2020.4.1-2020.4.7 魔笛手Pied pier周记
4.1 周三 第一天
本周序言:
《算法图解》这类书是学习用书,读起来是没有积极性的,毕竟谁会没事读教材,这不是跟自己过不去吗,但是我还必须得跟自己过不去,于是用写博客的形式记录下我的学习笔记。本书一共11章,每天读一章的话11天才能读完,一想到11天我就难受,但是要达到速战速决,还得每天的坚持,这个也是难得一匹,折衷想法是每天至少读一章,长痛不如短痛。
第一章:算法简介
(1)主要知识:二分查找,大O表示法
1.1 二分查找:输入要求是一个有序序列,例如经典的猜数问题,就是根据每次将中值和要找的值进行比对,根据大了还是小了调整查找范围,直到查找范围缩小到上限等于下限。对于二分查找,每次淘汰的是查找范围一半的数值,因此就是相当于除以2,故按照这种猜法,只需要看能被2除几次,直到商小于1为止(淘汰的数字的至少为1嘛,小于1就是淘汰环节终止),换句话说就是查找范围的总数等于几个2连乘,也就是取以2为底的对数(取对数就是幂运算的逆运算)。
1.2 大O表示法:O是指operator,也即操作数的次数,陈斌老师讲的,也就是看的赋值语句的次数(因为赋值语句里面同时包含表达式计算和变量存储,是一个好的衡量运行时间的标准,当然,操作次数具体是T(n),O()是T(n)的主导部分)。大O是主导部分的原因是因为它是算法运行时间随着问题规模n增大时的参与贡献最大的部分,也就是主要靠着它在拉动增长,那么它就是O()的括号里面填的内容,它甚至不需要系数,因为加上系数的增长也不及随着n的增大它本身的增大,而且它是最糟情况的下限(还有别的表示法:大欧米伽,大seita)。常见的几种运行时间有:对数时间(O(logn))、线性时间O(n),O(nlog(n))、O(n!)等。其中我们熟悉的排序算法,例如快速排序就是O(nlog(n)),选择排序就是O(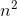 )。如果能用O(n!)衡量,那么是很耗时间的算法,因为n!的增速比
)。如果能用O(n!)衡量,那么是很耗时间的算法,因为n!的增速比 还要快,所谓n的阶乘,就是全排列问题,n=20时,时间消耗用你的一生衡量都太短,等结果出来了,太阳都没了。
还要快,所谓n的阶乘,就是全排列问题,n=20时,时间消耗用你的一生衡量都太短,等结果出来了,太阳都没了。
(2)经典代码
二分查找实现(Python):
def binary_search(num_list,number):
low=0
high=len(num_list)-1
while low<=high:
mid=(low+high)//2 #python里面地板除是//
if num_list[mid]==number:
return mid
else if num_list[mid] low=mid+1 else: high=mid-1 return None (3)小结感悟 开设“经典代码”模块是因为过去我很抵触这个,导致相关的,我就很抵触科研,但是其实代码写起来很有意思,尤其是当你慢慢地信手拈来,实现了一些比较酷炫的功能之后。所以,不要停止在想象的印象里,而要动手操作起来感受智趣,值得一提,代码是没看自己写的,一遍成功,但是只是鼓励下,因为这不是什么值得高兴的事,这是应该的,在内行看来这简直就是1+1=2。还好这本是python版本,不然真的这本书我直接就会以语言原因不看了,那样我会很心疼,心疼的是我的钱。说起来,数据结构和算法和语言密切相关,因为对同一算法的实现的性能不仅和算法本身相关,也和语言密切相关,当然算法本身是本质区别,之前看到那本紫色封面的清华出版社的严老师的教材,有个括号:C语言版,我当时还觉得干嘛标注语言,现在明白了,用啥实现也很有关系,必须要有针对性。至于为啥和语言相关,是因为现在接触到的编程语言基本都是高级语言,都是在机器语言上的演绎,而演绎方式各有不同,导致操作相同的话也会有不同的运行时间,而不像机器语言是统一标准的。 4.4 周六 第四天 第二章 :选择排序 (1)主要知识:数组和链表、选择查找 数组和链表:这两种数据结构主要是存储方式上的区别,数组是连续存储,链表是非连续存储,一个数组或者链表里面的元素数据类型需要一致。存储方式上的区别导致优势劣势的区分:数组的元素都在一块,相对固定,利于随机访问,不利于插入和删除元素;链表由于非连续存储,前一元素的存储除了值之外还要存储下一元素的地址值,在访问方式上就只能从第一个开始访问,是顺序访问,访问方式上占下风,但是由于自由散漫,因此利于插入和删除。由于各有千秋,因此最好的方式就是各取所长的链表数组,数组的每一个元素都指向的是一个链表,这样既可以随机访问,又可以随时插入和删除。例如facebook存储用户名,按照首字母存储的链表数组,查找的时候首先查找首字母,再在对应字母的链表里面添加。 选择查找:就是陈斌老师讲的简单查找,第一步遍历所有元素,找到最小元素,并转移到新的地方,第二步遍历剩下的元素,找到最小元素,依次类推。第一次查找次数是n,之后依次是n-1,n-2,n-3,...,1。加起来就是n(n+1)/2,忽略系数的话就是O( (2)经典代码:选择查找(定义两个函数,一个是找最小值,并返回下标,另一个是依次遍历数组,转移) def smallest(arr): smallest_num=arr[0] smallest_index=0 for i in range(len(arr)): if arr[i] smallest_num=arr[i] smallest_index=i return smallest_index def choose_search(arr): newarr=[] for i in range(len(arr)): smallnum=smallest(arr) newarr.append(arr.pop(smallnum)) return newarr (3)小结感悟:好的,又是一气呵成的代码,虽然又是特别基础的。不过又有了一点感觉,今早躺在床上想,自己没有用代码实现的算法都不算被自己真正掌握的算法。实现的过程就相当于当老师,把这个东西吸收成自己的讲给学生听,是理论到实践的飞跃,所以工程师是很厉害的。目前到第二章,还是没有超过我视频里面看到的东西,视频讲的更系统,更全面,更科学,但是书也是一种新思路,开阔眼界了。 第三章 :递归 (1)主要知识:递归(递归条件和基线条件)、调用栈 递归是一种自己调用自己的函数,在函数内部又调用自己,每调用自己一次,就缩小问题的规模一次,这就是递归条件,当然参数有所变化,一层一层的转化,直到化为可以直接返回的地步,这个地步就是基线条件。例如经典的求阶乘,就是从大数的阶乘一层一层缩小到最后只有1的阶乘,再从1开始返回,是一个连续的过程,既然连续,就能用到堆栈这种数据结构去解决,call stack(调用栈),所有函数调用都是使用堆栈实现的。堆栈的功能的特点就是连续性,可以连续插入或者弹出,例如当前运行函数1,函数1 的内存区域在堆栈的最底部,函数1运行到一部分时调用到函数2,那么函数2这时候就进来了,如果函数2还有调用就以此类推的进来,直到新进来的函数可以返回,开始返回之后就会接连地弹出,直到最后函数1的弹出,程序结束。递归是函数调用的一种特殊情况,也就是新进来的函数还是自己,只不过参数有所变化。最后总结,所谓堆栈,就是在执行中调用到新的就进来,直到新的可以开始返回,就轮到下面的旧函数执行了。 (2)经典代码:求阶乘 def factorial(x): if x==1: return 1 else: return x*factorial(x-1) (3)小结感悟:之前看严老师的书,总觉得堆栈很神秘很费劲,单独整一个堆栈有什么用,今天才理解原来函数调用是这样利用堆栈的,堆栈很有用啊,基本上是基石了,害,读书少,多见怪了,还有一个关于堆栈的就是据说黑客攻击会从堆栈下手,这是我觉得神秘的原因。另外,还有一个点有被惊艳到,就是说递归这个思想的概念很重要,递归能解决的问题用循环也能解决,但是用递归的方式去解释,就更直观,尤其是某些语言没有循环,只有将算法转化为递归才可以写,例如Haskell语言。不过其实我第一次接触递归的时候我觉得很难,很抽象,想半天想不明白,不过我真的就是那种笨笨的、反应慢,需要花时间才能理解的人,这样想就不慌一点。 第四章:选择排序 (1)主要知识:由递归引出的分而治之思想(DIVIDE AND CONQUER)、快速排序 分而治之思想:介绍“如何把一块地分成若干个最大方块的问题”,使用欧几里得思想:适用于小块地的最大方块也是适用于整块地的最大方块。这道题的基线条件就是一块地的长等于宽的两倍,那么直接就可以分成两个边长为宽的正方形。递归过程是首先按照宽去分解尽可能多的方块,再对剩下的土地执行相应的操作。 快速排序:指导思想是分而治之,每次选择一个基准值,根据基准值将剩下的数分成两个组,一个组是大于基准值,另一个则相反,再对分好的两个组执行相同的操作,直到小组里面只剩一个值或者没有值。注意这里基准值的选取对算法复杂度有直接影响,应该随机选取,使得平均水平为O(nlogn)。最糟糕的水平呢,就是O( (2)经典代码:以数组的第一个元素为基准值 def quick_sort(arr): if len(arr)<2: return arr else: pivot=arr[0] less=[for j in arr if j greater=[for k in arr if k>pivot] return quick_sort(less)+pivot+quick_sort(greater) (3)小结感悟:Python真有用。(最近没怎么读书,思想很贫瘠,有看出来吧 4.5 第五天 周日 今天也是疯狂赶进度的一天。对,我又在4.6赶4.5的进度,又在心里小声骂昨天的自己。 第五章:散列表 (1)主要知识:散列表及其内部机制(实现、冲突、散列函数 散列表:散列表的本质是一种映射关系,类似于函数,能通过已知的自变量的值迅速得到因变量的值的一种数据结构,在Python里面是“字典”。字典的特点是一个键对应一个值,且键的数值是不能重复的。因此关于这种数据结构就可以用来1.表征映射关系 2.需要防重复的设计 3.作为存储数据的结构(例如服务器会对常用访问网页进行存储,中央处理器中的Cache高速缓冲器,都是利用了这类数据结构查找、插入、删除的复杂度都是O(1)的特点)。散列表的内部核心是散列函数,即利用什么样的方式去选定存储位置的索引,比如利用字符串的长度来区分、或者利用字符串的首字母来区分等等,散列函数的设计很关键,万一设计不好,就会导致冲突,也就是说不同的键会分配到相同的存储位置的索引,这样也不是不行,这样的话一个位置当然放不下,就会生成一个链表,这个索引的位置就是存储的链表,本来查找就是一对一比较快,这样的话找到位置了还要面对一个链表进行二次选择,那就违背我的初衷辽,因此呢,我的散列函数的设计就是要1.分散 2.均匀(再品一品“散列”两个字,是不是觉得这个名字完全就是浓缩的精华),也没有完美的散列函数,面对纷繁复杂的数据都能做到分散均匀的,总是不免出现一个多个键影射到一个位置或者分布相对较满的情况,于是呢,需要调整,一旦被填充的部分占所有位置的比例超过百分之七十,那么就需要resize数组空间,然后将原来的键映射到新的宽敞的数组空间中来,降低这个填充比例。即使有这样一个resize的过程,使用散列表这种数据结构去存储查找的速度依然比数组去存储要快很多,当然是在平均情况下啦。 (2)经典代码:使用字典作为投票检查器和使用字典作为服务器缓存 1.book={} def one_vote(name): if book[name]: print('Go home and come back to your mother') else: book[name]=True print('You can vote now') 2.cache={} def storage(url): if cache.get(url): return cache[url] else: cache[url]=get_data_from_server(url) #从服务器中找到这个url对应的网址并存储在cache中 return cache[url] (3)小结感悟:虽然Python编程语言很高级,很多东西都封装好了,几乎没有底层的东西,很好上手,这样看好像不需要了解内部机制是什么样的,但是了解底层才对这个东西的掌握程度更好,就像买一件衣服,你还知道这衣服的面料以及加工过程,那么你在穿的时候就更能选择a more proper occasion.(沉迷这种体了,骚瑞),学习底层的东西很有必要,俺的个人看法。 第六章:广度优先搜索 (1)主要知识:数据结构图(有向图和无向图)、广度优先搜索(查找最短路径)、队列(先进先出的数据结构) 广度有限搜索用于解决最短路径,其使用的主要方法是图算法。所谓图,由节点(node)和边(edge)组成,节点之间由边连接起来,边分为单向和双向,单向则为有向图,双向则为无向图。对于要求最短路径的目标,我们先转化为“有路径吗”的问题。先看从起点开始,一步能到达的地方,再看两步能到达的地方,以此类推,我们的终点出现在三步能到达的地方,因此,三步就是最短路径,这就是核心思想,朋友里面没有你要找的人,那么再看朋友的朋友里面有没有你要找的人,注意找的时候不要出现重复查找的情况,也就是你的朋友和你朋友的朋友是同一个人的情况,这样不仅效率低下,而且还可能出现死循环的情况。如何实现先从朋友里面找,再在朋友的朋友里面找的顺序呢?采用队列这种数据结构。队列和对堆栈正好相反,是先进先出(First in First Out),保证了能够按照添加顺序进行检查。另外,使用字典实现”朋友的朋友“这种对应关系。 (2)经典代码: from collection import deque graph={} #利用字典建立对应关系 graph['you']=['Alice','Bob','Claire'] graph['Bob']=['anuj','peggy'] #此处仅添加这两个 不作一一列举 def search(name): search_sequence=deque()#建立队列实现按照添加顺序查找 search_sequence+=graph[name] searched=[] while search_queue: person=search_queue.popleft() if person not in searched: if person_is_seller(person): print person+'is a mango seller' return True else: search_quene+=graph[person] #这个人不是芒果商 于是把这个人的朋友加入队列进行检查 searched.append(name) #记录已经检查过的不是芒果商的人 return False #如果到这里说明找完了朋友,也找完了朋友的朋友,朋友的朋友的朋友等等,没找到,所以就没有芒果商 search('you') (3)小结感悟:不同的数据结构有他适应的问题,分析问题所需,选择对应的数据结构,另外,有一个小技巧,是防止重复的,可以新建一个列表,用于记录已经操作过的数字,在每次操作之前判断一下是in还是not in就可以。 4.10 周五(我太懒了 我接受了 不挣扎了 我看我不配有被要求 哼!!!气人 开头的十一天真的一点都不长哦!甚至太短了! 第七章:狄克斯特拉算法 (1)主要知识:广度优先搜索找出的是段数最少的路径,对象是没有加权的图。狄克斯特拉算法对象是有向无环加权图(注意与无向图实际上就是有环图,因为无向图就是两个节点之间互相相连,另外狄克斯特拉算法仅针对的是权重为正的,也就是“单增性”,总结下为有向加权图,对于负权图,应采用Bellman-Ford算法)。列一张表,对当前没有被更新过的最便宜的开销节点,计算当前点到终点的最近距离从而更新有关系的节点,如果最终不仅想计算最小开销,还想知道最短路径,只需要再在表格里面加一列“父节点‘即可,也即每次更新的时候顺便将对应的父节点记录下来。最终顺着终点-终点的父节点-父节点的父节点这样的顺序回溯回去就能得到最短路径。 (2)经典代码: 2.1 数据结构准备:三个字典和一个列表,分别存储有向加权图、开销表、父节点表以及处理过的节点。第一,graph['节点A'][’节点A的下一节点‘]=’权重值‘,graph['节点']本身就是一个字典,所以这是一个二级字典,是字典的字典,可以通过graph['A'].keys()访问和节点A相连的所有节点。开销表和父节点表就是两个一级字典,键值就是所有节点。处理过的节点列表为processed。另外,无穷大在python里面表示为float('inf') 2.2 主函数和子函数 主函数:node=find_lowest_cost_node(cost) #最初选取最便宜的节点,且最便宜的节点没有被处理过 while node is not None: cost=cost[node] neighbors=graph[node] for n in neighbors.keys(): if neighbor[node]+cost cost[n]=neighbor[node]+cost father[n]=node processed.append(node) node=find_lowest_cost_node(cost) 子函数:def find_lowest_cost_node(cost): low_cost=float('inf') low_cost_node=None for n in cost and not in processed: cost=cost[n] if cost low_cost=cost low_cost_node=n return low_cost_node (3)小结感悟:算法原理和实际实现之间有一定的距离,这个距离就是数据结构的准备。所以在实现算法的时候,首先整理好合适的数据结构,再动手写代码。狄克斯特拉狄克斯特拉狄克斯特拉,我真的记不住这个名字。 第八章:贪婪算法 (1)主要知识:所谓NP完全问题,就是无法在有限时间内完成的事情。算法复杂度在指数级别甚至阶乘级别的,其时间消耗随着问题规模的增长是爆炸式的,是在有生之年无法解决的,例如本书中列举的集合覆盖问题和旅行商问题,集合覆盖问题需要列出所有集合组合的情况,组合数相加的和是2的阶乘;旅行商问题是将要去的地方进行排列,我们知道全排列是n的阶乘。人生苦短,既然找到全局最优解是不可能滴,那么我们在有限时间内找到接近全局最优解的局部最优解也是好的,不求完美,优秀也是极好的。贪婪算法就是一种近似算法,是试图以局部最优解去代替全局最优解的算法。贪婪算法的主要思想是每次都找当前最优的做法,以背包问题为例的话就是每次都拿剩下的物品中最值钱的东西。 (2)经典代码:以集合覆盖问题为例,每次都覆盖剩下区域最多的广播台为best station,直到不剩下区域需要覆盖 while states_need: best_station=None state_covered=set() #初始化最大重叠区域 for state,station in station.items(): #遍历广播站,找到和当前剩下区域重叠最大的广播站 cover=state_needed&station if len(cover)>len(state_covered): best_station=state state_covered=cover #一旦找到最大重叠的就赋值给它 state_needed-=state_needed final_station.append(best_station) (3)小结感悟:处理问题的时候先看看是不是NP完全问题,如果是的话就可以用贪婪算法。 第九章:动态规划 (1)主要知识:动态规划(找有限制条件下的最优解)的基本思想和递归是一样的,都是将大问题转化为子问题来解决,找到每步的递推式,因此能用动态规划的一般也都能用递归解决。动态规划是自底向上的解决方法,递归是自顶向下的解决方法。在具体实现上,动态规划多是列表问题,有的是一维列表,有的是二维列表,具体看限制条件。例如经典的背包问题,就是二维列表,总容量限制为5磅,那么我们就从1磅开始看,1磅最多能装多少价值的,然后2磅,3磅依次填下去。表格的横轴是磅数,纵轴就是各种物品,一行一行地填,每新加1磅,就看能不能放下当前行的物品,如果可以的话计算总价值=当前物品价值+剩余磅数的价值(这个之前就算出来了,在表格里面有),不可以的话就直接照抄左边的值,这就是递推式。关于为啥从1磅开始,因为最小的物品就是重1磅,按照这个最小物品的重量去定颗粒度。另外,动态规划的经典应用还有“最长公共子序列”和“最长公共子串‘的问题,也都是二维列表,横轴纵轴当然就是需要比较的两个字串了。”最长公共子序列’的递推式就是当前的横轴纵轴对应的字母是否相同,相同的话就由左上角的对角格的数加一,否则就是0;“最长公共子串”的递推式也是同样的判断,如果相同的话也是一样计算,不相同的话就照抄左边格子和上边格子中的大的值。 (2)经典代码:代码没有什么好讲的,主要就是几个if判断,二位列表的计算等。 (3)小结感悟:这类算法还是需要多刷题,难点在于识别这类问题和找出递推式,另外注意递推式的初始值是需要自己找的。 第十章:K近邻算法 (1)主要知识:K近邻是一种分类或者回归算法,而分类问题就是分组问题,回归问题就是预测值问题。怎么分组和预测值呢?首先将分类对象特征化,对每个对象进行“编号‘,使用这个编号去代表它,所以这个特征是否具有代表性就很大程度地决定算法性能。再计算编号之间的”距离’或者“夹角‘来判断是否相似。和谁相似自然就是和谁一组,到这里分组已经解决,预测值的话就是把和他相近的这几个人的值处理一番后得到新的值就大功告成了。所谓K近邻就是分组或者预测值的时候,找几个人来参考。找5个人就是5近邻。推荐系统就有利用K近邻的原理去做,首先计算相似度,找到最相似的K个人,通过这K个人的数据去给这个人推荐电影或者预测这个人对某部电影的打分。 (2)经典代码:重在思想,没有列代码,在python里面也应该主要是调包了,scipy/sklean等。 (3)小结感悟:这本书很厉害的一点就是把枯燥的算法讲的深入浅出,看起来很高端的算法被他讲的好像也很好理解和上手。 第十一章:算法进阶 (1)主要知识:对基础算法有简单了解之后,本书作者继续介绍了更加深入的10类算法。 1.树:之前介绍的二分法查找是需要对有序列表进行查找,那么二叉搜索树(左小右大)就是一种适应这种算法的数据结构,但是二叉搜索树可能存在不平衡(一边特别长)的问题,所以就还有红黑树、B树、堆和伸展树。 2.反向索引:主要是搜索方面的应用,例如建立搜索关键词为键值、网页为值的字典,这种是为服务用户的反向索引。 3.傅里叶变换:BetterExplained这么解释傅里叶变换:如果你给他一杯沙冰,他能给你分析出有什么成分。 4.并行算法:将任务分解为一个个子任务,子任务不同的处理器中运行,最终再将结果合并。 5.Mapreduce:是一种需要很多处理器的分布式算法,可以在短时间内处理海量工作。其中map是映射函数,可以对列表中的每一个数做相同的操作,reduce是归并函数,也就是将列表中的所有数进行某个迭代式的运算,最终输出一个值。 6.布隆过滤器和Hyperloglog:当准确查找需要很大的工作量的时候,可以使用这样一种算法:结果不保证完全正确,但是大概率是准确的,可能出现错报,但是不可能出现漏报。以判定网站是否被搜集为例,如果返回”这个网页已经被搜集’,那么也很可能没有被搜集;但是如果返回“这个王爷没有被搜集”,那么这网页就是一定没有被搜集。 7.SHA算法:回顾一下之前学的散列函数(哈希函数),就是将数据映射到存储空间的某个位置的函数,那么这个SHA呢,就是secure hash algorithm,安全哈希函数。同样是映射,这个算法可以将对象映射到一个字符串,而且这个字符串不能倒推回原始对象,也就是说可以用来加密,也可以用来比对较大的文件,计算他们的哈希值并比较即可,节约时间。另外就是可以存储用户密码,存储密码的哈希值即可,每次输入密码,计算哈希值并和数据库里面的哈希值进行比对。 8.局部敏感的哈希算法:之前介绍的哈希算法对输入对象相差不大的情况是没有显现的,也就是说即使是相差不大的两个东西,那么他们的哈希值也可能是大不相同的,局部敏感的哈希算法就是解决了这类问题,将这一特征体现在哈希值上,改进为局部敏感的,当输入差不多的时候,那么他们的哈希值也是相差不大的,便于在相似情况下的比对。 9.diffie-hellman密钥交换:双方不需要知道加密算法,不需要协调要使用的加密算法,而且非常难以破解。DH算法使用公钥和密钥,公钥是公开的,发件人使用公钥进行加密,收件人使用私钥进行解密。 10.线性规划:线性规划是作者知道的最酷的算法之一,他是在给定条件下最大限度地改善指定的指标的算法。所有的图算法都可以用线性规划来解决。 (2)小结感悟:学海无涯。 第二天就凭拖延实力说话,连续两天都没有看一页,第四天了,今天一天要看三章,真的有点呜呜呜,谁让我懒懒两天的,拖延的我的眼泪不值钱。(一段想要划掉的回忆,拖延加后悔无限循环,我什么时候有长进5555))。我还是觉得陈老师讲的方法比较能推广,就是从程序里面分析T(n),计算赋值语句的执行次数,再算复杂度。)。这一讲一句,还有一个合并排序(Merge sort),它的复杂度也是O(nlogn),且一直是这个数,但是为啥还是用快速排序呢,因为复杂度水平相同时,这个时候常量的影响力就出来了,之前我们忽略常量是因为复杂度不可同日而语,但是一样的时候就该比较常量了。快速排序的常量比合并排序要小,因此依然选择看起来不稳定但实际上更为简洁的快速排序。