徒手写代码之《机器学习实战》----K均值算法(1)(对地理坐标进行聚类)
对地理坐标进行聚类
说明:
将 places.txt 和 Portland.png 放在当前目录下。
from numpy import *
K-均值聚类支持函数
"""
1.选择聚类的个数,k。例如k=3
2.生成k个聚类中心点
3.计算所有样本点到聚类中心点的距离,根据远近聚类。
4.更新质心,迭代聚类。
5.重复第4步骤直到满足收敛要求。(通常就是确定的质心点不再改变)
创建 k 个点作为起始质心(随机选择)
当任意一个点的簇分配结果发生改变时(不改变时算法结束)
对数据集中的每个数据点
对每个质心
计算质心与数据点之间的距离
将数据点分配到距其最近的簇
对每一个簇, 计算簇中所有点的均值并将均值作为质心
直到簇不再发生变化或者达到最大迭代次数
"""
#函数功能:计算两个数据集之间的欧式距离
#输入:两个数据集。
#返回:两个数据集之间的欧式距离(此处用距离平方和代替距离)
def distEclud(vecA, vecB):
return sqrt(sum(power(vecA - vecB, 2))) #la.norm(vecA-vecB)
#创建簇中心矩阵,初始化为k个在数据集的边界内随机分布的簇中心
def randCent(dataSet, k):
n = shape(dataSet)[1]
centroids = mat(zeros((k,n)))#create centroid mat
for j in range(n):#create random cluster centers, within bounds of each dimension
#求出数据集中第j列的最小值(即第j个特征)
minJ = min(dataSet[:,j])
#用第j个特征最大值减去最小值得出特征值范围
rangeJ = float(max(dataSet[:,j]) - minJ)
#创建簇矩阵的第J列,random.rand(k,1)表示产生(10,1)维的矩阵,其中每行值都为0-1中的随机值
#可以这样理解,每个centroid矩阵每列的值都在数据集对应特征的范围内,那么k个簇中心自然也都在数据集范围内
centroids[:,j] = mat(minJ + rangeJ * random.rand(k,1))
return centroids
K-均值聚类算法
#distMeas为距离计算函数
#createCent为初始化随机簇心函数
"""
函数功能:k均值聚类算法
参数说明:
dataset:数据集
k:簇的个数
distMeas:距离计算函数
createCent:随机质心生成函数
返回:
centroids:质心
clusterAssment:所有数据划分结果
"""
def kMeans(dataSet, k, distMeas=distEclud, createCent=randCent):
m = shape(dataSet)[0]
#创建一个(m,2)维矩阵,第一列存储每个样本对应的簇心,第二列存储样本到簇心的距离
clusterAssment = mat(zeros((m,2)))
#用createCent()函数初始化簇心矩阵
centroids = createCent(dataSet, k)
#保存迭代中clusterAssment是否更新的状态,如果未更新,那么退出迭代,表示收敛
#如果更新,那么继续迭代,直到收敛
clusterChanged = True
while clusterChanged:
clusterChanged = False
#程序中可以创建一个标志变量clusterChanged,如果该值为True,则继续迭代。
#上述迭代使用while循环来实现。接下来遍历所有数据找到距离每个点最近的质心,
#这可以通过对每个点遍历所有质心并计算点到每个质心的距离来完成
#对每个样本找出离样本最近的簇心
for i in range(m):
#minDist保存最小距离
#minIndex保存最小距离对应的簇心
minDist = inf
minIndex = -1
#遍历簇心,找出离i样本最近的簇心
for j in range(k):
distJI = distMeas(centroids[j,:],dataSet[i,:])
if distJI < minDist:
minDist = distJI; minIndex = j
#如果clusterAssment更新,表示对应样本的簇心发生变化,那么继续迭代
if clusterAssment[i,0] != minIndex: clusterChanged = True
#更新clusterAssment,样本到簇心的距离
clusterAssment[i,:] = minIndex,minDist**2
print(centroids)
#遍历簇心,更新簇心为对应簇中所有样本的均值
for cent in range(k):
#利用数组过滤找出簇心对应的簇。获取某个簇类的所有点
ptsInClust = dataSet[nonzero(clusterAssment[:,0].A==cent)[0]]#get all the point in this cluster
#对簇求均值,赋给对应的centroids簇心
centroids[cent,:] = mean(ptsInClust, axis=0) #assign centroid to mean
return centroids, clusterAssment
二分 K-均值算法
def biKmeans(dataSet, k, distMeas=distEclud):
m = shape(dataSet)[0]
clusterAssment = mat(zeros((m,2)))
#取数据集特征均值作为初始簇中心
centroid0 = mean(dataSet, axis=0).tolist()[0]
#centList保存簇中心数组,初始化为一个簇中心
#create a list with one centroid
centList =[centroid0] #create a list with one centroid
for j in range(m):#calc initial Error
clusterAssment[j,1] = distMeas(mat(centroid0), dataSet[j,:])**2
#迭代,直到簇中心集合长度达到k
while (len(centList) < k):
#初始化最小误差
lowestSSE = inf
#迭代簇中心集合,找出找出分簇后总误差最小的那个簇进行分解
for i in range(len(centList)):
#获取属于i簇的数据集样本
ptsInCurrCluster = dataSet[nonzero(clusterAssment[:,0].A==i)[0],:]
#对该簇进行k均值聚类
centroidMat, splitClustAss = kMeans(ptsInCurrCluster, 2, distMeas)
#获取该簇分类后的误差和
sseSplit = sum(splitClustAss[:,1])
#获取不属于该簇的样本集合的误差和,注意矩阵过滤中用的是!=i
sseNotSplit = sum(clusterAssment[nonzero(clusterAssment[:,0].A!=i)[0],1])
#打印该簇分类后的误差和和不属于该簇的样本集合的误差和
print("sseSplit, and notSplit: ",sseSplit,sseNotSplit)
#两误差和相加即为分簇后整个样本集合的误差和,找出簇中心集合中能让分簇后误差和最小的簇中心,保存最佳簇中心(bestCentToSplit),
#最佳分簇中心集合(bestNewCents),以及分簇数据集中样本对应簇中心及距离集合(bestClustAss),最小误差(lowestSSE)
if (sseSplit + sseNotSplit) < lowestSSE:
bestCentToSplit = i
bestNewCents = centroidMat
bestClustAss = splitClustAss.copy()
lowestSSE = sseSplit + sseNotSplit
#更新用K-means获取的簇中心集合,将簇中心换为len(centList)和bestCentToSplit,
#以便之后调整clusterAssment(总样本集对应簇中心与和簇中心距离的矩阵)时一一对应
bestClustAss[nonzero(bestClustAss[:,0].A == 1)[0],0] = len(centList) #change 1 to 3,4, or whatever
bestClustAss[nonzero(bestClustAss[:,0].A == 0)[0],0] = bestCentToSplit
print('the bestCentToSplit is: ',bestCentToSplit)
print('the len of bestClustAss is: ', len(bestClustAss))
#更新簇中心集合,注意与bestClustAss矩阵是一一对应的
centList[bestCentToSplit] = bestNewCents[0,:].tolist()[0]
centList.append(bestNewCents[1,:].tolist()[0])
clusterAssment[nonzero(clusterAssment[:,0].A == bestCentToSplit)[0],:]= bestClustAss#reassign new clusters, and SSE
return mat(centList), clusterAssment
球面距离计算
"""
函数distSLC()返回地球表面两点间的距离,单位是英里。给定两个点的经纬度,可以使用
球面余弦定理来计算两点的距离。这里的纬度和经度用角度作为单位,但是sin()以及cos()以
弧度为输入。可以将角度除以180然后再乘以圆周率pi转换为弧度。导入NumPy的时候就会导
入pi
"""
def distSLC(vecA, vecB):#Spherical Law of Cosines
a = sin(vecA[0,1]*pi/180) * sin(vecB[0,1]*pi/180)
b = cos(vecA[0,1]*pi/180) * cos(vecB[0,1]*pi/180) * \
cos(pi * (vecB[0,0]-vecA[0,0]) /180)
return arccos(a + b)*6371.0 #pi is imported with numpy
数据导入函数
def loadDataSet(fileName): #general function to parse tab -delimited floats
dataMat = [] #assume last column is target value
fr = open(fileName)
for line in fr.readlines():
curLine = line.strip().split('\t')
fltLine = list(map(float,curLine)) #map all elements to float()
dataMat.append(fltLine)
return dataMat
聚类及簇绘图函数
import matplotlib
import matplotlib.pyplot as plt
"""
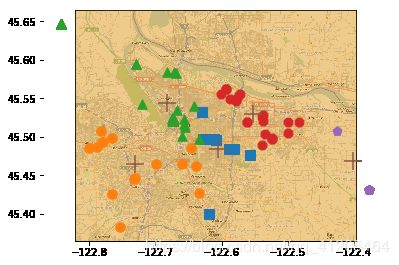
第二个函数clusterClubs()只有一个参数,即所希望得到的簇数目。该函数将文本文件的
解析、聚类以及画图都封装在一起,首先创建一个空列表,然后打开places.txt文件获取第4列和
第5列,这两列分别对应纬度和经度。基于这些经纬度对的列表创建一个矩阵。接下来在这些数
据点上运行biKmeans()并使用distSLC()函数作为聚类中使用的距离计算方法。最后将簇以及
簇质心画在图上
"""
def clusterClubs(numClust=5):
datList = []
for line in open('places.txt').readlines():
lineArr = line.split('\t')
datList.append([float(lineArr[4]), float(lineArr[3])])
datMat = mat(datList)
myCentroids, clustAssing = biKmeans(datMat, numClust, distMeas=distSLC)
fig = plt.figure()
rect=[0.1,0.1,0.8,0.8]
scatterMarkers=['s', 'o', '^', '8', 'p', \
'd', 'v', 'h', '>', '<']
axprops = dict(xticks=[], yticks=[])
ax0=fig.add_axes(rect, label='ax0', **axprops)
imgP = plt.imread('Portland.png')
ax0.imshow(imgP)
ax1=fig.add_axes(rect, label='ax1', frameon=False)
for i in range(numClust):
ptsInCurrCluster = datMat[nonzero(clustAssing[:,0].A==i)[0],:]
markerStyle = scatterMarkers[i % len(scatterMarkers)]
ax1.scatter(ptsInCurrCluster[:,0].flatten().A[0], ptsInCurrCluster[:,1].flatten().A[0], marker=markerStyle, s=90)
ax1.scatter(myCentroids[:,0].flatten().A[0], myCentroids[:,1].flatten().A[0], marker='+', s=300)
plt.show()
clusterClubs(5)
[[-122.50123301 45.48190552]
[-122.76168267 45.50290236]]
[[-122.55791888 45.51130344]
[-122.70332617 45.51328129]]
[[-122.55776318 45.51440209]
[-122.70347743 45.51027117]]
sseSplit, and notSplit: 3063.6947335061304 0.0
the bestCentToSplit is: 0
the len of bestClustAss is: 69
[[-122.48983786 45.51345496]
[-122.60443552 45.51145335]]
[[-122.50322869 45.50324862]
[-122.59152262 45.52130662]]
[[-122.50706986 45.50135379]
[-122.5932485 45.5235359 ]]
sseSplit, and notSplit: 741.4014272675822 1900.7331713346268
[[-122.73949131 45.43559581]
[-122.66970287 45.58294766]]
[[-122.73064807 45.4646222 ]
[-122.68309945 45.5445079 ]]
sseSplit, and notSplit: 1106.7327714438766 1162.961562171503
the bestCentToSplit is: 1
the len of bestClustAss is: 35
[[-122.52300861 45.41763998]
[-122.46734869 45.47112938]]
[[-122.60926571 45.47915871]
[-122.54441067 45.52353926]]
[[-122.60563667 45.48480644]
[-122.54052872 45.52505652]]
sseSplit, and notSplit: 859.8562027761263 1106.7327714438766
[[-122.76794698 45.43040135]
[-122.70082261 45.48767743]]
[[-122.76199717 45.44543167]
[-122.70974867 45.47741589]]
[[-122.766579 45.45739225]
[-122.68958414 45.472885 ]]
[[-122.7680632 45.4665528]
[-122.6558178 45.460761 ]]
sseSplit, and notSplit: 246.8875136159748 1766.0251407367637
[[-122.75447105 45.61027764]
[-122.72537232 45.57674902]]
[[-122.842918 45.646831 ]
[-122.67468795 45.53912247]]
sseSplit, and notSplit: 304.01028830517555 1666.630755050119
the bestCentToSplit is: 0
the len of bestClustAss is: 34
[[-122.58519449 45.50696341]
[-122.56066398 45.40595033]]
[[-122.60397962 45.4955235 ]
[-122.618893 45.39907 ]]
sseSplit, and notSplit: 53.26571037572606 1809.8661754941152
[[-122.68531707 45.48142388]
[-122.75793376 45.39426846]]
[[-122.72615654 45.47391254]
[-122.759843 45.404235 ]]
sseSplit, and notSplit: 387.5898454325387 1462.9197813413875
[[-122.73934818 45.59363143]
[-122.74062846 45.63998322]]
[[-122.67468795 45.53912247]
[-122.842918 45.646831 ]]
sseSplit, and notSplit: 304.01028830517555 1363.5253956547424
[[-122.51022354 45.46325094]
[-122.37899138 45.43717578]]
[[-122.54737142 45.52900392]
[-122.376304 45.430319 ]]
[[-122.55266787 45.52993361]
[-122.4009285 45.46897 ]]
sseSplit, and notSplit: 361.2106086859341 1263.4555701697648
the bestCentToSplit is: 3
the len of bestClustAss is: 25