CRNN+CTC实现不定长验证码识别(keras模型-示例篇)
目录
- 前言
- 运行环境
- 生成数据集
- 构建网络模型
- 训练模型
- 测试模型
- 错误集锦
- 结语
前言
本文的重心在于如何使用以tensorflow作为后端的keras构建一个使用CTC为loss的简化版CRNN,同时指出构建过程中容易出错的地方,让像我一样的初学者少踩坑。因此,本文不着重原理的阐述、网络结构优化等内容,并假定读者已经了解过CTC、CNN、RNN的基本原理,以及LSTM的工作原理。另外,需要解释的是这里的不定长有两层含义,一是验证码长度不定长,二是图片长度不定长。而为了缩短训练时间,这里暂时只使用纯数字验证码作为样本。关于CRNN与CTC的细节,详见https://zhuanlan.zhihu.com/p/43534801。
运行环境
- python环境(anaconda+python3.7.3)
| 第三方库 | 版本 |
|---|---|
| tensorflow-gpu | 1.13.1 |
| captcha | 0.3 |
| opencv-python | 4.1.0 |
| numpy | 1.16.4 |
p.s.: 由于以下部分代码使用了f-string格式字符串,因此要求python版本 ≥ \geq ≥ 3.6
- 硬件环境
gpu:GT940MX
cpu:i7-7500U
生成数据集
我们通过使用captcha这个第三方库,可以方便地生成各种图片大小及各种验证码长度的带干扰验证码样本,下面是使用这个库生成的数字验证码



这里我们利用它使用其默认图片大小随机生成长度从4到7的纯数字验证码各最多10000张(由于是随机生成图片,可能导致出现重复标签的图片覆盖之前已有的图片),并保存到当前工作目录的img_dir目录下,代码如下
from captcha.image import ImageCaptcha
import os
import random
import string
chars = string.digits # 验证码字符集
def generate_img(img_dir: '图片保存目录'='img_dir'):
for length in range(4, 8): # 验证码长度
if not os.path.exists(f'{img_dir}/{length}'):
os.makedirs(f'{img_dir}/{length}')
for _ in range(10000):
img_generator = ImageCaptcha()
char = ''.join([random.choice(chars) for _ in range(length)])
img_generator.write(chars=char, output=f'{img_dir}/{length}/{char}.jpg')
generate_img()
生成图片后,我们使用opencv读取图片到内存中,缩小图片尺寸,固定宽度为32,并转为灰度图(每张图片的shape为【图片高度,图片宽度】),最后将图片真实标签编码为数字备用,代码如下
import cv2
import numpy as np
char_map = {chars[c]: c for c in range(len(chars))} # 验证码编码(0到len(chars) - 1)
def load_img(img_dir: '图片保存目录'='img_dir', min_length: '最小长度'=4, max_length: '最大长度'=7):
labels = {length: [] for length in range(min_length, max_length + 1)} # 验证码真实标签{长度:标签列表}
imgs = {length: [] for length in range(min_length, max_length + 1)} # 图片BGR数据字典{长度:BGR数据列表}
### 读取图片
for length in range(min_length, max_length + 1):
for file in os.listdir(f'{img_dir}/{length}'):
img = cv2.imread(f'{img_dir}/{length}/{file}')
labels[length].append(file[:-4])
height, width, _ = img.shape
h_resize = 32
w_resize = int(img.shape[1] * h_resize / img.shape[0])
img_gray = cv2.cvtColor(cv2.resize(img, (w_resize, h_resize)), cv2.COLOR_BGR2GRAY) # 缩小图片固定宽度为32,并转为灰度图
imgs[length].append(img_gray)
### 编码真实标签
labels_encode = {length: [] for length in range(min_length, max_length + 1)}
for length in range(min_length, max_length + 1):
for label in labels[length]:
label = [char_map[i] for i in label]
labels_encode[length].append(label)
load_img()
构建网络模型
我们先来看一下我们需要构建的网络整体的结构,如下图
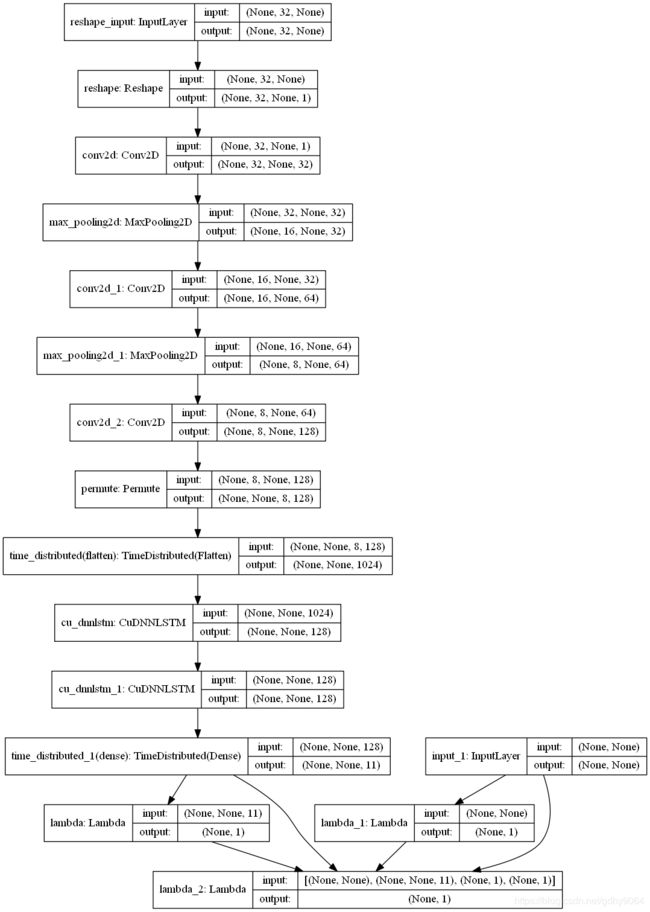
这里有几点需要解释一下:
- keras的网络层中与数据维度相关的参数都指的是单个样本的维度,没有包括样本维度。
- reshape的作用是将输入的灰度图数据的最后一维作为单独的一个通道(channel),这是因为卷积层的输入要求是shape为【样本数,图片高度,图片宽度,通道数】的四维数组,而我们的输入是shape为【样本数,图片高度,图片宽度】的三维数组。
- permute的作用是翻转输入的维度,Permute网络层参数中维度索引起始为1,在这里交换维度1和维度2,即与图片高度和宽度相关的维度,因为我们需要将图片宽度作为时间步提供给之后的LSTM层,并将图片高度和通道展开到同一维度作为LSTM层每一个时间步的输入数据。
- time_distributed(flatten) 的作用是将上一层输出的维度1当作样本维度,把剩下的维度的数据作为样本输入到Flatten层,展开维度2和维度3为同一维度。
- 由于我使用的是tensorflow-gpu,因此我使用CuDNNLSTM层代替LSTM层
- time_distributed_1(dense) 的作用是对上一层输出最后一个维度的数据使用Dense层,Dense层的节点为验证码字符集大小+1,这里的1代表空白分隔字符,Dense层的激活函数为softmax,这里的输出将用于后续ctc_loss的计算。
- lambda包装了计算时间步大小的函数,输出是shape为【样本数,1】,值为时间步大小的数组,用于ctc_loss的计算。
- lambda_1包装了计算真实标签长度的函数,输出是shape为【样本数,1】,值为标签长度的数组,用于ctc_loss的计算。
- input_1为编码后的真实标签输入,用于ctc_loss的计算。
- lambda_2包装了计算ctc_loss的函数,输出是shape为【样本数,1】,值为ctc损失值的数组,其使用了keras的ctc_batch_cost,ctc_batch_cost函数的参数有4个,各参数信息如下
| 参数名 | shape | 内容 |
|---|---|---|
| y_true | 【样本数,标签长度】 | 标签编码值 |
| y_pred | 【样本数,时间步数,验证码字符集大小+1】 | 各字符(包含空白分隔字符,索引为最后一位)的概率 |
| input_length | 【样本数,1】 | y_pred中各样本的时间步数 |
| label_length | 【样本数,1】 | y_true中各样本的标签长度 |
训练用模型的实现代码如下
import tensorflow as tf
import tensorflow.keras as keras
import tensorflow.keras.backend as K
from tensorflow.keras.layers import Conv2D
from tensorflow.keras.layers import CuDNNLSTM
from tensorflow.keras.layers import Dense
from tensorflow.keras.layers import Flatten
from tensorflow.keras.layers import Input
from tensorflow.keras.layers import Lambda
from tensorflow.keras.layers import LSTM
from tensorflow.keras.layers import MaxPooling2D
from tensorflow.keras.layers import Permute
from tensorflow.keras.layers import Reshape
from tensorflow.keras.layers import TimeDistributed
from tensorflow.keras.models import Model, Sequential
from tensorflow.keras.optimizers import Adadelta
def ctc_loss(args):
return K.ctc_batch_cost(*args)
labels_input = Input([None], dtype='int32')
sequential = Sequential([
Reshape([32, -1, 1], input_shape=[32, None]),
Conv2D(filters=32, kernel_size=(3, 3), activation='relu', padding='same'),
MaxPooling2D(pool_size=(2, 2)),
Conv2D(filters=64, kernel_size=(3, 3), activation='relu', padding='same'),
MaxPooling2D(pool_size=(2, 2)),
Conv2D(filters=128, kernel_size=(3, 3), activation='relu', padding='same'),
Permute((2, 1, 3)),
TimeDistributed(Flatten()),
CuDNNLSTM(units=128, return_sequences=True),
CuDNNLSTM(units=128, return_sequences=True),
TimeDistributed(Dense(len(chars) + 1, activation='softmax'))
])
input_length = Lambda(lambda x: K.tile([[K.shape(x)[1]]], [K.shape(x)[0], 1]))(sequential.output)
label_length = Lambda(lambda x: K.tile([[K.shape(x)[1]]], [K.shape(x)[0], 1]))(labels_input)
output = Lambda(ctc_loss)([labels_input, sequential.output, input_length, label_length])
fit_model = Model(inputs=[sequential.input, labels_input], outputs=output)
adadelta = Adadelta(lr=0.05)
fit_model.compile(
loss=lambda y_true, y_pred: y_pred,
optimizer=adadelta)
fit_model.summary()
其中K.tile的作用是将数组向数组的各个维度进行复制拓展。这里我们使用Adadelta作为优化器,通过试验发现设置的学习率过高或过低都会使得模型难以收敛,对于这里的情况而言,试验得到0.05的学习率比较合适。
训练模型
由于模型各网络层间数据的传递使用的是tf.Tensor,而它要求输入数据中各样本维度的shape是相同的,因此我们在训练过程中,需保证同一批次的训练数据具有相同的标签长度及图片宽度(这里不会出现图片宽度不等的情况)。这里我们利用keras.Model的训练接口fit_generator来随机生成数据训练模型,该函数需要传入一个数据生成器,生成器函数代码如下
def generate_data(imgs, labels_encode, batch_size):
imgs = {length: np.array(imgs[length]) for length in range(4, 8)} # 图片BGR数据字典{长度:BGR数据数组}
labels_encode = {length: np.array(labels_encode[length]) for length in range(4, 8)} # 验证码真实标签{长度:标签数组}
while True:
length = random.randint(4, 7)
test_idx = np.random.choice(range(len(imgs[length])), batch_size)
batch_imgs = imgs[length][test_idx]
batch_labels = labels_encode[length][test_idx]
yield ([batch_imgs, batch_labels], None) # 元组的第一个元素为输入,第二个元素为训练标签,即自定义loss函数时的y_true
在数据生成器的参数中,imgs表示之前处理好的灰度图数据, labels_encode表示编码后的真实标签数据,batch_size表示每次生成多少样本。这样以后我们可以开始训练模型了,训练代码如下
fit_model.fit_generator(
generate_data(imgs, labels_encode, 32),
epochs=100,
steps_per_epoch=100,
verbose=1)
在fit_generator的参数中,epochs表示要进行几轮的训练,steps_per_epoch表示每一轮生成多少批次的数据,即从数据生成器函数获取几次数据。我这里取每一次生成32个样本,每一轮生成100批次数据,共训练100轮。在训练的过程中,训练前期可以观察到模型的loss没有明显下降,而是在一个值附近起伏,这个时候模型预测得到的结果会一直是空白分隔字符占大概率,这是可以理解的,因为比起其他字符,空白分隔字符会使得loss更小。直到某一轮之后,loss才会开始下降(这里相当地迷惑人,起初我还以为模型不工作)。我自己试验的结果是在第30轮之后模型的loss开始有明显的下降,到第100轮基本能够下降到1以内。
测试模型
在完成了模型的训练之后,接下来可以开始测试模型了,不过在开始之前,我们先对模型的输出包装一下,生成一个可以直接预测得到编码结果的模型,代码如下
def ctc_decode(softmax):
return K.ctc_decode(softmax, K.tile([K.shape(softmax)[1]], [K.shape(softmax)[0]]))[0][0]
ctc_decode_output = Lambda(ctc_decode)(sequential.output)
model = Model(inputs=sequential.input, outputs=ctc_decode_output)
这里用到了keras中的ctc_decode函数,它的参数有两个,第一个参数是shape为【样本数,时间步数,字符集大小+1】,值为各字符概率的数组,第二个参数是shape为【样本数】,值为各样本时间步数的数组。其返回的结果为2个元素的列表,其中第一个元素是一个列表,里面仅包含我们所需标签编码的tf.SparseTensor,因此我们对该函数的输出结果取了两次第一个元素。模型的输出会自动将tf.SparseTensor转化为数组,而不需要在模型中手动先转换为tf.Tensor。之后我们便可以直接使用model预测标签的编码了,不过这里有一个地方要注意的是,模型预测的标签编码可能不是等长,对于同一批次的数据,长度较短的预测结果会自动在末尾补-1,以此保持整个批次的输出数据中各样本的shape一致;而对于不同批次的数据,在预测得到各个批次的输出数据后会将它们合并,由于不同批次的shape不一致,这一操作可能导致因shape大小不一致而无法合并的错误,因此我们需保证预测的数据都在同一批次内。为此我们使用模型的预测函数predict_on_batch强制输入数据在同一批次内,对于数据量较大的情况,我们需要手动分成多次进行预测。
首先,我们做好转换编码标签为字符串的相关准备,准备代码如下
idx_map = {value: key for key, value in char_map.items()} # 编码映射到字符
idx_map[-1] = '' # -1映射到空
def char_decode(label_encode):
return [''.join([idx_map[column] for column in row]) for row in label_encode]
其次,我们准备一个随机生成测试数据的生成器函数,其参数为每次生成的样本数,每次生成的样本为同一标签长度,代码如下
def generate_test_data(batch_size):
img_generator = ImageCaptcha()
while True:
test_labels_batch = []
test_imgs_batch = []
length = random.randint(4, 7)
for _ in range(batch_size):
char = ''.join([random.choice(chars) for _ in range(length)])
img = img_generator.generate_image(char)
img = np.asarray(img)
test_labels_batch.append(char)
h = 32
w = int(img.shape[1] * 32 / img.shape[0])
img_gray = cv2.cvtColor(cv2.resize(img, (w, h)), cv2.COLOR_BGR2GRAY)
test_imgs_batch.append(img_gray)
yield([np.array(test_imgs_batch), np.array(test_labels_batch)])
再次,我们开始使用该生成器测试模型实现测试模型的函数,其参数分别为每一轮的测试样本数和测试轮数,在测试过程中将打印出错误的预测结果,测试代码如下
def test(test_batch_size=32, test_iter_num=100):
error_cnt = 0
iterator = generate_test_data(test_batch_size)
for _ in range(test_iter_num):
test_imgs_batch, test_labels_batch = next(iterator)
labels_pred = model.predict_on_batch(np.array(test_imgs_batch))
labels_pred = char_decode(labels_pred)
for label, label_pred in zip(test_labels_batch, labels_pred):
if label != label_pred:
error_cnt += 1
print(f'{label} -> {label_pred}')
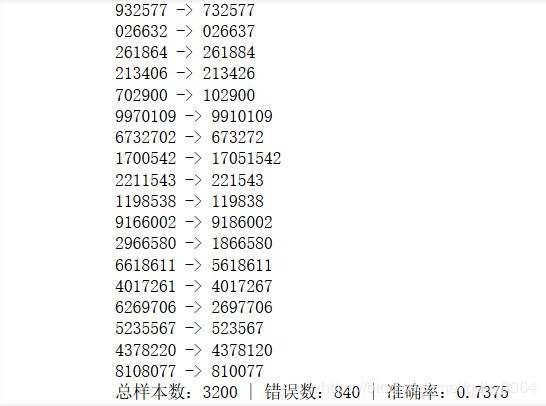
print(f'总样本数:{test_batch_size * test_iter_num} | '
f'错误数:{error_cnt} | '
f'准确率:{1 - error_cnt / test_batch_size / test_iter_num}')
经过测试,我们得到了这个模型的效果,如图
错误集锦
-
ValueError: Error when checking input: expected conv2d_16_input to have 4 dimensions, but got array with shape xxx
这个错误是由于输入的shape与conv2d的输入shape不一致造成,conv2d的输入要求为shape为【样本数,图片高度,图片宽度,通道数】的四维数组,像上面的模型输入是shape为【样本数,图片高度,图片宽度】的三维数组,因此如果之前没有一层reshape的话就会报错。 -
InvalidArgumentError (see above for traceback): Saw a non-null label (index >= num_classes - 1) following a null label, batch: 0 num_classes: xx labels: xx
在计算ctc_loss的时候,参数中正确标签的编码值取值范围为[0, 类别数],如纯数字的取值范围为[0, 10],最后一个编码值10代表空白分隔字符,一般在正确标签编码值中不出现,如果出现了,那么它之后不允许出现其他非空白分隔字符编码,否则就报错。
结语
尽管上面的模型并不适合直接用来实现验证码识别,但却足以达到keras搭建网络的演示效果。实现其他优化过的网络的过程也是与之大同小异的,可以根据自己需要更改网络层以优化网络结构,提高准确率。另外由于缩小图片尺寸及转为灰度图会减少图片的特征,也可在这一步进行自定义提高准确率。
完整代码:https://github.com/gdhy9064/crnn_ctc_simplified_for_digits_keras
2012.01.09更新: 添加了captcha库的验证码效果图,增加了部分tensorflow版keras接口出错解释