再谈SVM(hard-margin和soft-margin详细推导、KKT条件、核技巧)
前言:大概一个月前,通过李宏毅的机器学习系列视频,我自学了一点SVM,整理在:机器学习之SVM(Hinge Loss+Kernel Trick)原理推导与解析。最近,由于实验室组织了机器学习的暑期训练营,训练营的模式是每个模块让一个人负责自学,然后讲给大家听,由于当时的无知。。。。我选择了SVM,后来发现想要把SVM讲给别人听懂真的很难,于是到处找资料又自学了一遍,现整理如下:
再谈SVM
- 1.概述
- 2.间隔
- 2.1硬间隔(最大间隔分类器)
- 2.1.1模型定义
- 2.1.2约束
- 2.1.2.1函数间隔
- 2.1.2.2定义距离
- 2.1.3原问题
- 2.1.4拉格朗日乘数法
- 2.1.5强对偶与弱对偶
- 2.1.6求解最终问题
- 2.1.7KKT条件
- 2.1.8最终解答
- 2.2软间隔
- 2.2.1原问题
- 2.2.2拉格朗日乘数法
- 2.2.3强对偶转换
- 2.2.4求解最终问题
- 2.2.5KKT条件
- 2.2.6最终解答
- 3.核技巧(kernel trick)
- 参考文献
1.概述
俗话说,SVM有三宝:间隔、对偶、核技巧。这句话概括了SVM最精髓的三个部分,下面内容将围绕上述三个关键词展开。我们先来定义数据集: ( x 1 , y 1 ) , ( x 2 , y 2 ) , ( x 3 , y 3 ) . . . ( x N , y N ) {(x_{1},y_{1}),(x_{2},y_{2}),(x_{3},y_{3})...(x_{N},y_{N})} (x1,y1),(x2,y2),(x3,y3)...(xN,yN),每一个 y i ∈ ( 1 , − 1 ) y_{i}\in(1,-1) yi∈(1,−1),代表两个不同的类别。
2.间隔

假设每一个样本X都是一个二维列向量,那么对于数据集分类,无非就是找到一条直线(二维平面是就是直线,三维可以理解为一个平面,该平面也叫超平面),该直线可以把两类样本数据完全隔开。
2.1硬间隔(最大间隔分类器)
硬间隔,也叫最大间隔分类器。那么顾名思义,我们找到的那一条分类直线要尽可能地远离两边的样本点。为什么要尽量远离?因为你离得越近,比如说刚好有一些点在分界线上,那么就容易产生噪声。(这里的解释可能需要再次改进)
2.1.1模型定义
![]()
sign函数长这样:

当 w T x + b > = 0 w^Tx+b>=0 wTx+b>=0时, f ( w , b ) f(w,b) f(w,b)取+1,否则取-1。因此分界线可以定义为:
![]()
这样,分界线的一边样本点满足 w T x + b > 0 w^Tx+b>0 wTx+b>0,另一边满足 w T x + b < 0 w^Tx+b<0 wTx+b<0,对应的 f ( w , b ) f(w,b) f(w,b)一个为+1,一个为-1,就达到了分类效果。
我们可以猜测,能够将所有样本点分成两类的直线(二维平面上)往往不止一条,如下图所示:

那么哪一条才是最好的呢?答案就是中间那条红色的直线,它具备更强的“鲁棒性”,泛化能力更强。
2.1.2约束
于是我们的目标就很明确了,我们需要找到一条直线,使得它距离两边的样本点越远越好。
2.1.2.1函数间隔
在机器学习之SVM(Hinge Loss+Kernel Trick)原理推导与解析中,我们讲解了很多损失函数,先回顾一下:
在下面的问题中loss代表每一个样本的损失,Loss代表总的损失。
首先我们需要回顾一下前面所学的二分类问题:假设有一批样本, x 1 x^1 x1, x 2 x^2 x2, x 3 x^3 x3,…, x n x^n xn,对应的label分别是: y 1 ^ y\hat{1} y1^, y 2 ^ y\hat{2} y2^, y 3 ^ y\hat{3} y3^,…, y n ^ y\hat{n} yn^, y i ^ y\hat{i} yi^(i=1,2,…,n)有两个取值,-1和1,则Binary Classfication:
if f(x)>0,output=1,属于一个class
if(f(x)<0),output=-1,属于另一个class
在二分类问题中loss function的定义有很多种,其中最理想的loss function定义为:

即若分类正确loss=0,否则loss等于1,那么在这里Loss可以理解分类器在训练集上犯错误的次数。but如果Loss这样定义,是不能求微分的,所以我们换了一种方式,即:

我们以 y n ^ f ( x ) y\hat{n}f(x) yn^f(x)作为横轴,loss作为纵轴,从二分类的定义来看,当f(x)>0时,output=1,即 y n ^ = 1 y\hat{n}=1 yn^=1时,f(x)是越大越好的,同理,当 y n ^ = − 1 y\hat{n}=-1 yn^=−1时,f(x)是越小越好。 因此,当 y n ^ f ( x ) y\hat{n}f(x) yn^f(x)越大时,loss会越小。 这是我们判断一个loss function好坏的标准。
针对上面这个表达式,我们有以下几种情况可以讨论(加上ideal loss):
-
ideal loss
定义:
这个loss比较好理解,可以直接画出图像:

如图中黑线所示,当 y n ^ f ( x ) y\hat{n}f(x) yn^f(x)>0时,表面分类正确,loss=0,否则等于1。从其图像我们也可以看出,loss是不能进行Gradient Descent的。 -
Square loss
Square loss是用使用MSE来衡量误差,若output=1时,f(x)应该尽量接近1而当output=-1时,f(x)又应该尽量接近于-1,只有这样Square loss才能最小。因此我们可以定义 l ( f ( x n , y n ^ ) ) l(f(x^{n},y\hat{n})) l(f(xn,yn^)):

可以看出,该表达式是满足MSE定义的,我们画出 ( x − 1 ) ² (x-1)² (x−1)²的图像,如下所图红线示:
前面我们讨论过,当 y n ^ f ( x ) y\hat{n}f(x) yn^f(x)越大时,loss应当会越小。 但是Square loss显然是不符合情况的,这里也可以进一步解释前面我们为什么说不能用Square loss来作为损失函数。 -
Sigmoid+Square loss
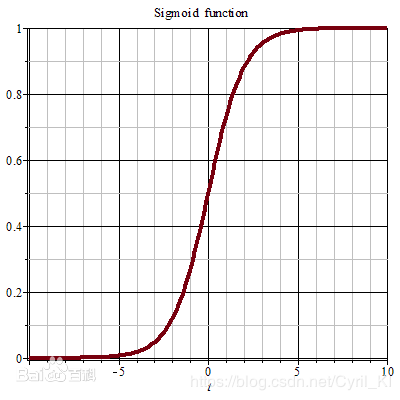
Sigmoid函数值域介于01之间,因此当output=1时, σ ( f ( x n ) ) \sigma (f(x^{n})) σ(f(xn))应该尽量接近1,而当output=-1时, σ ( f ( x n ) ) \sigma (f(x^{n})) σ(f(xn))又应该接近于0,因为其本质还是Square loss,只不过把输出映射到了01之间,因此,我们可以定义 l ( f ( x n , y n ^ ) ) : l(f(x^{n},y\hat{n})): l(f(xn,yn^)):

同样画出图像:
从目前来看,该损失函数好像挺合理的,但仔细一想又是不对的。该函数的渐近线是y=1,越往左loss是越大的,但是其斜率是越来越小的。在Gradient Descent中,如果一个位置的loss太大那么它应该更加快速的下降以找到最优解,但是上述函数不符合要求,loss越大下降反而越慢,属于典型的“没有回报,不想努力。” -
Sigmoid+Cross entropy
在逻辑回归中我们最终选择了交叉熵的形式,这里定义 l ( f ( x n , y n ^ ) ) : l(f(x^{n},y\hat{n})): l(f(xn,yn^)):

画出图像:
可以看出,从左到右符合下降的趋势,并且相较与Sigmoid+Square loss,Sigmoid+Cross entropy的loss越大,其梯度越大,情况符合“有回报有努力。” -
Hinge loss
l ( f ( x n , y n ^ ) ) l(f(x^{n},y\hat{n})) l(f(xn,yn^))定义为:

从表达式可以看出,当 y n ^ = 1 y\hat{n}=1 yn^=1时, f ( x n ) > 1 f(x^{n})>1 f(xn)>1则loss=0;当 y n ^ = − 1 y\hat{n}=-1 yn^=−1时, f ( x n ) < − 1 f(x^{n})<-1 f(xn)<−1则loss=0。
同样画出图像:

比较Hinge loss和Sigmoid+Cross entropy,比如说我们把黑点从1移动到2,可以发现Sigmoid+Cross entropy其实是可以做得更好的,而Hinge loss只要是 y n ^ f ( x ) y\hat{n}f(x) yn^f(x)大于它的阈值,无论怎么调整loss都不会变。但是当我们有outlier也就是异常值的时候,Hinge loss会给出比Cross entropy更好的结果。
通过上述讨论我们不难发现,我们在画损失函数图像时,是以 y n ^ f ( x ) y\hat{n}f(x) yn^f(x)作为横轴的,之所以选择 y n ^ f ( x ) y\hat{n}f(x) yn^f(x)作为横轴,是因为我们知道,当 y n ^ f ( x ) y\hat{n}f(x) yn^f(x)越大时损失应当越小才对,这一理论可以帮我们比较多个loss function之间的优劣。
回到硬间隔问题,我们知道若 y i y_{i} yi与 w T x + b w^Tx+b wTx+b同号,则表示我们的模型分类正确,否则分类错误。根据这一理论,我们引出了函数间隔的定义:
![]() 函数间隔大于0表示分类正确,否则分类错误。
函数间隔大于0表示分类正确,否则分类错误。
此外我们定义超平面(w,b)中关于T中所有样本点 ( x i , y i ) (x_{i},y_{i}) (xi,yi)的函数间隔的最小值,便为超平面(w,b)关于训练数据集的函数间隔:
![]()
2.1.2.2定义距离
我们要求分类直线 w T x + b = 0 w^Tx+b=0 wTx+b=0除了能够完美分开所有样本点,我们还要求它尽可能地远离它两端的样本点。 这里的远离指的是欧氏距离,因此,我们可以先定义点到直线的距离为:

点到直线的公式小学生都会写,这里就不再过多地讲解。
另外,我们再定义一个最小的距离,其实也就是上面提到的超平面关于训练集的函数间隔:

现在我们的目标就是最大化 m a r g i n ( w , b ) margin(w,b) margin(w,b),为什么是这样?因为我们最终的目标是使得直线尽可能的远离所有样本点,也就是距离足够大,我们让最小距离都达到最大,那么自然而然直线到所有样本点的距离就已经是最大了。
因此,硬间隔的约束条件为:在分类正确的前提下,分类直线尽可能地远离两边的样本点, 表达式如下:

将 d i s t a n c e ( w , b , x i ) distance(w,b,x_{i}) distance(w,b,xi)的表达式代入即为:

因此,硬间隔(最大间隔分类器)其实就是解决上面这个优化问题。
2.1.3原问题
我们观察上面那个那个优化问题的描述, 1 ∥ w ∥ \frac{1}{\parallel w\parallel } ∥w∥1对求解最右边表达式的最小值没有影响,那么实际上,我们可以将 1 ∥ w ∥ \frac{1}{\parallel w\parallel } ∥w∥1提到 m i n min min的前面去,变成:

另外我们再考虑一点, y i y_{i} yi的取值只有+1,-1,而且 y i y_{i} yi与 w T x i + b w^Tx_{i}+b wTxi+b同号,因此我们可以进一步将上面优化问题中最右边的绝对值去掉,然后在前面乘上 y i y_{i} yi,这样它还是表达了绝对值的意思:

好巧不巧, 1 ∥ w ∥ \frac{1}{\parallel w\parallel } ∥w∥1右边那部分不就是我们上面定义的超平面关于训练集的函数间隔么。我们不妨令函数间隔就为1,也即是: γ ^ = 1 \gamma\hat{}=1 γ^=1。
这里我们之所以要令 γ ^ = 1 \gamma\hat{}=1 γ^=1,是为了方便推导和优化,那凭什么我们又可以令 γ ^ = 1 \gamma\hat{}=1 γ^=1?
(重点)
这里我们可以这样想:超平面的方程是 w T x + b = 0 w^Tx+b=0 wTx+b=0,假设我们让 w 和 b w和b w和b同时乘上2,那么超平面的方程会变成 2 w T x + 2 b = 0 2w^Tx+2b=0 2wTx+2b=0,这跟原始的超平面方程是一样的。但是超平面虽然没变,函数间隔 y ( w T x + b ) y(w^Tx+b) y(wTx+b)却变成了原来的两倍,因此只要保证w和b是同样倍数变化,那么超平面是不会变的。我们要求解的是一组w和b,你 γ ^ = 1 \gamma\hat{}=1 γ^=1求出了 w 1 和 b 1 w_{1}和b_{1} w1和b1, γ ^ = 10 \gamma\hat{}=10 γ^=10求出了 w 10 和 b 10 w_{10}和b_{10} w10和b10, γ ^ = 100 \gamma\hat{}=100 γ^=100求出了 w 100 和 b 100 w_{100}和b_{100} w100和b100,但是三组w和b组成的超平面是一回事,我们要求的东西是一回事,那么我们何不就直接令函数间隔 γ ^ = 1 \gamma\hat{}=1 γ^=1呢,反正无论是多少最后求出的超平面都是一回事,令 γ ^ = 1 \gamma\hat{}=1 γ^=1还能方便运算呢。
因此最终硬间隔就变成了:

而我们又知道: ∥ w ∥ = w 1 2 + w 2 2 + . . . + w N 2 \parallel w\parallel =\sqrt{w_{1}^{2}+w_{2}^{2}+...+w_{N}^{2}} ∥w∥=w12+w22+...+wN2,我们要maximise 1 ∥ w ∥ \frac{1}{\parallel w\parallel } ∥w∥1,其实也就是minimise ∥ w ∥ \parallel w\parallel ∥w∥,那实际上也就是minimise ∥ w ∥ 2 \parallel w\parallel^2 ∥w∥2,前面乘上1/2(也是为了方便推导)也不影响,最终我们要minimise的其实就是 1 2 w T w \frac{1}{2}w^{T}w 21wTw,因此有:

我们称上述这个问题为原问题。
2.1.4拉格朗日乘数法
在数学最优问题中,拉格朗日乘数法(以数学家约瑟夫·路易斯·拉格朗日命名)是一种寻找变量受一个或多个条件所限制的多元函数的极值的方法。这种方法将一个有n 个变量与k 个约束条件的最优化问题转换为一个有n + k个变量的方程组的极值问题,其变量不受任何约束。这种方法引入了一种新的标量未知数,即拉格朗日乘数:约束方程的梯度(gradient)的线性组合里每个向量的系数。此方法的证明牵涉到偏微分,全微分或链法,从而找到能让设出的隐函数的微分为零的未知数的值。
原问题的变量w和b是受到约束的,即 y ( w T x + b ) > = 1 y(w^Tx+b)>=1 y(wTx+b)>=1,为了让要求的变量不受约束,我们引入了拉格朗日乘数法,根据其思想,我们令:

然后原问题就从有约束变成了无约束:

我们称上述问题为无约束问题。
2.1.5强对偶与弱对偶
由于本人数学知识不太够,这里只是能够做一些大概的解释,敬请见谅。
我们还是先引入无约束问题:
我们交换min与max的位置,变成:

我们称上述问题为无约束问题的对偶问题。
一般地,我们有:
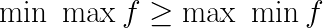
这种性质我们称为弱对偶性,若取等号就称为强对偶性。弱对偶性该怎么理解呢?这里参考了网上一位大佬的“证明”方法:凤尾>=鸡头。何谓“凤尾”?我先选出最强的一批人( max f \max f maxf),然后组成实验班,实验班倒数第一就是 min max f \min \ \max f min maxf;何谓“鸡头”?我先选出最弱的一批人( min f \min f minf),然后在这批比较弱的人当中选出最强的那个人,也即是 max min f \max \ \min f max minf,那么“鸡头”与“凤尾”孰强孰弱,是显而易见的。
而我们认为无约束问题是满足强对偶性的(暂不证明),也就是说,强间隔问题经过原问题->无约束问题->强对偶问题三个步骤转换(这个过程是等价的),我们最终要求的是:
我们暂且称上述问题为硬间隔最终问题。
2.1.6求解最终问题
我们先求最右边L的最小值。我们知道:
我们先让L对b求偏导:

然后我们将 ∑ i = 1 N λ i y i = 0 \sum_{i=1}^{N}\lambda_{i}y_{i}=0 ∑i=1Nλiyi=0代入到 L ( w , b , λ ) L(w,b,\lambda) L(w,b,λ)中得到:

接着我们让L对w求导得到:

我们再将w的值代入到 L ( w , b , λ ) L(w,b,\lambda) L(w,b,λ)中,可以得到:

于是我们将最终问题:
转换成了:

第二个条件是通过L对b求导得到的。
通常我们喜欢求解minimise问题,因此我们继续转化:

2.1.7KKT条件
先直接给出KKT条件:

KKT条件的意义:它是一个非线性规划(Nonlinear Programming)问题能有最优化解法的必要和充分条件。我们暂时只需要知道,有KKT条件,我们可以直接得到上面四个表达式。
有关KKT条件以及强弱对偶性的证明可以参考:强对偶性、弱对偶性以及KKT条件的证明(对偶问题的几何证明)
2.1.8最终解答
不要忘记我们前面所做的一切都是为了求解超平面方程中的w和b。 w ∗ w* w∗在L对w求导时我们就已经得到了: w ∗ = ∑ i = 1 N λ i y i x i w*=\sum_{i=1}^{N}\lambda_{i}y_{i}x_{i} w∗=∑i=1Nλiyixi,接下来我们要来求b*,求解b*,我们需要用到KKT条件中的松弛互补条件,也就是第二个条件:
λ i ( 1 − y i ( w T x + b ) ) = 0 \lambda_{i}(1-y_{i}(w^Tx+b))=0 λi(1−yi(wTx+b))=0

对于超平面 w T x + b = 1 和 w T x + b = − 1 w^Tx+b=1和w^Tx+b=-1 wTx+b=1和wTx+b=−1, w T x + b = 1 w^Tx+b=1 wTx+b=1平面左上方的样本点都满足 w T x + b > 1 w^Tx+b>1 wTx+b>1,而 w T x + b = − 1 w^Tx+b=-1 wTx+b=−1平面右下方的样本点都满足 w T x + b < − 1 w^Tx+b<-1 wTx+b<−1,所以,以上两个区域中的样本点都满足 1 − y i ( w T x i + b ) < 0 1-y_{i}(w^Tx_{i}+b)<0 1−yi(wTxi+b)<0,只有两个平面上的点才满足 1 − y i ( w T x i + b ) = 0 1-y_{i}(w^Tx_{i}+b)=0 1−yi(wTxi+b)=0
根据KKT条件:
第二条松弛互补条件,因为乘积为0,右边部分又不为0,所以以上两个区域的 λ = 0 \lambda=0 λ=0。
因为我们知道 w ∗ = ∑ i = 1 N λ i y i x i w*=\sum_{i=1}^{N}\lambda_{i}y_{i}x_{i} w∗=∑i=1Nλiyixi,只有两个超平面上的样本点的 λ \lambda λ才对最终求得的w有影响,因此我们又称上述平面上的样本点为Support Vector(支持向量)。
我们任取一个支持向量 ( x k , y k ) (x_{k},y_{k}) (xk,yk),我们知道,支持向量满足: 1 − y k ( w T x k + b ) = 0 1-y_{k}(w^Tx_{k}+b)= 0 1−yk(wTxk+b)=0,那么继续推导:

因此最终我们可以得到:

因此最终的超平面方程以及决策函数分别为:

至此,我们暂时解决了硬间隔问题。
2.2软间隔
前面硬间隔我们要求:存在一个超平面 w T x + b = 0 w^Tx+b=0 wTx+b=0能够将空间里所有样本点完美地分割成两部分,且我们要求超平面距离它两边样本点的距离越远越好。但在现实生活中,很多时候我们都不能找到一个完美的超平面来将所有样本点完全分开。
因此,我们引入松弛变量,允许模型分割边界附近有一些样本点不满足约束,如下所示:

同时我们也希望出错的样本越少越好,所以松弛变量也有限制。引入了松弛变量的margin我们称之为软间隔。
在机器学习之SVM(Hinge Loss+Kernel Trick)原理推导与解析中,我们说线性SVM与逻辑回归的区别就是损失函数的不同,如果使用Hinge loss就是线性SVM,使用Cross entropy就是逻辑回归。Hinge loss我们前面已经介绍过了,并且在线性SVM的另一种表述中,我们把Hinge loss又称为松弛因子。
2.2.1原问题
我们先来看看硬间隔的原问题:
我们加上松弛因子之后:

这里的C>0称为惩罚参数,一般由应用问题决定,C值大时对误分类的惩罚增加,C值小时对误分类的惩罚尽量小。 这句话该怎么理解呢?
我们知道硬间隔原问题要求间隔尽可能的大,而我们又知道,只有在支持向量上的样本点才满足 1 − y i ( w T x i + b ) = 0 1-y_{i}(w^Tx_{i}+b)=0 1−yi(wTxi+b)=0,其它时候都是小于0的,因此,只有支持向量上的样本点,我们在hinge loss上取值才是0,其他时候都是一个小于0的数,我们minimise hinge loss,即是要求分类失误的样本点尽量小,只有这样hinge loss才会小。
我们引入一个变量 ε i = 1 − y i ( w T x i + b ) \varepsilon_{i}=1-y_{i}(w^Tx_{i}+b) εi=1−yi(wTxi+b),我们假设 ε i ≥ 0 \varepsilon_{i}\geq 0 εi≥0,那么上述问题就可以转化为:

我们称该问题为软间隔的原问题。上述这个转化过程该怎么理解呢?优化目标函数应该很好理解,因为我们引入 ε i = 1 − y i ( w T x i + b ) \varepsilon_{i}=1-y_{i}(w^Tx_{i}+b) εi=1−yi(wTxi+b),并且我们假设 ε i ≥ 0 \varepsilon_{i}\geq 0 εi≥0,那么 ε i = 1 − y i ( w T x i + b ) \varepsilon_{i}=1-y_{i}(w^Tx_{i}+b) εi=1−yi(wTxi+b)与0取max就变成了 ε i = 1 − y i ( w T x i + b ) \varepsilon_{i}=1-y_{i}(w^Tx_{i}+b) εi=1−yi(wTxi+b)。重点是怎么理解约束条件的变化,我们不妨这样理解:

这里注意上图的上下标跟本文是相反的。我们引入了 ε i = 1 − y i ( w T x i + b ) \varepsilon_{i}=1-y_{i}(w^Tx_{i}+b) εi=1−yi(wTxi+b),并且我们假设 ε i ≥ 0 \varepsilon_{i}\geq 0 εi≥0,那么实际上 ε i = max ( 0 , 1 − y i ( w T x i + b ) ) \varepsilon_{i}=\max(0,1-y_{i}(w^Tx_{i}+b)) εi=max(0,1−yi(wTxi+b)),这点很好理解吧。现在我们要最小化上述的损失函数,也就是最小化 ε i \varepsilon_{i} εi,而实际上 ε i \varepsilon_{i} εi的最小值就是 max ( 0 , 1 − y i ( w T x i + b ) ) \max(0,1-y_{i}(w^Tx_{i}+b)) max(0,1−yi(wTxi+b)),所以我们有 ε i ≥ 1 − y i ( w T x i + b ) \varepsilon_{i}\geq 1-y_{i}(w^Tx_{i}+b) εi≥1−yi(wTxi+b),即 y i ( w T x i + b ) ≥ 1 − ε i y_{i}(w^Tx_{i}+b)\geq 1-\varepsilon_{i} yi(wTxi+b)≥1−εi,证毕。
因此,软间隔要解决的问题其实就是:
解决思路与上述硬间隔一模一样,先用拉格朗日乘数法转化为无约束问题,然后再转化为对偶问题最后求导求解。暂时先不讲具体过程吧。
2.2.2拉格朗日乘数法
(更新,写一下推导过程)
同样,软间隔原问题中待求解参数w和b同样是收到约束的,因此我们同样根据拉格朗日乘数法的思想,令:

因此原问题同样由有约束问题变成了无约束问题:

2.2.3强对偶转换
跟求解硬间隔一样,我们同样把软间隔无约束问题转换为它的强对偶问题:

2.2.4求解最终问题
我们同样先求右边的最小值。我们知道:
接下来我们让L先后对三个变量求导。
先让L对b求导得:

我们将 ∑ i = 1 N α i y i = 0 \sum_{i=1}^{N}\alpha _{i}y_{i}=0 ∑i=1Nαiyi=0代入到L中得到:

接着让L对w求导得到:

然后让L对 ε i \varepsilon_{i} εi求导得:

于是:

于是我们最终将:
转换成了:

进一步,根据 α i ≥ 0 , μ i ≥ 0 , C − α i − μ i = 0 \alpha_{i}\geq 0,\mu_{i}\geq 0,C-\alpha_{i}-\mu_{i}=0 αi≥0,μi≥0,C−αi−μi=0三个条件,我们可以得到: 0 ≤ α i ≤ C 0\leq\alpha_{i}\leq C 0≤αi≤C,于是最终问题变成了:

2.2.5KKT条件
原始问题为凸二次规划,满足KKT条件:

对KKT条件分类讨论:
(1) α i = 0 \alpha_{i}=0 αi=0,则 w = ∑ i = 1 N α i y i x i = 0 w=\sum_{i=1}^{N}\alpha_{i}y_{i}x_{i}=0 w=∑i=1Nαiyixi=0,说明向量 x i x_{i} xi不是支持向量。
(2) 0 < α i < C 0< \alpha_{i}< C 0<αi<C,此时 x i x_{i} xi是支持向量了。这里为什么会出现C?因为 μ i = C − α i \mu_{i}=C-\alpha_{i} μi=C−αi。此种情况下 μ i > 0 \mu_{i}>0 μi>0,又因为 μ i ε i = 0 \mu_{i}\varepsilon_{i}=0 μiεi=0,于是 ε i = 0 \varepsilon_{i}=0 εi=0,则 y i ( w T x i + b ) = 1 y_{i}(w^Tx_{i}+b)=1 yi(wTxi+b)=1,说明样本 x i x_{i} xi在分割边界上。
(3) α i = C \alpha_{i}=C αi=C,则根据 μ i = C − α i \mu_{i}=C-\alpha_{i} μi=C−αi可知 μ i = 0 \mu_{i}=0 μi=0,又因为 μ i ε i = 0 \mu_{i}\varepsilon_{i}=0 μiεi=0,于是 ε i > 0 \varepsilon_{i}>0 εi>0。
对第三种情况,进一步讨论:
- 0 < ε i < 1 0<\varepsilon_{i}<1 0<εi<1,则 y i ( w T x i + b ) = 1 − ε i ∈ ( 0 , 1 ) y_{i}(w^Tx_{i}+b)=1-\varepsilon_{i}\in(0,1) yi(wTxi+b)=1−εi∈(0,1),样本在间隔边界与超平面之间。
- ε i = 1 \varepsilon_{i}=1 εi=1,则 y i ( w T x i + b ) = 1 − ε i = 0 y_{i}(w^Tx_{i}+b)=1-\varepsilon_{i}=0 yi(wTxi+b)=1−εi=0,样本在超平面上。
- ε i > 1 \varepsilon_{i}>1 εi>1,则 y i ( w T x i + b ) = 1 − ε i < 0 y_{i}(w^Tx_{i}+b)=1-\varepsilon_{i}<0 yi(wTxi+b)=1−εi<0,样本在超平面另一侧,说明分类错误。
2.2.6最终解答
前面求导时我们已经得到了: w ∗ = ∑ i = 1 N α i y i x i w^*=\sum_{i=1}^{N}\alpha_{i}y_{i}x_{i} w∗=∑i=1Nαiyixi,求解b*的思路跟前面一样,任取一个支持向量 ( x k , y k ) (x_{k},y_{k}) (xk,yk),我们知道支持向量满足:
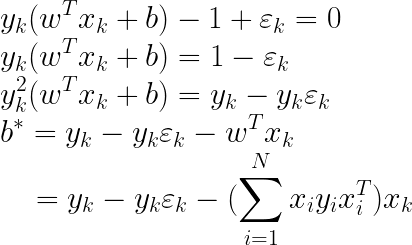
但是这里面有一个不确定量 ε k \varepsilon_{k} εk,我们如果选择了一个 ε k > 0 \varepsilon_{k}> 0 εk>0的支持向量,那么 ε k \varepsilon_{k} εk的具体值我们是无法知道的,因此我们只能选择一个 ε k = 0 \varepsilon_{k}= 0 εk=0的支持向量才能解出b,而根据上面对KKT条件的讨论,只有当 0 < α i < C 0< \alpha_{i}< C 0<αi<C时, ε k = 0 \varepsilon_{k}= 0 εk=0才成立。因此这里需要注意,硬间隔求b时我们可以选择任意一个支持向量,而软间隔不行,我们只有选择满足 0 < α i < C 0< \alpha_{i}< C 0<αi<C( α i > 0 \alpha_{i}>0 αi>0就是支持向量)的支持向量,才能解出b。这其实是一种人为制定的求 b 的规则。
3.核技巧(kernel trick)
先不谈什么是核技巧,先谈谈什么为什么要用核技巧。从前面的硬间隔与软间隔学习中我们可以看出来,SVM构建的是一个线性的决策边界,从而把数据集分到各自的类中(虽然软间隔不完全可分,但大部分还是可分的)。如果数据集是一个非线性的,直接使用SVM,得不到一个理想的结果,那么使用线性分类器求解非线性分类问题,就需要特殊的处理。
对非线性的原始样本,可以将样本从原始空间映射到一个更高维的特征空间中,使得样本在这个特征空间中线性可分。数学上可以证明,如果原始空间是有限维,即属性数有限,则一定存在一个高维特征空间使样本可分。(这里就不证明了)
我们令 ϕ ( x ) \phi(x) ϕ(x)表示将原始空间上样本x映射到高维空间上后的“新样本”,那么我们要求解的超平面方程就变成了: w T ϕ ( x ) + b = 0 w^T\phi(x)+b=0 wTϕ(x)+b=0,于是:

这与硬间隔的原问题求解是一模一样的,一点没变。因为我们知道硬间隔的最终求解答案为:
所以将线性不可分的样本映射到高维后,我们可以解出:

所以判别函数为:

注:上述 x j x_{j} xj只是为了便于区分才这样写,实际上是 x i x_{i} xi。我们令:
![]()
于是有:

这里的 K ( x i , x j ) K(x_{i},x_{j}) K(xi,xj)其实就是一种核函数,我们称之为线性核函数,常见的核函数还有:

关于核函数的详细讲述请见:核方法概述----正定核以及核技巧(Gram矩阵推导正定核)
参考文献
- 强对偶性、弱对偶性以及KKT条件的证明(对偶问题的几何证明)
- 机器学习之SVM(Hinge Loss+Kernel Trick)原理推导与解析
- SVM中对函数边距(functional margin) = 1 的思考
- 核方法概述----正定核以及核技巧(Gram矩阵推导正定核)
- 《机器学习》——周志华