取,需要是 “coalesced“。
所谓的 coalesced,是表示除了连续之外,而且它开始的地址,必须是每个 thread 所存取的大小的 16 倍。例如,如果每个thread 都读取 32 bits 的数据,那么第一个 thread 读取的地址,必须是 16*4 = 64 bytes 的倍数。
关于”coalesced“的满足与否,我们还需要考虑下面两种情况:
1 . 如果有一部份的 thread 没有读取内存,并不会影响到其它的 thread 速行 coalesced 的存取:
例如:
if(tid != 3)
{
int number = data[tid];
}虽然 thread 3 并没有读取数据,但是由于其它的 thread 仍符合 coalesced 的条件(假设 data 的地址是 64 bytes 的倍数),这样的内存读取仍会符合 coalesced 的条件。
2 .每个 thread 一次读取的内存数据量,可以是 32 bits、64 bits、或 128 bits。不过,32 bits 的效率是最好的。64 bits 的效率会稍差,而一次读取 128 bits 的效率则比一次读取 32 bits 要显著来得低(但仍比 non-coalesced 的存取要好)。
如果每个 thread 一次存取的数据并不是 32 bits、64 bits、或 128 bits,那就无法符合 coalesced 的条件.
例如,以下的程序:
struct vec3d { float x, y, z; };
...
__global__ void func(struct vec3d* data, float* output)
{
output[tid] = data[tid].x * data[tid].x + data[tid].y * data[tid].y + data[tid].z * data[tid].z;
}这个程序并不是 coalesced 的读取,因为 vec3d 的大小是 12 bytes,而非 4 bytes、8 bytes、或 16 bytes。
要解决这个问题,可以使用 __align(n)__,例如:
struct __align__(16) vec3d { float x, y, z; };这会让 compiler 在 vec3d 后面加上一个空的 4 bytes,以补齐 16 bytes。
另一个方法,是把数据结构转换成三个连续float的数组,例如:
__global__ void func(float* x, float* y, float* z, float* output)
{
output[tid] = x[tid] * x[tid] + y[tid] * y[tid] + z[tid] * z[tid];
}如果因为其它原因使数据结构无法这样调整,也可以考虑利用 shared memory 在 GPU 上做结构的调整。
例如:
__global__ void func(struct vec3d* data, float* output)
{
__shared__ float temp[THREAD_NUM * 3];
const float* fdata = (float*) data;
temp[tid] = fdata[tid];
temp[tid + THREAD_NUM] = fdata[tid + THREAD_NUM];
temp[tid + THREAD_NUM*2] = fdata[tid + THREAD_NUM*2];
//同步
__syncthreads();
output[tid] = temp[tid*3] * temp[tid*3] + temp[tid*3+1] * temp[tid*3+1] + temp[tid*3+2] * temp[tid*3+2];
}在上面的例子中,我们先用连续的方式,把数据从 global memory 读到 shared memory。由于shared memory 不需要担心存取顺序(但要注意 bank conflict 问题,后面马上会讲到),所以可以避开 non-coalesced 读取的问题。
ShareMemory
而接下来我们要使用的shared memory,是一个 block 中每个 thread 都共享的内存。它会使用在 GPU 上的内存,所以存取的速度相当快,不需要担心 latency 的问题。
声明一块ShareMemory也是十分简单的:
我们可以直接利用__shared__声明一个shared memory变量,例如:
__shared__ int sharedata[128];但是从硬件角度分析 Shared memory 有时候会出现一种叫bank conflict的问题,下面我们详细介绍一下,因为后面需要注意这个问题:
ShareMemory的bank conflict问题
目前 CUDA 装置中,每个 multiprocessor 有 16KB 的 shared memory。Shared memory 分成16 个 bank。如果同时每个 thread 是存取不同的 bank,就不会产生任何问题,存取 shared memory 的速度和存取寄存器相同。不过,如果同时有两个(或更多个) threads 存取同一个bank 的数据,就会发生 bank conflict,这些 threads 就必须照顺序去存取,而无法同时存取shared memory 了。
Shared memory 是以 4 bytes 为单位分成 banks。因此,假设以下的数据:
__shared__ int data[128];
那么,data[0] 是 bank 0、data[1] 是 bank 1、data[2] 是 bank 2、…、data[15] 是 bank 15,而 data[16] 又回到 bank 0。
由于 warp 在执行时是以 half-warp 的方式执行(关于half-warp参照上一篇博客),因此分属于不同的 half warp 的 threads,不会造成 bank conflict。
因此,如果程序在存取 shared memory的时候,使用以下的方式:
int number = data[base + tid];
那就不会有任何 bank conflict,可以达到最高的效率。但是,如果是以下的方式:
int number = data[base + 4 * tid];
那么,thread 0 和 thread 4 就会存取到同一个 bank,thread 1 和 thread 5 也是同样,这样就会造成 bank conflict。 在这个例子中,一个 half warp 的 16 个 threads 会有四个 threads 存取同一个 bank,因此存取 share memory 的速度会变成原来的 1/4。
一个重要的例外是,当多个 thread 存取到同一个 shared memory 的地址时,shared memory 可以将这个地址的 32 bits 数据「广播」到所有读取的 threads,因此不会造成 bank conflict。
例如:
int number = data[3];这样不会造成 bank conflict,因为所有的 thread 都读取同一个地址的数据。
很多时候 shared memory 的 bank conflict 可以透过修改数据存放的方式来解决。
例如,以下的程序:
data[tid] = global_data[tid];
...
int number = data[16 * tid];该程序会造成严重的 bank conflict,为了避免这个问题,可以把数据的排列方式稍加修改,把存取方式改成:
int row = tid / 16;
int column = tid % 16;
data[row * 17 + column] = global_data[tid];
...
int number = data[17 * tid];这样就不会造成 bank conflict 了。
Thread同步:
了解完ShareMemory与GlobalMemory之后,我们还需要学习一下Thread同步,因为我们要想让每个block把自己Thread的结果加起来,需要等到所有的Thread都将自己的结果结算出来。
不过同步问题也没什么好说的,因为这是无论使用哪种语言在使用多线程时都需要考虑的一个问题。
在CUDA中,想要完成block中的同步还是十分简单的,就是使用一个CUDA 的内部函数:
__syncthreads()它表示block 中所有的 thread 都要同步到这个点才能继续执行。
程序升级:
了解完这些非常重要的知识后,再去修改我们的程序也十分简单了,
我们先贴一下之前的完整代码:
#include >>(参数...);
sumOfSquares << < BLOCK_NUM, THREAD_NUM, 0 >> >(gpudata, result, time);
/*把结果从显示芯片复制回主内存*/
int sum[THREAD_NUM*BLOCK_NUM];
clock_t time_use[BLOCK_NUM * 2];
//cudaMemcpy 将结果从显存中复制回内存
cudaMemcpy(&sum, result, sizeof(int)* THREAD_NUM*BLOCK_NUM, cudaMemcpyDeviceToHost);
cudaMemcpy(&time_use, time, sizeof(clock_t)* BLOCK_NUM * 2, cudaMemcpyDeviceToHost);
//Free
cudaFree(gpudata);
cudaFree(result);
cudaFree(time);
int final_sum = 0;
for (int i = 0; i < THREAD_NUM*BLOCK_NUM; i++) {
final_sum += sum[i];
}
//采取新的计时策略 把每个 block 最早的开始时间,和最晚的结束时间相减,取得总运行时间
clock_t min_start, max_end;
min_start = time_use[0];
max_end = time_use[BLOCK_NUM];
for (int i = 1; i < BLOCK_NUM; i++) {
if (min_start > time_use[i])
min_start = time_use[i];
if (max_end < time_use[i + BLOCK_NUM])
max_end = time_use[i + BLOCK_NUM];
}
printf("GPUsum: %d gputime: %d\n", final_sum, max_end - min_start);
final_sum = 0;
for (int i = 0; i < DATA_SIZE; i++) {
final_sum += data[i] * data[i] * data[i];
}
printf("CPUsum: %d \n", final_sum);
return 0;
}首先我们的核函数肯定要进行修改:
// __global__ 函数 (GPU上执行) 计算立方和
__global__ static void sumOfSquares(int *num, int* result, clock_t* time)
{
//声明一块共享内存
extern __shared__ int shared[];
//表示目前的 thread 是第几个 thread(由 0 开始计算)
const int tid = threadIdx.x;
//表示目前的 thread 属于第几个 block(由 0 开始计算)
const int bid = blockIdx.x;
shared[tid] = 0;
int i;
//记录运算开始的时间
clock_t start;
//只在 thread 0(即 threadIdx.x = 0 的时候)进行记录,每个 block 都会记录开始时间及结束时间
if (tid == 0) time[bid] = clock();
//thread需要同时通过tid和bid来确定,同时不要忘记保证内存连续性
for (i = bid * THREAD_NUM + tid; i < DATA_SIZE; i += BLOCK_NUM * THREAD_NUM) {
shared[tid] += num[i] * num[i] * num[i];
}
//同步 保证每个 thread 都已经把结果写到 shared[tid] 里面
__syncthreads();
//使用线程0完成加和
if(tid == 0)
{
for(i = 1; i < THREAD_NUM; i++)
{
shared[0] += shared[i];
}
result[bid] = shared[0];
}
//计算时间的动作,只在 thread 0(即 threadIdx.x = 0 的时候)进行,每个 block 都会记录开始时间及结束时间
if (tid == 0) time[bid + BLOCK_NUM] = clock();
}
由于我们每个block中的计算结果已经在GPU里加和了,所以我们就不需要原来这么大的空间来保存运算结果了,result的长度只需更改为block数就好了:
cudaMalloc((void**)&result, sizeof(int)* BLOCK_NUM);
然后大家应该还记得在调用核函数的时候有一项是share memory,现在这个参数也需要改,我们一共需要的sharememory是thread数*int:
sumOfSquares << < BLOCK_NUM, THREAD_NUM, THREAD_NUM * sizeof(int) >> >(gpudata, result, time);最后从显存复制回内存的部分和CPU加和部分也需要修改(由于result长度的改变),不过我们现在只需要在CPU上把32个数加起来就可以了~:
/*把结果从显示芯片复制回主内存*/
int sum[BLOCK_NUM];
clock_t time_use[BLOCK_NUM * 2];
//cudaMemcpy 将结果从显存中复制回内存
cudaMemcpy(&sum, result, sizeof(int)*BLOCK_NUM, cudaMemcpyDeviceToHost);
cudaMemcpy(&time_use, time, sizeof(clock_t)* BLOCK_NUM * 2, cudaMemcpyDeviceToHost);
//Free
cudaFree(gpudata);
cudaFree(result);
cudaFree(time);
int final_sum = 0;
for (int i = 0; i < BLOCK_NUM; i++) {
final_sum += sum[i];
}完整程序:
#include >>(参数...);
sumOfSquares << < BLOCK_NUM, THREAD_NUM, THREAD_NUM * sizeof(int) >> >(gpudata, result, time);
/*把结果从显示芯片复制回主内存*/
int sum[BLOCK_NUM];
clock_t time_use[BLOCK_NUM * 2];
//cudaMemcpy 将结果从显存中复制回内存
cudaMemcpy(&sum, result, sizeof(int)*BLOCK_NUM, cudaMemcpyDeviceToHost);
cudaMemcpy(&time_use, time, sizeof(clock_t)* BLOCK_NUM * 2, cudaMemcpyDeviceToHost);
//Free
cudaFree(gpudata);
cudaFree(result);
cudaFree(time);
int final_sum = 0;
for (int i = 0; i < BLOCK_NUM; i++) {
final_sum += sum[i];
}
//采取新的计时策略 把每个 block 最早的开始时间,和最晚的结束时间相减,取得总运行时间
clock_t min_start, max_end;
min_start = time_use[0];
max_end = time_use[BLOCK_NUM];
for (int i = 1; i < BLOCK_NUM; i++) {
if (min_start > time_use[i])
min_start = time_use[i];
if (max_end < time_use[i + BLOCK_NUM])
max_end = time_use[i + BLOCK_NUM];
}
printf("GPUsum: %d gputime: %d\n", final_sum, max_end - min_start);
final_sum = 0;
for (int i = 0; i < DATA_SIZE; i++) {
final_sum += data[i] * data[i] * data[i];
}
printf("CPUsum: %d \n", final_sum);
return 0;
}运行结果:
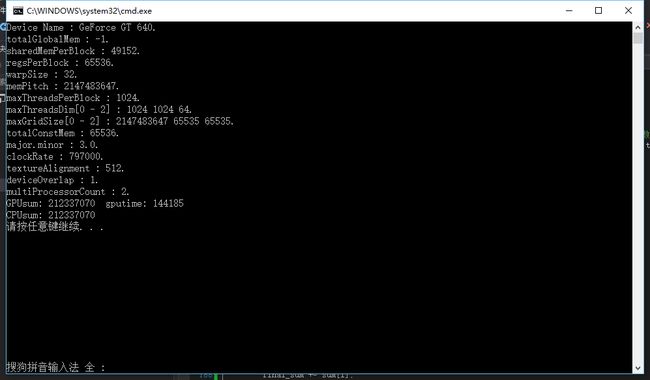
我们看到,结果没什么问题,不过比起上次133133个周期的运行时间,这次144185个周期显然有所变长,原因也很明显,因为我们在 GPU 上多做了一些动作,但是好的结果是这个时候我们的CPU只需要加和32个数字了,同时我们还减少了需要拷贝到内存的数据量。
我们看到效率有所降低,不过其实效率变差的一个原因是我们最后加总的操作只由每个block的Thread0来完成,这显然不是最有效率的方法。在下篇博客中我们会通过并行加法的算法来解决这个问题。
总结:
这篇博客我们主要介绍了ShareMemory和Thread同步,并利用这些知识解决了大量线程计算结果加和的压力,我们完成了block内Thread结果的加和,最终留给CPU的工作只剩下了32次加法,不过我们block的加和工作是使用一个thread0单线程完成的,这点还是有待改进的,所以接下来将会并行这个加法过程。
希望我的博客能帮助到大家~
参考资料:《深入浅出谈CUDA》