基于pytorch的segnet实现,使用camvid数据集训练
程序结构基本与https://blog.csdn.net/haohulala/article/details/107660273这篇文章相似,有什么问题也可以参考这篇文章。
import torch
from torch import nn
import torch.nn.functional as f
import torchvision
import torchvision.transforms as tfs
from torch.utils.data import DataLoader
from torch.autograd import Variable
import torchvision.models as models
import numpy as np
import os
from PIL import Image
import matplotlib.pyplot as plt
from datetime import datetime
# VOC数据集中对应的标签
classes = ["Animal", "Archway","Bicyclist","Bridge","Building","Car","CartLuggagePram",
"Child","Column_Pole", "Fence", "LaneMkgsDriv", "LaneMkgsNonDriv", "Misc_Text",
"MotorcycleScooter", "OtherMoving", "ParkingBlock", "Pedestrian", "Road", "RoadShoulder",
"Sidewalk", "SignSymbol", "Sky", "SUVPickupTruck", "TrafficCone", "TrafficLight",
"Train", "Tree", "Truck_Bus", "Tunnel", "VegetationMisc", "Void", "Wall"]
# 各种标签所对应的颜色
colormap = [[64,128,64],[192,0,128],[0,128,192],[0,128,64],[128,0,0],[64,0,128],
[64,0,192],[192,128,64],[192,192,128],[64,64,128],[128,0,192],[192,0,64],
[128,128,64],[192,0,192],[128,64,64],[64,192,128],[64,64,0],[128,64,128],
[128,128,192],[0,0,192],[192,128,128],[128,128,128],[64,128,192],[0,0,64],
[0,64,64],[192,64,128],[128,128,0],[192,128,192],[64,0,64],[192,192,0],
[0,0,0],[64,192,0]]
num_classes = len(classes)
print(num_classes)
print(len(colormap))
32
32
data_root = "./data"
ROOT = "./data/SegNet/CamVid"
# 开始读取数据
def read_image(mode="train", val=False):
if(mode=="train"): # 加载训练数据
filename = ROOT + "/train.txt"
elif(mode == "test"): # 加载测试数据
filename = ROOT + "/test.txt"
elif(mode == "val"):
filename = ROOT + "/val.txt"
else:
print("没有这个mod,请检查代码是否写错")
data = []
label = []
with open(filename, "r") as f:
images = f.read().split()
for i in range(len(images)):
if(i%2 == 0):
data.append(data_root+images[i])
else:
label.append(data_root+images[i])
if(val==True):
if(mode == "train"): # 将验证集也读入训练数据
filename = ROOT + "/val.txt"
with open(filename, "r") as f:
images = f.read().split()
for i in range(len(images)):
if(i%2 == 0):
data.append(data_root+images[i])
else:
label.append(data_root+images[i])
print(mode+":读取了"+str(len(data))+"张图片")
print(mode+":读取了"+str(len(label))+"张图片的标签")
return data, label
data, label = read_image("train")
print(data[:10], label[:10])
train:读取了367张图片
train:读取了367张图片的标签
['./data/SegNet/CamVid/train/0001TP_006690.png', './data/SegNet/CamVid/train/0001TP_006720.png', './data/SegNet/CamVid/train/0001TP_006750.png', './data/SegNet/CamVid/train/0001TP_006780.png', './data/SegNet/CamVid/train/0001TP_006810.png', './data/SegNet/CamVid/train/0001TP_006840.png', './data/SegNet/CamVid/train/0001TP_006870.png', './data/SegNet/CamVid/train/0001TP_006900.png', './data/SegNet/CamVid/train/0001TP_006930.png', './data/SegNet/CamVid/train/0001TP_006960.png'] ['./data/SegNet/CamVid/trainannot/0001TP_006690.png', './data/SegNet/CamVid/trainannot/0001TP_006720.png', './data/SegNet/CamVid/trainannot/0001TP_006750.png', './data/SegNet/CamVid/trainannot/0001TP_006780.png', './data/SegNet/CamVid/trainannot/0001TP_006810.png', './data/SegNet/CamVid/trainannot/0001TP_006840.png', './data/SegNet/CamVid/trainannot/0001TP_006870.png', './data/SegNet/CamVid/trainannot/0001TP_006900.png', './data/SegNet/CamVid/trainannot/0001TP_006930.png', './data/SegNet/CamVid/trainannot/0001TP_006960.png']
im = Image.open(data[0])
lab = Image.open(label[0])
plt.subplot(1,2,1), plt.imshow(im)
plt.subplot(1,2,2), plt.imshow(lab)
lab = np.array(lab)
print(lab.shape)
lab = torch.from_numpy(lab)
print(lab.shape)
im = tfs.ToTensor()(im)
print(im.shape)
(360, 480)
torch.Size([360, 480])
torch.Size([3, 360, 480])

size = 224
def crop(data, label, height=size, width=size):
st_x = 50
st_y = 50
box = (st_x, st_y, st_x+width, st_y+height)
data = data.crop(box)
label = label.crop(box)
return data, label
im = Image.open(data[0])
lab = Image.open(label[0])
im, lab = crop(im, lab)
plt.subplot(1,2,1), plt.imshow(im)
plt.subplot(1,2,2), plt.imshow(lab)
(,
)

def image_transforms(data, label, height=size, width=size):
data, label = crop(data, label, height, width)
# 将数据转换成tensor,并且做标准化处理
im_tfs = tfs.Compose([
tfs.ToTensor(),
tfs.Normalize([0.485, 0.456, 0.406], [0.229, 0.224, 0.225])
])
data = im_tfs(data)
label = np.array(label)
label = torch.from_numpy(label).long()
return data, label
im = Image.open(data[0])
lab = Image.open(label[0])
im, lab = image_transforms(im, lab)
print(im.shape)
print(lab.shape)
torch.Size([3, 224, 224])
torch.Size([224, 224])
class CamVidDataset(torch.utils.data.Dataset):
# 构造函数
def __init__(self, mode="train", height=size, width=size, transforms=image_transforms):
self.height = height
self.width = width
self.transforms = transforms
data_list, label_list = read_image(mode=mode)
self.data_list = data_list
self.label_list = label_list
# 重载getitem函数,使类可以迭代
def __getitem__(self, idx):
img = self.data_list[idx]
label = self.label_list[idx]
img = Image.open(img)
label = Image.open(label)
img, label = self.transforms(img, label, self.height, self.width)
return img, label
def __len__(self):
return len(self.data_list)
height = size
width = size
camvid_train = CamVidDataset(mode="train")
camvid_test = CamVidDataset(mode="test")
train_data = DataLoader(camvid_train, batch_size=1, shuffle=True)
valid_data = DataLoader(camvid_test, batch_size=1)
train:读取了367张图片
train:读取了367张图片的标签
test:读取了233张图片
test:读取了233张图片的标签
# 计算混淆矩阵
def _fast_hist(label_true, label_pred, n_class):
# mask在和label_true相对应的索引的位置上填入true或者false
# label_true[mask]会把mask中索引为true的元素输出
mask = (label_true >= 0) & (label_true < n_class)
# np.bincount()会给出索引对应的元素个数
"""
hist是一个混淆矩阵
hist是一个二维数组,可以写成hist[label_true][label_pred]的形式
最后得到的这个数组的意义就是行下标表示的类别预测成列下标类别的数量
比如hist[0][1]就表示类别为1的像素点被预测成类别为0的数量
对角线上就是预测正确的像素点个数
n_class * label_true[mask].astype(int) + label_pred[mask]计算得到的是二维数组元素
变成一位数组元素的时候的地址取值(每个元素大小为1),返回的是一个numpy的list,然后
np.bincount就可以计算各中取值的个数
"""
hist = np.bincount(
n_class * label_true[mask].astype(int) +
label_pred[mask], minlength=n_class ** 2).reshape(n_class, n_class)
return hist
"""
label_trues 正确的标签值
label_preds 模型输出的标签值
n_class 数据集中的分类数
"""
def label_accuracy_score(label_trues, label_preds, n_class):
"""Returns accuracy score evaluation result.
- overall accuracy
- mean accuracy
- mean IU
- fwavacc
"""
hist = np.zeros((n_class, n_class))
# 一个batch里面可能有多个数据
# 通过迭代器将一个个数据进行计算
for lt, lp in zip(label_trues, label_preds):
# numpy.ndarray.flatten将numpy对象拉成1维
hist += _fast_hist(lt.flatten(), lp.flatten(), n_class)
# np.diag(a)假如a是一个二维矩阵,那么会输出矩阵的对角线元素
# np.sum()可以计算出所有元素的和。如果axis=1,则表示按行相加
"""
acc是准确率 = 预测正确的像素点个数/总的像素点个数
acc_cls是预测的每一类别的准确率(比如第0行是预测的类别为0的准确率),然后求平均
iu是召回率Recall,公式上面给出了
mean_iu就是对iu求了一个平均
freq是每一类被预测到的频率
fwavacc是频率乘以召回率,我也不知道这个指标代表什么
"""
acc = np.diag(hist).sum() / hist.sum()
acc_cls = np.diag(hist) / hist.sum(axis=1)
# nanmean会自动忽略nan的元素求平均
acc_cls = np.nanmean(acc_cls)
iu = np.diag(hist) / (hist.sum(axis=1) + hist.sum(axis=0) - np.diag(hist))
mean_iu = np.nanmean(iu)
freq = hist.sum(axis=1) / hist.sum()
fwavacc = (freq[freq > 0] * iu[freq > 0]).sum()
return acc, acc_cls, mean_iu, fwavacc
class SegNet(nn.Module):
def __init__(self,input_nbr,label_nbr):
super(SegNet, self).__init__()
batchNorm_momentum = 0.1
self.conv11 = nn.Conv2d(input_nbr, 64, kernel_size=3, padding=1)
self.bn11 = nn.BatchNorm2d(64, momentum= batchNorm_momentum)
self.conv12 = nn.Conv2d(64, 64, kernel_size=3, padding=1)
self.bn12 = nn.BatchNorm2d(64, momentum= batchNorm_momentum)
self.conv21 = nn.Conv2d(64, 128, kernel_size=3, padding=1)
self.bn21 = nn.BatchNorm2d(128, momentum= batchNorm_momentum)
self.conv22 = nn.Conv2d(128, 128, kernel_size=3, padding=1)
self.bn22 = nn.BatchNorm2d(128, momentum= batchNorm_momentum)
self.conv31 = nn.Conv2d(128, 256, kernel_size=3, padding=1)
self.bn31 = nn.BatchNorm2d(256, momentum= batchNorm_momentum)
self.conv32 = nn.Conv2d(256, 256, kernel_size=3, padding=1)
self.bn32 = nn.BatchNorm2d(256, momentum= batchNorm_momentum)
self.conv33 = nn.Conv2d(256, 256, kernel_size=3, padding=1)
self.bn33 = nn.BatchNorm2d(256, momentum= batchNorm_momentum)
self.conv41 = nn.Conv2d(256, 512, kernel_size=3, padding=1)
self.bn41 = nn.BatchNorm2d(512, momentum= batchNorm_momentum)
self.conv42 = nn.Conv2d(512, 512, kernel_size=3, padding=1)
self.bn42 = nn.BatchNorm2d(512, momentum= batchNorm_momentum)
self.conv43 = nn.Conv2d(512, 512, kernel_size=3, padding=1)
self.bn43 = nn.BatchNorm2d(512, momentum= batchNorm_momentum)
self.conv51 = nn.Conv2d(512, 512, kernel_size=3, padding=1)
self.bn51 = nn.BatchNorm2d(512, momentum= batchNorm_momentum)
self.conv52 = nn.Conv2d(512, 512, kernel_size=3, padding=1)
self.bn52 = nn.BatchNorm2d(512, momentum= batchNorm_momentum)
self.conv53 = nn.Conv2d(512, 512, kernel_size=3, padding=1)
self.bn53 = nn.BatchNorm2d(512, momentum= batchNorm_momentum)
self.conv53d = nn.Conv2d(512, 512, kernel_size=3, padding=1)
self.bn53d = nn.BatchNorm2d(512, momentum= batchNorm_momentum)
self.conv52d = nn.Conv2d(512, 512, kernel_size=3, padding=1)
self.bn52d = nn.BatchNorm2d(512, momentum= batchNorm_momentum)
self.conv51d = nn.Conv2d(512, 512, kernel_size=3, padding=1)
self.bn51d = nn.BatchNorm2d(512, momentum= batchNorm_momentum)
self.conv43d = nn.Conv2d(512, 512, kernel_size=3, padding=1)
self.bn43d = nn.BatchNorm2d(512, momentum= batchNorm_momentum)
self.conv42d = nn.Conv2d(512, 512, kernel_size=3, padding=1)
self.bn42d = nn.BatchNorm2d(512, momentum= batchNorm_momentum)
self.conv41d = nn.Conv2d(512, 256, kernel_size=3, padding=1)
self.bn41d = nn.BatchNorm2d(256, momentum= batchNorm_momentum)
self.conv33d = nn.Conv2d(256, 256, kernel_size=3, padding=1)
self.bn33d = nn.BatchNorm2d(256, momentum= batchNorm_momentum)
self.conv32d = nn.Conv2d(256, 256, kernel_size=3, padding=1)
self.bn32d = nn.BatchNorm2d(256, momentum= batchNorm_momentum)
self.conv31d = nn.Conv2d(256, 128, kernel_size=3, padding=1)
self.bn31d = nn.BatchNorm2d(128, momentum= batchNorm_momentum)
self.conv22d = nn.Conv2d(128, 128, kernel_size=3, padding=1)
self.bn22d = nn.BatchNorm2d(128, momentum= batchNorm_momentum)
self.conv21d = nn.Conv2d(128, 64, kernel_size=3, padding=1)
self.bn21d = nn.BatchNorm2d(64, momentum= batchNorm_momentum)
self.conv12d = nn.Conv2d(64, 64, kernel_size=3, padding=1)
self.bn12d = nn.BatchNorm2d(64, momentum= batchNorm_momentum)
self.conv11d = nn.Conv2d(64, label_nbr, kernel_size=3, padding=1)
def forward(self, x):
# Stage 1 (224*224)->(112*112)
x11 = f.relu(self.bn11(self.conv11(x)))
x12 = f.relu(self.bn12(self.conv12(x11)))
x1p, id1 = f.max_pool2d(x12,kernel_size=2, stride=2,return_indices=True)
# Stage 2 (112*112)->(56*56)
x21 = f.relu(self.bn21(self.conv21(x1p)))
x22 = f.relu(self.bn22(self.conv22(x21)))
x2p, id2 = f.max_pool2d(x22,kernel_size=2, stride=2,return_indices=True)
# Stage 3 (56*56)->(28*28)
x31 = f.relu(self.bn31(self.conv31(x2p)))
x32 = f.relu(self.bn32(self.conv32(x31)))
x33 = f.relu(self.bn33(self.conv33(x32)))
x3p, id3 = f.max_pool2d(x33,kernel_size=2, stride=2,return_indices=True)
# Stage 4 (28*28)->(14*14)
x41 = f.relu(self.bn41(self.conv41(x3p)))
x42 = f.relu(self.bn42(self.conv42(x41)))
x43 = f.relu(self.bn43(self.conv43(x42)))
x4p, id4 = f.max_pool2d(x43,kernel_size=2, stride=2,return_indices=True)
# Stage 5 (14*14)->(7*7)
x51 = f.relu(self.bn51(self.conv51(x4p)))
x52 = f.relu(self.bn52(self.conv52(x51)))
x53 = f.relu(self.bn53(self.conv53(x52)))
x5p, id5 = f.max_pool2d(x53,kernel_size=2, stride=2,return_indices=True)
# Stage 5d (7*7)->(14*14)
x5d = f.max_unpool2d(x5p, id5, kernel_size=2, stride=2)
x53d = f.relu(self.bn53d(self.conv53d(x5d)))
x52d = f.relu(self.bn52d(self.conv52d(x53d)))
x51d = f.relu(self.bn51d(self.conv51d(x52d)))
# Stage 4d (14*14)->(28*28)
x4d = f.max_unpool2d(x51d, id4, kernel_size=2, stride=2)
x43d = f.relu(self.bn43d(self.conv43d(x4d)))
x42d = f.relu(self.bn42d(self.conv42d(x43d)))
x41d = f.relu(self.bn41d(self.conv41d(x42d)))
# Stage 3d (28*28)->(56*56)
x3d = f.max_unpool2d(x41d, id3, kernel_size=2, stride=2)
x33d = f.relu(self.bn33d(self.conv33d(x3d)))
x32d = f.relu(self.bn32d(self.conv32d(x33d)))
x31d = f.relu(self.bn31d(self.conv31d(x32d)))
# Stage 2d (56*56)->(112*112)
x2d = f.max_unpool2d(x31d, id2, kernel_size=2, stride=2)
x22d = f.relu(self.bn22d(self.conv22d(x2d)))
x21d = f.relu(self.bn21d(self.conv21d(x22d)))
# Stage 1d (112*112)->(224*224)
x1d = f.max_unpool2d(x21d, id1, kernel_size=2, stride=2)
x12d = f.relu(self.bn12d(self.conv12d(x1d)))
x11d = self.conv11d(x12d)
return x11d
def load_from_segnet(self, model_path):
s_dict = self.state_dict()# create a copy of the state dict
th = torch.load(model_path).state_dict() # load the weigths
# for name in th:
# s_dict[corresp_name[name]] = th[name]
self.load_state_dict(th)
num_classes = len(classes)
net = SegNet(3, num_classes)
if torch.cuda.is_available():
net = net.cuda()
criterion = nn.CrossEntropyLoss()
# 学习率不能太高,否则输出的标签就全变成0了
LEARNING_RATE = 5e-6
basic_optim = torch.optim.Adam(net.parameters(), lr=LEARNING_RATE, betas=(0.9, 0.999), eps=1e-08, weight_decay=0)
optimizer = basic_optim
def predict(img, label): # 预测结果
img = Variable(img.unsqueeze(0)).cuda()
out = net(img)
pred = out.max(1)[1].squeeze().cpu().data.numpy()
return pred, label
import random as rand
# 显示当前网络的训练结果
def show(size=224, num_image=4, img_size=10, offset=0, shuffle=False):
_, figs = plt.subplots(num_image, 3, figsize=(img_size, img_size))
for i in range(num_image):
if(shuffle==True):
offset = rand.randint(0, min(len(camvid_train)-i-1, len(camvid_test)-i-1))
img_data, img_label = camvid_test[i+offset]
pred, label = predict(img_data, img_label)
img_data = Image.open(camvid_test.data_list[i+offset])
img_label = Image.open(camvid_test.label_list[i+offset])
img_data, img_label = crop(img_data, img_label)
figs[i, 0].imshow(img_data) # 原始图片
figs[i, 0].axes.get_xaxis().set_visible(False) # 去掉x轴
figs[i, 0].axes.get_yaxis().set_visible(False) # 去掉y轴
figs[i, 1].imshow(img_label) # 标签
figs[i, 1].axes.get_xaxis().set_visible(False) # 去掉x轴
figs[i, 1].axes.get_yaxis().set_visible(False) # 去掉y轴
figs[i, 2].imshow(pred) # 模型输出结果
figs[i, 2].axes.get_xaxis().set_visible(False) # 去掉x轴
figs[i, 2].axes.get_yaxis().set_visible(False) # 去掉y轴
# 在最后一行图片下面添加标题
figs[num_image-1, 0].set_title("Image", y=-0.2*(10/img_size))
figs[num_image-1, 1].set_title("Label", y=-0.2*(10/img_size))
figs[num_image-1, 2].set_title("segnet", y=-0.2*(10/img_size))
plt.show()
EPOCHES = 100
# 训练时的数据
train_loss = []
train_acc = []
train_acc_cls = []
train_mean_iu = []
train_fwavacc = []
# 验证时的数据
eval_loss = []
eval_acc = []
eval_acc_cls = []
eval_mean_iu = []
eval_fwavacc = []
# 记录在训练和测试集上预测出全零的图片数量
num_zero_train_epoch = 0
num_zero_test_epoch = 0
num_zero_train = 0
num_zero_test = 0
train_zero = []
test_zero = []
for e in range(EPOCHES):
_train_loss = 0
_train_acc = 0
_train_acc_cls = 0
_train_mean_iu = 0
_train_fwavacc = 0
prev_time = datetime.now()
net = net.train()
for img_data, img_label in train_data:
if torch.cuda.is_available:
im = Variable(img_data).cuda()
label = Variable(img_label).cuda()
else:
im = Variable(img_data)
label = Variable(img_label)
# 前向传播
out = net(im)
loss = criterion(out, label)
# 反向传播
optimizer.zero_grad()
loss.backward()
optimizer.step()
_train_loss += loss.item()
# label_pred输出的是21*224*224的向量,对于每一个点都有21个分类的概率
# 我们取概率值最大的那个下标作为模型预测的标签,然后计算各种评价指标
label_pred = out.max(dim=1)[1].data.cpu().numpy()
# 如果得到的所有像素点的分类都是0,则输出
if(np.all(label_pred==0)):
# print("train: all zero! epoch: "+str(e))
num_zero_train_epoch += 1
label_true = label.data.cpu().numpy()
for lbt, lbp in zip(label_true, label_pred):
acc, acc_cls, mean_iu, fwavacc = label_accuracy_score(lbt, lbp, num_classes)
_train_acc += acc
_train_acc_cls += acc_cls
_train_mean_iu += mean_iu
_train_fwavacc += fwavacc
# print("epoch "+str(e)+" train : "+" num of zero label=" + str(num_zero_train_epoch))
num_zero_train += num_zero_train_epoch
train_zero.append(num_zero_train_epoch)
num_zero_train_epoch = 0
# 记录当前轮的数据
train_loss.append(_train_loss/len(train_data))
train_acc.append(_train_acc/len(camvid_train))
train_acc_cls.append(_train_acc_cls)
train_mean_iu.append(_train_mean_iu/len(camvid_train))
train_fwavacc.append(_train_fwavacc)
net = net.eval()
_eval_loss = 0
_eval_acc = 0
_eval_acc_cls = 0
_eval_mean_iu = 0
_eval_fwavacc = 0
for img_data, img_label in valid_data:
if torch.cuda.is_available():
im = Variable(img_data).cuda()
label = Variable(img_label).cuda()
else:
im = Variable(img_data)
label = Variable(img_label)
# forward
out = net(im)
loss = criterion(out, label)
_eval_loss += loss.item()
label_pred = out.max(dim=1)[1].data.cpu().numpy()
if(np.all(label_pred==0)):
# print("test: all zero! epoch: "+str(e))
num_zero_test_epoch += 1
label_true = label.data.cpu().numpy()
for lbt, lbp in zip(label_true, label_pred):
acc, acc_cls, mean_iu, fwavacc = label_accuracy_score(lbt, lbp, num_classes)
_eval_acc += acc
_eval_acc_cls += acc_cls
_eval_mean_iu += mean_iu
_eval_fwavacc += fwavacc
# print("epoch "+str(e)+" test : "+" num of zero label= " + str(num_zero_test_epoch))
num_zero_test += num_zero_test_epoch
test_zero.append(num_zero_test_epoch)
num_zero_test_epoch = 0
# 记录当前轮的数据
eval_loss.append(_eval_loss/len(valid_data))
eval_acc.append(_eval_acc/len(camvid_test))
eval_acc_cls.append(_eval_acc_cls)
eval_mean_iu.append(_eval_mean_iu/len(camvid_test))
eval_fwavacc.append(_eval_fwavacc)
# 打印当前轮训练的结果
cur_time = datetime.now()
h, remainder = divmod((cur_time - prev_time).seconds, 3600)
m, s = divmod(remainder, 60)
epoch_str = ('Epoch: {}, Train Loss: {:.5f}, Train Acc: {:.5f}, Train Mean IU: {:.5f}, \
Valid Loss: {:.5f}, Valid Acc: {:.5f}, Valid Mean IU: {:.5f} '.format(
e, _train_loss / len(train_data), _train_acc / len(camvid_train), _train_mean_iu / len(camvid_train),
_eval_loss / len(valid_data), _eval_acc / len(camvid_test), _eval_mean_iu / len(camvid_test)))
time_str = 'Time: {:.0f}:{:.0f}:{:.0f}'.format(h, m, s)
print(epoch_str + time_str)
# show()
F:\anaconda\lib\site-packages\ipykernel_launcher.py:52: RuntimeWarning: invalid value encountered in true_divide
F:\anaconda\lib\site-packages\ipykernel_launcher.py:55: RuntimeWarning: invalid value encountered in true_divide
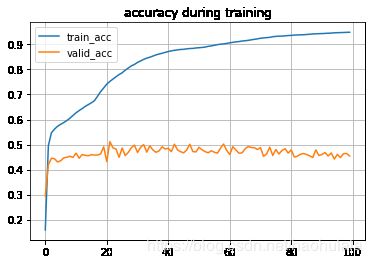
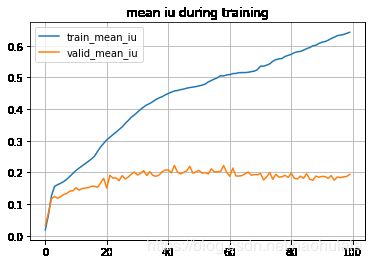
Epoch: 0, Train Loss: 3.28501, Train Acc: 0.15892, Train Mean IU: 0.01880, Valid Loss: 3.18600, Valid Acc: 0.29526, Valid Mean IU: 0.03251 Time: 0:1:50
Epoch: 1, Train Loss: 2.86483, Train Acc: 0.49563, Train Mean IU: 0.06439, Valid Loss: 2.80258, Valid Acc: 0.41886, Valid Mean IU: 0.07185 Time: 0:1:43
Epoch: 2, Train Loss: 2.52854, Train Acc: 0.54712, Train Mean IU: 0.12655, Valid Loss: 2.56649, Valid Acc: 0.44565, Valid Mean IU: 0.11731 Time: 0:1:43
Epoch: 3, Train Loss: 2.25882, Train Acc: 0.56177, Train Mean IU: 0.15582, Valid Loss: 2.38449, Valid Acc: 0.44337, Valid Mean IU: 0.12439 Time: 0:1:43
Epoch: 4, Train Loss: 2.03646, Train Acc: 0.57300, Train Mean IU: 0.16150, Valid Loss: 2.20902, Valid Acc: 0.43052, Valid Mean IU: 0.11890 Time: 0:1:43
Epoch: 5, Train Loss: 1.85545, Train Acc: 0.58089, Train Mean IU: 0.16603, Valid Loss: 2.08668, Valid Acc: 0.43515, Valid Mean IU: 0.12388 Time: 0:1:43
Epoch: 6, Train Loss: 1.70968, Train Acc: 0.58768, Train Mean IU: 0.17140, Valid Loss: 1.97054, Valid Acc: 0.44662, Valid Mean IU: 0.13049 Time: 0:1:43
Epoch: 7, Train Loss: 1.59064, Train Acc: 0.59591, Train Mean IU: 0.17880, Valid Loss: 1.86883, Valid Acc: 0.44894, Valid Mean IU: 0.13393 Time: 0:1:43
Epoch: 8, Train Loss: 1.49433, Train Acc: 0.60513, Train Mean IU: 0.18765, Valid Loss: 1.87306, Valid Acc: 0.45341, Valid Mean IU: 0.14141 Time: 0:1:43
Epoch: 9, Train Loss: 1.41259, Train Acc: 0.61615, Train Mean IU: 0.19726, Valid Loss: 1.80169, Valid Acc: 0.44858, Valid Mean IU: 0.14220 Time: 0:1:43
Epoch: 10, Train Loss: 1.34416, Train Acc: 0.62673, Train Mean IU: 0.20643, Valid Loss: 1.73046, Valid Acc: 0.46561, Valid Mean IU: 0.15175 Time: 0:1:43
Epoch: 11, Train Loss: 1.28178, Train Acc: 0.63563, Train Mean IU: 0.21394, Valid Loss: 1.75925, Valid Acc: 0.44533, Valid Mean IU: 0.14436 Time: 0:1:43
Epoch: 12, Train Loss: 1.22696, Train Acc: 0.64367, Train Mean IU: 0.22088, Valid Loss: 1.73248, Valid Acc: 0.45995, Valid Mean IU: 0.14926 Time: 0:1:43
Epoch: 13, Train Loss: 1.17771, Train Acc: 0.65246, Train Mean IU: 0.22804, Valid Loss: 1.69812, Valid Acc: 0.45693, Valid Mean IU: 0.15089 Time: 0:1:43
Epoch: 14, Train Loss: 1.13409, Train Acc: 0.65950, Train Mean IU: 0.23510, Valid Loss: 1.72055, Valid Acc: 0.45532, Valid Mean IU: 0.15226 Time: 0:1:42
Epoch: 15, Train Loss: 1.09525, Train Acc: 0.66688, Train Mean IU: 0.24241, Valid Loss: 1.69134, Valid Acc: 0.45942, Valid Mean IU: 0.15638 Time: 0:1:42
Epoch: 16, Train Loss: 1.06101, Train Acc: 0.67557, Train Mean IU: 0.25132, Valid Loss: 1.74224, Valid Acc: 0.45812, Valid Mean IU: 0.15664 Time: 0:1:42
Epoch: 17, Train Loss: 1.02359, Train Acc: 0.69295, Train Mean IU: 0.26652, Valid Loss: 1.79314, Valid Acc: 0.45788, Valid Mean IU: 0.15346 Time: 0:1:42
Epoch: 18, Train Loss: 0.98921, Train Acc: 0.71131, Train Mean IU: 0.28064, Valid Loss: 1.71934, Valid Acc: 0.46267, Valid Mean IU: 0.16688 Time: 0:1:42
Epoch: 19, Train Loss: 0.95765, Train Acc: 0.72605, Train Mean IU: 0.29199, Valid Loss: 1.68570, Valid Acc: 0.49098, Valid Mean IU: 0.18168 Time: 0:1:42
Epoch: 20, Train Loss: 0.92556, Train Acc: 0.74134, Train Mean IU: 0.30278, Valid Loss: 1.86335, Valid Acc: 0.43179, Valid Mean IU: 0.15071 Time: 0:1:42
Epoch: 21, Train Loss: 0.89429, Train Acc: 0.75209, Train Mean IU: 0.31119, Valid Loss: 1.65761, Valid Acc: 0.51178, Valid Mean IU: 0.19123 Time: 0:1:42
Epoch: 22, Train Loss: 0.86575, Train Acc: 0.76156, Train Mean IU: 0.31926, Valid Loss: 1.71666, Valid Acc: 0.48649, Valid Mean IU: 0.18236 Time: 0:1:42
Epoch: 23, Train Loss: 0.83652, Train Acc: 0.77069, Train Mean IU: 0.32688, Valid Loss: 1.69652, Valid Acc: 0.48204, Valid Mean IU: 0.18287 Time: 0:1:42
Epoch: 24, Train Loss: 0.80894, Train Acc: 0.77957, Train Mean IU: 0.33567, Valid Loss: 1.77136, Valid Acc: 0.44906, Valid Mean IU: 0.17413 Time: 0:1:42
Epoch: 25, Train Loss: 0.78598, Train Acc: 0.78664, Train Mean IU: 0.34358, Valid Loss: 1.72667, Valid Acc: 0.48632, Valid Mean IU: 0.19018 Time: 0:1:42
Epoch: 26, Train Loss: 0.76298, Train Acc: 0.79705, Train Mean IU: 0.35488, Valid Loss: 1.83021, Valid Acc: 0.45586, Valid Mean IU: 0.17961 Time: 0:1:42
Epoch: 27, Train Loss: 0.73780, Train Acc: 0.80555, Train Mean IU: 0.36424, Valid Loss: 1.78295, Valid Acc: 0.46869, Valid Mean IU: 0.18578 Time: 0:1:42
Epoch: 28, Train Loss: 0.71469, Train Acc: 0.81446, Train Mean IU: 0.37452, Valid Loss: 1.71426, Valid Acc: 0.48745, Valid Mean IU: 0.19481 Time: 0:1:42
Epoch: 29, Train Loss: 0.69615, Train Acc: 0.82003, Train Mean IU: 0.38172, Valid Loss: 1.63543, Valid Acc: 0.49760, Valid Mean IU: 0.20123 Time: 0:1:42
Epoch: 30, Train Loss: 0.67384, Train Acc: 0.82807, Train Mean IU: 0.39051, Valid Loss: 1.68845, Valid Acc: 0.46820, Valid Mean IU: 0.19190 Time: 0:1:42
Epoch: 31, Train Loss: 0.65256, Train Acc: 0.83400, Train Mean IU: 0.39884, Valid Loss: 1.65415, Valid Acc: 0.48879, Valid Mean IU: 0.19717 Time: 0:1:42
Epoch: 32, Train Loss: 0.63091, Train Acc: 0.84022, Train Mean IU: 0.40656, Valid Loss: 1.65206, Valid Acc: 0.49999, Valid Mean IU: 0.20575 Time: 0:1:42
Epoch: 33, Train Loss: 0.60994, Train Acc: 0.84526, Train Mean IU: 0.41324, Valid Loss: 1.76324, Valid Acc: 0.46952, Valid Mean IU: 0.19051 Time: 0:1:42
Epoch: 34, Train Loss: 0.59392, Train Acc: 0.84890, Train Mean IU: 0.41772, Valid Loss: 1.69548, Valid Acc: 0.49463, Valid Mean IU: 0.20253 Time: 0:1:42
Epoch: 35, Train Loss: 0.57544, Train Acc: 0.85343, Train Mean IU: 0.42383, Valid Loss: 1.74486, Valid Acc: 0.47838, Valid Mean IU: 0.19062 Time: 0:1:42
Epoch: 36, Train Loss: 0.55740, Train Acc: 0.85819, Train Mean IU: 0.43018, Valid Loss: 1.88567, Valid Acc: 0.46887, Valid Mean IU: 0.18800 Time: 0:1:42
Epoch: 37, Train Loss: 0.54158, Train Acc: 0.86154, Train Mean IU: 0.43528, Valid Loss: 1.80572, Valid Acc: 0.47477, Valid Mean IU: 0.19199 Time: 0:1:42
Epoch: 38, Train Loss: 0.52815, Train Acc: 0.86472, Train Mean IU: 0.43898, Valid Loss: 1.81261, Valid Acc: 0.49099, Valid Mean IU: 0.20222 Time: 0:1:42
Epoch: 39, Train Loss: 0.51204, Train Acc: 0.86816, Train Mean IU: 0.44473, Valid Loss: 1.72983, Valid Acc: 0.48228, Valid Mean IU: 0.20768 Time: 0:1:42
Epoch: 40, Train Loss: 0.49747, Train Acc: 0.87157, Train Mean IU: 0.44930, Valid Loss: 1.77279, Valid Acc: 0.48508, Valid Mean IU: 0.20806 Time: 0:1:42
Epoch: 41, Train Loss: 0.48307, Train Acc: 0.87429, Train Mean IU: 0.45333, Valid Loss: 1.84234, Valid Acc: 0.47137, Valid Mean IU: 0.19864 Time: 0:1:42
Epoch: 42, Train Loss: 0.47028, Train Acc: 0.87641, Train Mean IU: 0.45715, Valid Loss: 1.71891, Valid Acc: 0.50146, Valid Mean IU: 0.22231 Time: 0:1:42
Epoch: 43, Train Loss: 0.45875, Train Acc: 0.87806, Train Mean IU: 0.45861, Valid Loss: 1.86600, Valid Acc: 0.47865, Valid Mean IU: 0.20112 Time: 0:1:42
Epoch: 44, Train Loss: 0.44716, Train Acc: 0.87986, Train Mean IU: 0.46137, Valid Loss: 1.92784, Valid Acc: 0.47149, Valid Mean IU: 0.19560 Time: 0:1:42
Epoch: 45, Train Loss: 0.43783, Train Acc: 0.88034, Train Mean IU: 0.46298, Valid Loss: 1.90938, Valid Acc: 0.46674, Valid Mean IU: 0.20048 Time: 0:1:42
Epoch: 46, Train Loss: 0.42730, Train Acc: 0.88234, Train Mean IU: 0.46591, Valid Loss: 1.87458, Valid Acc: 0.47818, Valid Mean IU: 0.20529 Time: 0:1:42
Epoch: 47, Train Loss: 0.41725, Train Acc: 0.88359, Train Mean IU: 0.46786, Valid Loss: 1.80304, Valid Acc: 0.50111, Valid Mean IU: 0.21962 Time: 0:1:42
Epoch: 48, Train Loss: 0.40978, Train Acc: 0.88415, Train Mean IU: 0.46946, Valid Loss: 1.92397, Valid Acc: 0.47207, Valid Mean IU: 0.19773 Time: 0:1:42
Epoch: 49, Train Loss: 0.39902, Train Acc: 0.88575, Train Mean IU: 0.47084, Valid Loss: 1.95161, Valid Acc: 0.47048, Valid Mean IU: 0.20201 Time: 0:1:42
Epoch: 50, Train Loss: 0.39073, Train Acc: 0.88691, Train Mean IU: 0.47319, Valid Loss: 1.91477, Valid Acc: 0.48915, Valid Mean IU: 0.20651 Time: 0:1:42
Epoch: 51, Train Loss: 0.38442, Train Acc: 0.88788, Train Mean IU: 0.47565, Valid Loss: 1.99605, Valid Acc: 0.47899, Valid Mean IU: 0.19755 Time: 0:1:42
Epoch: 52, Train Loss: 0.37889, Train Acc: 0.88939, Train Mean IU: 0.47876, Valid Loss: 2.03147, Valid Acc: 0.47149, Valid Mean IU: 0.20023 Time: 0:1:42
Epoch: 53, Train Loss: 0.36824, Train Acc: 0.89233, Train Mean IU: 0.48574, Valid Loss: 2.02627, Valid Acc: 0.46720, Valid Mean IU: 0.19531 Time: 0:1:42
Epoch: 54, Train Loss: 0.36223, Train Acc: 0.89401, Train Mean IU: 0.49013, Valid Loss: 1.94340, Valid Acc: 0.47539, Valid Mean IU: 0.21146 Time: 0:1:42
Epoch: 55, Train Loss: 0.35433, Train Acc: 0.89659, Train Mean IU: 0.49481, Valid Loss: 2.02752, Valid Acc: 0.46911, Valid Mean IU: 0.20165 Time: 0:1:42
Epoch: 56, Train Loss: 0.34699, Train Acc: 0.89908, Train Mean IU: 0.49880, Valid Loss: 1.98171, Valid Acc: 0.46571, Valid Mean IU: 0.20269 Time: 0:1:42
Epoch: 57, Train Loss: 0.33995, Train Acc: 0.90101, Train Mean IU: 0.50527, Valid Loss: 2.04276, Valid Acc: 0.48569, Valid Mean IU: 0.20288 Time: 0:1:43
Epoch: 58, Train Loss: 0.33511, Train Acc: 0.90217, Train Mean IU: 0.50458, Valid Loss: 1.81559, Valid Acc: 0.50214, Valid Mean IU: 0.22199 Time: 0:1:43
Epoch: 59, Train Loss: 0.32949, Train Acc: 0.90416, Train Mean IU: 0.50783, Valid Loss: 2.02838, Valid Acc: 0.47651, Valid Mean IU: 0.20105 Time: 0:1:42
Epoch: 60, Train Loss: 0.32266, Train Acc: 0.90639, Train Mean IU: 0.50886, Valid Loss: 2.12491, Valid Acc: 0.46016, Valid Mean IU: 0.18820 Time: 0:1:42
Epoch: 61, Train Loss: 0.31528, Train Acc: 0.90836, Train Mean IU: 0.51197, Valid Loss: 1.91107, Valid Acc: 0.49161, Valid Mean IU: 0.21376 Time: 0:1:42
Epoch: 62, Train Loss: 0.30949, Train Acc: 0.91033, Train Mean IU: 0.51253, Valid Loss: 2.04708, Valid Acc: 0.47792, Valid Mean IU: 0.18893 Time: 0:1:42
Epoch: 63, Train Loss: 0.30450, Train Acc: 0.91138, Train Mean IU: 0.51487, Valid Loss: 2.14342, Valid Acc: 0.46558, Valid Mean IU: 0.18869 Time: 0:1:42
Epoch: 64, Train Loss: 0.29779, Train Acc: 0.91359, Train Mean IU: 0.51514, Valid Loss: 2.11690, Valid Acc: 0.46665, Valid Mean IU: 0.19009 Time: 0:1:42
Epoch: 65, Train Loss: 0.29309, Train Acc: 0.91471, Train Mean IU: 0.51521, Valid Loss: 2.05651, Valid Acc: 0.48343, Valid Mean IU: 0.19637 Time: 0:1:42
Epoch: 66, Train Loss: 0.28897, Train Acc: 0.91626, Train Mean IU: 0.51613, Valid Loss: 2.00803, Valid Acc: 0.49213, Valid Mean IU: 0.20128 Time: 0:1:42
Epoch: 67, Train Loss: 0.28157, Train Acc: 0.91834, Train Mean IU: 0.51820, Valid Loss: 2.14853, Valid Acc: 0.48817, Valid Mean IU: 0.19136 Time: 0:1:42
Epoch: 68, Train Loss: 0.27639, Train Acc: 0.92038, Train Mean IU: 0.51966, Valid Loss: 2.17045, Valid Acc: 0.48733, Valid Mean IU: 0.19345 Time: 0:1:42
Epoch: 69, Train Loss: 0.27105, Train Acc: 0.92218, Train Mean IU: 0.52441, Valid Loss: 2.23003, Valid Acc: 0.48020, Valid Mean IU: 0.19275 Time: 0:1:42
Epoch: 70, Train Loss: 0.26551, Train Acc: 0.92473, Train Mean IU: 0.53526, Valid Loss: 2.08014, Valid Acc: 0.48761, Valid Mean IU: 0.19654 Time: 0:1:42
Epoch: 71, Train Loss: 0.26149, Train Acc: 0.92611, Train Mean IU: 0.53520, Valid Loss: 2.32529, Valid Acc: 0.45273, Valid Mean IU: 0.17620 Time: 0:1:42
Epoch: 72, Train Loss: 0.25931, Train Acc: 0.92712, Train Mean IU: 0.53855, Valid Loss: 2.21807, Valid Acc: 0.46276, Valid Mean IU: 0.18641 Time: 0:1:42
Epoch: 73, Train Loss: 0.25464, Train Acc: 0.92827, Train Mean IU: 0.54267, Valid Loss: 2.24839, Valid Acc: 0.48946, Valid Mean IU: 0.19993 Time: 0:1:42
Epoch: 74, Train Loss: 0.24713, Train Acc: 0.93072, Train Mean IU: 0.55091, Valid Loss: 2.42770, Valid Acc: 0.45627, Valid Mean IU: 0.17844 Time: 0:1:42
Epoch: 75, Train Loss: 0.24154, Train Acc: 0.93211, Train Mean IU: 0.55599, Valid Loss: 2.18964, Valid Acc: 0.48055, Valid Mean IU: 0.19412 Time: 0:1:42
Epoch: 76, Train Loss: 0.23791, Train Acc: 0.93303, Train Mean IU: 0.55836, Valid Loss: 2.43686, Valid Acc: 0.46224, Valid Mean IU: 0.18542 Time: 0:1:42
Epoch: 77, Train Loss: 0.23582, Train Acc: 0.93321, Train Mean IU: 0.55956, Valid Loss: 2.32287, Valid Acc: 0.47637, Valid Mean IU: 0.18661 Time: 0:1:42
Epoch: 78, Train Loss: 0.23073, Train Acc: 0.93435, Train Mean IU: 0.56611, Valid Loss: 2.40340, Valid Acc: 0.48348, Valid Mean IU: 0.19092 Time: 0:1:42
Epoch: 79, Train Loss: 0.22596, Train Acc: 0.93540, Train Mean IU: 0.56950, Valid Loss: 2.54092, Valid Acc: 0.46588, Valid Mean IU: 0.18447 Time: 0:1:42
Epoch: 80, Train Loss: 0.22157, Train Acc: 0.93612, Train Mean IU: 0.57265, Valid Loss: 2.29604, Valid Acc: 0.47878, Valid Mean IU: 0.19788 Time: 0:1:42
Epoch: 81, Train Loss: 0.21700, Train Acc: 0.93724, Train Mean IU: 0.57794, Valid Loss: 2.70717, Valid Acc: 0.45007, Valid Mean IU: 0.18198 Time: 0:1:42
Epoch: 82, Train Loss: 0.21285, Train Acc: 0.93804, Train Mean IU: 0.58067, Valid Loss: 2.59054, Valid Acc: 0.45344, Valid Mean IU: 0.17966 Time: 0:1:42
Epoch: 83, Train Loss: 0.20971, Train Acc: 0.93833, Train Mean IU: 0.58220, Valid Loss: 2.49625, Valid Acc: 0.46118, Valid Mean IU: 0.18841 Time: 0:1:42
Epoch: 84, Train Loss: 0.20774, Train Acc: 0.93860, Train Mean IU: 0.58594, Valid Loss: 2.59302, Valid Acc: 0.46414, Valid Mean IU: 0.18163 Time: 0:1:42
Epoch: 85, Train Loss: 0.20315, Train Acc: 0.93973, Train Mean IU: 0.59068, Valid Loss: 2.66223, Valid Acc: 0.46025, Valid Mean IU: 0.19633 Time: 0:1:42
Epoch: 86, Train Loss: 0.19926, Train Acc: 0.94053, Train Mean IU: 0.59407, Valid Loss: 2.67234, Valid Acc: 0.45498, Valid Mean IU: 0.17927 Time: 0:1:42
Epoch: 87, Train Loss: 0.19475, Train Acc: 0.94185, Train Mean IU: 0.59949, Valid Loss: 2.97073, Valid Acc: 0.44814, Valid Mean IU: 0.17524 Time: 0:1:42
Epoch: 88, Train Loss: 0.19142, Train Acc: 0.94247, Train Mean IU: 0.60158, Valid Loss: 2.45502, Valid Acc: 0.47853, Valid Mean IU: 0.18866 Time: 0:1:42
Epoch: 89, Train Loss: 0.18866, Train Acc: 0.94299, Train Mean IU: 0.60703, Valid Loss: 2.75901, Valid Acc: 0.45605, Valid Mean IU: 0.18480 Time: 0:1:42
Epoch: 90, Train Loss: 0.18676, Train Acc: 0.94336, Train Mean IU: 0.61113, Valid Loss: 2.60492, Valid Acc: 0.46024, Valid Mean IU: 0.18778 Time: 0:1:42
Epoch: 91, Train Loss: 0.18372, Train Acc: 0.94399, Train Mean IU: 0.61298, Valid Loss: 2.57802, Valid Acc: 0.46786, Valid Mean IU: 0.18686 Time: 0:1:42
Epoch: 92, Train Loss: 0.18070, Train Acc: 0.94476, Train Mean IU: 0.61717, Valid Loss: 2.71728, Valid Acc: 0.45426, Valid Mean IU: 0.18145 Time: 0:1:42
Epoch: 93, Train Loss: 0.17829, Train Acc: 0.94524, Train Mean IU: 0.62271, Valid Loss: 2.71710, Valid Acc: 0.46632, Valid Mean IU: 0.19028 Time: 0:1:42
Epoch: 94, Train Loss: 0.17403, Train Acc: 0.94633, Train Mean IU: 0.62669, Valid Loss: 2.99219, Valid Acc: 0.44193, Valid Mean IU: 0.17579 Time: 0:1:42
Epoch: 95, Train Loss: 0.17127, Train Acc: 0.94687, Train Mean IU: 0.63160, Valid Loss: 2.69827, Valid Acc: 0.46080, Valid Mean IU: 0.18583 Time: 0:1:42
Epoch: 96, Train Loss: 0.16951, Train Acc: 0.94728, Train Mean IU: 0.63352, Valid Loss: 2.77256, Valid Acc: 0.44772, Valid Mean IU: 0.18387 Time: 0:1:42
Epoch: 97, Train Loss: 0.16740, Train Acc: 0.94762, Train Mean IU: 0.63521, Valid Loss: 2.85770, Valid Acc: 0.46352, Valid Mean IU: 0.18602 Time: 0:1:42
Epoch: 98, Train Loss: 0.16479, Train Acc: 0.94825, Train Mean IU: 0.63885, Valid Loss: 2.79530, Valid Acc: 0.46444, Valid Mean IU: 0.18735 Time: 0:1:42
Epoch: 99, Train Loss: 0.16294, Train Acc: 0.94866, Train Mean IU: 0.64242, Valid Loss: 2.89714, Valid Acc: 0.45412, Valid Mean IU: 0.19405 Time: 0:1:42
epoch = np.array(range(EPOCHES))
plt.plot(epoch, train_loss, label="train_loss")
plt.plot(epoch, train_loss, label="valid_loss")
plt.title("loss during training")
plt.legend()
plt.grid()
plt.show()

plt.plot(epoch, train_acc, label="train_acc")
plt.plot(epoch, eval_acc, label="valid_acc")
plt.title("accuracy during training")
plt.legend()
plt.grid()
plt.show()
plt.plot(epoch, train_mean_iu, label="train_mean_iu")
plt.plot(epoch, eval_mean_iu, label="valid_mean_iu")
plt.title("mean iu during training")
plt.legend()
plt.grid()
plt.show()
# 保存模型
PATH = "./model/segnet-camvid.pth"
torch.save(net.state_dict(), PATH)
# 加载模型
# model.load_state_dict(torch.load(PATH))
show(offset=200, shuffle=True)
