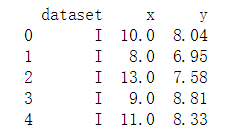
- pandas寻找四分位数及判断离群点
SXxtyz
python
importpandasaspdtrain_df=pd.read_csv("train.csv")q1,q3=train_df['price'].quantile([0.25,0.75])iqr=q3-
- Python----数据分析(Pandas四:一维数组Series的统计计算,分组和聚合)
蹦蹦跳跳真可爱589
数据分析Pythonpandaspython数据分析
一、统计计算1.1、count用于计算Series中非NaN(非空)值的数量。importpandasaspds=pd.Series([1,2,None,4,None])count_non_na=s.count()print(count_non_na)1.2、sumsum()函数会计算所有值的总和。Series.sum(axis=None,skipna=True,numeric_only=None
- Python----数据分析(Pandas三:一维数组Series的数据操作:数据清洗,数据转换,数据排序,数据筛选,数据拼接)
蹦蹦跳跳真可爱589
数据分析Pythonpython数据分析pandas
一、数据清洗1.1、dropna()删除包含NaN值的行。series.dropna(axis=0,inplace=False)描述说明axis可选参数,用于指定按哪个轴删除缺失值。对于Series对象,因为它是一维数据结构,只有一个轴,所以此参数默认值为0,且一般不需要修改这个参数(在处理DataFrame时该参数才有更多实际意义,如除,axis=1表示按列删除)。inplace可选参数,用于指
- 房产租赁数据分析与可视化
学习只是用户态
数据分析信息可视化数据挖掘
【实训目的】 通过本次实训,要求了解Python用于数据可视化的常用包:matplotlib、seaborn、pyecharts等基本使用,及各种图形的使用。【实训环境】 Jupyter环境、Pandas、NumPy、Matplotlib。【实训内容】 1.数据统计与分析方面的可视化; 2.数据分析与预测方面的可视化; 3.数据多类型的可视化。 本次实验以温州市三区房屋租赁数据(res
- selenium+pyquery爬取《鱿鱼游戏》评论2000+条
铁憨憨0304
python爬虫seleniumpython测试工具
IMDB网址爬取《鱿鱼游戏》的全部评论评论排名评论标题id评论时间评论内容导入所需要的包selenium:模拟浏览器,这里使用的是Edge浏览器,需要安装Edge浏览器驱动解析库:PyQuery保存数据:pandas,保存为csv文件fromseleniumimportwebdriverfromselenium.webdriver.support.uiimportWebDriverWaitfrom
- Python——文件读取
一颗小松松
python开发语言
Python可以读取不同格式的文件,下面简单来介绍一下:1、使用read_excel或read_csv读取文件,若在路径前加r,使用“\”importpandasaspd#在路径前加r,使用“\”df=pd.read_excel(r'C:\Users\merit\Desktop\测试.xlsx')#导入.csv文件,以“,”为分隔符data=pd.read_csv(r'C:\Users\merit
- C 结构体基础练习题
噜噜soeur
c语言开发语言
这些题目都是我自己练过挑选出来的,有错误请指出哦谢谢定义一个名为“Student”的结构体,其中包含成员的name(姓名)、age(年龄)和totalMarks(总分)。编写一个C程序来输入两个学生的数据,显示他们的信息,并找到总分的平均值。#includestructStudent{charname[50];intage;floattotalMarks;};intmain(){//Declare
- Python处理CSV文件的12个高效技巧
宇宙大豹发
python开发语言
今天,我们的Python之旅,目标是那片由逗号分隔的宝藏——CSV文件。别看它简单,掌握这些技巧,你的数据处理能力将直线上升,轻松驾驭千行万列的数据海洋。让我们一起,用Python的魔力,让CSV舞动起来吧!1.初次见面,你好,CSV!安装pandas,是这场冒险的起点。它,是Python数据分析的瑞士军刀。pipinstallpandas导入我们的英雄——pandas,并亲切地叫它pd。impo
- Java基础语法练习41(泛型以及自定义泛型)
橙序研工坊
小白Java的成长java开发语言
目录一、泛型:用来表示数据类型的一种类型(在不知道定义为啥数据类型的时候用泛型来代替)1.入门示例代码如下:2.泛型的基本声明:3.泛型的实例化:二、自定义泛型类三、自定义泛型接口四、自定义泛型方法五、泛型的继承和通配符六、练习题一、泛型:用来表示数据类型的一种类型(在不知道定义为啥数据类型的时候用泛型来代替)一句话:泛型是待定的数据类型1.入门示例代码如下:publicclassGeneric0
- 2025-03-14 学习记录--C/C++-PTA 习题2-1 求整数均值
小呀小萝卜儿
学习-C/C++学习c语言
合抱之木,生于毫末;九层之台,起于累土;千里之行,始于足下。一、题目描述⭐️习题2-1求整数均值本题要求编写程序,计算4个整数的和与平均值。题目保证输入与输出均在整型范围内。输入格式:输入在一行中给出4个整数,其间以空格分隔。输出格式:在一行中按照格式“Sum=和;Average=平均值”顺序输出和与平均值,其中平均值精确到小数点后一位。输入样例:1234输出样例:Sum=10;Average=2
- HarmonyOS NEXT<HarmonyOS第一课> DevEco Studio的使用DevEco Studio的使用 试题答案
芦苇花开
鸿蒙学习试题集鸿蒙系统鸿蒙
【习题】DevEcoStudio的使用未通过/及格分80/满分100判断题1.如果代码中涉及到一些网络、数据库、传感器等功能的开发,均可使用预览器进行预览。正确(True)错误(False)正确答案:错误(False)2.module.json5文件中的deviceTypes字段中,配置了phone,tablet,2in1等多种设备类型,才能进行多设备预览。正确(True)错误(False)正确答
- C++每日一练——day 1
「已注销」
#C++每日一练C++c++
年轻人,你渴望拥有C++练习题吗???从这篇博文开始,我每天都会更新一个C++主要知识点题目,并附上解析!~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~Dayone——解密题目描述给你这样一个任务:解密一份被加密过的文件。经过研究,你发现了加密文件有如下加密规律(括号中是一个“原文一>密文”的例子)
- Python中三种表示NA的方式
风语者666
python
Python中三种表示NA的方式#-*-coding:utf-8-*-importnumpyasnpimportpandasaspd#data_frame=np.load('a.npy',allow_pickle=True)#print(data_frame.columns)df=pd.DataFrame({'one':[1,2,3,pd.NA]})df=pd.DataFrame({'one':[
- AI 之路——数据分析(1)Pandas小结与框架整理
Robin_Pi
机器学习之路数据分析数据分析python人工智能可视化
目录1.写在前面1.1AI之路:1.2工具/技能:2.数据分析2.1数据分析的流程2.2数据的基本操作方法2.2.1Pandas概览2.2.2使用Pandas操作数据的核心(1)选择数据(2)操作数据2.2.2数据详解3.写在最后1.写在前面主要是阶段性框架总结1.1AI之路:数据分析——机器学习——深度学习——CV/NLP1.2工具/技能:Python、NumPy、Pandas、Matplotl
- python/R 连接 clickhouse
weixin_41283198
pythonclickhouser语言python大数据r语言
1、python-clickhouseimportnumpyasnpfromclickhouse_driverimportClientimportpandasaspdsql=open('/opt/check_detect_local.sql','r',encoding='utf8')sqltxt=sql.readlines()print(len(sqltxt))sqls=[]foriinnp.ar
- CSDN每日一练
文盲老顾
算法每日一练
每日一练不会做的题目n边形划分K树盗版解锁密码小豚鼠搬家清理磁盘空间待更新未能完全通过case的题目拯救爱情环形单向链表硬币的面值(CSDN已修改用例数据,2023-2-14)小计不会做的题目n边形划分练习题地址https://edu.csdn.net/skill/program/28790?practiceId=19348927题目名称:n边形划分时间限制:1000ms内存限制:256M题目描述
- Python Pandas带多组参数和标签的Snowflake数据库批量数据导出程序
weixin_30777913
pandaspython云计算数据仓库
设计一个基于多个带标签的SnowflakeSQL模板作为配置文件和多组参数的PythonPandas代码程序,实现根据不同的输入参数自动批量地将Snowflake数据库中的数据导出为CSV文件到指定目录上,然后逐个文件压缩为zip文件,标签和多个参数(以“_”分割)为组成导出数据文件名,文件已经存在则覆盖原始文件。需要考虑SQL结果集是大数据量分批数据导出的情况,通过多线程和异步操作来提高程序性能
- 《信息系统安全》课后习题答案(陈萍)
1ce0range
系统安全安全
第一章一、填空题1、机密性、完整性、可用性2、主动3、设备安全、数据安全、内容安全、行为安全4、通信保密、信息安全、信息安全保障5、保护、检测、响应、恢复二、选择题1、D2、C3、B4、A5、D6、A7、C8、B9、A10、B第二章一、填空题1、《保密系统的信息理论》,DES,RSA2、相同、存在确定的转换关系3、单向、机密性、不可否认性4、混淆、扩散5、完整性6、流密码7、密钥8、穷举法、分析法
- Python Pandas实现dataframe导出为Excel 2007格式的文件并设置合适的列宽度
weixin_30777913
pandaspython开发语言excel
PythonPandas实现dataframe导出为Excel2007格式的文件,并且针对每一列的数据调整到合适宽度,并封装为函数。此函数能够有效处理大多数情况下的列宽调整需求,确保Excel文件内容清晰易读。将PandasDataFrame导出为Excel2007+格式(.xlsx)并自动调整列宽,可以使用以下函数。该函数会处理索引列和数据列,确保每列宽度适合内容。importpandasasp
- Python中Pandas常用函数及案例详解
程序员爱技术
pythonpandas开发语言数据分析大数据
Pandas是一个强大的Python数据分析工具库,它为Python提供了快速、灵活且表达能力强的数据结构,旨在使“关系”或“标签”数据的操作既简单又直观。Pandas的核心数据结构是DataFrame,它是一个二维标签化数据结构,可以看作是一个表格,其中可以存储不同类型的数据。下面是Pandas中一些关于导入、导出、查看、检查、选取、清理、合并、统计等常用函数的详解以及案例说明:第一、导入函数P
- 解决pandas的to_excel方法写入数据被覆盖的问题
hobbies.
pandasexcelpython
1.先用openpyxl读取到了excel文件的数据,载入excel文件的内容到ExcelWriter中,使用ExcelWriter写入保存importpandasaspdfromopenpyxlimportload_workbookdf=pd.DataFrame([66])withpd.ExcelWriter(r'C:\Users\Administrator\Desktop\1.xlsx')as
- Pandas:to_excel 在原Excel表 追加写入数据
条件漫步
pythonpython
@创建于:20211118文章目录1、直接写入2、直接写入3、参考链接1、直接写入如果只是想把一个DataFrame保存为单独的一个Excel文件,那么直接写:df_data.to_excel('xxx.excel','sheet1',index=False)保存为单个Excel文件和这个文件中的单个表。如果先前存在有同名的Excel文件,这样做会把之前的Excel文件覆盖掉。2、直接写入ifno
- 4种方法用Python批量实现多Excel多Sheet合并_excel表格自动合成python
2401_84010702
程序员pythonexcel开发语言
importpandasaspd #读取Excel文件 file_list=['file1.xlsx','file2.xlsx'] dfs=[pd.read_excel(file)forfileinfile_list] #合并多个工作表 result=pd.concat(dfs,ignore_index=True) #保存到新的Excel文件 result.to_excel('merg
- 【go语言圣经】习题答案 第一章
flying_elephant
研发管理go
自己写了点gopl的练习题,发个答案大家共勉一下。有问题也请大佬指教。第一章练习题答案1.11.2打印命令行参数1.4打印重复出现的某行代码及其出现位置1.5替换gif图像颜色1.7使用io.Copy代替read方法get网页内容1.8为请求连接增添HTTPS前缀1.9获取HTTP返回的状态码1.11对每个URL执行两遍请求,查看两次时间是否有较大的差别,并且每次获取到的响应内容是否一致1.12修
- pandas常用数据格式IO性能对比
lining808
Pythonpandaspython数据分析
前言本文对pandas支持的一些数据格式进行IO(读写)的性能测试,大数据时代以数据为基础,经常会遇到操作大量数据的情景,数据的IO性能尤为重要,本文对常见的数据格式csv、feather、hdf5、jay、parquet、pickle性能进行对比。csvCSV(Comma-SeparatedValues)是一种用于存储表格数据的简单文件格式。在CSV文件中,每一行通常代表一条记录,字段(列)由逗
- Python数据分析NumPy和pandas(十七、pandas 二进制格式文件处理)
FreedomLeo1
Python数据分析python数据分析pandasHDF5PyTablesh5pyExcel
以二进制格式存储(或序列化)数据的一种简单方法是使用Python的内置pickle模块。同时,pandas构造的对象都有一个to_pickle方法,该方法以pickle格式将数据写入磁盘。我们先把之前示例用到的ex1.csv文件加载到pandas对象中,然后将数据以二进制pickle格式写入examples/frame_pickle文件中:importpandasaspdframe=pd.read
- python语言字符串练习题
微__凉
习题集python开发语言numpy
第1关:求字符串的长度任务描述本关需要你编写一个程序,输出字符串的长度。相关知识len()方法描述:Python中的len()方法返回对象(字符、列表、元组等)的长度。####编程要求comment:<>(“编程要求”部分说一下本关要解决的问题的具体要求,并给出相应代码的框架,以及要求学生填写的那一块)命令行随机输入一个字符串,输出其长度测试举例:测试输入:1234预期输出:4importmath
- java字符串练习题_java练习题——字符串
阿呆java
java
一.动手动脑之String.equals()方法:判断s1和s2的内容相同s1.equals(s2)。判断s1和s2的地址相同s1==s2。二.整理String类的Length()、charAt()、getChars()、replace()、toUpperCase()、toLowerCase()、trim()、toCharArray()使用说明1、length()字符串的长度2、charAt()截
- C语言:5.20程序练习题
异步的告白
C语言初学c语言开发语言
打印一个菱形图案。程序分为两部分:上半部分和下半部分。上半部分打印一个逐渐增大的星号图案,下半部分打印一个逐渐缩小的星号图案。#includeintmain(){introw=5;//定义行数intt=2;for(inti=row;00;k--){putchar('');}for(intg=t-1;g>0;g--){putchar('*');}t=t+2;printf("\n");}t=t-4;f
- Pandas真实案例进阶:从数据清洗到高性能分析的完整指南
Eqwaak00
Pandaspython开发语言科技pandas
案例背景:电商用户行为分析假设某电商平台提供以下数据集(模拟数据包含100万条记录),需完成用户行为分析:user_logs.csv:用户浏览、加购、下单日志user_profiles.csv:用户地域、设备信息product_info.csv:商品类目、价格数据一、数据加载与内存优化1.1智能数据类型转换#列类型预设字典dtype_dict={'user_id':'category','even
- apache ftpserver-CentOS config
gengzg
apache
<server xmlns="http://mina.apache.org/ftpserver/spring/v1"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="
http://mina.apache.o
- 优化MySQL数据库性能的八种方法
AILIKES
sqlmysql
1、选取最适用的字段属性 MySQL可以很好的支持大数据量的存取,但是一般说来,数据库中的表越小,在它上面执行的查询也就会越快。因此,在创建表的时候,为了获得更好的 性能,我们可以将表中字段的宽度设得尽可能小。例如,在定义邮政编码这个字段时,如果将其设置为CHAR(255),显然给数据库增加了不必要的空间,甚至使用VARCHAR这种类型也是多余的,因为CHAR(6)就可以很
- JeeSite 企业信息化快速开发平台
Kai_Ge
JeeSite
JeeSite 企业信息化快速开发平台
平台简介
JeeSite是基于多个优秀的开源项目,高度整合封装而成的高效,高性能,强安全性的开源Java EE快速开发平台。
JeeSite本身是以Spring Framework为核心容器,Spring MVC为模型视图控制器,MyBatis为数据访问层, Apache Shiro为权限授权层,Ehcahe对常用数据进行缓存,Activit为工作流
- 通过Spring Mail Api发送邮件
120153216
邮件main
原文地址:http://www.open-open.com/lib/view/open1346857871615.html
使用Java Mail API来发送邮件也很容易实现,但是最近公司一个同事封装的邮件API实在让我无法接受,于是便打算改用Spring Mail API来发送邮件,顺便记录下这篇文章。 【Spring Mail API】
Spring Mail API都在org.spri
- Pysvn 程序员使用指南
2002wmj
SVN
源文件:http://ju.outofmemory.cn/entry/35762
这是一篇关于pysvn模块的指南.
完整和详细的API请参考 http://pysvn.tigris.org/docs/pysvn_prog_ref.html.
pysvn是操作Subversion版本控制的Python接口模块. 这个API接口可以管理一个工作副本, 查询档案库, 和同步两个.
该
- 在SQLSERVER中查找被阻塞和正在被阻塞的SQL
357029540
SQL Server
SELECT R.session_id AS BlockedSessionID ,
S.session_id AS BlockingSessionID ,
Q1.text AS Block
- Intent 常用的用法备忘
7454103
.netandroidGoogleBlogF#
Intent
应该算是Android中特有的东西。你可以在Intent中指定程序 要执行的动作(比如:view,edit,dial),以及程序执行到该动作时所需要的资料 。都指定好后,只要调用startActivity(),Android系统 会自动寻找最符合你指定要求的应用 程序,并执行该程序。
下面列出几种Intent 的用法
显示网页:
- Spring定时器时间配置
adminjun
spring时间配置定时器
红圈中的值由6个数字组成,中间用空格分隔。第一个数字表示定时任务执行时间的秒,第二个数字表示分钟,第三个数字表示小时,后面三个数字表示日,月,年,< xmlnamespace prefix ="o" ns ="urn:schemas-microsoft-com:office:office" />
测试的时候,由于是每天定时执行,所以后面三个数
- POJ 2421 Constructing Roads 最小生成树
aijuans
最小生成树
来源:http://poj.org/problem?id=2421
题意:还是给你n个点,然后求最小生成树。特殊之处在于有一些点之间已经连上了边。
思路:对于已经有边的点,特殊标记一下,加边的时候把这些边的权值赋值为0即可。这样就可以既保证这些边一定存在,又保证了所求的结果正确。
代码:
#include <iostream>
#include <cstdio>
- 重构笔记——提取方法(Extract Method)
ayaoxinchao
java重构提炼函数局部变量提取方法
提取方法(Extract Method)是最常用的重构手法之一。当看到一个方法过长或者方法很难让人理解其意图的时候,这时候就可以用提取方法这种重构手法。
下面是我学习这个重构手法的笔记:
提取方法看起来好像仅仅是将被提取方法中的一段代码,放到目标方法中。其实,当方法足够复杂的时候,提取方法也会变得复杂。当然,如果提取方法这种重构手法无法进行时,就可能需要选择其他
- 为UILabel添加点击事件
bewithme
UILabel
默认情况下UILabel是不支持点击事件的,网上查了查居然没有一个是完整的答案,现在我提供一个完整的代码。
UILabel *l = [[UILabel alloc] initWithFrame:CGRectMake(60, 0, listV.frame.size.width - 60, listV.frame.size.height)]
- NoSQL数据库之Redis数据库管理(PHP-REDIS实例)
bijian1013
redis数据库NoSQL
一.redis.php
<?php
//实例化
$redis = new Redis();
//连接服务器
$redis->connect("localhost");
//授权
$redis->auth("lamplijie");
//相关操
- SecureCRT使用备注
bingyingao
secureCRT每页行数
SecureCRT日志和卷屏行数设置
一、使用securecrt时,设置自动日志记录功能。
1、在C:\Program Files\SecureCRT\下新建一个文件夹(也就是你的CRT可执行文件的路径),命名为Logs;
2、点击Options -> Global Options -> Default Session -> Edite Default Sett
- 【Scala九】Scala核心三:泛型
bit1129
scala
泛型类
package spark.examples.scala.generics
class GenericClass[K, V](val k: K, val v: V) {
def print() {
println(k + "," + v)
}
}
object GenericClass {
def main(args: Arr
- 素数与音乐
bookjovi
素数数学haskell
由于一直在看haskell,不可避免的接触到了很多数学知识,其中数论最多,如素数,斐波那契数列等,很多在学生时代无法理解的数学现在似乎也能领悟到那么一点。
闲暇之余,从图书馆找了<<The music of primes>>和<<世界数学通史>>读了几遍。其中素数的音乐这本书与软件界熟知的&l
- Java-Collections Framework学习与总结-IdentityHashMap
BrokenDreams
Collections
这篇总结一下java.util.IdentityHashMap。从类名上可以猜到,这个类本质应该还是一个散列表,只是前面有Identity修饰,是一种特殊的HashMap。
简单的说,IdentityHashMap和HashM
- 读《研磨设计模式》-代码笔记-享元模式-Flyweight
bylijinnan
java设计模式
声明: 本文只为方便我个人查阅和理解,详细的分析以及源代码请移步 原作者的博客http://chjavach.iteye.com/
import java.util.ArrayList;
import java.util.Collection;
import java.util.HashMap;
import java.util.List;
import java
- PS人像润饰&调色教程集锦
cherishLC
PS
1、仿制图章沿轮廓润饰——柔化图像,凸显轮廓
http://www.howzhi.com/course/retouching/
新建一个透明图层,使用仿制图章不断Alt+鼠标左键选点,设置透明度为21%,大小为修饰区域的1/3左右(比如胳膊宽度的1/3),再沿纹理方向(比如胳膊方向)进行修饰。
所有修饰完成后,对该润饰图层添加噪声,噪声大小应该和
- 更新多个字段的UPDATE语句
crabdave
update
更新多个字段的UPDATE语句
update tableA a
set (a.v1, a.v2, a.v3, a.v4) = --使用括号确定更新的字段范围
- hive实例讲解实现in和not in子句
daizj
hivenot inin
本文转自:http://www.cnblogs.com/ggjucheng/archive/2013/01/03/2842855.html
当前hive不支持 in或not in 中包含查询子句的语法,所以只能通过left join实现。
假设有一个登陆表login(当天登陆记录,只有一个uid),和一个用户注册表regusers(当天注册用户,字段只有一个uid),这两个表都包含
- 一道24点的10+种非人类解法(2,3,10,10)
dsjt
算法
这是人类算24点的方法?!!!
事件缘由:今天晚上突然看到一条24点状态,当时惊为天人,这NM叫人啊?以下是那条状态
朱明西 : 24点,算2 3 10 10,我LX炮狗等面对四张牌痛不欲生,结果跑跑同学扫了一眼说,算出来了,2的10次方减10的3次方。。我草这是人类的算24点啊。。
然后么。。。我就在深夜很得瑟的问室友求室友算
刚出完题,文哥的暴走之旅开始了
5秒后
- 关于YII的菜单插件 CMenu和面包末breadcrumbs路径管理插件的一些使用问题
dcj3sjt126com
yiiframework
在使用 YIi的路径管理工具时,发现了一个问题。 <?php
- 对象与关系之间的矛盾:“阻抗失配”效应[转]
come_for_dream
对象
概述
“阻抗失配”这一词组通常用来描述面向对象应用向传统的关系数据库(RDBMS)存放数据时所遇到的数据表述不一致问题。C++程序员已经被这个问题困扰了好多年,而现在的Java程序员和其它面向对象开发人员也对这个问题深感头痛。
“阻抗失配”产生的原因是因为对象模型与关系模型之间缺乏固有的亲合力。“阻抗失配”所带来的问题包括:类的层次关系必须绑定为关系模式(将对象
- 学习编程那点事
gcq511120594
编程互联网
一年前的夏天,我还在纠结要不要改行,要不要去学php?能学到真本事吗?改行能成功吗?太多的问题,我终于不顾一切,下定决心,辞去了工作,来到传说中的帝都。老师给的乘车方式还算有效,很顺利的就到了学校,赶巧了,正好学校搬到了新校区。先安顿了下来,过了个轻松的周末,第一次到帝都,逛逛吧!
接下来的周一,是我噩梦的开始,学习内容对我这个零基础的人来说,除了勉强完成老师布置的作业外,我已经没有时间和精力去
- Reverse Linked List II
hcx2013
list
Reverse a linked list from position m to n. Do it in-place and in one-pass.
For example:Given 1->2->3->4->5->NULL, m = 2 and n = 4,
return
- Spring4.1新特性——页面自动化测试框架Spring MVC Test HtmlUnit简介
jinnianshilongnian
spring 4.1
目录
Spring4.1新特性——综述
Spring4.1新特性——Spring核心部分及其他
Spring4.1新特性——Spring缓存框架增强
Spring4.1新特性——异步调用和事件机制的异常处理
Spring4.1新特性——数据库集成测试脚本初始化
Spring4.1新特性——Spring MVC增强
Spring4.1新特性——页面自动化测试框架Spring MVC T
- Hadoop集群工具distcp
liyonghui160com
1. 环境描述
两个集群:rock 和 stone
rock无kerberos权限认证,stone有要求认证。
1. 从rock复制到stone,采用hdfs
Hadoop distcp -i hdfs://rock-nn:8020/user/cxz/input hdfs://stone-nn:8020/user/cxz/运行在rock端,即源端问题:报版本
- 一个备份MySQL数据库的简单Shell脚本
pda158
mysql脚本
主脚本(用于备份mysql数据库): 该Shell脚本可以自动备份
数据库。只要复制粘贴本脚本到文本编辑器中,输入数据库用户名、密码以及数据库名即可。我备份数据库使用的是mysqlump 命令。后面会对每行脚本命令进行说明。
1. 分别建立目录“backup”和“oldbackup” #mkdir /backup #mkdir /oldbackup
- 300个涵盖IT各方面的免费资源(中)——设计与编码篇
shoothao
IT资源图标库图片库色彩板字体
A. 免费的设计资源
Freebbble:来自于Dribbble的免费的高质量作品。
Dribbble:Dribbble上“免费”的搜索结果——这是巨大的宝藏。
Graphic Burger:每个像素点都做得很细的绝佳的设计资源。
Pixel Buddha:免费和优质资源的专业社区。
Premium Pixels:为那些有创意的人提供免费的素材。
- thrift总结 - 跨语言服务开发
uule
thrift
官网
官网JAVA例子
thrift入门介绍
IBM-Apache Thrift - 可伸缩的跨语言服务开发框架
Thrift入门及Java实例演示
thrift的使用介绍
RPC
POM:
<dependency>
<groupId>org.apache.thrift</groupId>