Fasttext
目录
- 《Bag of Tricks for Efficient Text Classification》
- 1、论文总览
- Abstract
- 1.1 Introduction
- 1.2 Model architecture
- 1.3 Experiments
- 1.4 Discussion and conclusion
- 2、论文导读
- 2.1 论文背景知识
- 2.1.1 基于深度学习的文本分类模型
- 2.1.2 论文背景
- 2.2 论文研究成果及意义
- 2.2.1 论文研究成果
- 2.2.2 论文研究意义
- 3、论文精读
- 3.1 摘要
- 3.2 Fasttext模型
- 3.3 Fasttext模型和CBOW模型的区别和联系
- 3.4 Fasttext模型的优缺点
- 3.5 Fasttext应用
- 3.6 基于SubWord词向量的训练方法
- 3.6.1 Skip-gram模型
- 3.6.2 Subword词向量
- 4、论文总结
- 5、代码复现
- 5.1 项目环境配置
- 5.2 数据集下载
- 5.3 数据处理模块
- 5.4 Fasttext模型
《Bag of Tricks for Efficient Text Classification》
- Fasttext:对于高效率文本分类的一揽子技巧
- 作者:Armand Joulin(第一作者)
- 单位:Facebook
- 会议:EACL 2017
1、论文总览
Abstract
本文提出了一种简单并且高效的文本分类模型,我们模型的效果和其它深度学习模型相当,但是速度快了好几个数量级。
1.1 Introduction
文本分类是自然语言处理中非常重要的任务,基于深度学习的文本分类任务效果很好,但是速度很慢。而线性分类器一般也表现很好,而且速度快,所以本文提出了一种快速的线性分类器Fasttext。
1.2 Model architecture
详细介绍了Fasttext的模型结构以及两个技巧,分别为层次softmax和N-gram特征。
1.3 Experiments
在文本分类任务上和tag预测任务上都取得了非常好的效果。
1.4 Discussion and conclusion
对论文进行一些总结。
2、论文导读
2.1 论文背景知识
2.1.1 基于深度学习的文本分类模型
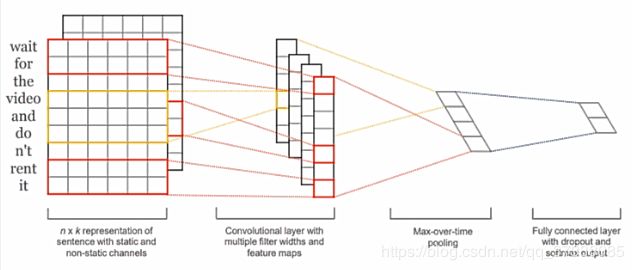
基 于 卷 积 神 经 网 络 的 文 本 分 类 模 型 ( C o n v o l u t i o n a l N e u r a l N e t w o r k s f o r S e n t e n c e C l a s s i f i c a t i o n , 2014 ) 基于卷积神经网络的文本分类模型(Convolutional \space Neural \space Networks \space for \space Sentence \space Classification,2014) 基于卷积神经网络的文本分类模型(Convolutional Neural Networks for Sentence Classification,2014)

字 符 级 别 卷 积 神 经 网 络 的 文 本 分 类 模 型 ( c h a r a c t e r − l e v e l C o n v o l u t i o n a l N e t w o r k s f o r T e x t C l a s s i f i c a t i o n , 2015 ) 字符级别卷积神经网络的文本分类模型(character-level \space Convolutional \space Networks \space for \space Text \space Classification,2015) 字符级别卷积神经网络的文本分类模型(character−level Convolutional Networks for Text Classification,2015)
基于深度学习的文本分类模型的优点:
- 效果好,一般能达到目前最好的分类效果;
- 不用做特征工程,模型简洁;
基于深度学习的文本分类模型的缺点:
- 速度太慢,无法在大规模的文本分类任务上使用;
基于机器学习的文本分类模型的优点:
- 速度一般都很快,因为模型都是线性分类器,所以比较简单;
- 效果还可以,在某些任务上也能取得最好的效果;
基于机器学习的文本分类模型的缺点:
- 需要做特征工程,分类效果依赖于有效特征的选取;
Fasttext的动机:
综合深度学习的文本分类模型和机器学习的文本分类模型的优点,达到:
- 速度快;
- 效果好;
- 自动特征工程;
2.1.2 论文背景
- 文本分类是自然语言处理的重要任务,可以用于信息检索、网页搜索、文档分类等;
- 基于深度学习的方法可以达到非常好的效果,但是速度很慢,限制了文本分类的应用;
- 基于机器学习的线性分类器效果也很好,有用于大规模分类任务的潜力;
- 从现在词向量学习中得到的灵感,作者提出了一种新的文本分类方法Fasttext,这种方法能够快速的训练和测试并达到和最优结果相似的效果;
2.2 论文研究成果及意义
2.2.1 论文研究成果
- Fasttext在多个任务上表现很好;
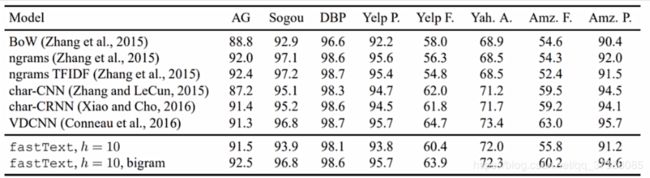
- Fasttext在效果很好的同时,速度非常快;

2.2.2 论文研究意义
Fasttext历史意义
- 提出了一种新的文本分类方法——Fasttext,能够进行快速的文本分类,并且效果很好;
- 提出了一种新的使用子词的词向量训练方法-Fasttext,能够一定程度上解决OOV问题;
- 将Fasttext开源,使得工业界和学术界能够快速使用Fasttext;
3、论文精读
3.1 摘要
- 本文为文本分类任务提出了一种简单并且高效的基准模型——Fasttext;
- Fasttext模型在精度上和基于深度学习的分类器平分秋色,但是在训练和测试速度上Fasttext快上几个数量级;
- 我们使用标准的多核CPU在10亿词的数据集上训练Fasttext,用时少于10分钟,并且在一分钟内分类好具有312k类别的50万个句子;
3.2 Fasttext模型
Fasttext模型和word2vec中的CBOW相似,现在先简单介绍一下CBOW模型,CBOW简单来说就是用周围词预测中心词,因为周围词有很多个,所以需要将所有的周围词向量SUM到一起,我们经常是对周围词向量进行取平均操作,然后基于平均得到的向量预测中心词。
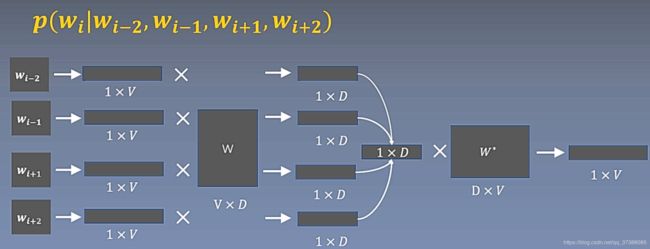
CBOW模型

下面简单分析一下CBOW的计算过程,如下图, W W W为周围词的词向量矩阵, W ∗ W^* W∗是中心词的词向量矩阵,假设窗口大小为2,CBOW模型首先将左边两个背景词和右边两个背景词映射出one-hot向量,图中的V为词表大小,背景词向量矩阵 W W W的维度D表示词嵌入的维度大小。
四个背景词的one-hot向量经过词嵌入矩阵后变为4个对应的词嵌入向量,4个背景词向量求和平均之后得到一个 1 ∗ D 1*D 1∗D的平均词向量。这一个平均词向量和中心词向量矩阵 W ∗ W^* W∗相乘最后得到一个长度为V的向量,V的大小为词的个数。该长度为V的向量有V个值,其值表示生成词表每个词的权重,如果要将这个权重转换为概率,还需要经过一个softmax变换。
因为Fasttext模型和CBOW非常相似,下面我们介绍一下Fasttext模型:

上图为原文中的模型结构图,图中的 x 1 x_1 x1, x 2 x_2 x2,…, x N x_N xN是一句话的词对应的词向量(假设为n维的向量),将N个词向量进行平均得到hidden(维度同样为n维的向量)。
hidden到output之间是一个n*label_num的矩阵,这样hidden的向量(维度为[1,n])乘于[n,label_num]的矩阵得到一个[1,label_num]的向量,label_num为分标签的个数。这也是CBOW和Fasttext的主要差别,CBOW对应的输出为词表大小个数,Fasttext为分类样本的个数。
3.3 Fasttext模型和CBOW模型的区别和联系
联系:
- 都是Log-linear模型,模型非常简单;
- 都是对输入的词向量做平均,然后进行预测;
- 模型结构完全一样;
区别:
- Fasttext提出的是句子特征,CBOW提出的是上下文特征;
- Fasttext需要标注语料,是监督学习,CBOW不需要标注语料,是无监督学习;
目前Fasttext存在的问题:
- 当类别非常多的时候,最后softmax速度依旧非常慢;
- 使用的是词袋模型,没有词序信息;
解决方法:、
- 类似于word2vec,使用层次softmax;
- 为了添加词序信息,使用n-gram特征添加局部词序信息;
3.4 Fasttext模型的优缺点
优点:
- 速度非常快,并且效果还可以;
- 有开源实现,可以快速上手使用;
缺点:
- 模型结构简单,所以目前来说,不是最优模型;
- 因为使用词袋思想,所以语义信息获取有限;
3.5 Fasttext应用
应用:
- 文本特别多,对分类速度要求很高的场合;
- 作为一个基准baseline;
3.6 基于SubWord词向量的训练方法
3.6.1 Skip-gram模型
基于SubWord的词向量训练方法和word2vec的Skip-gram方法比较类似,Skip-gram是使用中心词预测背景词,假设窗口大小为2,可以得到四个背景词的概率。

Skip-gram采用负采样的方法进行训练,因此计算损失函数的时候使用以下计算公式:
∑ t = 1 T [ ∑ c ∈ c t L ( s ( w t , w c ) + ∑ n ∈ N t , c L ( − s ( w t , n ) ) ] \sum_{t=1}^{T}\left[\sum_{c \in c_{t}} L\left(s\left(w_{t}, w_{c}\right)+\sum_{n \in N_{t}, c} L\left(-s\left(w_{t}, n\right)\right)\right]\right. t=1∑T⎣⎡c∈ct∑L⎝⎛s(wt,wc)+n∈Nt,c∑L(−s(wt,n))⎦⎤
对于基于中心词得到的一些正样本,希望其与中心词的內积越大越好,同样,对于采样得到的负样本,希望其和中心词的內积越小越好,对应于上述公式中的后半部分,加上负号表示越大越好。
3.6.2 Subword词向量
nlp中普遍存在的OOV问题,在传统的word2vec得到的词向量中,假设一个词congratulations被错误写为congratutations,则会由一个普通词变为一个unknow词。
subword的思想是定义一个字符的n-gram方法,比如给定一个词where,在其头部和尾部分别加上<和>,得到一个新词,再使用3-gram进行划分得到[
Subword的损失函数为:
s ( w , c ) = ∑ g ∈ G w z g T v c s(w, c)=\sum_{g \in G_{w}} z_{g}^{T} v_{c} s(w,c)=g∈Gw∑zgTvc
上述损失函数中的 v c v_c vc为中心词向量, z g z_g zg为背景词的子词向量。
举个例子,一个句子为“we have”,中心词为“have”,使用3-gram对have进行分词,得到have的子词组合为[
4、论文总结
关键点:
- 基于深度学习的文本分类方法效果好,但是速度比较慢;
- 基于线性分类器的机器学习方法效果还行,速度也比较快,但是需要做烦琐的特征工程;
创新点:
- 提出了一种新的文本分类模型——Fasttext模型;
- 提出了一种加快文本分类和使得文本分类效果更好的技巧——层次softmax和n-gram;
- 在文本分类和tag预测两个任务上得到了又快又好的结果;
启发点:
- 虽然这些深度学习模型能够取得非常好的效果,但是他们在训练和测试的时候非常慢,这限制了他们在大数据集上的应用;
- 然而,线性分类器不同特征和类别之间不共享参数,这可能限制了一些只有少量样本类别的泛化能力;
- 大部分词向量方法对每个词分配一个独立的词向量,而没有共享参数。特别的是,这些方法忽略了词之间的内在联系,这对于形态学丰富的语言更加重要;
5、代码复现
5.1 项目环境配置
- Python3.5
- jupyter notebook
- torch 1.4.0
- numpy 1.16.2
- nltk
- tqdm
- torchsummary
代码运行环境建议使用Pycharm;
Pycharm:强大的Python IDE,拥有调试、语法高亮、远程调试、代码跳转等功能;
5.2 数据集下载
- AG News: https://s3.amazonaws.com/fast-ai-nlp/ag_news_csv.tgz
- DBPedia: https://s3.amazonaws.com/fast-ai-nlp/dbpedia_csv.tgz
- Sogou news: https://s3.amazonaws.com/fast-ai-nlp/sogou_news_csv.tgz
- Yelp Review Polarity: https://s3.amazonaws.com/fast-ai-nlp/yelp_review_polarity_csv.tgz
- Yelp Review Full: https://s3.amazonaws.com/fast-ai-nlp/yelp_review_full_csv.tgz
- Yahoo! Answers: https://s3.amazonaws.com/fast-ai-nlp/yahoo_answers_csv.tgz
- Amazon Review Full: https://s3.amazonaws.com/fast-ai-nlp/amazon_review_full_csv.tgz
- Amazon Review Polarity: https://s3.amazonaws.com/fast-ai-nlp/amazon_review_polarity_csv.tgz
5.3 数据处理模块
- 数据集加载
- 读取标签和数据
- 创建word2id
- 将数据转化成id
from torch.utils import data
import os
import csv
import nltk
import numpy as np
# 数据集加载
f = open("./data/AG/train.csv")
rows = csv.reader(f,delimiter=',', quotechar='"')
rows = list(rows)
rows[0:5]
读取得到的rows是一个list,rows的前五行数据表示如下所示:
[['3',
'Wall St. Bears Claw Back Into the Black (Reuters)',
"Reuters - Short-sellers, Wall Street's dwindling\\band of ultra-cynics, are seeing green again."],
['3',
'Carlyle Looks Toward Commercial Aerospace (Reuters)',
'Reuters - Private investment firm Carlyle Group,\\which has a reputation for making well-timed and occasionally\\controversial plays in the defense industry, has quietly placed\\its bets on another part of the market.'],
['3',
"Oil and Economy Cloud Stocks' Outlook (Reuters)",
'Reuters - Soaring crude prices plus worries\\about the economy and the outlook for earnings are expected to\\hang over the stock market next week during the depth of the\\summer doldrums.'],
['3',
'Iraq Halts Oil Exports from Main Southern Pipeline (Reuters)',
'Reuters - Authorities have halted oil export\\flows from the main pipeline in southern Iraq after\\intelligence showed a rebel militia could strike\\infrastructure, an oil official said on Saturday.'],
['3',
'Oil prices soar to all-time record, posing new menace to US economy (AFP)',
'AFP - Tearaway world oil prices, toppling records and straining wallets, present a new economic menace barely three months before the US presidential elections.']]
文本数据中第一部分的“3”表示文本类别标签,第二部分为文本标题,第三部分为文本正文内容;
标签一般从0开始,而文本数据中从1开始,所以在数据处理时将标签值减一;在后面处理文本时将标题和正文拼接起来;
# 读取标签和数据
n_gram = 2
lowercase = True # 不区分大小写
label = []
datas = []
for row in rows:
label.append(int(row[0])-1) # label减一
txt = " ".join(row[1:]) # 拼接标题和正文,用空格隔开
if lowercase:
txt = txt.lower()
txt = nltk.word_tokenize(txt) # 将句子转化成词
new_txt= []
for i in range(0,len(txt)):
for j in range(n_gram): # 添加n-gram词
if j<=i:
new_txt.append(" ".join(txt[i-j:i+1])) # 因为n-gram=2,所以有两种情况,一种是单词,一种是双词
datas.append(new_txt)
print (label[0:5])
print (datas[0:5])
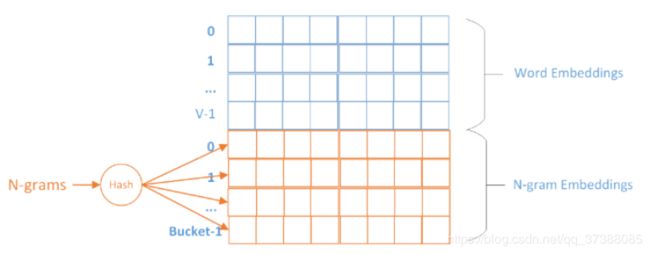
在Fasttext中使用了Hash技术,因为Fasttext中使用到n-gram技术,如果为每一个词或者n-gram词组构建一个词向量,则词表会非常大。因此在Fasttext中,对于每个词构建一个词向量,对于n-gram得到的词组,则可能会有多个n-gram词组共享一个词向量,这样能够减小词表的规模。
# 得到word2id
min_count = 3 # 词频小于3的词忽略
word_freq = {} # word2id字典
for data in datas: # 遍历每个句子,首先统计词频,后续通过词频过滤低频词
for word in data: # 遍历每个词
if word_freq.get(word)!=None: # 对应词的词频+1
word_freq[word]+=1
else:
word_freq[word] = 1
word2id = {"" :0,"" :1}
for word in word_freq: # 首先构建uni-gram词,因为不需要hash
if word_freq[word]<min_count or " " in word: # 如果词频小于3或者不是uni-gram则忽略
continue
word2id[word] = len(word2id)
uniwords_num = len(word2id) # 统计uni-gram的词个数
for word in word_freq: # 构建2-gram以上的词,需要hash
if word_freq[word]<min_count or " " not in word:
continue
word2id[word] = len(word2id)
word2id
# 将文本中的词都转化成id
max_length = 100 # 设定句子的最大长度为100
for i,data in enumerate(datas): # 遍历每个句子
for j,word in enumerate(data): # 遍历句子中的每个词
if " " not in word: # 如果是uni-gram词
datas[i][j] = word2id.get(word,1) # 获得词对应的id,如果是unknow词则设定为1(UNK词)
else:
datas[i][j] = word2id.get(word, 1)%100000+uniwords_num # hash函数,处理n-gram词
datas[i] = datas[i][0:max_length]+[0]*(max_length-len(datas[i])) # 对长度不足100的词则在句子后padding 0
datas[0:5]
5.4 Fasttext模型
import torch
import torch.nn as nn
import numpy as np
class Fasttext(nn.Module):
def __init__(self,vocab_size,embedding_size,max_length,label_num):
super(Fasttext,self).__init__()
self.embedding =nn.Embedding(vocab_size,embedding_size) # 嵌入层
self.avg_pool = nn.AvgPool1d(kernel_size=max_length,stride=1) # 平均层
self.fc = nn.Linear(embedding_size, label_num) # 全连接层
def forward(self, x):
x = x.long()
out = self.embedding(x) # batch_size*length*embedding_size
out = out.transpose(1, 2).contiguous() # batch_size*embedding_size*length
out = self.avg_pool(out).squeeze() # batch_size*embedding_size
out = self.fc(out) # batch_size*label_num
return out
fasttext = Fasttext(vocab_size=1000,embedding_size=10,max_length=100,label_num=4)
test = torch.zeros([64,100]).long()
out = fasttext(test)
from torchsummary import summary
summary(fasttext, input_size=(100,))
