You Only Look Once: Unified, Real-Time Object Detection阅读笔记
疫情原因,学校新开设了一门文献阅读。唉,现在只好读一篇记录一点,最后还要写一万五千字的文献综述,绝望啊。
今天的论文是 :You Only Look Once: Unified, Real-Time Object Detection
全文和翻译:
Abstract
We present YOLO, a new approach to object detection. Prior work on object detection repurposes classifiers to perform detection. Instead, we frame object detection as a regression problem to spatially separated bounding boxes and associated class probabilities. A single neural network predicts bounding boxes and class probabilities directly from full images in one evaluation. Since the whole detection pipeline is a single network, it can be optimized end-to-end directly on detection performance. Our unified architecture is extremely fast. Our base YOLO model processes images in real-time at 45 frames per second. A smaller version of the network, Fast YOLO, processes an astounding 155 frames per second while still achieving double the mAP of other real-time detectors. Compared to state-of-the-art detection systems, YOLO makes more localization errors but is less likely to predict false positives on background. Finally, YOLO learns very general representations of objects. It outperforms other detection methods, including DPM and R-CNN, when generalizing from natural images to other domains like artwork.
我们在这里解释介绍一种新的对象检测方法YOLO。先前目标检测的工作将分类器用于执行检测。而本文将目标检测作为边界框(用于空间划分)和相关类概率的回归问题。本文采用了单个神经网络,可以在一次评估中从整幅图像直接预测边界框和类概率。由于检测采用了单网络,对检测性能的优化过程是端到端进行的。这个统一的框架体系运行速度非常快。我们的基本YOLO模型,以每秒45帧的速度实时处理图像。较小的网络版本Fast YOLO每秒可处理155帧,同时达到其他实时检测器的两倍mAP。与最新的检测框架相比,YOLO会产生更多的定位错误,但预测背景假阳性的可能性较小。最后,YOLO学习的是通用的物体表达形式。从自然图像到绘画等其他领域,它的性能明显优于其他检测方法(DPM和R-CNN)。
1. Introduction
Humans glance at an image and instantly know what objects are in the image, where they are, and how they interact. The human visual system is fast and accurate, allowing us to perform complex tasks like driving with little conscious thought. Fast, accurate algorithms for object detection would allow computers to drive cars without specialized sensors, enable assistive devices to convey real-time scene information to human users, and unlock the potential for general purpose, responsive robotic systems.
Current detection systems repurpose classifiers to perform detection. To detect an object, these systems take a classifier for that object and evaluate it at various locations and scales in a test image. Systems like deformable parts models (DPM) use a sliding window approach where the classifier is run at evenly spaced locations over the entire image [10].
More recent approaches like R-CNN use region proposalmethods to first generate potential bounding boxes in an image and then run a classifier on these proposed boxes. After classification, post-processing is used to refine the bounding boxes, eliminate duplicate detections, and rescore the boxes based on other objects in the scene [13]. These complex pipelines are slow and hard to optimize because each individual component must be trained separately.
人类看一眼图像,立即知道图像中有什么对象,它们在哪里以及如何相互作用。人类的视觉系统快速准确,使我们能够执行一些复杂的任务,例如在没有意识的情况下驾驶。快速,准确的物体检测算法,将允许计算机在没有专用传感器的情况下驾驶汽车,使辅助设备向人类用户传达实时场景信息,并释放通用响应型机器人系统的潜力。
当前的检测系统将分类器重新利用来执行检测。为了检测物体,这些系统采用了该物体的分类器,并在测试图像的各个位置和比例上对其进行了评估。像DPM模型之类的系统在滑动窗口中运行分类器,并均匀遍历整个图像[10]。
很多方法(R-CNN),首先在图像中生成潜在的边界框,然后在这些建议框上运行分类器。分类后,再使用后处理方法来优化边界框,消除重复检测,并根据场景中的其他对象对这些框进行重新评分[13]。这些框架运行缓慢,且难以优化,因为每个单独的部分都必须分别进行培训。
We reframe object detection as a single regression problem, straight from image pixels to bounding box coordinates and class probabilities. Using our system, you only look once (YOLO) at an image to predict what objects are present and where they are.
我们将对象检测重新构造为一个回归问题,直接从图像得到边界框坐标和类概率。使用我们的系统,您只需看一次(YOLO)图像即可预测存在的物体及其位置。
YOLO is refreshingly simple: see Figure 1. A single convolutional network simultaneously predicts multiple bounding boxes and class probabilities for those boxes.YOLO trains on full images and directly optimizes detection performance. This unified model has several benefits over traditional methods of object detection.
YOLO非常简单:参见图1。单个卷积网络可同时预测多个边界框和这些框的类概率。YOLO训练完整图像并直接优化检测性能。与传统的对象检测方法相比,此统一模型具有多个优点。

First, YOLO is extremely fast. Since we frame detection as a regression problem we don’t need a complex pipeline. We simply run our neural network on a new image at test time to predict detections. Our base network runs at 45 frames per second with no batch processing on a Titan X GPU and a fast version runs at more than 150 fps. This means we can process streaming video in real-time with less than 25 milliseconds of latency. Furthermore, YOLO achieves more than twice the mean average precision of other real-time systems. For a demo of our system running in real-time on a webcam please see our project webpage: http://pjreddie.com/yolo/.
首先,YOLO非常快。由于我们将检测框架视为回归问题,因此不需要复杂的流程。我们只需在测试时在新图像上运行神经网络即可预测检测结果。我们的基本网络以每秒45帧的速度运行,在Titan X GPU上不用批处理,而快速版本的运行速度超过150 fps。这意味着我们可以实时处理视频流,而延时不到25毫秒。此外,YOLO达到了其他实时系统平均精度的两倍以上。在网络摄像头上实时运行系统的演示,请参阅项目网页:http://pjreddie.com/yolo/。
Second, YOLO reasons globally about the image when making predictions. Unlike sliding window and region proposal-based techniques, YOLO sees the entire image during training and test time so it implicitly encodes contextual information about classes as well as their appearance. Fast R-CNN, a top detection method [14], mistakes background patches in an image for objects because it can’t see the larger context. YOLO makes less than half the number of background errors compared to Fast R-CNN.
其次,YOLO在做出预测时会考虑全局图像。与基于滑动窗口和区域提议的技术不同,YOLO在训练和测试期间会看到整个图像,因此它隐式地编码有关类及其外观的内容信息。Fast R-CNN这种检测方法[14],因为看不到较大视野,因此将图像中的背景色块误认为是对象。与Fast R-CNN相比,YOLO产生的背景错误减少了一半。
Third, YOLO learns generalizable representations of objects. When trained on natural images and tested on artwork, YOLO outperforms top detection methods like DPM and R-CNN by a wide margin. Since YOLO is highly generalizable it is less likely to break down when applied to new domains or unexpected inputs.
YOLO still lags behind state-of-the-art detection systems in accuracy. While it can quickly identify objects in images it struggles to precisely localize some objects, especially small ones. We examine these tradeoffs further in our experiments.
All of our training and testing code is open source. A variety of pretrained models are also available to download.
第三,YOLO学习了目标的一般表达。在自然图像上进行训练,并在艺术图像上进行测试时,YOLO在很大程度上优于DPM和R-CNN等检测方法。由于YOLO具有高度通用性,因此在应用于新的领域或意外输入时,奔溃的可能性较小。
YOLO在准确性方面仍落后于最新的检测系统。尽管它可以快速识别图像中的对象,但仍难以精确定位某些对象,尤其是小的对象。我们在实验中进一步研究了这些折衷。
所有的测试和测试代码都是开源的。各种预训练的模型也可以下载。
2. Unified Detection
We unify the separate components of object detection into a single neural network. Our network uses features
from the entire image to predict each bounding box. It also predicts all bounding boxes across all classes for an image simultaneously. This means our network reasons globally about the full image and all the objects in the image.The YOLO design enables end-to-end training and realtime speeds while maintaining high average precision.
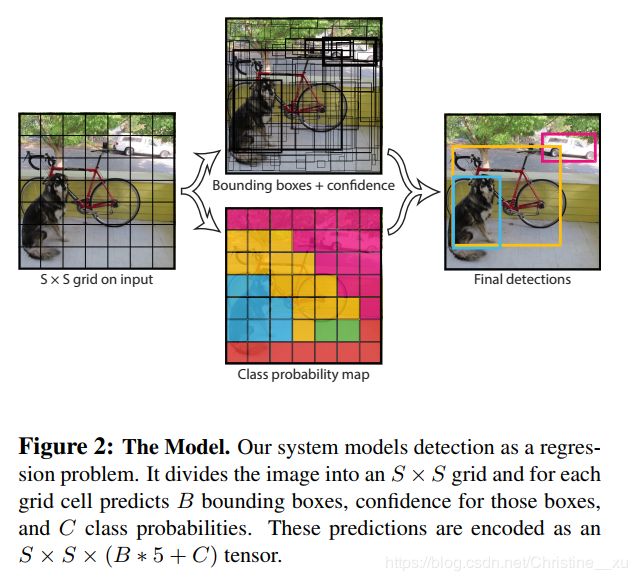
Our system divides the input image into an S × S grid. If the center of an object falls into a grid cell, that grid cell
is responsible for detecting that object.
我们将对象检测的各个组成部分统一为一个神经网络。我们的网络使用整个图像中的特征来预测每个边界框。它还可以同时预测图像所有类的所有边界框。这意味着我们的网络会在全局范围内考虑完整图像和图像中的所有对象。YOLO的设计可在保持较高平均精度的同时实现端到端训练和实时速度。
我们的系统将输入图像划分为S×S网格。如果对象的中心落入网格单元,则该网格单元负责检测该对象。
Each grid cell predicts B bounding boxes and confidence scores for those boxes. These confidence scores reflect how
confident the model is that the box contains an object and also how accurate it thinks the box is that it predicts. Formally we define confidence as Pr(Object) ∗ IOUtruth pred. If no object exists in that cell, the confidence scores should be
zero. Otherwise we want the confidence score to equal the intersection over union (IOU) between the predicted box
and the ground truth.
每个网格单元预测B个边界框和这些框的置信度得分。这些置信度得分反映了该模型对预测框包含一个对象的信赖程度,以及它认为预测框预测的准确性。形式上,我们将置信度定义为Pr(Object)* IOU(真实、预测)。如果该单元格中没有对象,则置信度为零。否则,我们希望置信度分数等于预测框与真实背景之间的交集/并集(IOU)。
Each bounding box consists of 5 predictions: x, y, w, h, and confidence. The (x, y) coordinates represent the center
of the box relative to the bounds of the grid cell. The width and height are predicted relative to the whole image. Finally
the confidence prediction represents the IOU between the predicted box and any ground truth box.
每个预测框由5个预测值组成:x,y,w,h和置信度。(x,y)坐标表示框相对于网格单元边界的中心。宽度和高度是相对于整个图像的比例。最后,置信度预测表示预测框与任何地面真实框之间的IOU。
Each grid cell also predicts C conditional class probabilities, Pr(Classi|Object). These probabilities are conditioned on the grid cell containing an object. We only predict one set of class probabilities per grid cell, regardless of the number of boxes B.
每个网格单元还预测C个条件类概率Pr(Classi | Object)。这些概率以网格单元包含目标为条件。无论框B的数量如何,我们仅预测每个网格单元的一组类概率。
At test time we multiply the conditional class probabilities and the individual box confidence predictions,

which gives us class-specific confidence scores for each box. These scores encode both the probability of that class appearing in the box and how well the predicted box fits the object.
在测试时,我们将条件类概率与各个框的置信度预测相乘,(1)式,它为我们提供了每个框的特定于类的置信度得分。这些分数既代表了该类别出现在预测框中的概率,也表面了预测框与对象的匹配程度。
For evaluating YOLO on PASCAL VOC, we use S = 7, B = 2. PASCAL VOC has 20 labelled classes so C = 20. Our final prediction is a 7 × 7 × 30 tensor.
2.1. Network Design
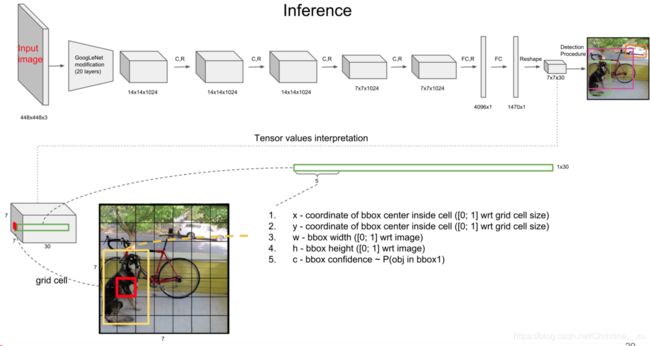
We implement this model as a convolutional neural network and evaluate it on the PASCAL VOC detection dataset [9]. The initial convolutional layers of the network extract features from the image while the fully connected layers predict the output probabilities and coordinates.
Our network architecture is inspired by the GoogLeNet model for image classification [34]. Our network has 24 convolutional layers followed by 2 fully connected layers. Instead of the inception modules used by GoogLeNet, we simply use 1 × 1 reduction layers followed by 3 × 3 convolutional layers, similar to Lin et al [22]. The full network is shown in Figure 3.
该模型以卷积神经网络实现,并在PASCAL VOC检测数据集上进行评估[9]。网络的初始卷积层从图像中提取特征,而全连接层则预测输出概率和坐标。
我们的网络结构受到用于图像分类的GoogLeNet模型的启发[34]。我们的网络有24个卷积层,其后是2个完全连接的层。与Lin等[22]相似,我们没有使用GoogLeNet的初始模块,而是仅使用1×1约减层,然后是3×3卷积层。完整的网络如图3所示。

We also train a fast version of YOLO designed to push the boundaries of fast object detection. Fast YOLO uses a neural network with fewer convolutional layers (9 instead of 24) and fewer filters in those layers. Other than the size of the network, all training and testing parameters are the same between YOLO and Fast YOLO.
我们还训练了一种快速版本的YOLO,旨在突破快速物体检测的极限。Fast YOLO使用的神经网络具有较少的卷积层(从9个而不是24个),并且这些层中的过滤器较少。除了网络的规模外,YOLO和Fast YOLO之间的所有训练和测试参数都相同。
The final output of our network is the 7 × 7 × 30 tensor of predictions.
我们网络的最终输出是 7 × 7 × 30 的预测张量。
2.2. Training
We pretrain our convolutional layers on the ImageNet 1000-class competition dataset [30]. For pretraining we use the first 20 convolutional layers from Figure 3 followed by a average-pooling layer and a fully connected layer. We train this network for approximately a week and achieve a single crop top-5 accuracy of 88% on the ImageNet 2012 validation set, comparable to the GoogLeNet models in Caffe’s Model Zoo [24]. We use the Darknet framework for all training and inference [26].
We then convert the model to perform detection. Ren et al. show that adding both convolutional and connected layers to pretrained networks can improve performance [29]. Following their example, we add four convolutional layers and two fully connected layers with randomly initialized weights. Detection often requires fine-grained visual information so we increase the input resolution of the network from 224 × 224 to 448 × 448.
我们在ImageNet 1000类竞赛数据集上对卷积层进行预训练[30]。对于预训练,我们使用图3中的前20个卷积层,然后是平均池层和完全连接层。我们对这个网络进行了大约一周的训练,并在ImageNet 2012验证集上达到了单作物top-5的准确性,达到88%,与Caffe模型动物园[24]中的GoogLeNet模型相当。我们将Darknet框架用于所有训练和推断[26]。
然后,我们将模型用于检测。任少卿等人表明将卷积层和连接层都添加到预训练的网络中可以提高性能[29]。按照他们的示例,我们添加了四个卷积层和两个完全连接的层,它们具有随机初始化的权重。检测通常需要细粒度的视觉信息,因此我们将网络的输入分辨率从224×224增加到448×448。
Our final layer predicts both class probabilities and bounding box coordinates. We normalize the bounding box width and height by the image width and height so that they fall between 0 and 1. We parametrize the bounding box x and y coordinates to be offsets of a particular grid cell location so they are also bounded between 0 and 1.
We use a linear activation function for the final layer and all other layers use the following leaky rectified linear activation:
We optimize for sum-squared error in the output of our model. We use sum-squared error because it is easy to optimize, however it does not perfectly align with our goal of maximizing average precision. It weights localization error equally with classification error which may not be ideal. Also, in every image many grid cells do not contain any object. This pushes the “confidence” scores of those cells towards zero, often overpowering the gradient from cells that do contain objects. This can lead to model instability, causing training to diverge early on.
我们的最后一层可以预测类概率和边界框坐标。我们通过图像的宽度和高度对边界框的宽度和高度进行归一化,使它们落在0和1之间。我们将边界框的x和y坐标参数化为特定网格单元位置的偏移量,因此它们也被限制在0和1之间。
我们对最终层使用线性激活函数,而所有其他层均使用以下泄漏校正线性激活:式子(2)
我们针对模型输出中的平方误差进行了优化。我们使用平方和误差是因为它易于优化,但它与我们实现平均精度最大化的目标并不完全一致。它对定位误差和分类误差的权重相等,这可能不理想。同样,在每个图像中,许多网格单元都不包含任何对象。这会将这些单元格的“置信度”得分推向零,通常会超过确实包含对象的单元格的梯度。这可能会导致模型不稳定,从而导致训练在早期就出现分歧。
To remedy this, we increase the loss from bounding box coordinate predictions and decrease the loss from confidence predictions for boxes that don’t contain objects. We use two parameters, λcoord and λnoobj to accomplish this. We
set λcoord = 5 and λnoobj = :5.
Sum-squared error also equally weights errors in large boxes and small boxes. Our error metric should reflect that small deviations in large boxes matter less than in small boxes. To partially address this we predict the square root of the bounding box width and height instead of the width and height directly.
YOLO predicts multiple bounding boxes per grid cell. At training time we only want one bounding box predictor to be responsible for each object. We assign one predictor to be “responsible” for predicting an object based on which prediction has the highest current IOU with the ground truth. This leads to specialization between the bounding box predictors. Each predictor gets better at predicting certain sizes, aspect ratios, or classes of object, improving overall recall.
为了解决这个问题,对于不包含对象的预测框,我们增加了边界框坐标预测的损失,并减少了置信度预测的损失。我们使用两个参数λcoord和λnoobj来完成此操作。我们设置λcoord= 5和λnoobj=:5。
平方和误差也平均权衡大盒子和小盒子中的误差。我们的误差指标应反映出,大盒子中的小偏差比小盒子中的小偏差要小。为了部分解决此问题,我们预测边界框的宽度和高度的平方根,而不是直接预测宽度和高度。
YOLO预测每个网格单元有多个边界框。在训练时,我们只希望一个边界框预测变量对每个对象负责。我们将一个预测变量指定为“负责任的”预测对象,基于哪个预测具有最高的当前IOU和真实性。这导致边界框预测变量之间的专用化。每个预测器都可以更好地预测某些大小,纵横比或对象类别,从而改善总体召回率。
During training we optimize the following, multi-part loss function:

where 1obj i denotes if object appears in cell i and 1obj ij denotes that the jth bounding box predictor in cell i is “responsible” for that prediction.
Note that the loss function only penalizes classification error if an object is present in that grid cell (hence the conditional class probability discussed earlier). It also only penalizes bounding box coordinate error if that predictor is “responsible” for the ground truth box (i.e. has the highest IOU of any predictor in that grid cell).
We train the network for about 135 epochs on the training and validation data sets from PASCAL VOC 2007 and 2012. When testing on 2012 we also include the VOC 2007 test data for training. Throughout training we use a batch size of 64, a momentum of 0.9 and a decay of 0.0005.
其中1obj i表示对象是否出现在单元格i中,1obj ij表示该单元格i中的第j个边界框预测变量对该预测“负责”。
请注意,如果该网格单元中存在对象,则损失函数只会惩罚分类错误(因此,前面讨论过的条件分类概率)。如果该预测变量对地面真值框“负责”(即该网格单元中任何预测变量的IOU最高),它也只会惩罚边界框坐标误差。
我们根据PASCAL VOC 2007和2012的培训和验证数据集对网络进行了135个时期的培训。在2012年进行测试时,我们还包含了VOC 2007测试数据进行培训。在整个训练过程中,我们使用的批次大小为64,动量为0.9,衰减为0.0005。
Our learning rate schedule is as follows: For the first epochs we slowly raise the learning rate from 10-3 to 10-2. If we start at a high learning rate our model often diverges due to unstable gradients. We continue training with 10-2 for 75 epochs, then 10-3 for 30 epochs, and finally 10-4 for 30 epochs.
To avoid overfitting we use dropout and extensive data augmentation. A dropout layer with rate = .5 after the first connected layer prevents co-adaptation between layers [18]. For data augmentation we introduce random scaling and translations of up to 20% of the original image size. We also randomly adjust the exposure and saturation of the image by up to a factor of 1:5 in the HSV color space.
我们的学习率时间表如下:在第一个时期,我们将学习率从10-3逐渐提高到10-2。如果我们以较高的学习率开始,则由于不稳定的梯度,我们的模型经常会发散。我们将继续以10-2训练75个时期,然后以10-3训练30个时期,最后以10-4训练30个时期。
为了避免过拟合,我们使用了dropout和数据扩充。在第一个连接层之后,速率为.5的退出层可防止层之间的共同适应[18]。对于数据扩充,我们引入了随机缩放和最多原始图像大小20%的转换。我们还将在HSV颜色空间中将图像的曝光和饱和度随机调整至1:5。
2.3. Inference
Just like in training, predicting detections for a test image only requires one network evaluation. On PASCAL VOC the network predicts 98 bounding boxes per image and class probabilities for each box. YOLO is extremely fast at test time since it only requires a single network evaluation, unlike classifier-based methods.
The grid design enforces spatial diversity in the bounding box predictions. Often it is clear which grid cell an object falls in to and the network only predicts one box for each object. However, some large objects or objects near the border of multiple cells can be well localized by multiple cells. Non-maximal suppression can be used to fix these multiple detections. While not critical to performance as it is for R-CNN or DPM, non-maximal suppression adds 2-3% in mAP.
就像在训练中一样,预测测试图像的检测仅需要进行一次网络评估。在PASCAL VOC上,网络可预测每个图像98个边界框,并预测每个框的类概率。与基于分类器的方法不同,YOLO只需要进行一次网络评估,因此测试时间非常快。
网格设计在边界框预测中强制执行空间分集。通常,很明显,一个对象属于哪个网格单元,并且网络仅为每个对象预测一个框。但是,一些大对象或多个单元格边界附近的对象可以被多个单元格很好地定位。非最大抑制可用于修复这些多次检测。尽管对于R-CNN或DPM而言,对性能并不重要,但非最大抑制会在mAP中增加2-3%。
2.4. Limitations of YOLO
YOLO imposes strong spatial constraints on bounding box predictions since each grid cell only predicts two boxes and can only have one class. This spatial constraint limits the number of nearby objects that our model can predict. Our model struggles with small objects that appear in groups, such as flocks of birds.
Since our model learns to predict bounding boxes from data, it struggles to generalize to objects in new or unusual aspect ratios or configurations. Our model also uses relatively coarse features for predicting bounding boxes since our architecture has multiple downsampling layers from the input image.
Finally, while we train on a loss function that approximates detection performance, our loss function treats errors the same in small bounding boxes versus large bounding boxes. A small error in a large box is generally benign but a small error in a small box has a much greater effect on IOU. Our main source of error is incorrect localizations.
由于每个网格单元仅预测两个框且只能具有一个类别,因此YOLO对边界框的预测施加了强大的空间约束。这种空间限制限制了我们的模型可以预测的附近物体的数量。我们的模型在成组出现的小物体(例如成群的鸟)效果不佳。
由于我们的模型学会了根据数据来预测边界框,因此很难将其推广到具有新的或不同寻常的宽高比或配置的对象。我们的模型还使用相对粗糙的特征来预测边界框,因为我们的体系结构从输入图像中有多个下采样层。
最后,虽然我们训练的是近似检测性能的损失函数,但损失函数在小边界框与大边界框中对待错误的方式相同。大盒中的小错误通常是良性的,但小盒中的小错误对IOU的影响更大。错误的主要来源是错误的本地化。
3. Comparison to Other Detection Systems
Object detection is a core problem in computer vision. Detection pipelines generally start by extracting a set of robust features from input images (Haar [25], SIFT [23], HOG [4], convolutional features [6]). Then, classifiers [36, 21, 13, 10] or localizers [1, 32] are used to identify objects in the feature space. These classifiers or localizers are run either in sliding window fashion over the whole image or on some subset of regions in the image [35, 15, 39]. We compare the YOLO detection system to several top detection frameworks, highlighting key similarities and differences.
Deformable parts models. Deformable parts models(DPM) use a sliding window approach to object detection[10]. DPM uses a disjoint pipeline to extract static features, classify regions, predict bounding boxes for high scoring regions, etc. Our system replaces all of these disparate parts with a single convolutional neural network. The network performs feature extraction, bounding box prediction, nonmaximal suppression, and contextual reasoning all concurrently. Instead of static features, the network trains the features in-line and optimizes them for the detection task. Our unified architecture leads to a faster, more accurate model than DPM.
对象检测是计算机视觉中的核心问题。检测管线通常从输入图像中提取一组鲁棒特征开始(Haar [25],SIFT [23],HOG [4],卷积特征[6])。然后,使用分类器[36、21、13、10]或定位器[1、32]来识别特征空间中的对象。这些分类器或定位器以滑动窗口的方式在整个图像上或图像的某些区域子集上运行[35、15、39]。我们将YOLO检测系统与几个顶级检测框架进行了比较,突出了关键的异同。
DPM模型。DPM使用滑动窗口方法进行目标检测[10]。DPM使用不相交的管线提取静态特征,对区域进行分类,预测高分区域的边界框等。我们的系统用单个卷积神经网络替换了所有这些不同的部分。网络同时执行特征提取,边界框预测,非最大抑制和上下文推理。网络代替静态功能,而是在线训练功能并针对检测任务对其进行优化。与DPM相比,我们的统一体系结构可导致更快,更准确的模型。
R-CNN. R-CNN and its variants use region proposals instead of sliding windows to find objects in images. Selective Search[35] generates potential bounding boxes, a convolutional network extracts features, an SVM scores the boxes, a linear model adjusts the bounding boxes, and non-max suppression eliminates duplicate detections. Each stage of this complex pipeline must be precisely tuned independently and the resulting system is very slow, taking more than 40 seconds per image at test time [14].
R-CNN及其变体使用区域提议而不是滑动窗口在图像中查找对象。选择性搜索[35]生成潜在的边界框,卷积网络提取特征,支持向量机对这些框进行评分,线性模型调整边界框,非最大抑制消除重复的检测。这个复杂的流水线的每个阶段都必须独立地精确调整,并且结果系统非常慢,在测试时间每个图像花费40秒钟以上的时间[14]。
YOLO shares some similarities with R-CNN. Each grid cell proposes potential bounding boxes and scores those boxes using convolutional features. However, our system puts spatial constraints on the grid cell proposals which helps mitigate multiple detections of the same object. Our system also proposes far fewer bounding boxes, only 98 per image compared to about 2000 from Selective Search. Finally, our system combines these individual components into a single, jointly optimized model.
YOLO与R-CNN有一些相似之处。每个网格单元都会提出潜在的边界框,并使用卷积特征对这些框进行评分。但是,我们的系统在网格单元建议上施加了空间限制,这有助于减轻对同一对象的多次检测。我们的系统还提出了更少的边界框,每个图像只有98个边界框,而选择性搜索只有2000个边界框。最后,我们的系统将这些单独的组件组合到一个共同优化的模型中。
Other Fast Detectors Fast and Faster R-CNN focus on speeding up the R-CNN framework by sharing computation and using neural networks to propose regions instead of Selective Search [14] [28]. While they offer speed and accuracy improvements over R-CNN, both still fall short of real-time performance.
Many research efforts focus on speeding up the DPM pipeline [31] [38] [5]. They speed up HOG computation, use cascades, and push computation to GPUs. However, only 30Hz DPM [31] actually runs in real-time.
Instead of trying to optimize individual components of a large detection pipeline, YOLO throws out the pipeline entirely and is fast by design.
Detectors for single classes like faces or people can be highly optimized since they have to deal with much less variation [37]. YOLO is a general purpose detector that learns to detect a variety of objects simultaneously.
其他快速检测器:Fast and Faster R-CNN专注于通过共享计算和使用神经网络来提议区域而不是选择性搜索来加快R-CNN框架[14] [28]。尽管它们在R-CNN上提供了速度和准确性方面的改进,但两者仍未达到实时性能。
许多研究工作集中在加速DPM管道[31] [38] [5]。它们可以加快HOG计算,使用级联并将计算推入GPU。但是,只有30Hz DPM [31]实际上是实时运行的。YOLO并没有尝试优化大型检测管道的各个组件,而是完全淘汰了该管道,并且设计合理。像面孔或人这样的单一类别的检测器可以进行高度优化,因为它们必须处理更少的变化[37]。YOLO是一种通用检测器,可学习同时检测各种物体。
Deep MultiBox. Unlike R-CNN, Szegedy et al. train a convolutional neural network to predict regions of interest [8] instead of using Selective Search. MultiBox can also perform single object detection by replacing the confidence prediction with a single class prediction. However, MultiBox cannot perform general object detection and is still just a piece in a larger detection pipeline, requiring further image patch classification. Both YOLO and MultiBox use a convolutional network to predict bounding boxes in an image but YOLO is a complete detection system.
与R-CNN不同,Szegedy等人。训练卷积神经网络来预测感兴趣区域[8],而不是使用选择性搜索。通过将置信度预测替换为单个类别预测,MultiBox还可以执行单个对象检测。但是,MultiBox无法执行常规的对象检测,并且仍然只是较大检测管道中的一部分,需要进一步的图像补丁分类。YOLO和MultiBox都使用卷积网络来预测图像中的边界框,但是YOLO是一个完整的检测系统。
OverFeat. Sermanet et al. train a convolutional neural network to perform localization and adapt that localizer to perform detection [32]. OverFeat efficiently performs sliding window detection but it is still a disjoint system. OverFeat optimizes for localization, not detection performance.
Like DPM, the localizer only sees local information when making a prediction. OverFeat cannot reason about global context and thus requires significant post-processing to produce coherent detections.
Sermanet等训练一个卷积神经网络来执行定位,并使该定位器执行检测[32]。OverFeat有效地执行滑动窗口检测,但它仍然是不相交的系统。OverFeat针对本地化而不是检测性能进行优化。像DPM一样,本地化程序只能在进行预测时看到本地信息。OverFeat无法推理全局上下文,因此需要进行大量后期处理才能产生连贯的检测结果。
MultiGrasp. Our work is similar in design to work on grasp detection by Redmon et al [27]. Our grid approach to bounding box prediction is based on the MultiGrasp system for regression to grasps. However, grasp detection is a much simpler task than object detection. MultiGrasp only needs to predict a single graspable region for an image containing one object. It doesn’t have to estimate the size, location, or boundaries of the object or predict it’s class, only find a region suitable for grasping. YOLO predicts both bounding boxes and class probabilities for multiple objects of multiple classes in an image.
我们的工作在设计上类似于Redmon等人[27]的抓握检测工作。我们用于边界框预测的网格方法是基于MultiGrasp系统进行回归分析的。但是,抓取检测比对象检测要简单得多。MultiGrasp只需要为包含一个对象的图像预测单个可抓握区域。不必估计物体的大小,位置或边界或预测其类别,仅需找到适合抓握的区域即可。YOLO预测图像中多个类别的多个对象的边界框和类别概率。
4. Experiments
5. Real-Time Detection In The Wild
我就不贴了。
6. Conclusion
We introduce YOLO, a unified model for object detection. Our model is simple to construct and can be trained directly on full images. Unlike classifier-based approaches, YOLO is trained on a loss function that directly corresponds to detection performance and the entire model is trained jointly.
Fast YOLO is the fastest general-purpose object detector in the literature and YOLO pushes the state-of-the-art in real-time object detection. YOLO also generalizes well to new domains making it ideal for applications that rely on fast, robust object detection.
我们介绍了YOLO,这是一个用于物体检测的统一模型。我们的模型构造简单,可以直接在完整图像上进行训练。与基于分类器的方法不同,YOLO在直接与检测性能相对应的损失函数上进行训练,并且整个模型都在一起进行训练。
快速YOLO是文献中最快的通用目标检测器,YOLO推动了实时目标检测的最新发展。YOLO还很好地推广到了新领域,使其成为依赖快速,强大的对象检测的应用程序的理想选择。
总结:
1.YOLO的独特之处:
并不采用两步的策略(先定位再分类),而是采用回归的方法,将检测过程简化为一步,实现端到端的检测。
2.整体框架
将图像分成 SxS 个网格,如果某目标的中心落在这个网格中,则这个网格就负责预测这个目标。
每个网格要预测 B 个预测框,每个框除了要得到目标的位置(x, y, w, h)外,还要预测置信度值。(x,y)是相对于预测框的位置,(w,h)是相对于整体图片的大小,因此都在【0,1】之间取值。置信度代表了框内是否含有物体,并且预测框位置与真实目标位置的相似度(IOU)。如果预测框里有物体,则第一项为1.
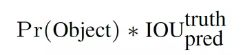
另外,对于网格来说,每个网格需要预测C个类别(总类别数为C),并且不管B取多大,C是固定的。
因此总输出就是 S x S x (5*B+C) 的大小。
注:类别是针对网格的,(x,y,w,h)和置信度是针对预测框的。
在 test 的时候,每个网格预测的 类信息和 预测框的置信度相乘,就得到每个 bounding box 的 class-specific confidence score:

等式左边第一项就是每个网格预测的类别信息,第二、三项就是每个 bounding box 预测的 confidence。这个乘积即 encode 了预测的 box 属于某一类的概率,也有该 box 准确度的信息。
得到每个 box 的 class-specific confidence score 以后,设置阈值,滤掉得分低的 boxes,对保留的 boxes 进行 NMS 非极大值抑制处理,就得到最终的检测结果。
*虽然每个格子可以预测 B 个预测框,但是最终只选择只选择 IOU 最高的预测框输出,即每个格子最多只预测出一个物体。当物体占画面比例较小,如图像中包含畜群或鸟群时,每个格子包含多个物体,但却只能检测出其中一个。这是 YOLO 方法的一个缺陷。
3.细节处理
对预测框来说有 30 维,其中回归坐标(8维),置信度(2维),类别(20维)。当可能的类别数越多,维度就越不均衡。
损失函数是sum-squared error loss ,如何平衡维度间的均衡性,是个大问题。另外如果一个网格中没有物体,那么在训练中出现不平衡问题也很难解决。还有对大小预测框中目标的坐标的误差,权重也是一个问题。
YOLO的解决办法:
-
给坐标预测更大的权重。
-
对没有目标的预测框的置信度,赋予小的权重。
-
有有目标的预测框的置信度和类别的权重取1。
-
为了解决大小预测框中目标的坐标的误差权重,作者将width 和 height 取平方根。这样对不同大小的预测框的坐标预测影响归一化。
一个网格预测多个 box,希望的是每个 box predictor 专门负责预测某个 object。具体做法就是看当前预测的 box 与 ground truth box 中哪个 IoU 大,就负责哪个。这种做法称作 box predictor 的 specialization。
损失函数(借用了其他博主的图):
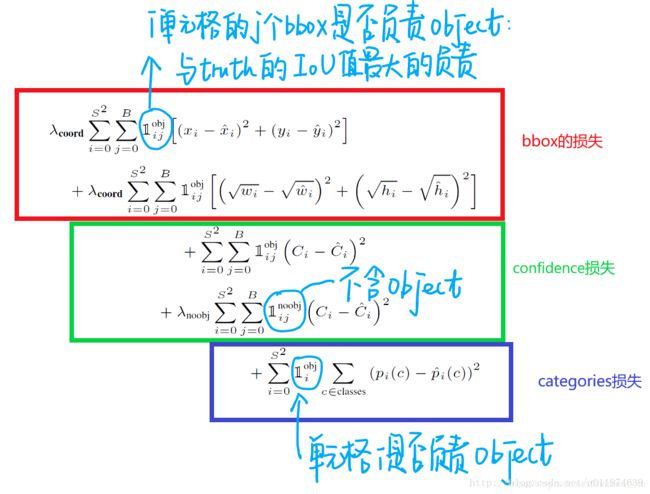
这个损失函数中:
-
网格中有目标的时候才对分类误差进行惩罚。
-
只有当某个 box predictor 对某个 ground truth box 负责的时候,才会对 box 的 coordinate error 进行惩罚,而对哪个 ground truth box 负责就看其预测值和 ground truth box 的 IoU 是不是在那个 cell 的所有 box 中最大。
另外,模型用 ImageNet 进行预训练。
4.YOLO 的缺点
- YOLO 对相互靠的很近的物体,还有很小的群体检测效果不好,这是因为一个网格中只预测了两个框,并且只属于一类。
- 长宽比少见的目标,检测能力偏弱
参考
1. https://www.jianshu.com/p/13ec2aa50c12
2. https://blog.csdn.net/guleileo/article/details/80581858