【Tensorflow】Tensorflow中的卷积函数(conv2d、slim.conv2d、depthwise_conv2d、conv2d_transpose)
【fishing-pan:https://blog.csdn.net/u013921430 转载请注明出处】
前言
卷积是卷积神经网络中最主要、最重要的运算。想必大家最早接触卷积的概念就是在初高中的数学当中,它是一个这样的公式;
( g ∗ h ) ( x ) = ∫ − ∞ ∞ g ( τ ) ⋅ h ( x − τ ) d τ (g\ast h)(x)=\int_{-\infty }^{\infty }g(\tau )\cdot h(x-\tau )d\tau (g∗h)(x)=∫−∞∞g(τ)⋅h(x−τ)dτ
上面的公式是一维空间中连续函数的卷积,而在图像处理中,卷积操作是二维平面上的离散卷积;卷积的过程可以表示为下方的式子,式子中的 k e r n e l ( i , j ) kernel(i,j) kernel(i,j) 表示卷积核的坐标为 ( i , j ) (i,j) (i,j) 处的权重, H H H 与 W W W 分别表示卷积核的高与宽。
o u t p u t ( x , y ) = ∑ i = 0 i = H − 1 ∑ j = 0 j = W − 1 i n p u t ( x + i , y + j ) ⋅ k e r n e l ( i , j ) output(x,y)=\sum_{i=0}^{i=H-1}\sum_{j=0}^{j=W-1}input(x+i,y+j)\cdot kernel(i,j) output(x,y)=i=0∑i=H−1j=0∑j=W−1input(x+i,y+j)⋅kernel(i,j)
详细的计算过程可以模拟为下方的gif图中的形式。(图片来源链接)
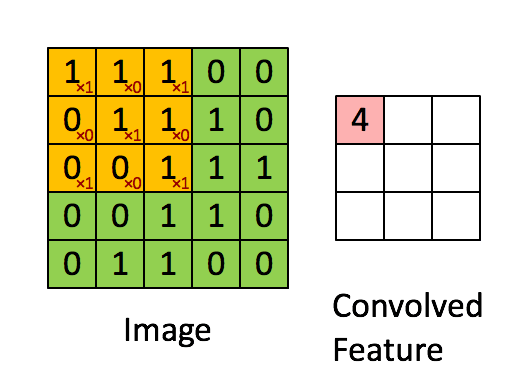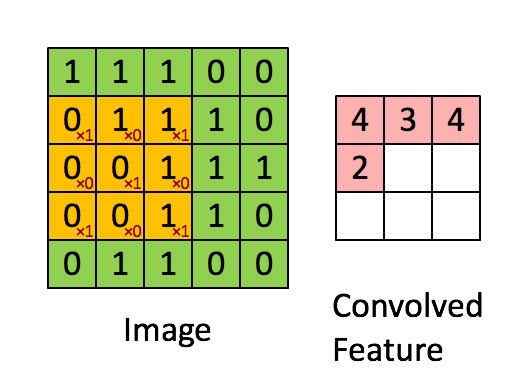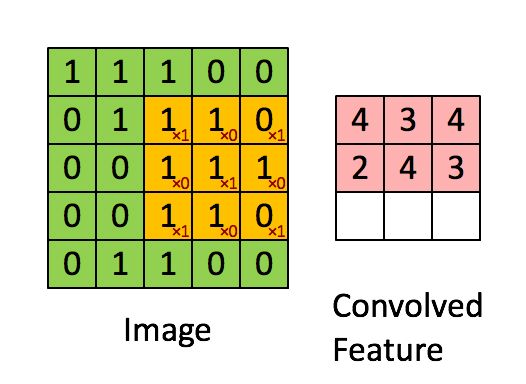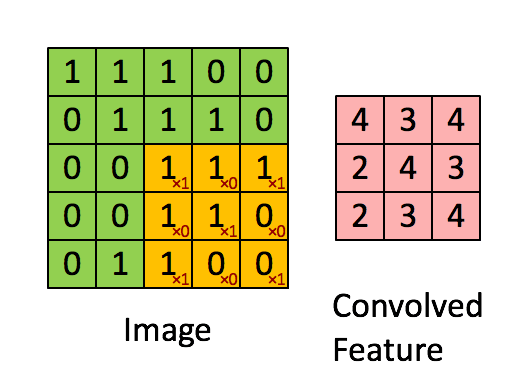
Tensorflow中的卷积函数到底做了些什么
上面的简单介绍主要是为了让大家了解卷积的操作过程。下面将进入正题,介绍一下tf中的卷积函数。本文将着重介绍tf.nn.conv2d函数,余下的函数主要分析他们之间的区别。
tf.nn.conv2d
这应该是tensorflow构建网络模型时最常用的卷积函数了,他的定义如下;
conv2d(input, filter, strides, padding, use_cudnn_on_gpu=True,
data_format="NHWC", dilations=[1, 1, 1, 1], name=None):
参数中带有默认值的一般不需要管,我们这里就不详细介绍了,大家想了解的可以自行查看函数定义。接下来详细介绍一下四个主要的参数:input, filter, strides, padding
input:输入的tensor,被卷积的图像,conv2d要求input必须是四维的。四个维度分别为[batch, in_height, in_width, in_channels],即batch size,输入图像的高和宽以及单张图像的通道数。
filter:卷积核,也要求是四维,[filter_height, filter_width, in_channels, out_channels]四个维度分别表示卷积核的高、宽,输入图像的通道数和卷积输出通道数。其中in_channels大小需要与 input 的in_channels一致。
strides:步长,即卷积核在与图像做卷积的过程中每次移动的距离,一般定义为[1,stride_h,stride_w,1],stride_h与stride_w分别表示在高的方向和宽的方向的移动的步长,第一个1表示在batch上移动的步长,最后一个1表示在通道维度移动的步长,而目前tensorflow规定:strides[0] = strides[3] = 1,即不允许跳过bacth和通道,前面的动态图中的stride_h与stride_w均为1。
padding:边缘处理方式,值为“SAME” 和 “VALID”,熟悉图像卷积操作的朋友应该都熟悉这两种模式;由于卷积核是有尺寸的,当卷积核移动到边缘时,卷积核中的部分元素没有对应的像素值与之匹配。此时选择“SAME”模式,则在对应的位置补零,继续完成卷积运算,在strides为[1,1,1,1]的情况下,卷积操作前后图像尺寸不变即为“SAME”。若选择 “VALID”模式,则在边缘处不进行卷积运算,若运算后图像的尺寸会变小。
首先分别定义输入图像与卷积核。为了方便分析,将输入图像的batch size设为1,图像尺寸为10x10,通道数为3。卷积核尺寸为[5,5,3,4]。进行卷积操作,然后输出卷积结果的尺寸。
input_img=tf.Variable(tf.constant(10,dtype=tf.float32,shape=[1,10,10,3])) #定义输入图像
W1=tf.Variable(tf.truncated_normal([5,5,3,4],stddev=0.1)) #定义卷积核
conv1=tf.nn.conv2d(input_img,W1,strides=[1,2,2,1],padding='SAME') #卷积操作
init=tf.global_variables_initializer()
with tf.Session() as sess:
sess.run(init)
print('conv1 shape is:',sess.run(tf.shape(conv1)))
可想而知,conv1的尺寸是[1 5 5 4],因为在定义卷积核的时候就明确说明卷积核的第四个维度为输出通道数。那么问题来了,conv1中的每个元素的值是如何确定的呢?问得好。
从表面上来看,我们只定义了一个卷积核W1,“他”将图像从3通道变成了4通道,就像下面这个过程。
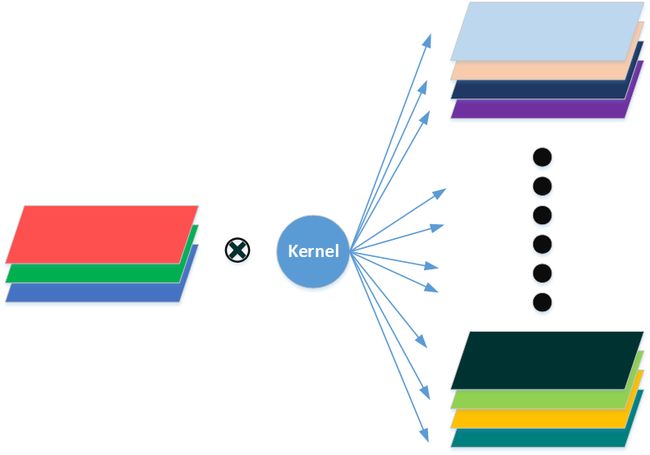
但是实际上并不是这样, W 1 W1 W1不是一个卷积核,而是表示一个包含c个卷积核的卷积层。conv2d函数卷积的过程可以表示成下面的公式;其中 i i i、 j j j表示像素点的位置, d i di di、 d j dj dj表示卷积核中元素的相对位置, q q q 表示输入通道序号, c c c 表示输出通道数。
c o n v 1 [ b , i , j , c ] = ∑ d i , d j , q i n p u t [ b , s t r i d e s [ 1 ] ∗ i + d i , s t r i d e s [ 2 ] ∗ j + d j , q ] ∗ W 1 [ d i , d j , q , c ] conv1[b, i, j, c]=\sum_{di,dj,q}^{ }input[b, strides[1] * i + di, strides[2] * j + dj, q] *W_{1}[di, dj, q, c] conv1[b,i,j,c]=di,dj,q∑input[b,strides[1]∗i+di,strides[2]∗j+dj,q]∗W1[di,dj,q,c]
从公式中可以看出,卷积核的前三个维度形成一个三维的卷积核,与输入图像做卷积,最终得到一个单通道的输出(这个过程可以简单理解为,把三个通道的特征压缩到了一个通道上);而卷积核的第四个维度 c c c 对应着输出的每一个通道,其实 c c c 表示的是有多少个这样的卷积核。其过程可以简化成下图;
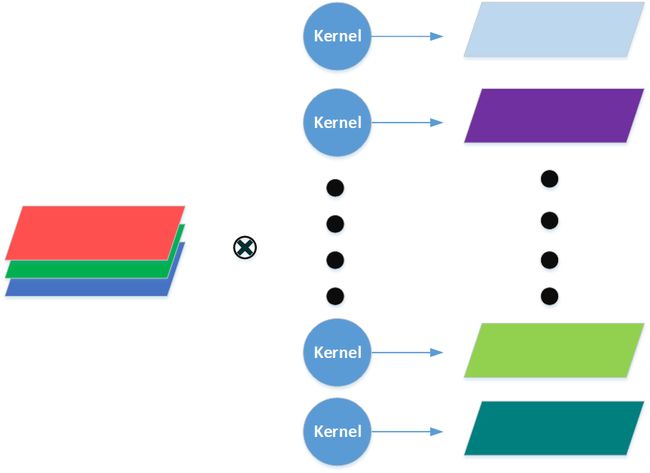
经过上述描述,想必大家也都明白了为何卷积核的第三个维度要是输入图像的通道数。
tf.contrib.slim.conv2d
另一个常见的卷积函数是 tf.contrib.slim.conv2d,他的卷积过程与tf.nn.conv2d一致,其函数名和参数定义如下。
convolution(inputs,num_outputs,kernel_size,stride=1,padding='SAME',data_format=None,
rate=1,activation_fn=nn.relu,normalizer_fn=None,normalizer_params=None,weights_initializer=initializers.xavier_initializer(),
weights_regularizer=None,biases_initializer=init_ops.zeros_initializer(),biases_regularizer=None,
reuse=None,variables_collections=None,outputs_collections=None,trainable=True,cope=None):
其中的参数很多,就不一一介绍了,主要的参数依然是inputs,num_outputs,kernel_size,stride,padding。使用slim.conv2d函数进行卷积操作,不需要单独定义卷积层,激活函数,甚至是偏置。
input_img=tf.Variable(tf.constant(10,dtype=tf.float32,shape=[1,10,10,3]))#定义输入图像
W1=tf.Variable(tf.truncated_normal([5,5,3,4],stddev=0.1))#定义卷积核
conv1=tf.nn.conv2d(input_img,W1,strides=[1,2,2,1],padding='SAME')
relu1=tf.nn.relu(conv1)
conv4=slim.conv2d(input_imgg,4,[5,5],strides=2,padding='SAME')
在上方的代码中第6行与2至4行所执行的功能是一致的。而代码量却小了很多。因此在构建网络层数较多的网络时,使用slim.conv2d以及slim库中的其他功能可以使模型的构建,训练,测试都变得更加简单。
tf.nn.depthwise_conv2d
tf.nn.depthwise_conv2d的意思是深度二维卷积,他的定义如下。
depthwise_conv2d(input,filter,strides, padding,
rate=None,name=None, data_format=None):
与tf.nn.conv2d一样,他的主要参数也是input, filter, strides, padding,他与tf.nn.conv2d的区别在于filter的不同。在depthwise_conv2d中filter的四个维度分别为[filter_height, filter_width, in_channels, channel_multiplier],其第四个维度不再是输出通道数,而是通道倍数,最终输出的总的通道数为 i n c h a n n e l s ∗ c h a n n e l m u l t i p l i e r in channels*channel multiplier inchannels∗channelmultiplier,因为此时分通道进行卷积与输出,不再卷积结果合并成单通道,明白了这个道理,函数的卷积过程就好理解了。可以用以下的公式表示;
c o n v 1 [ b , i , j , c ∗ m u l t i + q ] = ∑ d i , d j i n p u t [ b , s t r i d e s [ 1 ] ∗ i + d i , s t r i d e s [ 2 ] ∗ j + d j , c ] ∗ W 1 [ d i , d j , c , q ] conv1[b, i, j, c*multi + q]=\sum_{di,dj}^{ }input[b, strides[1] * i + di, strides[2] * j + dj, c] *W_{1}[di, dj, c, q] conv1[b,i,j,c∗multi+q]=di,dj∑input[b,strides[1]∗i+di,strides[2]∗j+dj,c]∗W1[di,dj,c,q]
而卷积过程可以表示为下图所示的形式。
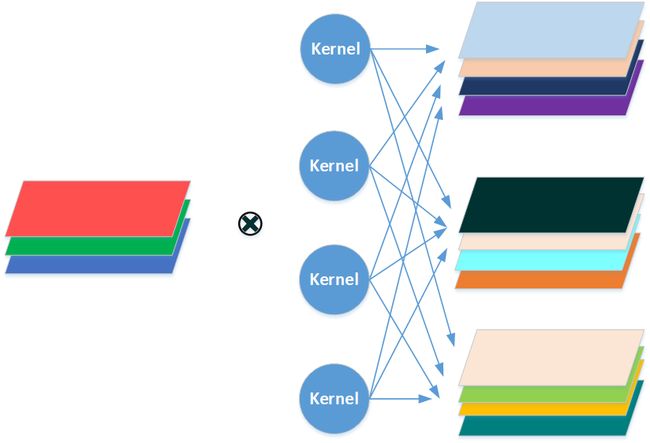
这里可以验证一下上述过程。使用同样的输入与卷积核,分别用不同的卷积方式做卷积,并且对depthwise_conv2d卷积的输出的第一个、第五个、第九个通道对应位置的元素求和,与conv2d卷积第一通道的结果对比,看看有什么差异。
import tensorflow as tf
input_img=tf.Variable(tf.constant(10,dtype=tf.float32,shape=[1,10,10,3]))#定义输入图像
W1=tf.Variable(tf.truncated_normal([5,5,3,4],stddev=0.1))#定义卷积核
conv1=tf.nn.conv2d(input_img,W1,strides=[1,2,2,1],padding='SAME')
conv2=tf.nn.depthwise_conv2d(input_img,W1,strides=[1,2,2,1],padding='SAME')
conv2_1=conv2[:,:,:,0]
conv2_2=conv2[:,:,:,4]
conv2_3=conv2[:,:,:,8]
conv2_sum123=tf.add(tf.add(conv2_1,conv2_2),conv2_3)
init=tf.global_variables_initializer()
with tf.Session() as sess:
sess.run(init)
print('conv1 shape is:',sess.run(tf.shape(conv1)))
print('conv2 shape is:',sess.run(tf.shape(conv2)))
# print('conv2d sum:',sess.run(tf.reduce_sum(conv1,axis=3)))
# print('depthwise_conv2d sum:',sess.run(tf.reduce_sum(conv2,axis=3)))
print(sess.run(conv2_sum123))
print(sess.run(conv1[:,:,:,0]))
最终输出如下:

从求和结果可以看出,两者基本一致。也证明了depthwise_conv2d的计算输出是未进行通道求和之前的conv2d函数的计算结果。
tf.nn.conv2d_transpose
tf.nn.conv2d_transpose是反卷积函数,进行的是卷积的反向操作,一般应用于上采样过程,其定义如下;
conv2d_transpose(value,filter, output_shape,strides,
padding="SAME",data_format="NHWC",name=None):
value:指需要做反卷积的输入图像,与之前的一样,要求是一个四维的tensor。
filter:卷积核,要求是一个四维tensor,与之前的卷积核不同,其四个维度分别是[filter_height, filter_width, out_channels, in_channels],注意输入通道数与输出通道数的位置改变了
output_shape:反卷积操作输出tensor的shape,之前的卷积中是没有这个参数的。
strides:反卷积时在图像每一维上的步长
此处output_shape并不能取任意的尺寸,应该根据输入图像尺寸、卷积核尺寸以及正向卷积的过程,反推出尺寸大小。例如,下面的代码中output_shape有两个错误,第一个是输出图像的长宽不匹配,第二个就是输出通道数为5与卷积核的输出通道数3不匹配。
import tensorflow as tf
input_img=tf.Variable(tf.constant(10,dtype=tf.float32,shape=[1,10,10,3]))#定义输入图像
W1=tf.Variable(tf.truncated_normal([5,5,3,4],stddev=0.1))#定义卷积核
conv1=tf.nn.conv2d(input_img,W1,strides=[1,2,2,1],padding='SAME')
conv3=tf.nn.conv2d_transpose(conv1,W1,[1,15,15,5],strides=[1,2,2,1],padding='SAME')
init=tf.global_variables_initializer()
with tf.Session() as sess:
sess.run(init)
print('conv1 shape is:',sess.run(tf.shape(conv1)))
print('conv3 shape is:',sess.run(tf.shape(conv3)))
print(sess.run(conv3[:,:,:,0]))
反卷积的过程就不展开了,感兴趣的可以自行查找资料学习。
参考
最后,向大家推荐一个对卷积详细描述的网站(链接)。
已完。。