李宏毅学习笔记18.Explainable ML
文章目录
- 简介
- 例子
- 原因
- Myth of Explainable ML
- Interpretable v.s.Powerful
- Local Explanation: Explain the Decision
- Basic ldea
- Limitation of Gradient based Approaches
- Attack Interpretation?!
- Case Study: Pokémon v.s. Digimon
- Saliency Map分析
- GLOBAL EXPLANATION: EXPLAIN THE WHOLE MODEL
- Activation Minimization (review)
- 用Generator做正则
- USING A MODEL TO EXPLAIN ANOTHER
- 怎么做
- Local Interpretable ModelAgnostic Explanations (LIME)
- LIME - Image
- Decision Tree
简介
这个内容也是新的,EXPLAINABLE MACHINE LEARNING
机器不但要知道,还要告诉我们它为什么会知道。
公式输入请参考:在线Latex公式
例子
之前的作业中有做分类:
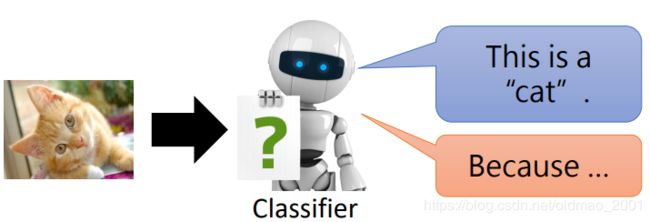
关于解释有两种:
Local Explanation: Why do you think this image is a cat?
Global Explanation: What do you think a “cat” looks like?
原因
用机器来协助判断简历
·具体能力?还是性别?
用机器来协助判断犯人是否可以假释
·具体证据?还是肤色?
金融相关的决策常常依法需要提供理由
·为什麽拒绝了某個人的贷款?
模型诊断:到底机器学到了甚麽
·不能只看正确率?想想神马汉斯的故事
一个多世纪前欧洲某个国家的一个农场出了一个非常聪明的名叫汉斯的神马。它不仅可以完成10以内的加减乘除,而且还能和人玩丢手绢游戏,总能找到拿手绢的人。后来一位马戏团的老板听说后很不以为然,决定揭穿这位农场主的戏法。老板带了几个随员,专门盯住农场主四肢的一举一动,老板相信是农场主给了汉斯信号。结果老板失败了。农场主根本没有参与测验,汉斯照样100%得到正确答案。汉斯后来越来越有名,结果惊动了一位科学家。这位科学家去测试汉斯,发现汉斯的确能给出任何计算的答案。汉斯给出答案的方法很简单,就是用前蹄敲地面,敲几下,就是答案。这位科学家眼看无计可施,无法判断汉斯是否真有计算能力时,突然问汉斯从农场到首都有多远?结果汉斯敲了几下蹄子后就开始犹豫不决。科学家突然明白了,汉斯只知道人们已经知道的答案,它不会计算。不过汉斯的确是一个聪明的马,它能根据人的各种表情、眼神乃至身体动作判断一个数的正确性。后来这位科学家决定取代汉斯。他让人心里想一个数,他用敲桌子的方式猜出这个数。他同样也能近乎100%地猜中人心里的数。当代测谎仪也是遵循同样的道理。
最近北京出了一个5个月大的超常婴儿,据说可以做加减乘除开根,认识上千个字,等等。方法同样是父母用一个正确,一个错误的答案让婴儿去猜。其实这和神马汉斯没有大的区别。真要测试婴儿,一个是拿多个,比如4个以上的答案让他猜,或者给他两个错误答案让他猜。家长愿意让孩子过早地记忆抽象的东西是家长的选择和自由,经过训练孩子会比其他没有训练的孩子不一样,属于异常,并非是超常。这种训练很容易让孩子远离同龄人,没有朋友,变成江郎,或者成为出家人。
We can improveML model based on explanation.
Myth of Explainable ML
·Goal of ML Explanation ≠ you completely know how the ML model work(Not necessary)
·Human brain is also a Black Box!
·People don’t trust network because it is Black Box,but you trust the decision of human!
·Goal of ML Explanation is(my point of view)
Make people(your customers,your boss,yourself)comfortable.(让人觉得很爽)
Personalized explanation in the future
Interpretable v.s.Powerful
·Some models are intrinsically interpretable.
·For example,linear model(from weights,you know the importance of features)
·But…not very powerful.
·Deep network is difficult to interpretable.
·Deep network is a black box.
Because deep network is a black box,we don’t use it.(这样做是不对的)
·But it is more powerful than linear model…
Let’s make deep network interpretable.
·Are there some models interpretable and powerful at the same time?
·How about decision tree?
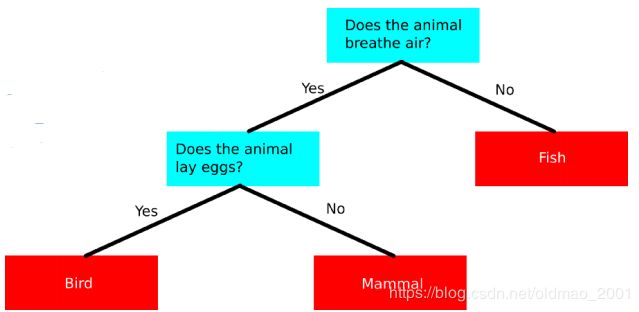
其实树本身也可以很复杂(后面课程有二次元的例子,用树来解析图片)

还可以由很多树组合为森林,因此decision tree的可解释性也不是很好。
因此,本课从两个方面来学习ML的可解释性。
Local Explanation: Explain the Decision
Basic ldea
假设我们的对象x有N个组件,这些组件可以用来判断x。

如果是用pixel,那么x就是一个个的像素
如果是用segment,那么就是把图片分成一块块的。

We want to know the importance of each components for making the decision.
Idea: Removing or modifying the values of the components, observing the change of decision.
如果有Large decision change,那么就可以得到:Important component
例如:找一个图片,然后用一个灰色的方块,这个方块可以在图片中任意一个位置。当灰色图片位于某个位置导致机器判断改变,那么我们就把这个位置的方块区域看为重要的component。

上图中,蓝色区域就是重要区域,把这个区域遮住就会无法判断这是一只国美狗。同理:

Reference: Zeiler, M. D., & Fergus, R. (2014). Visualizing and understanding convolutional networks. In Computer Vision–ECCV 2014 (pp. 818-833)
注意,方块的大小和颜色会影响结果。
另外一种方法:
将 x 1 , . . . , x n , . . . , x N x_1,...,x_n,...,x_N x1,...,xn,...,xN中的某一项加上一些噪声变成 x 1 , . . . , x n + Δ x , . . . , x N x_1,...,x_n+\Delta x,...,x_N x1,...,xn+Δx,...,xN
看这个噪声对输出 y k y_k yk有什么影响: y k + Δ y y_k+\Delta y yk+Δy
y k y_k yk是模型预测为分类k的概率。如果影响越大那么越重要

影响可以用 ∣ Δ y Δ x ∣ |\cfrac{\Delta y}{\Delta x}| ∣ΔxΔy∣来表示,计算方式就是求偏导: ∣ ∂ Δ y ∂ Δ x ∣ |\cfrac{\partial{\Delta y}}{\partial{\Delta x}}| ∣∂Δx∂Δy∣
得到的图称为:Saliency Map
文献:Karen Simonyan, Andrea Vedaldi, Andrew Zisserman, “Deep Inside Convolutional
Networks: Visualising Image Classification Models and Saliency Maps”, ICLR, 2014
To Learn More……
· Grad-CAM(https://arxiv.org/abs/1610.02391)
· SmoothGrad(https://arxiv.org/abs/1706.03825)
· Layer-wise Relevance Propagation
(https://arxiv.org/abs/1604.00825)
· Guided Backpropagation
(https://arxiv.org/abs/1412.6806)
Limitation of Gradient based Approaches
缺点:刚才那种方法基本要依靠Gradient Saturation
例如:大象的鼻子对于判断图片中是否有大象非常关键,但是当鼻子长到一定程度之后,机器就会非常的肯定是一只大象:
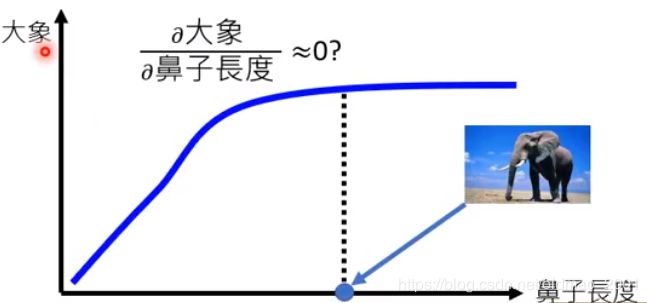
也就是说,鼻子的长度超过某个阈值之后,再变长对于判断大象这个事情没有啥帮助了。这个明显是不合理的。
To deal with this problem:(两种方法解决这个问题)
DeepLIFT
(https://arxiv.org/abs/1704.02685)
Integrated gradient
(https://arxiv.org/abs/1611.02639)
Attack Interpretation?!
(https://arxiv.org/abs/1710.10547)
找到重要的component之后就可以对判断进行干扰,例如一个卡车,用两种方法判断出来的重要component如下:
Vanilla Gradient
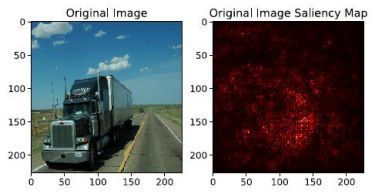
Deep LIFT

加入扰动噪声后:
Vanilla Gradient

Deep LIFT

可以看到,机器判断的component变成了白云。
Case Study: Pokémon v.s. Digimon
分辨神奇宝贝(现在叫宝可梦)和数码宝贝

各自的数据集:
Pokémon images: https://www.Kaggle.com/kvpratama/pokemonimages-dataset/data
Digimon images:https://github.com/DeathReaper0965/Digimon-Generator-GAN
例如:

Testing Images:

第一只:宝可梦
第二只:数码宝贝
第三只:宝可梦
看机器能否识别,随便叠一个model

结果:
Training Accuracy: 98.9%
Testing Accuracy: 98.4%
准确率很高啊,为什么呢?来分析一下Saliency Map
Saliency Map分析
数码宝贝

宝可梦:

发现机器学习的重点居然都是图片的背景,为什么?因为图片的格式:
All the images of Pokémon are PNG, while most images of Digimon are JPEG.
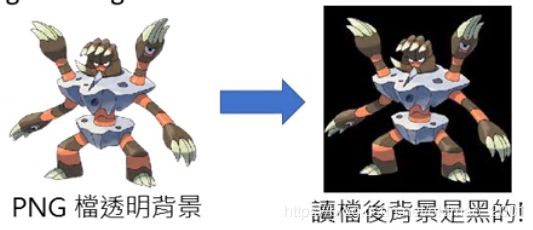
Machine discriminate Pokémon and Digimon based on Background color
This shows that explainable ML is very critical.
GLOBAL EXPLANATION: EXPLAIN THE WHOLE MODEL
这块内容之前有讲过,就是找到一个图片,让某个隐藏层的输出最大:
Activation Minimization (review)
手写数字识别的模型
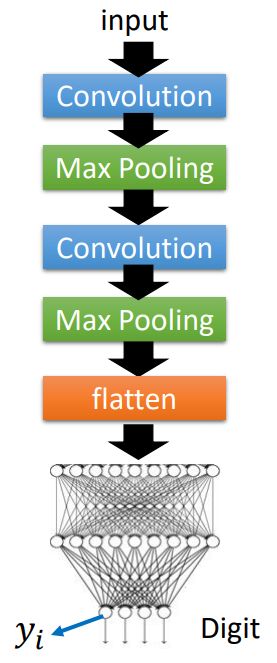
x ∗ = a r g m a x x y i x^*=arg\underset{x}{max}y_i x∗=argxmaxyi
找出机器认为理想的数字如下:

加上限制,图片要越像数字越好:

With several regularization terms, and hyperparameter tuning ……
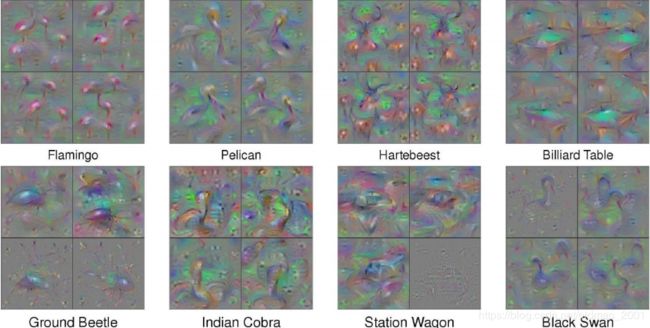
文献:https://arxiv.org/abs/1506.06579
用Generator做正则
上面提到要对图片做一个限制,比较像一个图片,这个事情可以用Generator来做,大概步骤如下:
通过一个低维向量进行输入,经过GAN或者VAE等生成模型,得到图片。
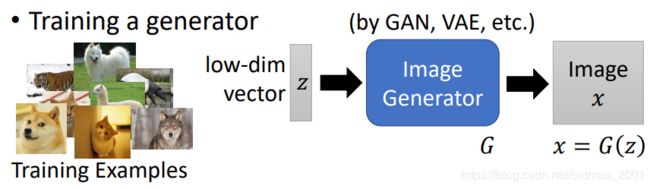
然后再接入上面的模型,image x要使得输出越像y越好,现在加入了生成模型后,就是要找z使得输出越像y越好,最好的那个z记为 z ∗ z^* z∗:
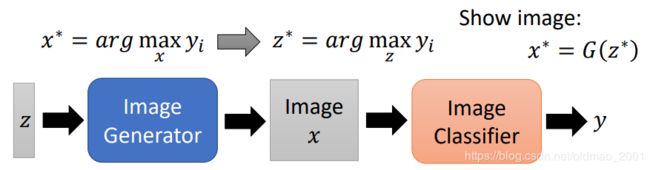
用这个方法得到的一些结果:


文献:https://arxiv.org/abs/1612.00005
这里和GAN里面的discriminator不一样,discriminator只会判断generator生成的图片好或者不好,这里是要生成某一个类型的图片。generator不变,我们调整的是低维向量z。
USING A MODEL TO EXPLAIN ANOTHER
Some models are easier to Interpret.
Using interpretable model to mimic uninterpretable model.
怎么做
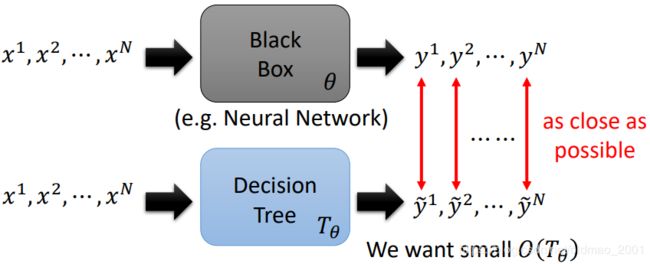
Using an interpretable model to mimic the behavior of an uninterpretable model.
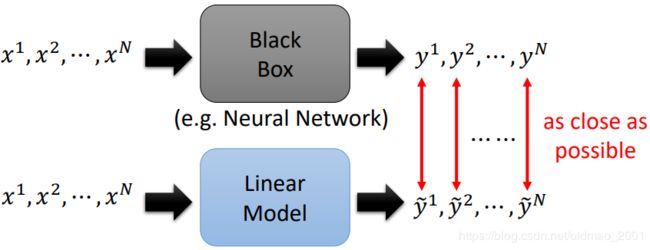
我们需要训练蓝色具有解释性的模型,使得在相同输入的情况下,两个模型的输出越接近越好。当蓝色模型和黑色模型一样的时候,我们就可以研究在训练蓝色模型的过程中模型学到了什么东西。
Problem: Linear model cannot mimic neural network …
但是:it can mimic a local region.只模拟部分。
下面来看例子:
Local Interpretable ModelAgnostic Explanations (LIME)
假设模型是黑盒子,输入和输出都是一维的。
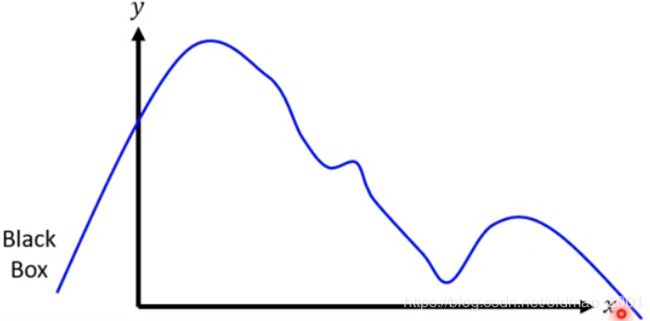
1.Given a data point you want to explain
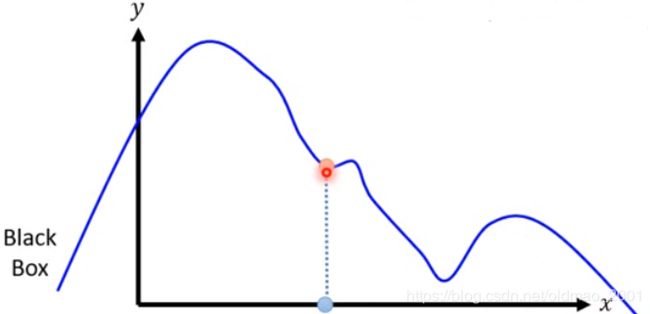
2.Sample at the nearby(x轴蓝色的),然后把蓝点代入黑盒子,得到具体的y值。
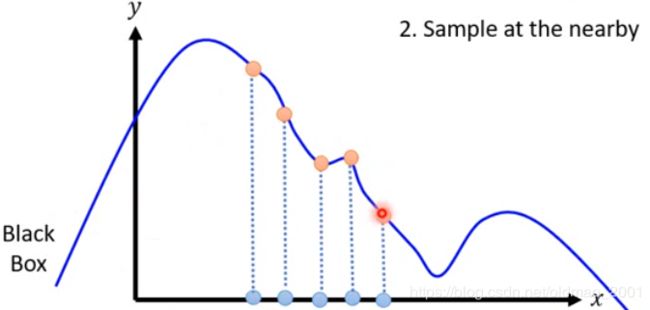
3. Fit with linear model(or other interpretable models)可以得到在这个区域内x增大,y变小的结论。
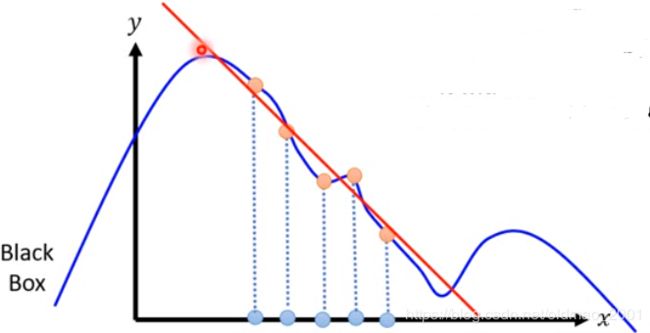
4. Interpret the linear model ,取值不一样,得到的结论不一样:
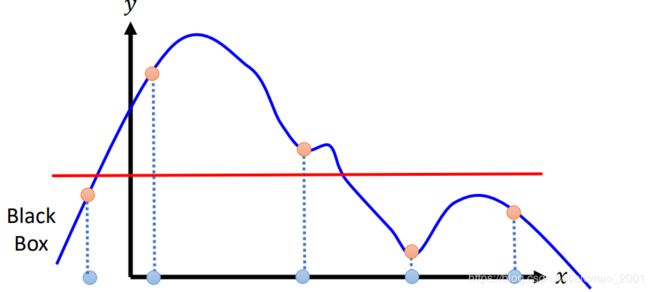
下面看一下用LIME解释如何识别一个图片
LIME - Image
我们知道线性模型不能fit图片,只能对图片做local的解释。

- Given a data point you want to explain
- Sample at the nearby
• Each image is represented as a set of superpixels(segments).
Randomly delete some segments.

然后用黑盒子计算结果Compute the probability “frog” by black box - Fit with linear (or interpretable) model
但是之前说过,把图片输入到线性模型不好弄,这里要设计一下,先对图片做extraction,提取特征将pixel表示为低维的向量。
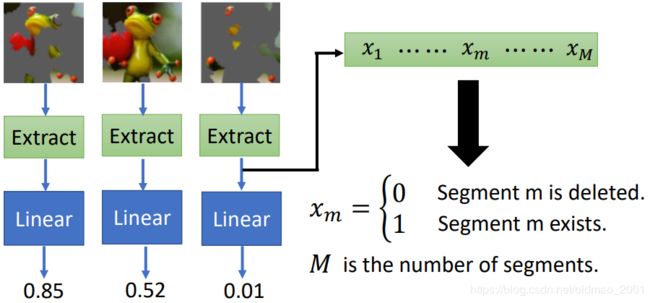
这里M是一个超参数。 - Interpret the model you learned
y = w 1 x 1 + ⋯ + w m x m + ⋯ + w M x M x m = 0 , S e g m e n t m i s d e l e t e d x m = 1 , S e g m e n t m e x i s t s y=w_1x_1+\cdots+w_mx_m+\cdots+w_Mx_M\\ x_m=0,Segment\space m\space is\space deleted\\ x_m=1,Segment\space m\space exists y=w1x1+⋯+wmxm+⋯+wMxMxm=0,Segment m is deletedxm=1,Segment m exists
If w m w_m wm ≈ 0, segment m is not related to “frog”
If w m w_m wm is positive, segment m indicates the image is “frog”
If w m w_m wm is negative, segment m indicates the image is not “frog”
再看老师手工实例:

结果分析:
和服:0.25
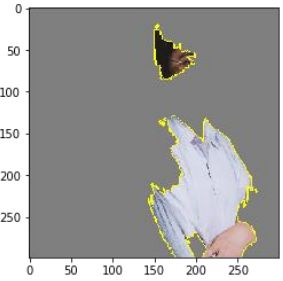
實驗袍:0.05
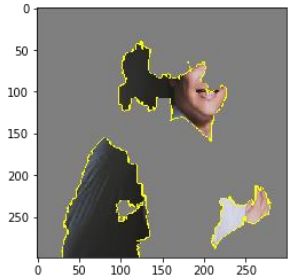
Decision Tree
下面用Decision Tree来代替上面的线性模型做解释工作。
当Decision Tree足够复杂理论上完全可以模仿黑盒子的结果,但是这样Decision Tree会非常非常复杂,那么Decision Tree本身又变得没法解释了,因此:Problem: We don’t want the tree to be too large.
这里我们用 O ( T θ ) O(T_\theta) O(Tθ)表示决策树的复杂度。
一般情况下,模型的损失函数为:
θ = a r g m i n θ L ( θ ) \theta=arg\underset{\theta}{min}L(\theta) θ=argθminL(θ)
Train a network that is easy to be interpreted by decision tree.要考虑决策树的复杂度,因此要在损失函数中加一个正则项:
θ = a r g m i n θ L ( θ ) + λ O ( T θ ) \theta=arg\underset{\theta}{min}L(\theta)+\lambda O(T_\theta) θ=argθminL(θ)+λO(Tθ)
Is the objective function with tree regularization differentiable? No! Check the reference for solution
但是这个正则项没法做偏导,所以没有办法做GD。
解决方法:https://arxiv.org/pdf/1711.06178.pdf
中心思想是用一个随机初始化的结构简单的NN,训练后可以模拟出决策树的参数,然后用NN替换上面的正则项,NN是可以偏导的,然后就可以GD了。