黑马程序员——Java基础语法
------Java培训、Android培训、iOS培训、.Net培训、期待与您交流! -------
黑马程序员——Java基础语法
JAVA语言基础组成
关键字、标识符、注释、常量和变量、运算符、语句、函数、数组
一、关键字:被Java语言赋予了特殊含义的单词,关键字中所有的字母都为小写。


二、标识符:在程序中自定义的一些名称
由26个英文字母大小写,数字0--9,_,$组成
定义合法标识符规则:
(1)数字不可以开头
(2)
不可以使用关键字
(3)
Java中严格区分大小写,注意在起名字时,为了提高阅读性,要尽量有意义。
Java中的名称规范:
A 包名:
由多个单词组成时,所有字母小写,xxyyzz。
举例:
com一级包
itheima.interview二级包
注意:www.itheima.com(域名反写)
com一级包
itheima.interview二级包
注意:www.itheima.com(域名反写)
B 类名接口名:
如果是一个单词,首字母大写。
举例:
Demo,Test,Student
如果是多个单词,每个单词的首字母大写。
举例:
HelloWorld,StudyJava
举例:
Demo,Test,Student
如果是多个单词,每个单词的首字母大写。
举例:
HelloWorld,StudyJava
C 变量名和函数名:
如果是一个单词,首字母小写。
举例:
main(),name,age.show().method()
如果是多个单词,从第二个单词开始每个单词的首字母大写。
举例:
showName(),studentName()
D 常量名:
全部大写,如果多个单词组成,用_连接。
举例:
PI,STUDENT_MAX_AGE
举例:
PI,STUDENT_MAX_AGE
三、注释
对于单行和多行注释,被注释的文字,不会被JVM解释执行,对于文档注释,是Java特有的注释,其中注释内容可以被JDK提供的工具Javadoc所解析,生成一套以网页文件形式体现的改程序的说明文档。注释是一个程序员必须要具有的良好的编程习惯。将自己的思想通过注释先整理出来,用代码去体现。
A:单行注释
a:以//开头,以回车结束。
b:单行注释是可以嵌套单行注释的。
B:多行注释
a:以/*开头,以*/结束。
b:多行注释是不可以嵌套多行注释的,但可以嵌套单行注释。
C:文档注释(了解)
将来被Javadoc工具解析,生成一个说明书。
a:以//开头,以回车结束。
b:单行注释是可以嵌套单行注释的。
B:多行注释
a:以/*开头,以*/结束。
b:多行注释是不可以嵌套多行注释的,但可以嵌套单行注释。
C:文档注释(了解)
将来被Javadoc工具解析,生成一个说明书。
格式:
单行注释://
多行注释: /* */
文档注释: /** */
注释的作用:
A:解释程序,提高程序的阅读性。
B:可以调试错误。
注释是一个程序员必须具有的良好编程习惯。 初学者编写程序可以养成习惯:先写注释再写代码。 将自己的思想通过注释先整理出来,在用代码去体现。 因为代码仅仅是思想的一种体现形式而已。
建议:写代码之前写需求,思路,步骤,养成一个良好的习惯。
单行注释://
多行注释: /* */
文档注释: /** */
注释的作用:
A:解释程序,提高程序的阅读性。
B:可以调试错误。
注释是一个程序员必须具有的良好编程习惯。 初学者编写程序可以养成习惯:先写注释再写代码。 将自己的思想通过注释先整理出来,在用代码去体现。 因为代码仅仅是思想的一种体现形式而已。
建议:写代码之前写需求,思路,步骤,养成一个良好的习惯。
四、常量与变量
常量表示不能改变的数值
Java中常量的分类
(1)整数常量,所有整数 如1,-1
(2)小数常量,所有小数 如1.1
(3)布尔型常量,较为特殊,只有两个值 true false
(4)字符常量,将一个数字、字母或者符号用单引号' '标识,如'3',只能放一个。
(5)字符串常量,将一个或者多个字符用双引号" "标识,"a","ab"。
(6)null常量,只有一个数值就是null
对于整数,Java有三种表现形式
十进制 0--9 满10进1
八进制 0--7 满8进1
十六进制 0--9 A B C D E F满16进1
任何数据在计算机都是以二进制的形式存在的,用0,1编码字符,组成编码表,进制是为了更好的表示数据
变量就是将不确定的数据进行存储,也就是需要在内存中开辟一个空间。
变量:就是讲不确定的数据进行存储,也就是需要在内存中开辟一个空间。
(1)程序的运行过程中,在指定范围内发生改变的量。
(2)格式:
格式1:
数据类型 变量名 = 初始化值;
格式2:
数据类型 变量名;
变量名 = 初始化值;
举例:
方式1:
byte b = 10;
方式2:
byte b;
b = 10;
理解:变量就如同数学中的未知数。
(1)程序的运行过程中,在指定范围内发生改变的量。
(2)格式:
格式1:
数据类型 变量名 = 初始化值;
格式2:
数据类型 变量名;
变量名 = 初始化值;
举例:
方式1:
byte b = 10;
方式2:
byte b;
b = 10;
理解:变量就如同数学中的未知数。
内存中的一个存储区域,在该区域有自己的名称和类型,该区域内数据可以在同一类型范围内不断变化。
Java语言是强类型语言,对于每一种数据都定义了明确的具体数据类型,
在内存中分配了不同大小的内存空间。
数据类型:
(1)基本数据类型:
数值型:整数类型(占用字节)
byte(1) short(2) int(4) long(8)
浮点类型 float(4) double(8)
字符型 char(2)
布尔型 boolean(1)
(2)引用数据类型:类 class
接口 interface
数组 [ ]

类型转换
(1)、boolean类型不参与转换。(因为boolean值是常量,默认只有俩个值,要么true,要么false)
(2)、隐式转换(从小到大) 自动类型提升,从小到大的提升。
(byte,short,char) --> int --> long --> float --> double
(3)、强制转换(从大到小)
强制类型转换,从大到小的转换。
int b;b=(byte)(b+2);
格式: (数据类型)数据; 表达式的数据类型自动提升
(1)、boolean类型不参与转换。(因为boolean值是常量,默认只有俩个值,要么true,要么false)
(2)、隐式转换(从小到大) 自动类型提升,从小到大的提升。
(byte,short,char) --> int --> long --> float --> double
(3)、强制转换(从大到小)
强制类型转换,从大到小的转换。
int b;b=(byte)(b+2);
格式: (数据类型)数据; 表达式的数据类型自动提升
所有byte型、short型和char的值将被提升到int型。
如果一个操作数是long型,计算结果就是long型。
如果一个操作数是float型,计算结果就是float型。
如果一个操作数是double型,计算结果就是double型。
当数据不确定时,需要对数据进行存储时,就定义一个变量来完成存储动作
如果一个操作数是long型,计算结果就是long型。
如果一个操作数是float型,计算结果就是float型。
如果一个操作数是double型,计算结果就是double型。
当数据不确定时,需要对数据进行存储时,就定义一个变量来完成存储动作
(4)、转义字符
\n :换行
\b:退格
\r:按回车
\t:制表符
\n :换行
\b:退格
\r:按回车
\t:制表符
五、运算符
算数运算符 赋值运算符 比较运算符
逻辑运算符 位运算符 三元运算符
(1)算数运算符
| 运算符 | 运算 | 范例 | 结果 |
| + | 正号 | +3 | 3 |
| - | 负号 | b=4,-b | -4 |
| + | 加 | 5+5 | 10 |
| - | 减 | 6-4 | 2 |
| * | 乘 | 2*2 | 4 |
| / | 除 | 2/2 | 1 |
| % | 取模 | 5%5 | 0 |
| ++ | 自增(前) | a=2,b=++a | a=3,b=3 |
| ++ | 自增(后) |
a=2,b=a++ | a=3,b=2 |
| -- | 自减(前) | a=2,b=--a | a=1,b=1 |
| -- | 自减(后) | a=2,b=a-- | a=1,b=2 |
| + | 字符串相加 | "He"+"llo" | "Hello" |
| 运算符 | 运算 | 范例 | 结果 |
| == | 相等于 | 4==3 | false |
| != | 不等于 | 4!=3 | true |
| < | 小于 | 4<3 | false |
| > | 大于 | 4>3 | true |
| <= | 小于等于 | 4<=3 | false |
| >= | 大于等于 | 4>=3 | false |
| instance of | 检查是否是类的对象 | "Hello" | instance of String true |
(3)逻辑运算符
| 运算符 | 运算 | 范例 | 结果 |
| & | AND与 | false&true | false |
| | | OR或 | false|true |
true |
| ^ | XOR异或 | false^true |
true |
| ! | NOT非 | !true | false |
| && | AND短路 | false&&true |
false |
| || | OR短路 | false||true |
true |
(4)位运算符
| 位运算 | 运算 | 范例 |
| << | 左移 | 3<<2=12 ------3*2*2=12 |
| >> | 右移 | 3>>1=1 ------3/2=1 |
| >>> | 无符号右移 | 3>>>1=1 ------3/2=1 |
| & | 与运算 | 6&3=2 |
| || | 或运算 | 6|3=7 |
| ^ | 异或运算 | 6^3=5 |
| ~ | 反码 | ~6=-7 |

(5) 三元运算符
格式:(条件表达式)?表达式1:表达式2 ;
如果条件为true,运算后的结果是表达式1,如果条件为flase,运算后的结果是表达式2 ,
六、语句
(
1
)判断结构
if:语句用于做判断使用的。
常见于对某个范围进行判断,或者几个变量进行判断,还有就是boolean表达式的判断。
判断语句三种格式:
<1>.if(条件表达式){ 执行语句; }
执行流程:如果条件表达式为true,就执行语句,否则,什么都不执行。
<2>. if(条件表达式){ if语句执行体; }else{else语句执行体; }
执行流程:如果条件表达式为true,就if语句执行体;否则,就执行else语句执行体;
<3>. if(条件表达式){if语句执行体; }else if(条件表达式){else if语句执行体; } ...else{else语句执行体; }
执行流程: 如果条件表达式1 为true,就执行if语句执行体;; 如果条件表达式2 为true,就执行else if语句执行体;;
如果条件表达式...为true,就执行else if语句执行体;; 否则,就执行else语句执行体;
注意事项
<1>:什么时候用哪一种if语句?
第一种格式在判断条件为一种情况下使用。
第二种格式在判断条件为两种情况下使用。
第三种格式在判断条件为多种情况下使用。
<2>:if语句执行完会执行另外一个语句吗?
每一种if语句其实都是一个整体,如果有地方执行了。其他的就不执行了。
<3>:大括号需要每次都写上吗?
如果if或者else里面控制的语句体是一条语句,是可以省略大括号的, 但是,如果是控制多条语句,就必须写 上大括号。 建议:永远写上大括号。
<4>:大括号和分号一般不同时出现。
(2)选择结构
switch语句
用于做选择使用的。一般用于几个常量的判断。 switch语句会把几个常量值直接加载到内存,在判断的时候,效率要比if语句高。 所以,针对几个常量的判断,一般选择switch语句。
选择语句格式:
switch(变量){
case 取值1: 执行语句; break;
case 取值 2: 执行语句;break;
...
default: 执行语句; break;
}
针对格式的解释
switch:表示这里使用的是switch语句,后面跟的是选项。
表达式:byte,short,int,char
JDK 1.5以后可以是枚举
JDK 1.7以后可以是字符串
case:表示这里就是选项的值,它后面的值将来和表达式的值进行匹配。
case:后面的值是不能够重复的。
break:switch语句执行到这里,就结束了。
default:当所有的case和表达式都不匹配的时候,就走default的内容。
它相当于if语句的else。一般不建议省略。
执行流程: 进入switch语句后,就会根据表达式的值去找对应的case值。 如果最终没有找到,那么, 就执行default的内容。
注意事项:
a:default整体可以省略吗?
可以,但是不建议。
b:default的位置可以放到前面吗?
可以,但是不建议。
c:break可以省略吗?
可以,但是不建议。default在最后,default的break是可以省略的,但是结果可能有问题。
d:switch语句什么时候结束呢?
就是遇到break或者执行到程序的末尾。
if和switch的应用:
if语句特点:
<1>,对具体的值进行判断。
<2>,对区间判断。
<3>,对运算结果是boolean类型的表达式进行判断。
switch语句特点:
<1>,对具体的值进行判断。
<2>,值的个数通常是固定的。 对于几个固定的值判断,建议使用switch语句,因为switch语句会将具体的答 案都加载进内存。效率相对高一点。
<3>.switch只能对基本数据类型进行操作 byte,short,int,char
(3)循环结构
循环语句:while, do while , for
如果我们发现有很多重复的内容的时候,就该考虑使用循环改进代码。让我们代码看起来简洁了。
while循环语句格式:
while(条件表达式){ 循环执行体; }
do while 循环语句格式:
do{ 循环执行体; }while(条件表达式);
while 特点:条件如果不满足,不会走循环体
do while特点:条件无论是否满足,循环体至少执行一次。
for循环语句格式:
for(初始化表达式;循环条件表达式;循环后的操作表达式){ 执行语句;(循环体) }
循环注意 :while 先判断后执行。 do while 先执行一次后判断。
循环总结:一定要注意哪些语句需要参加循环,哪些不需要。
总结:什么时候用循环语句?
当对某些语句执行很多次时,就使用循环结构。
总结:什么情况用for,什么情况用while呢?
for和while可以互换。如果用于定义循环增量。用for更合适。因为节约内存。 当然,当我们在写测试程序时,为了书写的简洁,也是可以用while,因为容易看。 不过建议使用for,习惯成自然。你懂的大笑。
嵌套循环:
简单的说就是循环里面还有循环。 外循环执行一次,内循环执行一遍。
for(初始化表达式;条件表达式;循环后的操作表达式){ for(初始化表达式;条件表达式;循环后的操作表达式){ } }
while(条件表达式){ while(条件表达式){} }
总结:嵌套循环是外循环条件成立执行一次,内循环必须执行到条件不满足才结束。
<1>累加思想:
原理:通过变量记录住每次变化的结果,通过循环的形式,进行累加动作。
<2>.计数器思想:
原理:通过一个变量记录住数据的状态变化,也许通过循环完成。
<3>大圈套小圈思想:
原理:尖朝上改变条件。尖朝下改变初始值。
注意:
<1>,for里面的连个表达式运行的顺序,初始化表达式只读一次,判断循环条件,为真就执行循环体,然后再执 行循环后的操作表达式,接着继续判断循环条件,重复找个过程,直到条件不满足为止。
<2>, while和for可以互换,区别在于for为了循环而定义的变量在for循环结束就是在内存中释放。而while循环使 用的变量在循环结束后还可以继续使用。
<3>, 最简单无限循环格式:while(true),for(;;)无限循环存在的原因是并不知道循环多少次,而是根据某些条 件,来控制循环。比如在循环体定义判断语句。
其它流程控制语句:
有些时候,我们需要对循环进行一些控制终止,这个时候,就出现了两个关键字:
break和continue
break(跳出),continue(继续)
break语句:应用范围:选择结构和循环结构。
continue语句:应用于循环结构。
注意:
<1>, 这两个语句离开应用范围,存在是没有意义的。
<2>, 这两个语句单独存在下面都不只可以有语句,因为执行不到。
<3>, continue语句是结束本次循环继续下次循环,结束之后会去判断表达式。
<4>, 标号的出现,可以让这两个语句作用于指定的范围。方便了可以跳出或者继续哪层循环。
七、函数
判断语句三种格式:
<1>.if(条件表达式){ 执行语句; }
执行流程:如果条件表达式为true,就执行语句,否则,什么都不执行。
<2>. if(条件表达式){ if语句执行体; }else{else语句执行体; }
执行流程:如果条件表达式为true,就if语句执行体;否则,就执行else语句执行体;
<3>. if(条件表达式){if语句执行体; }else if(条件表达式){else if语句执行体; } ...else{else语句执行体; }
执行流程: 如果条件表达式1 为true,就执行if语句执行体;; 如果条件表达式2 为true,就执行else if语句执行体;;
如果条件表达式...为true,就执行else if语句执行体;; 否则,就执行else语句执行体;
注意事项
<1>:什么时候用哪一种if语句?
第一种格式在判断条件为一种情况下使用。
第二种格式在判断条件为两种情况下使用。
第三种格式在判断条件为多种情况下使用。
<2>:if语句执行完会执行另外一个语句吗?
每一种if语句其实都是一个整体,如果有地方执行了。其他的就不执行了。
<3>:大括号需要每次都写上吗?
如果if或者else里面控制的语句体是一条语句,是可以省略大括号的, 但是,如果是控制多条语句,就必须写 上大括号。 建议:永远写上大括号。
<4>:大括号和分号一般不同时出现。
(2)选择结构
switch语句
用于做选择使用的。一般用于几个常量的判断。 switch语句会把几个常量值直接加载到内存,在判断的时候,效率要比if语句高。 所以,针对几个常量的判断,一般选择switch语句。
选择语句格式:
switch(变量){
case 取值1: 执行语句; break;
case 取值 2: 执行语句;break;
...
default: 执行语句; break;
}
针对格式的解释
switch:表示这里使用的是switch语句,后面跟的是选项。
表达式:byte,short,int,char
JDK 1.5以后可以是枚举
JDK 1.7以后可以是字符串
case:表示这里就是选项的值,它后面的值将来和表达式的值进行匹配。
case:后面的值是不能够重复的。
break:switch语句执行到这里,就结束了。
default:当所有的case和表达式都不匹配的时候,就走default的内容。
它相当于if语句的else。一般不建议省略。
执行流程: 进入switch语句后,就会根据表达式的值去找对应的case值。 如果最终没有找到,那么, 就执行default的内容。
注意事项:
a:default整体可以省略吗?
可以,但是不建议。
b:default的位置可以放到前面吗?
可以,但是不建议。
c:break可以省略吗?
可以,但是不建议。default在最后,default的break是可以省略的,但是结果可能有问题。
d:switch语句什么时候结束呢?
就是遇到break或者执行到程序的末尾。
if和switch的应用:
if语句特点:
<1>,对具体的值进行判断。
<2>,对区间判断。
<3>,对运算结果是boolean类型的表达式进行判断。
switch语句特点:
<1>,对具体的值进行判断。
<2>,值的个数通常是固定的。 对于几个固定的值判断,建议使用switch语句,因为switch语句会将具体的答 案都加载进内存。效率相对高一点。
<3>.switch只能对基本数据类型进行操作 byte,short,int,char
(3)循环结构
循环语句:while, do while , for
如果我们发现有很多重复的内容的时候,就该考虑使用循环改进代码。让我们代码看起来简洁了。
while循环语句格式:
while(条件表达式){ 循环执行体; }
do while 循环语句格式:
do{ 循环执行体; }while(条件表达式);
while 特点:条件如果不满足,不会走循环体
do while特点:条件无论是否满足,循环体至少执行一次。
for循环语句格式:
for(初始化表达式;循环条件表达式;循环后的操作表达式){ 执行语句;(循环体) }
循环注意 :while 先判断后执行。 do while 先执行一次后判断。
循环总结:一定要注意哪些语句需要参加循环,哪些不需要。
总结:什么时候用循环语句?
当对某些语句执行很多次时,就使用循环结构。
总结:什么情况用for,什么情况用while呢?
for和while可以互换。如果用于定义循环增量。用for更合适。因为节约内存。 当然,当我们在写测试程序时,为了书写的简洁,也是可以用while,因为容易看。 不过建议使用for,习惯成自然。你懂的大笑。
嵌套循环:
简单的说就是循环里面还有循环。 外循环执行一次,内循环执行一遍。
for(初始化表达式;条件表达式;循环后的操作表达式){ for(初始化表达式;条件表达式;循环后的操作表达式){ } }
while(条件表达式){ while(条件表达式){} }
总结:嵌套循环是外循环条件成立执行一次,内循环必须执行到条件不满足才结束。
<1>累加思想:
原理:通过变量记录住每次变化的结果,通过循环的形式,进行累加动作。
<2>.计数器思想:
原理:通过一个变量记录住数据的状态变化,也许通过循环完成。
<3>大圈套小圈思想:
原理:尖朝上改变条件。尖朝下改变初始值。
注意:
<1>,for里面的连个表达式运行的顺序,初始化表达式只读一次,判断循环条件,为真就执行循环体,然后再执 行循环后的操作表达式,接着继续判断循环条件,重复找个过程,直到条件不满足为止。
<2>, while和for可以互换,区别在于for为了循环而定义的变量在for循环结束就是在内存中释放。而while循环使 用的变量在循环结束后还可以继续使用。
<3>, 最简单无限循环格式:while(true),for(;;)无限循环存在的原因是并不知道循环多少次,而是根据某些条 件,来控制循环。比如在循环体定义判断语句。
其它流程控制语句:
有些时候,我们需要对循环进行一些控制终止,这个时候,就出现了两个关键字:
break和continue
break(跳出),continue(继续)
break语句:应用范围:选择结构和循环结构。
continue语句:应用于循环结构。
注意:
<1>, 这两个语句离开应用范围,存在是没有意义的。
<2>, 这两个语句单独存在下面都不只可以有语句,因为执行不到。
<3>, continue语句是结束本次循环继续下次循环,结束之后会去判断表达式。
<4>, 标号的出现,可以让这两个语句作用于指定的范围。方便了可以跳出或者继续哪层循环。
七、函数
(1).函数的定义
<1>.函数就是定义在类中的具有特定功能的一段独立小程序。函数也称为方法。
<2>.函数的格式:
修饰符 返回值类型 函数名(参数类型 形式参数1,参数类型 形式参数2...) {
执行语句;
return 返回值;
}
(2).函数的特点:
<1>.定义函数可以将功能代码进行封装,便于对该功能进行复写。
<2>.函数只有被调用才会被执行。
<3>.函数的出现提高了代码的复用性。
<4>.对于函数没有具体返回值的情况,返回值类型用关键字void表示,那么该函数中的 return语句如果在最后一 行可以省略不写。
<5>.函数中只能调用函数,不可以在函数内部定义函数。
<6>.定义函数时,函数的结果应该返回给调用者,交由调用者处理。
<7>.可以自定义一个访问权限。
定义函数时需要注意:
<1>.功能中只定义所需内容,不是该功能所需的内容不要定义。
<2>.如果非要定义,也是单独定义一个功能来体现。以后开发时,尽量都将功能以不同的函数来体现。
<3>.不要将代码都定义在主函数中。
<4>.主函数的作用是:对已有的功能的进行调用,可以理解为用于功能的测试。
<5>.函数名就是一个自己定义的标示符。函数名的定义,要尽量体现出这个函数的功能。是为了增强该函数的 阅读性,方便于调用者使用,所以函数名一定要有起的有意义。
<6>.静态方法只能调用静态方法。主函数是静态的。
<7>.返回值类型和参数类型没有直接关系。
定义函数时候需要有两个明确:
<1>这个函数会得到什么结果,也就是返回值是什么。
<2>有没有未知内数据参与运算。
(3).函数的重载(Overload):
<1>.重载的概念:在同一个类中,允许存在一个以上的同名函数,只要它们的参数个数和参数类型不同即可。
<2>.重载的特点:与返回值类型无关,只看参数列表。
<3>.重载的好处:方便于阅读,优化了程序设计。
注:Java是严谨性语言,如果函数出现的调用不确定性,会编译失败。
(4).函数重载什么时候使用?
重载:当定义的功能相同,但参与运算的未知内容不同,那么,这时就定义一个函数名称以表示其功能,方便阅读,而通过参数列表的同来区分多个同名函数。
八、数组
(1).数组的概述:
<1>.概念:同一种类型数据的集合。其实数组就是一个容器。
<2>.好处:可以自动给数组中的元素从0开始编号,方便操作这些元素。
<3>.对数组的基本操作就是存和取。核心思想:基于角标。
<4>既可以存储基本数据类型又可以存储引用类型,只是长度固定。集合长度可变,但只能存储引用类型。
(2).数组的定义:
<1>元素类型[] 数组名 = new 元素类型[元素个数或数组长度];
<2>元素类型[] 数组名 ={1,2,3,4,5,6,7};可以直接指定具体的数据
<3>元素类型[] 数组名;
数组名 = new 元素类型[元素个数或数组长度];
(3).数组的特点:
<1>数组定义时,必须明确数组的长度(就是数组中可以存储的元素的个数。)因为数组长度是固定的。
<2>数组定义时,必须明确数组中的元素的数据类型。
例子:
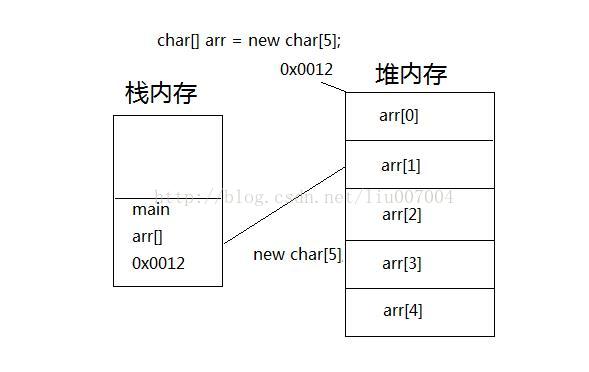
char[] arr = new char[5];
arr[0] = '黑';arr[1] ='马';
(4).数组的内存结构:
Java内存区域的划分
<2>.函数的格式:
修饰符 返回值类型 函数名(参数类型 形式参数1,参数类型 形式参数2...) {
执行语句;
return 返回值;
}
(2).函数的特点:
<1>.定义函数可以将功能代码进行封装,便于对该功能进行复写。
<2>.函数只有被调用才会被执行。
<3>.函数的出现提高了代码的复用性。
<4>.对于函数没有具体返回值的情况,返回值类型用关键字void表示,那么该函数中的 return语句如果在最后一 行可以省略不写。
<5>.函数中只能调用函数,不可以在函数内部定义函数。
<6>.定义函数时,函数的结果应该返回给调用者,交由调用者处理。
<7>.可以自定义一个访问权限。
定义函数时需要注意:
<1>.功能中只定义所需内容,不是该功能所需的内容不要定义。
<2>.如果非要定义,也是单独定义一个功能来体现。以后开发时,尽量都将功能以不同的函数来体现。
<3>.不要将代码都定义在主函数中。
<4>.主函数的作用是:对已有的功能的进行调用,可以理解为用于功能的测试。
<5>.函数名就是一个自己定义的标示符。函数名的定义,要尽量体现出这个函数的功能。是为了增强该函数的 阅读性,方便于调用者使用,所以函数名一定要有起的有意义。
<6>.静态方法只能调用静态方法。主函数是静态的。
<7>.返回值类型和参数类型没有直接关系。
定义函数时候需要有两个明确:
<1>这个函数会得到什么结果,也就是返回值是什么。
<2>有没有未知内数据参与运算。
(3).函数的重载(Overload):
<1>.重载的概念:在同一个类中,允许存在一个以上的同名函数,只要它们的参数个数和参数类型不同即可。
<2>.重载的特点:与返回值类型无关,只看参数列表。
<3>.重载的好处:方便于阅读,优化了程序设计。
注:Java是严谨性语言,如果函数出现的调用不确定性,会编译失败。
(4).函数重载什么时候使用?
重载:当定义的功能相同,但参与运算的未知内容不同,那么,这时就定义一个函数名称以表示其功能,方便阅读,而通过参数列表的同来区分多个同名函数。
八、数组
(1).数组的概述:
<1>.概念:同一种类型数据的集合。其实数组就是一个容器。
<2>.好处:可以自动给数组中的元素从0开始编号,方便操作这些元素。
<3>.对数组的基本操作就是存和取。核心思想:基于角标。
<4>既可以存储基本数据类型又可以存储引用类型,只是长度固定。集合长度可变,但只能存储引用类型。
(2).数组的定义:
<1>元素类型[] 数组名 = new 元素类型[元素个数或数组长度];
<2>元素类型[] 数组名 ={1,2,3,4,5,6,7};可以直接指定具体的数据
<3>元素类型[] 数组名;
数组名 = new 元素类型[元素个数或数组长度];
(3).数组的特点:
<1>数组定义时,必须明确数组的长度(就是数组中可以存储的元素的个数。)因为数组长度是固定的。
<2>数组定义时,必须明确数组中的元素的数据类型。
例子:
char[] arr = new char[5];
arr[0] = '黑';arr[1] ='马';
(4).数组的内存结构:
Java内存区域的划分
<1>寄存器
<2>本地方法区
<3>方法区
<4>栈内存
<5>堆内存
为什么划分这么区域?因为每一个内存区域对数据的处理方式不同。目前要讲的就是栈和堆。
<1>栈内存的特点:存储都是局部变量
(函数参数,函数内定义的变量,语句中定义的变量)变量一旦使用完(作用域结束),就会在栈内存中自动释放。
<2>堆内存特点:存储的是实体
堆内存中的实体都有首内存地址值,堆内存中的变量都有默认初始化值,对于没有任何引用变量指向的实体,会视为垃圾,会被垃圾回收机制所回收。 (数组和对象,只要是new的,都在堆内存中) 。
为什么划分这么区域?因为每一个内存区域对数据的处理方式不同。目前要讲的就是栈和堆。
<1>栈内存的特点:存储都是局部变量
(函数参数,函数内定义的变量,语句中定义的变量)变量一旦使用完(作用域结束),就会在栈内存中自动释放。
<2>堆内存特点:存储的是实体
堆内存中的实体都有首内存地址值,堆内存中的变量都有默认初始化值,对于没有任何引用变量指向的实体,会视为垃圾,会被垃圾回收机制所回收。 (数组和对象,只要是new的,都在堆内存中) 。
(5).操作数组时常见问题:
A.数组角标越界异常(ArrayIndexOutOfBoundsException):操作数组时,访问到了数组中不存在的角标。
B.空指针异常(NullPointerException):当引用没有任何指向值为null的情况,该引用还在用于操作实体。
(6).对数组的常见操作:
<1>.获取数组中的元素
A.数组角标越界异常(ArrayIndexOutOfBoundsException):操作数组时,访问到了数组中不存在的角标。
B.空指针异常(NullPointerException):当引用没有任何指向值为null的情况,该引用还在用于操作实体。
(6).对数组的常见操作:
<1>.获取数组中的元素
<2>.获取最值
最大值:
/* 思路:
1,需要进行比较。并定义变量记录住每次比较后较大的值。
2,对数组中的元素进行遍历取出,和变量中记录的元素进行比较。
如果遍历到的元素大于变量中记录的元素,就用变量记录住较大的值。
3,遍历结果,该变量记录就是最大值。
定义一个功能来是实现。
明确一,结果。
是数组中的元素。int .
明确二,未知内容。
数组.
*/
<3>.排序(冒泡排序 最大的在最后、选择排序)
/*排序(选择排序,冒泡排序)*/
public static void swap(int[] arr,int x,int y)
{
int temp = arr[x];
arr[x]= arr[y];
arr[y]= temp;
}
/*
冒泡排序。
*/
public static void bubbleSort(int[] arr)
{
for(int x=0; xarr[y+1])
{
swap(arr,y,y+1);
}
}
}
}
/*
选择排序。
*/
public static void selectSort(int[] arr)
{
for(int x=0; xarr[y])
{
swap(arr,x,y);
}
}
}
} 利用数组进行进制转换
public static void toBin(int num)
{
//定义二进制的表。
char[] chs = {'0','1'};
//定义一个临时存储容器。
char[] arr = new char[32];
//定义一个操作数组的指针
int pos = arr.length;
while(num!=0)
{
int temp = num & 1;
arr[--pos] = chs[temp];
num = num >>> 1;
}
for(int x=pos; x>> offset;
}
System.out.println("pos="+pos);
//存储数据的arr数组遍历。
for(int x=pos;x 九、二维数组
(1).什么是二维数组:
其实元素就是一个一维数组。
(2).二维数组格式:
<1>.方式1:元素类型[][] 数组名 = new 元素类型[3][2];
例子:
int[][] arr = new int[3][2];
解释:
定义了名称为arr的二维数组 ,二维数组中有3个一维数组 每一个一维数组中有2个元素 ,一维数组的名称分别为arr[0], arr[1], arr[2]
给第一个一维数组1索引位赋值为78写法是:arr[0][1] = 98;
<2>.方式2:元素类型[][] 数组名 =new 元素类型[3][];
例子:
int[][] arr = new int[3][];
二维数组中有3个一维数组元素,每个一维数组都是默认初始化值null ,可以对这个三个一维数组分别进行初始化
arr[0] = new int[3];
arr[1] = new int[1];
arr[2] = new int[2];
<3>.方式3:元素类型[][] 数组名 = {{一维数组元素}{一维数组元素}{一维数组元素}};
int[][] arr = {{3,8,2},{2,7},{9,0,1,6}};
(3).二维数组的遍历
思路:
<1>.二维数组的每一个元素是一维数组。 获取到每一个一维数组。
<2>.一维数组的遍历。
<2>.方式2:元素类型[][] 数组名 =new 元素类型[3][];
例子:
int[][] arr = new int[3][];
二维数组中有3个一维数组元素,每个一维数组都是默认初始化值null ,可以对这个三个一维数组分别进行初始化
arr[0] = new int[3];
arr[1] = new int[1];
arr[2] = new int[2];
<3>.方式3:元素类型[][] 数组名 = {{一维数组元素}{一维数组元素}{一维数组元素}};
int[][] arr = {{3,8,2},{2,7},{9,0,1,6}};
(3).二维数组的遍历
思路:
<1>.二维数组的每一个元素是一维数组。 获取到每一个一维数组。
<2>.一维数组的遍历。
class Test
{
public static void main(String[] args)
{
//二维数组的遍历
int[][] arr = {{3,8,2},{2,7},{9,0,1,6}};
//arr.length 获取二维数组的长度,其实也就是一维数组的个数
for(int x=0; x