用于视觉问答的基于关系推理和注意力的多峰特征融合模型《Multimodal feature fusion by relational reasoning and attention for VQA》
目录
一、文献摘要介绍
二、网络框架介绍
三、实验分析
四、结论
这是视觉问答论文阅读的系列笔记之一,本文有点长,请耐心阅读,定会有收货。如有不足,随时欢迎交流和探讨。
一、文献摘要介绍
The recently emerged research of Visual Question Answering (VQA) has become a hot topic in computer vision. A key solution to VQA exists in how to fuse multimodal features extracted from image and question. In this paper, we show that combining visual relationship and attention together achieves more fine-grained feature fusion. Specifically, we design an effective and efficient module to reason complex relationship between visual objects. In addition, a bilinear attention module is learned for question guided attention on visual objects, which allows us to obtain more discriminative visual features. Given an image and a question in natural language, our VQA model learns visual relational reasoning network and attention network in parallel to fuse fifine-grained textual and visual features, so that answers can be predicted accurately. Experimental results show that our approach achieves new state-of-the-art performance of single model on both VQA 1.0 and VQA 2.0 datasets.
最近出现的视觉问题解答(VQA)研究已经成为计算机视觉中的热门话题。 VQA的关键解决方案在于如何融合从图像和问题中提取的多峰特征。 在本文中,表明将视觉关系和注意力结合在一起可以实现更细粒度的特征融合。 具体来说,作者设计了一个有效的模块来推理视觉对象之间的复杂关系。 另外,学习了一个双线性注意力模块,用于对视觉对象进行问题指导的注意力,这使我们能够获得更具区分性的视觉特征。 给定自然语言中的图像和问题,作者的VQA模型并行学习视觉关系推理网络和注意力网络,以融合细粒度的文本和视觉特征,从而可以准确地预测答案。 实验结果表明,该方法在VQA 1.0和VQA 2.0数据集上均实现了单个模型的最新性能。
二、网络框架介绍
如图2所示,我们的完整VQA模型以问题、由自底向上注意生成的检测框为输入,通过视觉关系推理和视觉注意获得细粒度特征,从而推断出正确答案,模型由五个主要部分组成:(1)图像建模。 输入图像由自下而上的注意处理,该方法基于Faster R-CNN框架中的ResNet CNN,获得了K个图像区域的视觉特征。 (2)问题嵌入。输入问题被修剪为最多14个单词,每个单词都被转换成一个带有单词嵌入的向量表示。 然后将这些向量传递到门控循环单元(GRU),使用最终的隐藏状态作为问题的表示。(3)视觉关系推理模块,用于对检测到的图像区域推荐之间的关系进行推理,以获得关系视觉特征。(4)视觉注意模块在问题指导下对检测到的图像区域推荐分配权重,以获取视觉特征。 (5)最后,学习由深度神经网络组成的多标签分类器,以推断出正确的答案。 视觉关系推理模块和视觉注意模块是即插即用的,我们可以通过将它们并行组合来获得细粒度的特征融合,下面进行详细分析。
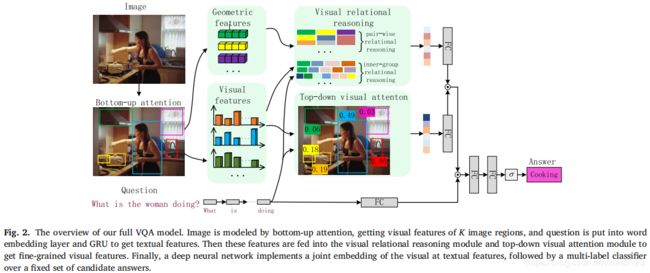
2.1. Image modelling
采用Faster R-CNN框架在输入图像中获取对象检测框。 然后,对每个对象区域执行非最大抑制,并选择排名靠前的K个检测框(通常为= 36)。 对于每个选定区域推荐  ,
, 被定义为该区域的平均池卷积特征,因此输入图像最终表示为
被定义为该区域的平均池卷积特征,因此输入图像最终表示为![]()
Faster R-CNN以这种方式使用,是一种“硬”注意机制,因为可以从大量可能的配置中选择相对较少的图像区域。此外,还记录了选定图像区域的缩放几何特征,记为![]() ,其中
,其中![]() 。
。 ![]() 和
和![]() 分别是所选区域
分别是所选区域  的坐标,宽度和高度。
的坐标,宽度和高度。 和
和 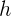 分别是输入图像的宽度和高度,这些缩放的几何特征将被输入到我们的视觉关系推理模块中。
分别是输入图像的宽度和高度,这些缩放的几何特征将被输入到我们的视觉关系推理模块中。
2.2. Question embedding
首先将每个输入问题  修剪为最多14个单词以提高计算效率(VQA数据集中只有约0.25%的问题长于14个单词。简单地丢弃长度超过14个单词的问题的多余单词,而长度小于14个单词的问题则以零向量结尾填充)。然后,对问题进行标记,并通过使用预训练的GloVe词嵌入初始化的词嵌入层将每个词转换为300维向量。 单词嵌入的结果序列依次通过其隐藏状态为
修剪为最多14个单词以提高计算效率(VQA数据集中只有约0.25%的问题长于14个单词。简单地丢弃长度超过14个单词的问题的多余单词,而长度小于14个单词的问题则以零向量结尾填充)。然后,对问题进行标记,并通过使用预训练的GloVe词嵌入初始化的词嵌入层将每个词转换为300维向量。 单词嵌入的结果序列依次通过其隐藏状态为 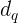 维的GRU。 我们使用最终的隐藏状态
维的GRU。 我们使用最终的隐藏状态![]() 作为输入问题 的表示。
作为输入问题 的表示。
2.3Visual relational reasoning module
关系推理模型受Santoro A 2017 等人 的启发,如图3所示,作者提出的视觉关系推理模块由四部分组成:降维,成对组合,成对关系推理和内部组关系推理。给定输入图像的K个图像区域的视觉特征![]() 和几何特征
和几何特征![]() ,并伴随问题表示
,并伴随问题表示![]() ,我们的视觉关系推理模块旨在查找图像区域之间的视觉关系并生成输入图像的关系视觉特征。
,我们的视觉关系推理模块旨在查找图像区域之间的视觉关系并生成输入图像的关系视觉特征。
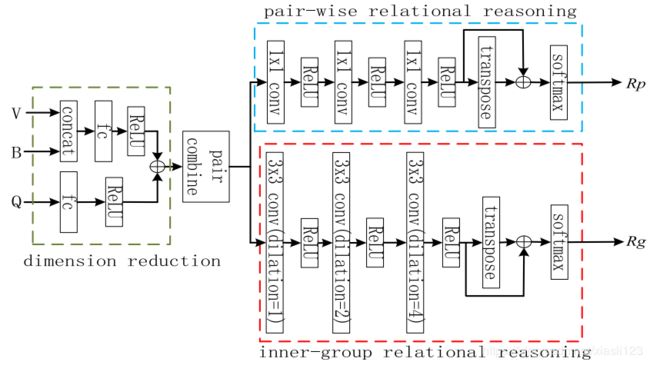

在我们的视觉关系推理模块中,视觉特征和几何特征被连接在一起生成图像区域表示,表示为:![]() 。为了减少以下操作的内存使用,将图像区域表示和问题特征非线性地投影到一个低维子空间中,其中我们将问题特征嵌入到图像区域表示中,如下所示:
。为了减少以下操作的内存使用,将图像区域表示和问题特征非线性地投影到一个低维子空间中,其中我们将问题特征嵌入到图像区域表示中,如下所示:
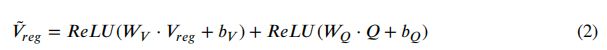
其中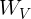 和
和![]() 是可学习的权重,
是可学习的权重,![]() 和
和![]() 是偏差。
是偏差。![]() ,其中
,其中 ![]() 是子空间的维数,
是子空间的维数,![]() 是图像区域 的表示,该图像区域结合了视觉特征,几何特征和问题特征。
是图像区域 的表示,该图像区域结合了视觉特征,几何特征和问题特征。
在视觉关系推理模块中,成对组合的目的是将所有的图像区域表示成对地组合起来,对组合的计算公式可写为:

其中![]() 返回在第一个位置插入的尺寸为1的张量,而
返回在第一个位置插入的尺寸为1的张量,而![]() 操作将沿新插入的尺寸重复张量K次。因此,我们得到了所有图像区域的对组合,表示为
操作将沿新插入的尺寸重复张量K次。因此,我们得到了所有图像区域的对组合,表示为![]() 。
。
受Santoro A 2017 等人的启发,我们提出的视觉关系推理模块通过约束神经网络的功能形式来捕捉图像区域之间的关系,就像CNNs内置了对空间、平移不变性属性进行推理的能力一样。与Santoro A 2017 等人不同的是,我们不仅挖掘了成对视觉关系,而且还分析了图像区域之间的内部群体视觉关系。为了达到这个目的,我们设计了两个并行的CNN流,一个具有多个1×1卷积层用于推理成对关系 ![]() ,另一个具有扩展卷积层用于推理内部群关系
,另一个具有扩展卷积层用于推理内部群关系 ![]() 。如图3中绿色虚线框所示,我们通过在成对
。如图3中绿色虚线框所示,我们通过在成对![]() 上建立三个1×1卷积层,每个卷积层后接一个ReLU激活层来推理成对关系。第一,第二和第三卷积层产生的通道数分别为
上建立三个1×1卷积层,每个卷积层后接一个ReLU激活层来推理成对关系。第一,第二和第三卷积层产生的通道数分别为![]() 和1,因此最后一个卷积层的输出和ReLU激活为
和1,因此最后一个卷积层的输出和ReLU激活为![]() 。最后,我们应用softmax生成成对关系:
。最后,我们应用softmax生成成对关系:
![]()
其中![]() 和
和![]() 均表示图像区域 和
均表示图像区域 和  之间的关系。为了使
之间的关系。为了使![]() 成为对称矩阵,我们对
成为对称矩阵,我们对![]() 及其转置之和应用softmax。
及其转置之和应用softmax。
上面的1×1卷积层流只能找到成对关系,内部群体关系是另一种重要的视觉关系,解决内部群关系的一种简单方法是设计n×n卷积层。这种层的感受野大小与网络的深度成线性关系。换句话说,更大的感受野需要更多的卷积层,这可能需要更多的数据来训练和更多的计算消耗。因此,在这里,我们的解决方案是采用能够产生指数级大的感受野的放大卷积。如图3中红色虚线框所示,我们在对组合![]() 的顶部构建了三个3×3的扩展卷积层,每个扩展卷积层后面跟着ReLU激活层,图4示出了三个扩张的卷积。
的顶部构建了三个3×3的扩展卷积层,每个扩展卷积层后面跟着ReLU激活层,图4示出了三个扩张的卷积。
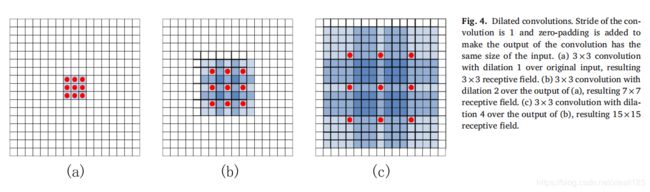
三个卷积的扩张分别为1、2和4。所有卷积的步幅为1,并且使用零填充来使每个卷积的输出具有相同的输入大小。最后,我们将Softmax应用于最后一个卷积的输出,表示为![]() ,产生内部群体关系:
,产生内部群体关系:

值得注意的是,矩阵![]() 的每个元素都捕获了所有图像区域之间的关系,因为卷积的感受野为15×15,这大于图像区域的总数。给定以上成对关系和内部组关系,可以将每个图像区域的视觉特征更新为:
的每个元素都捕获了所有图像区域之间的关系,因为卷积的感受野为15×15,这大于图像区域的总数。给定以上成对关系和内部组关系,可以将每个图像区域的视觉特征更新为:

因此,每个图像区域的表示就是该区域及其相关区域的融合。 最后,整个图像的关系视觉表示可以是所有图像区域特征的总和![]()
![]() 。
。
2.4.Top-down visual attention module
给定图像区域的视觉特征![]() 和问题特征
和问题特征![]() ,最简单的多峰双线性模型定义如下:
,最简单的多峰双线性模型定义如下:
![]()
其中,![]() 是投影矩阵,偏置项被省略,因为它隐含在
是投影矩阵,偏置项被省略,因为它隐含在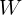 中。尽管双线性模型可以有效地捕获特征维之间的成对相互作用,但它也会引入大量参数,这可能导致高计算成本和过拟合的风险。Pirsiavash等 提出了一种低秩双线性模型,通过用两个较小的矩阵
中。尽管双线性模型可以有效地捕获特征维之间的成对相互作用,但它也会引入大量参数,这可能导致高计算成本和过拟合的风险。Pirsiavash等 提出了一种低秩双线性模型,通过用两个较小的矩阵![]() 替换
替换 ![]() ,以减少双线性模型中的参数数量,其中
,以减少双线性模型中的参数数量,其中![]() ,
,![]()
![]()
其中![]() 是1的向量,∘表示逐元素相乘。
是1的向量,∘表示逐元素相乘。
现在我们要得到类似于公式(9)的注意力图。图像区域 的参与权重 ![]() 可以计算如下:
可以计算如下:

为了减少参数,对所有图像区域使用相同的投影矩阵![]() 和
和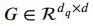 。 因此,等式(10)中的
。 因此,等式(10)中的 ![]() 为:
为:
![]()
其中,![]() 是可学习的向量。最后,图像中所有区域的参与特征表示
是可学习的向量。最后,图像中所有区域的参与特征表示![]() 可以是所有区域视觉特征的加权和:
可以是所有区域视觉特征的加权和:
![]()
其中,是注意力图。
2.5.Answer prediction
在计算了关系视觉特征表示![]() 和注意力特征表示
和注意力特征表示![]() 之后,我们现在将这两个视觉特征和问题表示融合如下:
之后,我们现在将这两个视觉特征和问题表示融合如下:
![]()
或者
![]()
其中,![]() 和
和![]() 是可学习的权重矩阵,偏差项在不失一般性的情况下被省略。
是可学习的权重矩阵,偏差项在不失一般性的情况下被省略。![]() 是融合向量的维数。
是融合向量的维数。
给定图像和问题的融合表示,我们现在可以使用简单的两层MLP(在其隐藏层中具有ReLU非线性)来计算答案 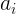 的概率:
的概率:
![]()
选择所有候选答案集中概率最大的答案作为最终预测。 因此,我们使用二进制交叉熵损失函数对预测进行惩罚。
三、实验分析
对于VQA 1.0和VQA 2.0数据集,我们使用Adamax解算器,![]() = 0.9,
= 0.9,![]() = 0.999,使用逐步预热,这意味着将第一个训练时期的学习率设置为0.001,将第二个训练时期的学习率设置为0.002,将第三个训练时期的学习率设置为0.003。 然后,我们将学习率保持到第十个循环,此后学习率每2个循环衰减一次。 还使用了梯度裁剪技术,批处理大小设置为512。为防止过度拟合,在每个全连接的层之后使用了丢弃率。 对于编码问题,每个单词都嵌入大小为300的向量中,GRU的隐藏状态设置为1024。
= 0.999,使用逐步预热,这意味着将第一个训练时期的学习率设置为0.001,将第二个训练时期的学习率设置为0.002,将第三个训练时期的学习率设置为0.003。 然后,我们将学习率保持到第十个循环,此后学习率每2个循环衰减一次。 还使用了梯度裁剪技术,批处理大小设置为512。为防止过度拟合,在每个全连接的层之后使用了丢弃率。 对于编码问题,每个单词都嵌入大小为300的向量中,GRU的隐藏状态设置为1024。
表1 使用开放式任务(VQA 2.0)的val拆分对模型的每个模块和超参数进行消融研究
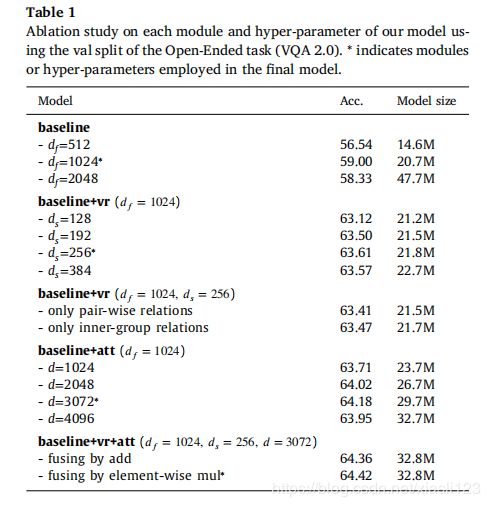
图5.VQA模型的训练损失和验证准确性与历时的关系。
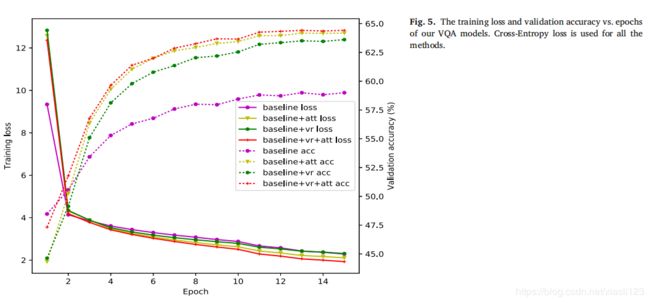
表2 模型的性能与最先进的方法在VQA1.0上的比较。

表3 模型的性能与最先进的方法在VQA2.0上的比较。

表4 模型的性能与最先进的方法在CLEVR上的比较。

图6.VQA实例。

四、结论
In this paper, we design a visual relational reasoning module,which is an effective and efficient network module to reason complex relationship between visual objects. In addition, a bilinear attention module is also learned for question guided attention on visual objects, which allows us to obtain more discriminative visual features. Based on these two modules, we design a VQA model. Given an image and a question in natural language, our model parallelly learns visual relational reasoning network and attention network to get and fuse fine-grained textual and visual features, and answer can be predicted accurately. The experimental results on VQA 1.0, VQA 2.0, and CLEVR datasets confirm the effectiveness of the proposed modules and the full VQA model.
Recently, visual question answering has been extended to the video domain . Video-based QA is often recognized as a more challenging task than image-based one, because video-based QA models must extract spatio-temporal information from videos and learn to answer questions according to the complex visual content of the videos. Our VQA model in this work learns to reason visual relations on images for image-based QA task. How to extend our model to address video-based QA task deserves extensive exploration and will become one of our future work.
本文设计了一种视觉关系推理模块,该模块是一种有效,高效的网络模块,用于推理视觉对象之间的复杂关系。此外,还学习了一个双线性注意力模块,用于对视觉对象进行问题指导的注意力,这使能够获得更具区分性的视觉特征。基于这两个模块,作者设计了一个VQA模型。给定自然语言中的图像和问题,该模型并行学习视觉关系推理网络和注意力网络,以获取和融合细粒度的文本和视觉特征,并可以准确地预测答案。在VQA 1.0,VQA 2.0和CLEVR数据集上的实验结果证实了所提出模块和完整VQA模型的有效性。
最近,视觉问答已经扩展到视频领域。与基于图像的质量检查相比,基于视频的质量检查通常被认为是更具挑战性的任务,因为基于视频的质量检查模型必须从视频中提取时空信息,并学会根据视频的复杂视觉内容来回答问题。作者在这项工作中的VQA模型学习了推理图像上的视觉关系以进行基于图像的QA任务。如何扩展该模型以解决基于视频的质量检查任务值得广泛探索,并将成为未来的工作之一。