SVM中的训练算法:序列最小最优化算法SMO的读书笔记
最近重看李航的统计学习方法,看SVM这章,细细的对了一下其中将SMO的这一张,记得去年这会儿看这本书的SMO这章还有点懵懵懂懂,并在书上写了自己一些疑问的笔记,今年重新看发现之前的疑问不再是疑问了,于是做个笔记总结一下,总结一下。
首先线性可分支持向量机的构建条件是需要线性可分的。与感知机不同的是,SVM还加了一个约束:最大间隔。因此与感知机只考虑误分类点的损失函数不同,SVM是唯一存在的。而感知机是有多个解的。(下图为感知机的形式)
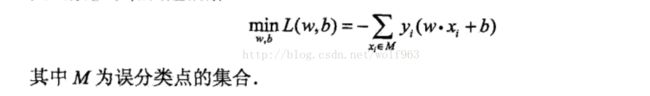
线性SVM的原始问题描述如下:

该问题的对偶问题描述如下:

其中的alpha为对应样本点的拉格朗日系数。
因为这里我们关注的是SMO算法的推导过程,因此对偶问题的描述的具体推导过程,可参考李航的《统计学习方法》。在此不展开细讲。
看到这里不知你是否跟我当初看书的时候有同样的疑问,那就是上面这个描述中只有alpha,难道不能用再用一次拉格朗日方程,然后对alpha求导,这样不是就可以直接用梯度下降法了吗?
答案是不行的:因为上面的问题描述不符合拉格朗日对偶性中构建拉格朗日方程的条件,条件3是有上下限的(下图为拉格朗日对偶性的原始问题)

那么SVM本身能不能够利用梯度下降法来求解呢?
答案是:可以的。
因为线性SVM本身是等价于合页损失函数+最小化的二阶范数的(如下图)
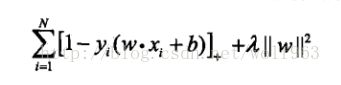
式子中的+表示的是

顺便说一下,上面损失函数的第一项意味着,当SVM的函数间隔>1 的时候,损失才为0,否则损失为
1-y(w*x+b),这意味着SVM对于正确划分的要求更加高。
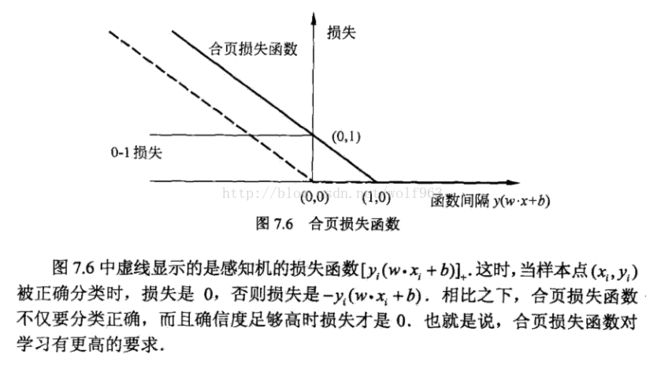
这里再贴一下书中关于感知机,SVM和0-1损失的比较,来说明上面的SVM对于正确划分的要求更加高这个问题。
再说回SVM是否可以用梯度下降法来求解呢?看之前的损失函数形式(下图)
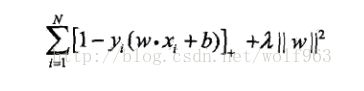
这里面只有w,没有约束,然后求解的是使该式子最小的w,那么当然可以用梯度下降法了。
具体的求解方法,不在这里详细叙述有兴趣的童鞋可以看一下,下面这篇blog,连接如下:
http://blog.csdn.net/sinat_27612639/article/details/70037499
再回到正题SMO,在正式讲解SMO之前,我觉得还需要介绍一下其他的关于SVM的求解优化算法,这样有助于理解SMO是怎样来的,增加理解SMO这个算法。
我这里贴一段看的一篇关于SVM的论文综述的一部分。(论文:支持向量机理论与算法研究综述,丁世飞,齐丙娟,谭红艳)
SVM训练算法有三大类:块算法(chunking algorithm);分解算法(decomposition algorithm);增量算法(incremental algorithm)
1.块算法:
Chunking算法
[10]的出发点是删除矩阵中对应Lagrange乘数为零的行和列将不会影响最终的结
果。对于给定的样本, Chunking算法的目标是通过某种迭代方式逐步排除非支持向量,从而降低训练过程对存储器容量的要求。具体做法是,将一个大型QP问题分解为一系列较小规模的QP问题, 然后找到所有非零的Lagrange乘数并删除。在算法的每步中Chunking都解决一个QP问题,其样本为上一步所剩的具有非零Lagrange乘数的样本以及M个不满足KKT条件的最差样本。如果在某一步中,不满足KKT条件的样本数不足M个,则这些样本全部加入到新的QP问题中。每个QP子问题都采用上一个QP子问题的结果作为初始值。在算法进行到最后一步时,所有非零Lagrange乘数都被找到,从而解决了初始的大型QP问题。Chunking算法将矩阵规模从训练样本数的平方减少到具有非零Lagrange乘数的样本数的平方,在很大程度上降低了训练过程对存储容量的要求。Chunking算法能够大大提高训练速度,尤其是当支持向量的数目远远小于训练样本的数目时。然而,如果支持向量个数比较多,随着算法迭代次数的增多,所选的块也会越来越大,算法的训练速度依旧会变得十分缓慢。
2.分解算法(decomposition algorithm)
分解算法最早在文献[11]中提出, 是目前有效解决大规模问题的主要方法。分解算法将二次规划问题分解成一系列规模较小的二次规划子问题,进行迭代求解。在每次迭代中,选取拉格朗日乘子分量的一个子集做为工作集,利用传统优化算法求解一个二次规划的子问题。以分类SVM为例,分解算法的主要思想是将训练样本分成工作集B和非工作集N,工作集B中的样本个数为 q , q 远小于训练样本总数。每次只针对工作集B中的样本进行训练,而固定N中的训练样本。该算法的关键在于选择一种最优工作集选择算法,而在工作集的选取中采用了随机的方法,因此限制了算法的收敛速度。文献[12]在分解算法的基础上对工作集的选择做了重要改进。采用类似可行方向法的策略确定工作集B。如果存在不满足KTT条件的样本,利用最速下降法,在最速下降方向中存在 q 个样本,然后以这 q 个样本构成工作集, 在该工作集上解决QP问题,直到所有样本满足KTT条件。如此改进提高了分解算法的收敛速度,并且实现了SVM
light算法。文 献 [13] 提 出 的 序 列 最 小 优 化 (sequential minimal optimization, SMO)算法是分解算法的一个特例,工作集中只有2个样本,其优点是针对2个样本的二次规划问题可以有解析解的形式,从而避免多样本情况下的数值解不稳定及耗时问题,且不需要大的矩阵存储空间,特别适合稀疏样本。工作集的选择不是传统的最陡下降法,而是启发式。通过两个嵌套的循环寻找待优化的样本,然后在内环中选择另一个样本,完成一次优化,再循环,进行下一次优化,直到全部样本都满足最优条件。 SMO算法主要耗时在最优条件的判断上,所以应寻找最合理即计算代价最低的最优条件判别式。SMO算法提出后,许多学者对其进行了有效的改进。文献[14]提出了在内循环中每次优化3个变量,因为3个变量的优化问题同样可以解析求解, 实验表明该算法比SMO的训练时间更短。文献[15-16]在迭代过程中的判优条件和循环策略上做了一定的修改,加快了算法的速度。
3.增量算法(incremental algorithm)
增量学习是机器学习系统在处理新增样本时,能够只对原学习结果中与新样本有关的部分进行增加修改或删除操作,与之无关的部分则不被触及。增量训练算法的一个突出特点是支持向量机的学习不是一次离线进行的,而是一个数据逐一加入反复优化的过程。文献[17]最早提出了SVM增量训练算法,每次只选一小批常规二次算法能处理的数据作为增量,保留原样本中的支持向量和新增样本混合训练,直到训练样本用完。文献[18]提出了增量训练的精确解 , 即 增 加 一 个 训 练 样 本 或 减 少 一 个 样 本 对Lagrange系数和支持向量的影响。文献[19]提出了另一种增量式学习方法,其思想是基于高斯核的局部特性,只更新对学习机器输出影响最大的Lagrange系数,以减少计算复杂度。文献[20]提出了一种“快速增量学习算法”, 该算法依据边界向量不一定是支持向量,但支持向量一定是边界向量的原理,首先选择那些可能成为支持向量的边界向量,进行SVM的增量学习,找出支持向量,最终求出最优分类面,提高训练速度。文献[21]提出了基于中心距离比值的增量运动向量机,利用中心距离比值,在保证训练和测试准确率没有改变的情况下,提高收敛速度。文献[22]提出了基于壳向量的线性SVM增量学习算法,通过初始样本集求得壳向量,进行SVM训练,得到支持向量集降低二次规划过程的复杂度,提高整个算法的训练速度和分类精度。
其中统计学习方法中讲到的的SMO算法是属于分解算法。
下面来讲解什么是SMO算法,书上是这样说的:

这里需要需要注意的是:

具体来说:

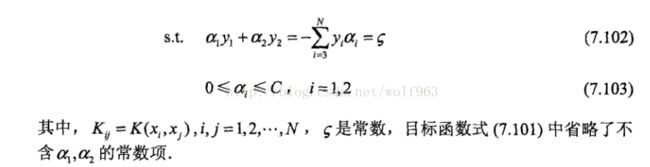
基本就是上面式子的展开,没什么东西,注意这里Kij = k(xi,xj)是核函数,因此kij =kji,这是核函数的定义来的。
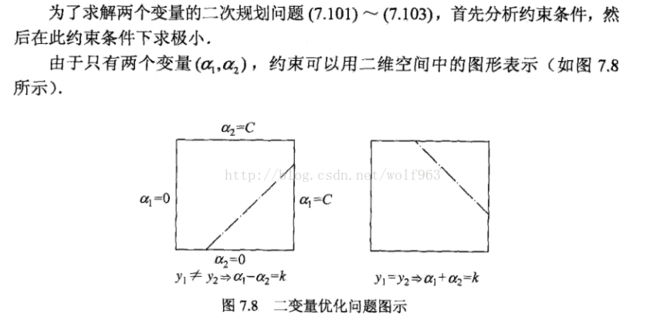
看到这里不知道大家是不是跟我当初第一次看一样,有点懵为什么y1!=y2 => alpha1-alpha2=k;y1=y2 => alpha1 + alpha2 = k; 因为对于二分类问题来说(y 为 +1, -1),y1 != y2 那么就是 y1/y2 = -1 ,当y1 = y2 那么 y1/y2 = 1。所以才有了上面的图中的式子。

对于这里的L,H 的确定,不知大家有没有想清楚,首先L,H是alpha2的上下界,因此如下图所示。

那么对于y1 != y2 则 alpha2 = alpha1 - k; k = alpha1 - alpha2
y1 = y2 则 alpha 2 = k - alpha1; k = alpha1 + alpha2
带入对应的极值点 alpha1 = 0 或C的时候,就得到了,上面的L,H 上下界的关系了。


这个定理李航书上几乎手把手的教你证明了,感觉大家可以跟着书上推一遍,应该就比较能理解整个过程了。这里就不粘贴过来,因为书确实将的比较细致了。


不知道你是不是跟我一样比较疑惑,什么叫KKT违反最严重的点?我想应该是该样本点带入yi*g(xi)后与1的差最大的点吧。

这里其实就是外层alpha1定了,那么内层alpha2应该也就定了的意思。只是有些特殊情况下目标函数不能产生足够的下降,所以才会启发式的选择alpha2,直到拥有足够的下降。如果一直找不到就更换外层循环的alpha1,这也是为什么这个方法称之为启发式的算法的原因:有规则,但也不完全遵从规则。


我们可以看到,在更细Ei 的时候,我们只需要更行对应的支持向量即可。
最后:

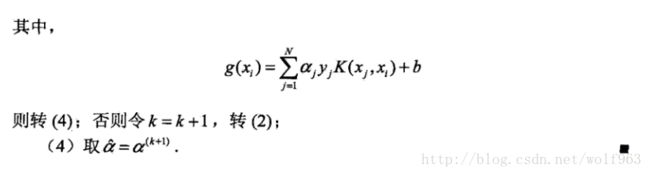
参考文献:
《统计学习方法》李航
http://blog.csdn.net/sinat_27612639/article/details/70037499
[10] BOSER B E, GUYON I M, VAPNIK V N. A training algorithm for optimal margin classifiers[C]//Proceedings of The Fifth Annual Workshop on Computational Learning Theory. New York: ACM Press, 1992: 144-152.
[11] OSUNA E, FRENUD R, GIROSI F. An improved training algorithm for support vector machines[C] Proceedings of IEEE Workshop on Neural Networks for Signal Processing.New York, USA: [s.n.], 1997: 276-285.
[12] JOACHIMS T. Making large-scale support vector machine learning practical[C]//Advances in Kernel Methods:Support Vector Learning. Cambridge, MA: The MIT Press,1998.
[13] PLATT J. Fast training of support vector machines using sequential minimal optimization[C] dvances in Kernel Methods: Support Vector Learning. Cambridge, MA: The MIT Press, 1998.
[14] DAI Liu-ling, HUANG He-yan, CHEN Zhao-xiong.Ternary sequential analytic optimization algorithm for SVM classifier design[J]. Asian Journal of Information Technology, 2005, 4(3): 2-8.
[15] KEERTHI S S, SHEVADE S K, BHATTAEHARYYA C. Improvements to platt's SMO algorithm for SVM classifier design[J]. Neural Computation, 2001, 13(3): 637- 649.
[16] PLATT J. Using analytic QP and sparseness to speed training support vector machines[C] Advances in Neural Information Processing Systems. [S.l]: MIT Press, 1999,557-563.
[17] SYED N, LIU H, SUNG K. Incremental learning with support vector machines[C] International Joint Conference on Artificial Intelligence. Sweden: Morgan kaufmann publishers, 1999: 352-356.
[18] GAUWENBERGHS G, POGGIO T. Incremental and decremental support vector machine[J]. Machine Learning.2001, 44 (13): 409- 415.
[19] RALAIVOLA L, FLORENCE D’ALCHÉ-BUC.Incremental support vector machine learning: a local approach[C] Proceedings of International Conference on Neural Networks. Vienna, Austria: [s.n.], 2001: 322-330.
[20] 孔锐, 张冰. 一种快速支持向量机增量学习算法[J]. 控制与决策, 2005, 20(1): 1129- 1132.
KONG Rui, ZHANG Bing. A fast incremental learning algorithm for support vector machine[J]. Control And Decision, 2005, 20(1): 1129- 1132.
[21] 孔波, 刘小茂, 张钧. 基于中心距离比值的增量支持向量机[J]. 计算机应用, 2006, 26(6): 1434-1436.KONG Bo, LIU Xiao-mao, ZHANG Jun. Incremental support vector machine based on center distance ratio[J].Journal of Computer Applications, 2006, 26(6): 1434-1436.
[22] 李东晖, 杜树新, 吴铁军. 基于壳向量的线性支持向量机快速增量学习算法[J]. 浙江大学学报, 2006, 40(2):202- 215.