基于 PyTorch 实现 AlexNet 并在 Cifar-10 数据集上进行验证
写在前面
这是深度学习课程的第二个实验,实验的主要内容是卷积神经网络,要求实现 AlexNet。但是 AlexNet 的输入不符合 Cifar-10 数据集,因此这里将参数更改了一下,但网络结构没有变,还是五层卷积,三层全连接。
虽然对于 32 X 32 这么小的图片,用 AlexNet 有点大材小用的感觉,但实验要求,而且对于初学者来说,AlexNet 还是很经典的,能学到不少东西,直接干就好了。
首先放上实验要求:
基于 PyTorch 实现 AlexNet
在 Cifar-10 数据集上进行验证
使用tensorboard进行训练数据可视化(Loss 曲线)
如有条件,尝试不同参数的影响,尝试其他网络结构
请勿使用torchvision.models.AlexNet
实验2的 github 地址:lab2 AlexNet
卷积神经网的尺寸计算
在写卷积神经网的代码之前,首先,必须要知道一个知识点,就是每层卷积神经网的输入和输出的关系,即卷积过程的尺寸变化。
尺寸的变化公式可以按照如下公式进行计算:
N = ( W − F + 2 P ) / S + 1 N = (W − F + 2P )/S+1 N=(W−F+2P)/S+1
其中
- W 表示输入图片尺寸(W×W)
- F 表示卷积核的大小(F×F)
- S 表示步长
- P 表示填充的像素数(Padding)
最后输出的图像大小是 N × N N \times N N×N
池化层的计算大致一样,也是利用滤波器的大小 F×F 和 步长的大小 S 进行计算;通常是不加 padding 的,如果有 Padding, 则完全按照卷积的公式计算即可。
过程
加载数据集
实验中使用的是 CIFAR-10 数据集,CIFAR-10 数据集由 10 个类的 60000 个 32x32 彩色图像组成,每个类有6000个图像。有50000个训练图像和10000个测试图像。
首先,加载数据集:
# 加载数据集 (训练集和测试集)
trainset = torchvision.datasets.CIFAR10(root='./Cifar-10', train=True, download=True, transform=transforms.ToTensor())
trainloader = torch.utils.data.DataLoader(trainset, batch_size=batchSize, shuffle=True)
testset = torchvision.datasets.CIFAR10(root='./Cifar-10', train=False, download=True, transform=transforms.ToTensor())
testloader = torch.utils.data.DataLoader(testset, batch_size=batchSize, shuffle=False)
定义网络结构
Pytorch 中,实现卷积神经网的两个主要函数必须要记得(写在前面,方便参考它们的参数):
卷积层:
class torch.nn.Conv2d(in_channels, out_channels, kernel_size, stride=1, padding=0, dilation=1, groups=1, bias=True)
池化层(以 MaxPool2d 为例):
class torch.nn.MaxPool2d(kernel_size, stride=None, padding=0, dilation=1, return_indices=False, ceil_mode=False)
AlexNet 的网络结构是 5 层卷积,3 层全连接,由于输入的图片大小是 32 x 32 的,因此不能完全按照 AlexNet 设计,更改网络结构如下:
# 定义神经网络
class Net(nn.Module): # 训练 ALexNet
'''
三层卷积,三层全连接 (应该是5层卷积,由于图片是 32 * 32,且为了效率,这里设成了 3 层)
'''
def __init__(self):
super(Net, self).__init__()
# 五个卷积层
self.conv1 = nn.Sequential( # 输入 32 * 32 * 3
nn.Conv2d(in_channels=3, out_channels=6, kernel_size=3, stride=1, padding=1), # (32-3+2)/1+1 = 32
nn.ReLU(),
nn.MaxPool2d(kernel_size=2, stride=2, padding=0) # (32-2)/2+1 = 16
)
self.conv2 = nn.Sequential( # 输入 16 * 16 * 6
nn.Conv2d(in_channels=6, out_channels=16, kernel_size=3, stride=1, padding=1), # (16-3+2)/1+1 = 16
nn.ReLU(),
nn.MaxPool2d(kernel_size=2, stride=2, padding=0) # (16-2)/2+1 = 8
)
self.conv3 = nn.Sequential( # 输入 8 * 8 * 16
nn.Conv2d(in_channels=16, out_channels=32, kernel_size=3, stride=1, padding=1), # (8-3+2)/1+1 = 8
nn.ReLU(),
nn.MaxPool2d(kernel_size=2, stride=2, padding=0) # (8-2)/2+1 = 4
)
self.conv4 = nn.Sequential( # 输入 4 * 4 * 64
nn.Conv2d(in_channels=32, out_channels=64, kernel_size=3, stride=1, padding=1), # (4-3+2)/1+1 = 4
nn.ReLU(),
nn.MaxPool2d(kernel_size=2, stride=2, padding=0) # (4-2)/2+1 = 2
)
self.conv5 = nn.Sequential( # 输入 2 * 2 * 128
nn.Conv2d(in_channels=64, out_channels=128, kernel_size=3, stride=1, padding=1),# (2-3+2)/1+1 = 2
nn.ReLU(),
nn.MaxPool2d(kernel_size=2, stride=2, padding=0) # (2-2)/2+1 = 1
) # 最后一层卷积层,输出 1 * 1 * 128
# 全连接层
self.dense = nn.Sequential(
nn.Linear(128, 120),
nn.ReLU(),
nn.Linear(120, 84),
nn.ReLU(),
nn.Linear(84, 10)
)
def forward(self, x):
x = self.conv1(x)
x = self.conv2(x)
x = self.conv3(x)
x = self.conv4(x)
x = self.conv5(x)
x = x.view(-1, 128)
x = self.dense(x)
return x
每层的输出大小已经在注释中进行标注
训练
训练之前,要定义一些全局变量:
# 定义全局变量
modelPath = './model.pkl'
batchSize = 5
nEpochs = 20
# 定义Summary_Writer
writer = SummaryWriter('./Result') # 数据存放在这个文件夹
# cuda
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
其中的 SummaryWriter 是用来做可视化的
然后定义训练函数:
# 训练函数
def train():
# 定义损失函数和优化器
criterion = nn.CrossEntropyLoss() # 交叉熵损失
optimizer = optim.SGD(net.parameters(), lr=0.001, momentum=0.9) # 随机梯度下降
iter = 0
num = 1
# 训练网络
for epoch in range(nEpochs): # loop over the dataset multiple times
running_loss = 0.0
for i, data in enumerate(trainloader, 0):
iter = iter + 1
# 取数据
inputs, labels = data
inputs, labels = inputs.to(device), labels.to(device) # 将输入和目标在每一步都送入GPU
# 将梯度置零
optimizer.zero_grad()
# 训练
outputs = net(inputs)
loss = criterion(outputs, labels).to(device)
loss.backward() # 反向传播
writer.add_scalar('loss', loss.item(), iter)
optimizer.step() # 优化
# 统计数据
running_loss += loss.item()
if i % 100 == 99: # 每 batchsize * 100 张图片,打印一次
print('epoch: %d\t batch: %d\t loss: %.6f' % (epoch + 1, i + 1, running_loss / (batchSize*100)))
running_loss = 0.0
writer.add_scalar('accuracy', Accuracy(), num + 1)
num + 1
# 保存模型
torch.save(net, './model.pkl')
测试函数
测试函数已经在训练时使用了,代码如下:
# 使用测试数据测试网络
def Accuracy():
correct = 0
total = 0
with torch.no_grad(): # 训练集中不需要反向传播
for data in testloader:
images, labels = data
images, labels = images.to(device), labels.to(device) # 将输入和目标在每一步都送入GPU
outputs = net(images)
_, predicted = torch.max(outputs.data, 1) # 返回每一行中最大值的那个元素,且返回其索引
total += labels.size(0)
correct += (predicted == labels).sum().item()
print('Accuracy of the network on the 10000 test images: %d %%' % (100 * correct / total))
return 100.0 * correct / total
完整代码
import os
import torch
import torch.nn as nn
import torch.nn.functional as F
import torchvision
import torchvision.transforms as transforms
import torch.optim as optim
from tensorboardX import SummaryWriter
# 定义全局变量
modelPath = './model.pkl'
batchSize = 5
nEpochs = 20
numPrint = 1000
# 定义Summary_Writer
writer = SummaryWriter('./Result') # 数据存放在这个文件夹
# cuda
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
# 加载数据集 (训练集和测试集)
trainset = torchvision.datasets.CIFAR10(root='./Cifar-10', train=True, download=True, transform=transforms.ToTensor())
trainloader = torch.utils.data.DataLoader(trainset, batch_size=batchSize, shuffle=True)
testset = torchvision.datasets.CIFAR10(root='./Cifar-10', train=False, download=True, transform=transforms.ToTensor())
testloader = torch.utils.data.DataLoader(testset, batch_size=batchSize, shuffle=False)
# 定义神经网络
class Net(nn.Module): # 训练 ALexNet
'''
三层卷积,三层全连接 (应该是5层卷积,由于图片是 32 * 32,且为了效率,这里设成了 3 层)
'''
def __init__(self):
super(Net, self).__init__()
# 五个卷积层
self.conv1 = nn.Sequential( # 输入 32 * 32 * 3
nn.Conv2d(in_channels=3, out_channels=6, kernel_size=3, stride=1, padding=1), # (32-3+2)/1+1 = 32
nn.ReLU(),
nn.MaxPool2d(kernel_size=2, stride=2, padding=0) # (32-2)/2+1 = 16
)
self.conv2 = nn.Sequential( # 输入 16 * 16 * 6
nn.Conv2d(in_channels=6, out_channels=16, kernel_size=3, stride=1, padding=1), # (16-3+2)/1+1 = 16
nn.ReLU(),
nn.MaxPool2d(kernel_size=2, stride=2, padding=0) # (16-2)/2+1 = 8
)
self.conv3 = nn.Sequential( # 输入 8 * 8 * 16
nn.Conv2d(in_channels=16, out_channels=32, kernel_size=3, stride=1, padding=1), # (8-3+2)/1+1 = 8
nn.ReLU(),
nn.MaxPool2d(kernel_size=2, stride=2, padding=0) # (8-2)/2+1 = 4
)
self.conv4 = nn.Sequential( # 输入 4 * 4 * 64
nn.Conv2d(in_channels=32, out_channels=64, kernel_size=3, stride=1, padding=1), # (4-3+2)/1+1 = 4
nn.ReLU(),
nn.MaxPool2d(kernel_size=2, stride=2, padding=0) # (4-2)/2+1 = 2
)
self.conv5 = nn.Sequential( # 输入 2 * 2 * 128
nn.Conv2d(in_channels=64, out_channels=128, kernel_size=3, stride=1, padding=1),# (2-3+2)/1+1 = 2
nn.ReLU(),
nn.MaxPool2d(kernel_size=2, stride=2, padding=0) # (2-2)/2+1 = 1
) # 最后一层卷积层,输出 1 * 1 * 128
# 全连接层
self.dense = nn.Sequential(
nn.Linear(128, 120),
nn.ReLU(),
nn.Linear(120, 84),
nn.ReLU(),
nn.Linear(84, 10)
)
def forward(self, x):
x = self.conv1(x)
x = self.conv2(x)
x = self.conv3(x)
x = self.conv4(x)
x = self.conv5(x)
x = x.view(-1, 128)
x = self.dense(x)
return x
net = Net().to(device)
# 使用测试数据测试网络
def Accuracy():
correct = 0
total = 0
with torch.no_grad(): # 训练集中不需要反向传播
for data in testloader:
images, labels = data
images, labels = images.to(device), labels.to(device) # 将输入和目标在每一步都送入GPU
outputs = net(images)
_, predicted = torch.max(outputs.data, 1) # 返回每一行中最大值的那个元素,且返回其索引
total += labels.size(0)
correct += (predicted == labels).sum().item()
print('Accuracy of the network on the 10000 test images: %d %%' % (100 * correct / total))
return 100.0 * correct / total
# 训练函数
def train():
# 定义损失函数和优化器
criterion = nn.CrossEntropyLoss() # 交叉熵损失
optimizer = optim.SGD(net.parameters(), lr=0.001, momentum=0.9) # 随机梯度下降
iter = 0
num = 1
# 训练网络
for epoch in range(nEpochs): # loop over the dataset multiple times
running_loss = 0.0
for i, data in enumerate(trainloader, 0):
iter = iter + 1
# 取数据
inputs, labels = data
inputs, labels = inputs.to(device), labels.to(device) # 将输入和目标在每一步都送入GPU
# 将梯度置零
optimizer.zero_grad()
# 训练
outputs = net(inputs)
loss = criterion(outputs, labels).to(device)
loss.backward() # 反向传播
writer.add_scalar('loss', loss.item(), iter)
optimizer.step() # 优化
# 统计数据
running_loss += loss.item()
if i % numPrint == 999: # 每 batchsize * numPrint 张图片,打印一次
print('epoch: %d\t batch: %d\t loss: %.6f' % (epoch + 1, i + 1, running_loss / (batchSize*numPrint)))
running_loss = 0.0
writer.add_scalar('accuracy', Accuracy(), num + 1)
num = num + 1
# 保存模型
torch.save(net, './model.pkl')
if __name__ == '__main__':
# 如果模型存在,加载模型
if os.path.exists(modelPath):
print('model exits')
net = torch.load(modelPath)
print('model loaded')
else:
print('model not exits')
print('Training Started')
train()
writer.close()
print('Training Finished')
总结
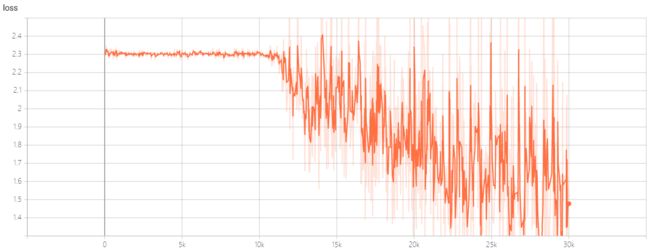
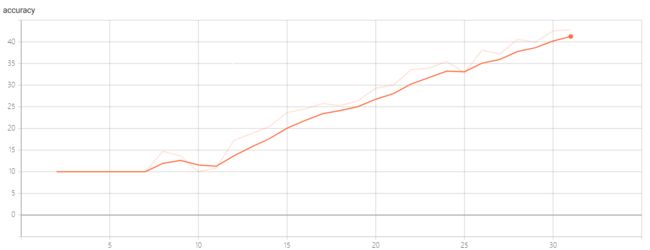
最后训练完后,执行命令:可以查看 loss 和 准确率曲线,最后的效果图还是挺好的,我用模型训练了两个 epoch 的效果如下:
Loss 曲线:
准确率曲线:
这次实验让我对卷积神经网络的理解更深了,现在看到的代码是我在课程结束后改的,实验提交上去的代码简直不忍直视,错误的地方太多了,只怪当时没好好学习,,,希望助教手下留情吧。。。