pytorch张量的.item()和.numpy()
pytorch张量的.item()和.numpy()
今天在加载一个pytorch代码时出现了在测试集上的精度计算为0的情况。于是小白我又懵圈了,代码明明是按书上敲的,怎么就是不对呢。代码本身非常简单,是一个MNIST数据集上的hello world代码。但没想到后面在测试集上的精度计算却给我来了一个意外的“惊喜”。(后面有MNIST的整个代码,和我写的精度为零的部分。),经过参考https://www.jianshu.com/p/be3276b434b2文章上的相关内容,我也只是知道了一个大概的修改方法,并在最后留下了一个疑问,至于为什么会这样,还是希望哪位路过的大神给解释一下。
问题描述:
在使用最后的代码进行求解精度的时候,精度的计算为0。出错代码行:
print('Accuracy of the network on the 10000 test images: %d %%'%(100*(correct/total)))输出的内容为:
![]()
解决办法:
经过分别打印correct和total的类型,发现correct是tensor类型,而total是int类型,因此想到pytorch可以通过.numpy()和torch.from_numpy()实现tensor和numpy的ndarray类型之间的转换,如下例:
x = torch.rand(5,3)
y = x.numpy()
z = torch.from_numpy(y)同时,对于1维的pytorch.tensor或者tensor中的某一个元素来说同样了使用.itme()获取tensor中的内容。于是我变将上面的print程序改成了如下的形式:
print('Accuracy of the network on the 10000 test images: %d %%'%(100*(correct/total)))
print('Accuracy of the network on the 10000 test images: %d %%'%(100*(correct.numpy()/total)))
print('Accuracy of the network on the 10000 test images: %d %%'%(100*(correct.item()/total)))
print('correct',correct)
print('total',total)
print('type(correct)',type(correct))
print('type(correct.numpy())',type(correct.numpy()))
print('type(correct.item())',type(correct.item()))
print('type(total)',type(total))得到的结果如下:
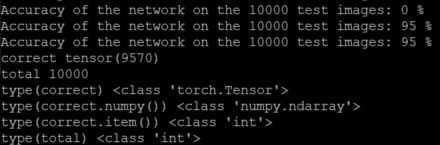
通过这个结果,可以看到correct.numpy()的类型是ndarray,而correct.item()的类型是int。但这两种方式都能够正确的计算精度了。问题解决了。
疑问:
虽然我通过上面的方法解决了这个问题,但是我还是留下了一个疑问,因为我发现如果把print语句改成如下的形式,也能够得到正确的精度,但是这种方式没有显示的改变correct的类型啊?请问有哪位路过的大神指点一下呗!小弟在此谢谢啦!
print('Accuracy of the network on the 10000 test images: %d %%'%(100*correct/total))完整代码:
大家如果感兴趣,可以试一下,注意修改download的参数,如果没有数据集就改成True吧,还有num_epochs我是为了图省事儿,才设定为1的。
from __future__ import print_function
import torch
import torch.nn as nn
import torchvision.datasets as dsets
import torchvision.transforms as transforms
from torch.autograd import Variable
torch.manual_seed(1)
input_size = 784
hidden_size = 500
num_classes = 10
num_epochs = 1
batch_size = 100
learning_rate = 0.001
train_dataset = dsets.MNIST(root = './data', train=True, transform=transforms.ToTensor(), download=False)
test_dataset = dsets.MNIST(root = './data', train = False, transform=transforms.ToTensor())
train_loader = torch.utils.data.DataLoader(dataset=train_dataset, batch_size=batch_size, shuffle=True)
test_loader = torch.utils.data.DataLoader(dataset=test_dataset, batch_size=batch_size, shuffle=False)
class Net(nn.Module):
def __init__(self, input_size, hidden_size, num_classes):
super(Net, self).__init__()
self.fc1 = nn.Linear(input_size, hidden_size)
self.relu = nn.ReLU()
self.fc2 = nn.Linear(hidden_size, num_classes)
def forward(self, x):
out = self.fc1(x)
out = self.relu(out)
out = self.fc2(out)
return out
net = Net(input_size, hidden_size, num_classes)
print(net)
criterion = nn.CrossEntropyLoss()
optimizer = torch.optim.Adam(net.parameters(), lr=learning_rate)
for epoch in range(num_epochs):
for i, (images, labels) in enumerate(train_loader):
images = Variable(images.view(-1, 28*28))
labels = Variable(labels)
optimizer.zero_grad()
outputs = net(images)
loss = criterion(outputs, labels)
loss.backward()
optimizer.step()
if (i+1) % 100 == 0:
print('Epoch [%d/%d], Step[%d/%d], Loss: %.4f'%(epoch+1, num_epochs, i+1, len(train_dataset)//batch_size, loss.item()))
correct = 0
total = 0
for images, labels in test_loader:
images = Variable(images.view(-1, 28*28))
outputs = net(images)
_, predicted = torch.max(outputs.data, 1)
total += labels.size(0)
correct += (predicted == labels).sum()
print('Accuracy of the network on the 10000 test images: %d %%'%(100*correct/total))
print('Accuracy of the network on the 10000 test images: %d %%'%(100*(correct/total)))
print('Accuracy of the network on the 10000 test images: %d %%'%(100*(correct.numpy()/total)))
print('Accuracy of the network on the 10000 test images: %d %%'%(100*(correct.item()/total)))
print('correct',correct)
print('total',total)
print('type(correct)',type(correct))
print('type(correct.numpy())',type(correct.numpy()))
print('type(correct.item())',type(correct.item()))
print('type(total)',type(total))