人脸识别技术发展及实用方案设计

作者 | 汪彪
责编 | 何永灿
人脸识别技术不但吸引了Google、Facebook、阿里、腾讯、百度等国内外互联网巨头的大量研发投入,也催生了Face++、商汤科技、Linkface、中科云从、依图等一大波明星创业公司,在视频监控、刑事侦破、互联网金融身份核验、自助通关系统等方向创造了诸多成功应用案例。本文试图梳理人脸识别技术发展,并根据作者在相关领域的实践给出一些实用方案设计,期待能对感兴趣的读者有所裨益。
概述
通俗地讲,任何一个的机器学习问题都可以等价于一个寻找合适变换函数的问题。例如语音识别,就是在求取合适的变换函数,将输入的一维时序语音信号变换到语义空间;而近来引发全民关注的围棋人工智能AlphaGo则是将输入的二维布局图像变换到决策空间以决定下一步的最优走法;相应的,人脸识别也是在求取合适的变换函数,将输入的二维人脸图像变换到特征空间,从而唯一确定对应人的身份。
一直以来,人们都认为围棋的难度要远大于人脸识别,因此,当AlphaGo以绝对优势轻易打败世界冠军李世乭九段和柯洁九段时,人们更惊叹于人工智能的强大。实际上,这一结论只是人们的基于“常识”的误解,因为从大多数人的切身体验来讲,即使经过严格训练,打败围棋世界冠军的几率也是微乎其微;相反,绝大多数普通人,即便未经过严格训练,也能轻松完成人脸识别的任务。然而,我们不妨仔细分析一下这两者之间的难易程度:在计算机的“眼里”,围棋的棋盘不过是个19x19的矩阵,矩阵的每一个元素可能的取值都来自于一个三元组{0,1,2},分别代表无子,白子及黑子,因此输入向量可能的取值数为3361;而对于人脸识别来讲,以一幅512x512的输入图像为例,它在计算机的“眼中”是一个512x512x3维的矩阵,矩阵的每一个元素可能的取值范围为0~255,因此输入向量可能的取值数为256786432。虽然,围棋AI和人脸识别都是寻求合适的变换函数f,但后者输入空间的复杂度显然远远大于前者。
对于一个理想的变换函数f而言,为了达到最优的分类效果,在变换后的特征空间上,我们希望同类样本的类内差尽可能小,同时不同类样本的类间差尽可能大。但是,理想是丰满的,现实却是骨感的。由于光照、表情、遮挡、姿态等诸多因素(如图1)的影响,往往导致不同人之间的差距比相同人之间差距更小,如图2。人脸识别算法发展的历史就是与这些识别影响因子斗争的历史。

图1 人脸识别的影响因素
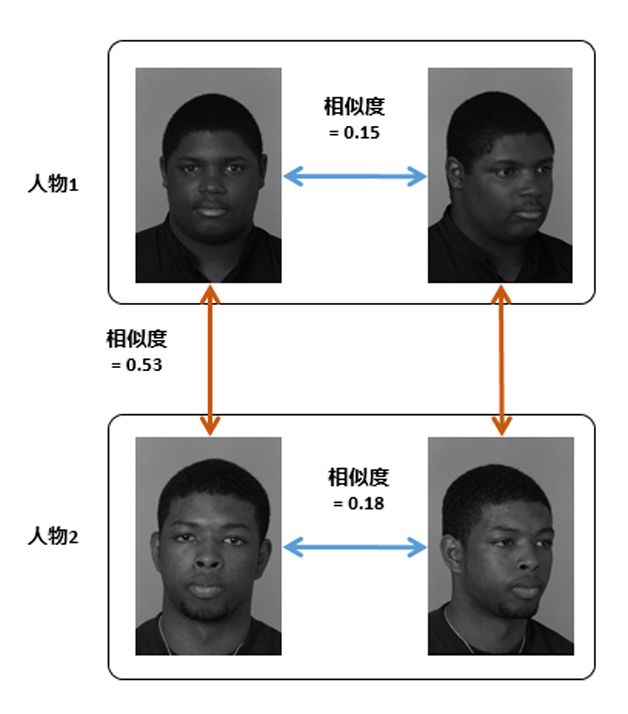
图2 姿态导致不同人相似度比同人更高
人脸识别技术发展
早在20世纪50年代,认知科学家就已着手对人脸识别展开研究。20世纪60年代,人脸识别工程化应用研究正式开启。当时的方法主要利用了人脸的几何结构,通过分析人脸器官特征点及其之间的拓扑关系进行辨识。这种方法简单直观,但是一旦人脸姿态、表情发生变化,则精度严重下降。
1991年,著名的“特征脸”方法[1]第一次将主成分分析和统计特征技术引入人脸识别,在实用效果上取得了长足的进步。这一思路也在后续研究中得到进一步发扬光大,例如,Belhumer成功将Fisher判别准则应用于人脸分类,提出了基于线性判别分析的Fisherface方法[2]。
21世纪的前十年,随着机器学习理论的发展,学者们相继探索出了基于遗传算法、支持向量机(Support Vector Machine, SVM)、boosting、流形学习以及核方法等进行人脸识别。 2009年至2012年,稀疏表达(Sparse Representation)[3]因为其优美的理论和对遮挡因素的鲁棒性成为当时的研究热点。
与此同时,业界也基本达成共识:基于人工精心设计的局部描述子进行特征提取和子空间方法进行特征选择能够取得最好的识别效果。Gabor[4]及LBP[5]特征描述子是迄今为止在人脸识别领域最为成功的两种人工设计局部描述子。这期间,对各种人脸识别影响因子的针对性处理也是那一阶段的研究热点,比如人脸光照归一化、人脸姿态校正、人脸超分辨以及遮挡处理等。也是在这一阶段,研究者的关注点开始从受限场景下的人脸识别转移到非受限环境下的人脸识别。LFW人脸识别公开竞赛在此背景下开始流行,当时最好的识别系统尽管在受限的FRGC测试集上能取得99%以上的识别精度,但是在LFW上的最高精度仅仅在80%左右,距离实用看起来距离颇远。
2013年,MSRA的研究者首度尝试了10万规模的大训练数据,并基于高维LBP特征和Joint Bayesian方法[6]在LFW上获得了95.17%的精度。这一结果表明:大训练数据集对于有效提升非受限环境下的人脸识别很重要。然而,以上所有这些经典方法,都难以处理大规模数据集的训练场景。
2014年前后,随着大数据和深度学习的发展,神经网络重受瞩目,并在图像分类、手写体识别、语音识别等应用中获得了远超经典方法的结果。香港中文大学的Sun Yi等人提出将卷积神经网络应用到人脸识别上[7],采用20万训练数据,在LFW上第一次得到超过人类水平的识别精度,这是人脸识别发展历史上的一座里程碑。自此之后,研究者们不断改进网络结构,同时扩大训练样本规模,将LFW上的识别精度推到99.5%以上。如表1所示,我们给出了人脸识别发展过程中一些经典的方法及其在LFW上的精度,一个基本的趋势是:训练数据规模越来越大,识别精度越来越高。如果读者阅读有兴趣了解人脸识别更细节的发展历史,可以参考文献[8][9]。
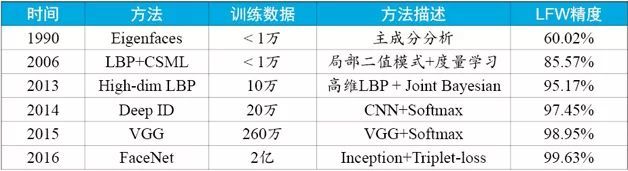
表1 人脸识别经典方法及其在LFW上精度对比
技术方案
要在实用中实现高精度的人脸识别,就必须针对人脸识别的挑战因素如光照、姿态、遮挡等进行针对性的设计。例如,针对光照和姿态因素,要么在收集训练样本时力求做到每个个体覆盖足够多的光照和姿态变化,要么设计出行之有效的预处理方法以补偿光照和姿态带来的人脸身份信息变化。图3给出了作者在相关领域的一些研究成果[10][11]。

表2 较为正常的人脸识别训练集
表2给出了本文用到的训练数据集,其中前3个是当前最主流的公开训练数据集,最后一个为私有业务数据集。表3出给了性能验证的两个数据集及测试协议,其中LFW是目前最主流的非受限人脸识别公开竞赛。我们注意到,大多数训练集都有较大噪声,如果不进行相应清洗操作,则训练会较难收敛。本文给出了一种快速可靠的数据清洗方法,如表4所示。

表3 本文用到的测试集

表4 一种快速可靠的训练数据清洗方法
图4给出了一套行之有效的人脸识别技术方案,主要包括多patch划分、CNN特征抽取、多任务学习/多loss融合,以及特征融合模块。
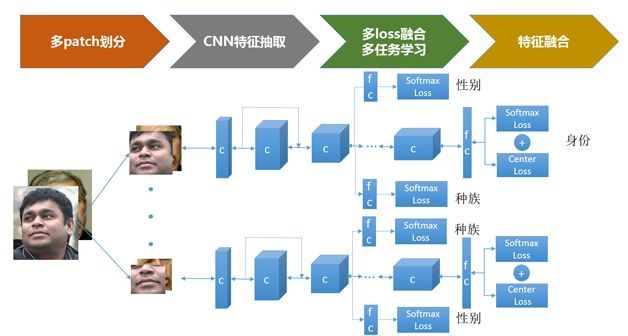
图4 人脸识别技术方案
多patch划分主要是利用人脸不同patch之间的互补信息增强识别性能。尤其是多个patch之间的融合能有效提升遮挡情况下的识别性能。当前,在LFW评测中超过99.50%的结果大多数是由多个patch融合得到。
经过验证较优秀的人脸特征抽取卷积神经网络包括:Deep-ID系列、VGG-Net、ResNet、Google Inception结构。读者可以根据自己对精度及效率的需求选择合适的网络。本文以19层resnet举例。
多任务学习主要是利用其他相关信息提升人脸识别性能。本文以性别和种族识别为例,这两种属性都是和具体人的身份强相关的,而其他的属性如表情、年龄都没有这个特点。我们在resnet的中间层引出分支进行种族和性别的多任务学习,这样CNN网络的前几层相当于具有了种族、性别鉴别力的高层语义信息,在CNN网络的后几层我们进一步学习了身份的细化鉴别信息。同时,训练集中样本的性别和种族属性可以通过一个baseline分类器进行多数投票得到。
多loss融合主要是利用不同loss之间的互补特性学习出适当的人脸特征向量,使得类内差尽可能小,类间差尽可能大。当前人脸识别领域较为常用的集中loss包括:pair-wise loss、triplet loss、softmax loss、center loss等。其中triplet loss直接定义了增大类内类间差gap的优化目标,但是在具体工程实践中,其trick较多,不容易把握。而最近提出的center loss,结合softmax loss,能较好地度量特征空间中的类内、类间差,训练配置也较为方便,因此使用较为广泛。
通过多个patch训练得到的模型将产生多个特征向量,如何融合多特征向量进行最终的身份识别也是一个重要的技术问题。较为常用的方案包括:特征向量拼接、分数级加权融合以及决策级融合(如投票)等。
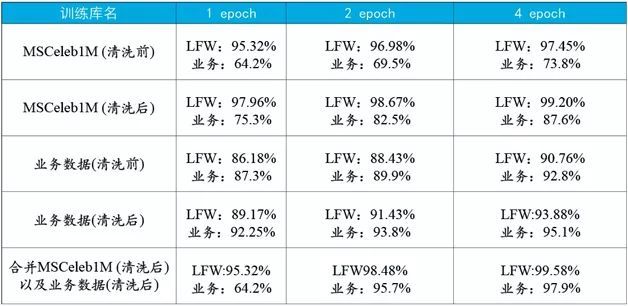
表5 数据清洗前后识别模型性能对比
表5给出了训练数据清洗前后在测试集上的性能对比结果。据此可以得到以下结论:
数据的清洗不但能加快模型训练,也能有效提升识别精度;
在西方人为主的训练集MSCeleb1M上训练得到的模型,在同样以西方人为主的测试集LFW上达到了完美的泛化性能;但是在以东方人为主的业务测试集的泛化性能则有较大的下滑;
在以东方人为主的业务训练集训练得到的模型,在东方人为主的业务测试集上性能非常好,但是在西方人为主的测试集LFW上相对MSCeleb1M有一定差距;
将业务训练集和MSCeleb1M进行合并,训练得到的模型在LFW和业务数据上都有近乎完美的性能。其中,基于三个patch融合的模型在LFW上得到了99.58%的识别精度。
由此,我们可以知道,为了达到尽可能高的实用识别性能,我们应该尽可能采用与使用环境相同的训练数据进行训练。同样的结论也出现在论文[12]中。
实际上,一个完整的人脸识别实用系统除了包括上述识别算法以外,还应该包括人脸检测,人脸关键点定位,人脸对齐等模块,在某些安全级别要求较高的应用中,为了防止照片、视频回放、3D打印模型等对识别系统的假冒攻击,还需要引入活体检测模块;为了在视频输入中取得最优的识别效果,还需要引入图像质量评估模块选择最合适的视频帧进行识别,以尽可能排除不均匀光照、大姿态、低分辨和运动模糊等因素对识别的影响。另外,也有不少研究者和公司试图通过主动的方式规避这些因素的影响:引入红外/3D摄像头。典型的实用人脸识别方案如图5所示。
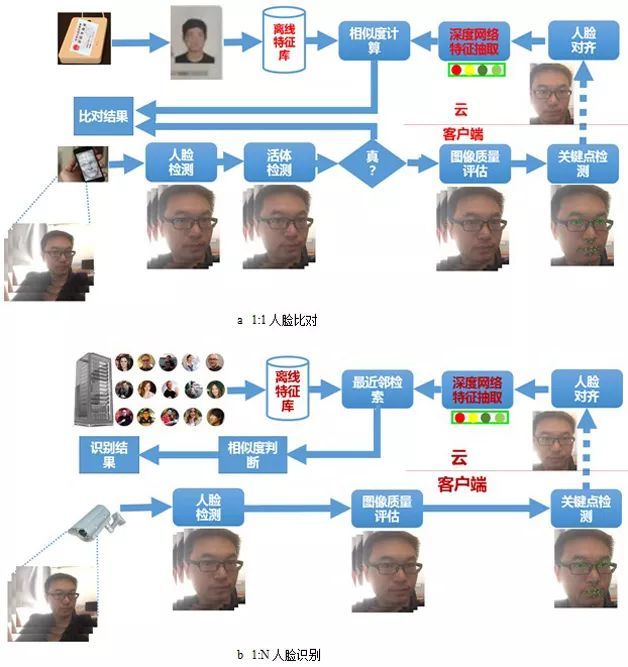
图5 实用人脸识别方案流程图
总结
本文简单总结了人脸识别技术的发展历史,并给出了实用方案设计的参考。虽然人脸识别技术在LFW公开竞赛中取得了99%以上的精度,但是在视频监控等实用场景下的1:N识别距离真正实用还有一段路要走,尤其是在N很大的情况下。未来,我们还需要在训练数据扩充、新模型设计及度量学习等方面投入更多的精力,让大规模人脸识别早日走入实用。
参考文献
[1]Turkand M A, Pengland A P. Eigenfaces for recognition [J]. Journal of Cognitve Neuroscience, 1991, 3(1): 71-86.
[2]Belhumeur P, Hespanha J, Kriegman D. Eigenfaces vs. fisherfaces: Recognition using class specific linear projection [J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 1997, 19(7): 711-720.
[3]Liu C, Wechsler. Gabor feature based classification using enhanced fisher linear model for face recognition [J]. IEEE Transactions on Image Processing, 2002, 11(4): 467-476.
[4]Ahonen T, Hadid A, Pietikäinen M. Face description with local binary patterns: Application to face recognition [J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2006, 28(12): 2037-2041.
[5]Wright J, Yang A, Ganesh A, Sastry S, Ma Y. Robust face recognition via sparse representation [J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2009, 31(2): 210-227.
[6]Chen D, Cao X, Wen F, Sun J. Blessing of dimensionality: high-dimensional feature and its efficient compression for face verification [C]. IEEE International Conference on Computer Vision and Pattern Recognition, 2013.
[7]Sun Y, Wang X, Tang X. Deep learning face representation by joint identification-Verification [C].
[8]Zhao W, Chellappa R, Rosenfeld A, Phillips P J. Face recognition: A literature survey [J]. ACM Computing Surveys, 2003, 35(4): 399-458.
[9]Li S Z, Jain A K. Handbook of face recognition (2nd Edition) [M]. Springer-Verlag, 2011.
[10]Wang B, Li W, Yang W, Liao Q. Illumination normalization based on Weber’s law with application to face recognition [J]. IEEE Signal Processing Letters, 2011, 18(8): 462-465.
[11]Wang Biao, Feng X, Gong L, Feng H, Hwang W, Han J. Robust Pose normalization for face recognition under varying views [C]. ICIP, 2015,
[12]Kan M. Domain Adaptation for face recognition: Targetize source domain briged by common subspace, IJCV, 2014.
作者简介:汪彪,阿里巴巴集团iDST视觉计算组算法专家。2013年从清华大学电子工程系博士毕业后加入北京三星研究院任责任研究员及开发组长。2016年加入阿里巴巴。从事人脸识别方向研究及开发近10年,累计发布论文/专利20余篇。
热文精选
亏本也要抢市场!谷歌亚马逊一路死磕到CES,争夺语音入口之路
AI领域真正最最最最最稀缺的人才是……会解牛的那个庖丁
2018年了,但愿你还有被剥削的价值!因为AI失业潮真的开始了...
2018 年了,该不该下定决心转型AI呢?
不用数学也能讲清贝叶斯理论的马尔可夫链蒙特卡洛方法?这篇文章做到了
先搞懂这八大基础概念,再谈机器学习入门!
这三个普通程序员,几个月就成功转型AI,他们的经验是...
干货 | AI 工程师必读,从实践的角度解析一名合格的AI工程师是怎样炼成的
AI校招程序员最高薪酬曝光!腾讯80万年薪领跑,还送北京户口
详解 | 如何用Python实现机器学习算法
